第八次作业
WordCount程序任务:
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
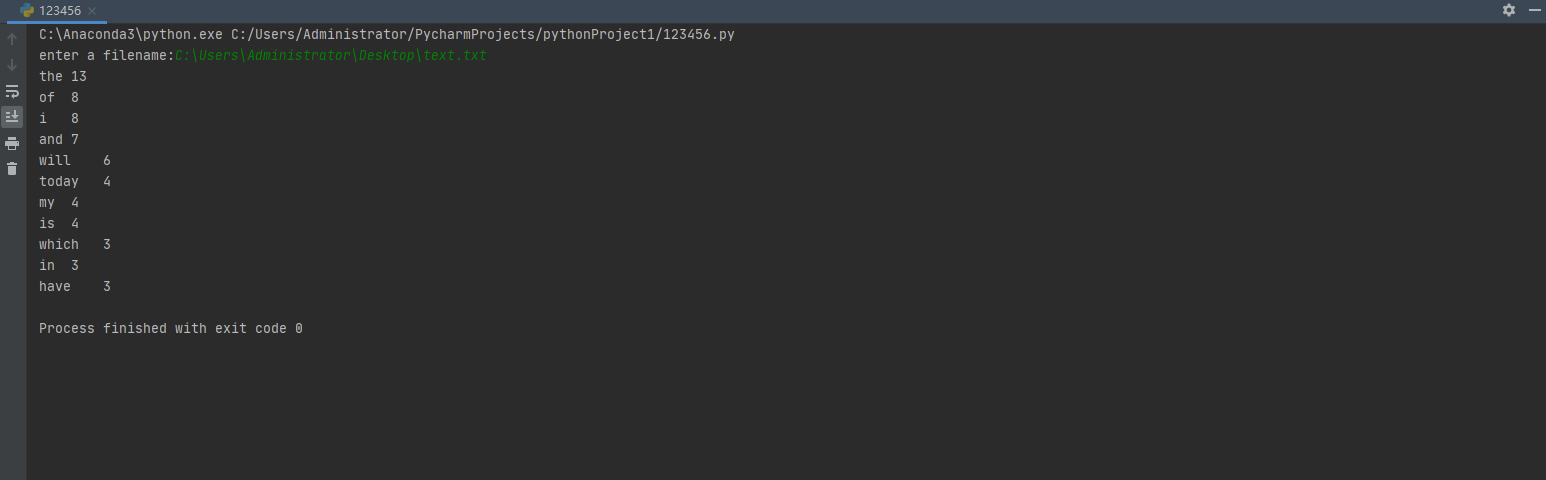
输出 |
文件中每个单词及其出现次数(频数), 并按照单词字母顺序排序, 每个单词和其频数占一行,单词和频数之间有间隔 |
1.用你最熟悉的编程环境,编写非分布式的词频统计程序。
- 读文件
- 分词(text.split列表)
- 按单词统计(字典,key单词,value次数)
- 排序(list.sort列表)
- 输出
#引入turtle模块,用于绘制结果图
import turtle
#全局变量
#词频排列显示个数,我们只显示出现次数最多的11个单词
count=11
#单词频率数组--作为y轴数据
numbers=[]
#单词数组--作为x轴数据
words=[]
#y轴显示放大倍数--可以根据词频数量进行调节
yScale=15
#x轴放大倍数--可以根据count数量进行调节
xScale=36
#处理文本的每一行,计算每一行的词频
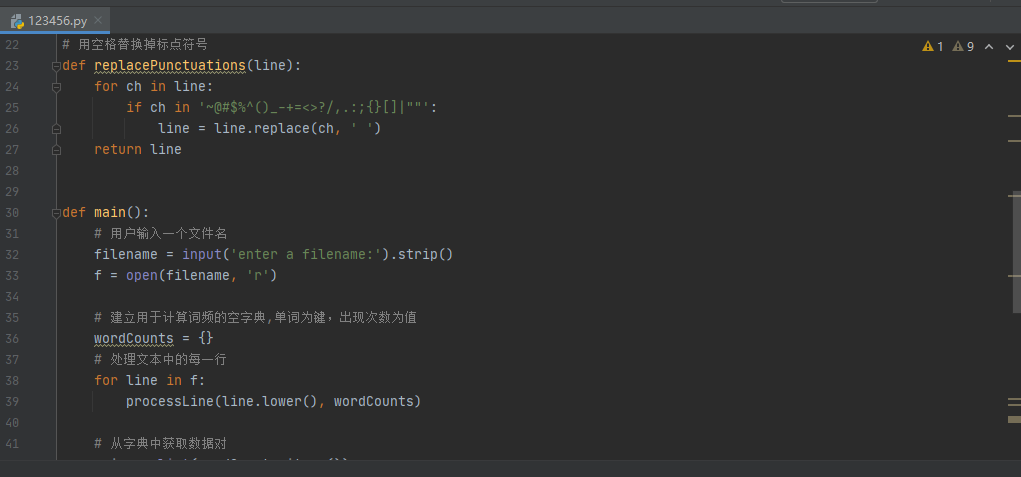
def processLine(line,wordCounts):
#用空格替换标点符号
line=replacePunctuations(line)
#从每一行获取每个词
words=line.split()
for word in words:
if word in wordCounts:
wordCounts[word]+=1
else:
wordCounts[word]=1
#用空格替换掉标点符号
def replacePunctuations(line):
for ch in line:
if ch in '~@#$%^()_-+=<>?/,.:;{}[]|""':
line=line.replace(ch,' ')
return line
def main():
#用户输入一个文件名
filename=input('enter a filename:').strip()
f=open(filename,'r')
#建立用于计算词频的空字典,单词为键,出现次数为值
wordCounts={}
#处理文本中的每一行
for line in f:
processLine(line.lower(),wordCounts)
#从字典中获取数据对
pairs=list(wordCounts.items())
#列表中的数据对交换位置,数据对排序
items=[[x,y] for (y,x) in pairs]
items.sort()#按照单词出现次数排序(由小到大)
#输出最大的count个词频结果(列表中最后count个元素最大)
for i in range(len(items)-1,len(items)-count-1,-1):
print(items[i][1]+'\t'+str(items[i][0]))
numbers.append(items[i][0])
words.append(items[i][1])
f.close()
#调用main()函数
if __name__=='__main__':
main()