
数据库基础知识复习
一. 事务
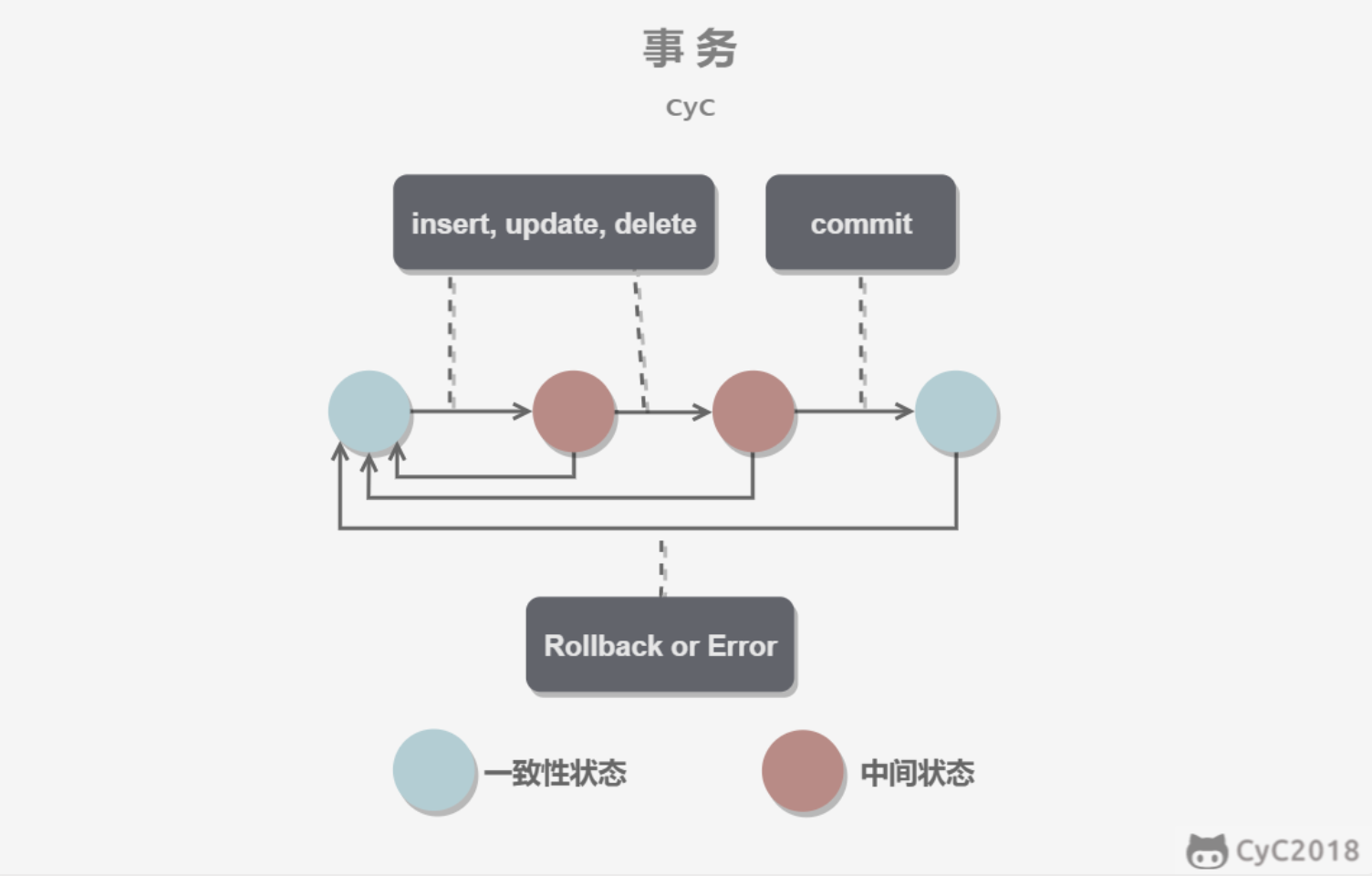
事务指满足ACID特性的一组操作,可以通过commit提交,也可以使用rollback回滚。
ACID
1.原子性 (atomicity) 事务被视为不可分割的最小单元。事务的所有操作要么全部提交成功,要么失败进行回滚。
2.一致性(consistency) 数据库在事务执行前后保持一致的状态。在一致性状态下,所有事务对同一个数据的读取状态相同。
3.隔离性(isolation) 一个事务所做的修改在提交前,其他事务是不可见的
4.持久性(durability) 一旦事务提交,其所做的修改会永远保存在数据库中。即使系统发生崩溃,结果也不会丢失。

二. 并发一致性问题
1.丢失修改
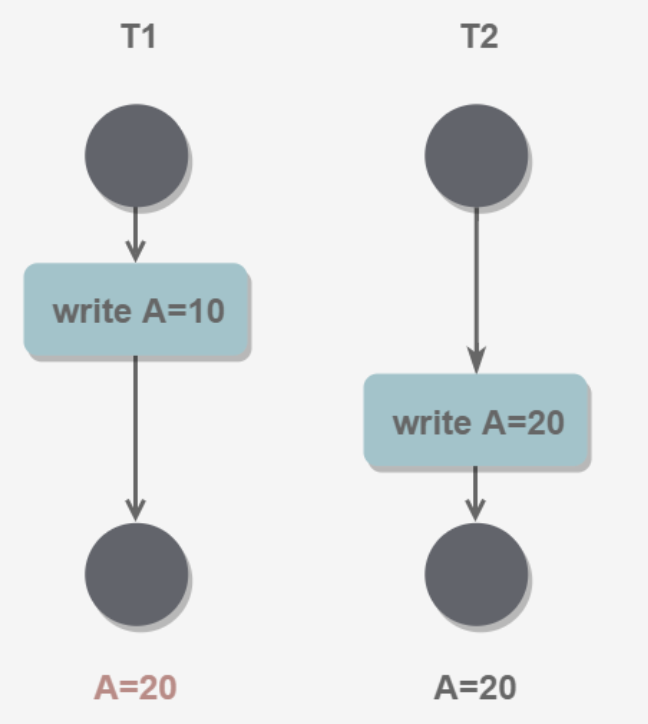
T1和T2两个事务都对数据A修改,T1先修改,T2后修改,T2的修改结果覆盖了T1的
2.读脏数据
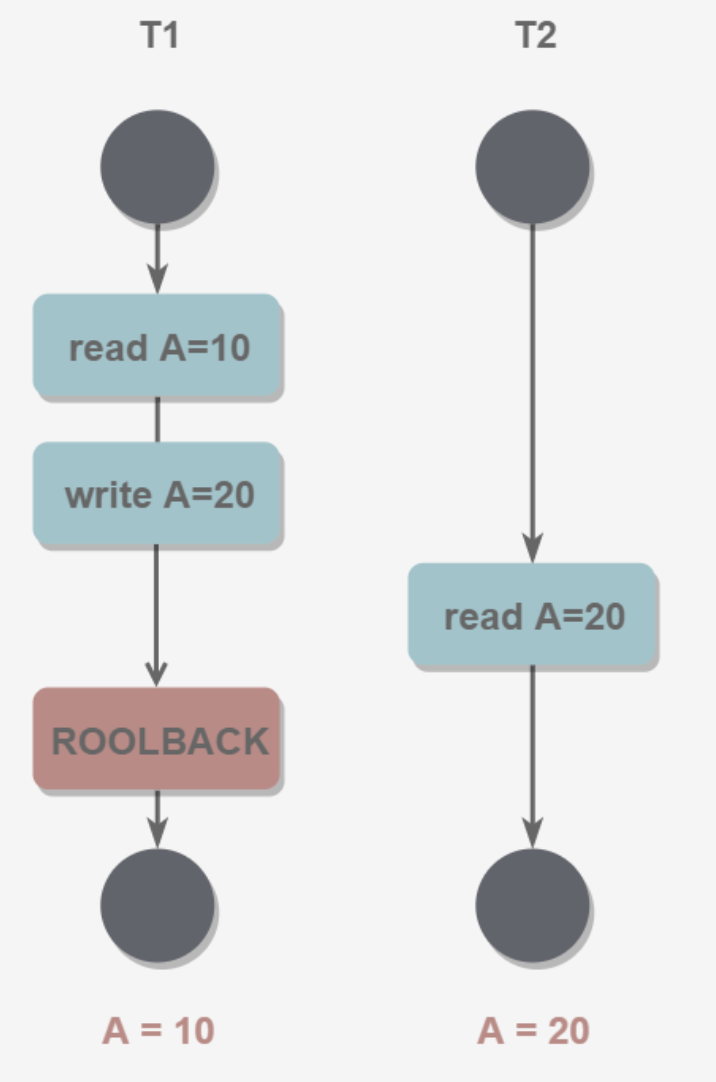
T1修改一个数据,T2随后读,如果T1修改失败回滚,T2读到的结果就是脏数据
3.不可重复读
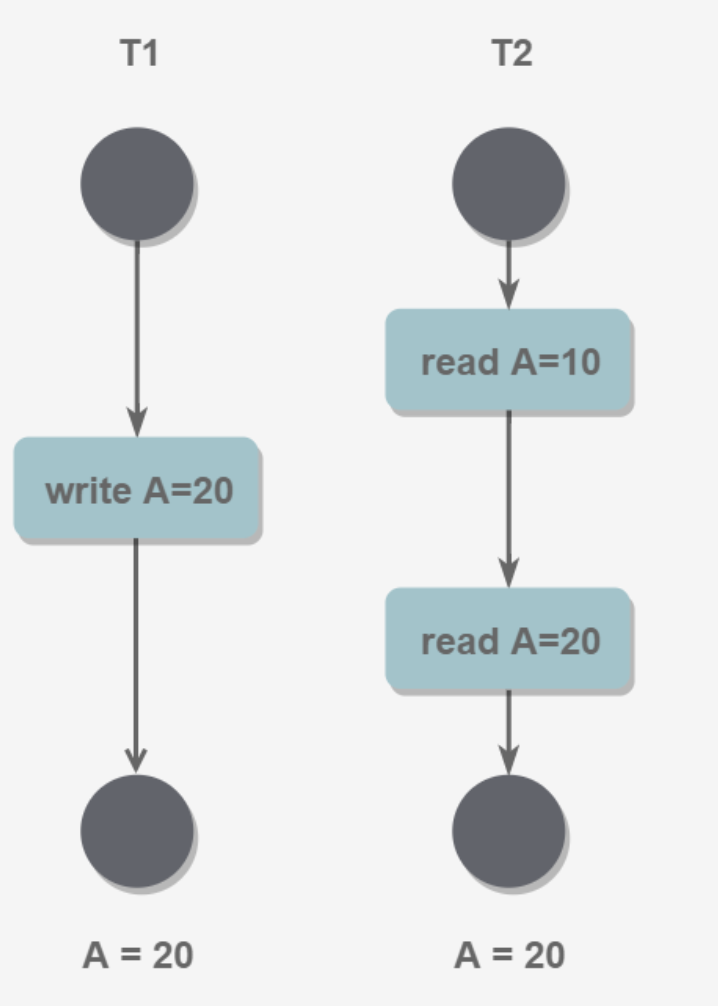
T2读取一个数据,T1做了修改,T2再次读取,这时候两次数据不一致。
4.幻影读
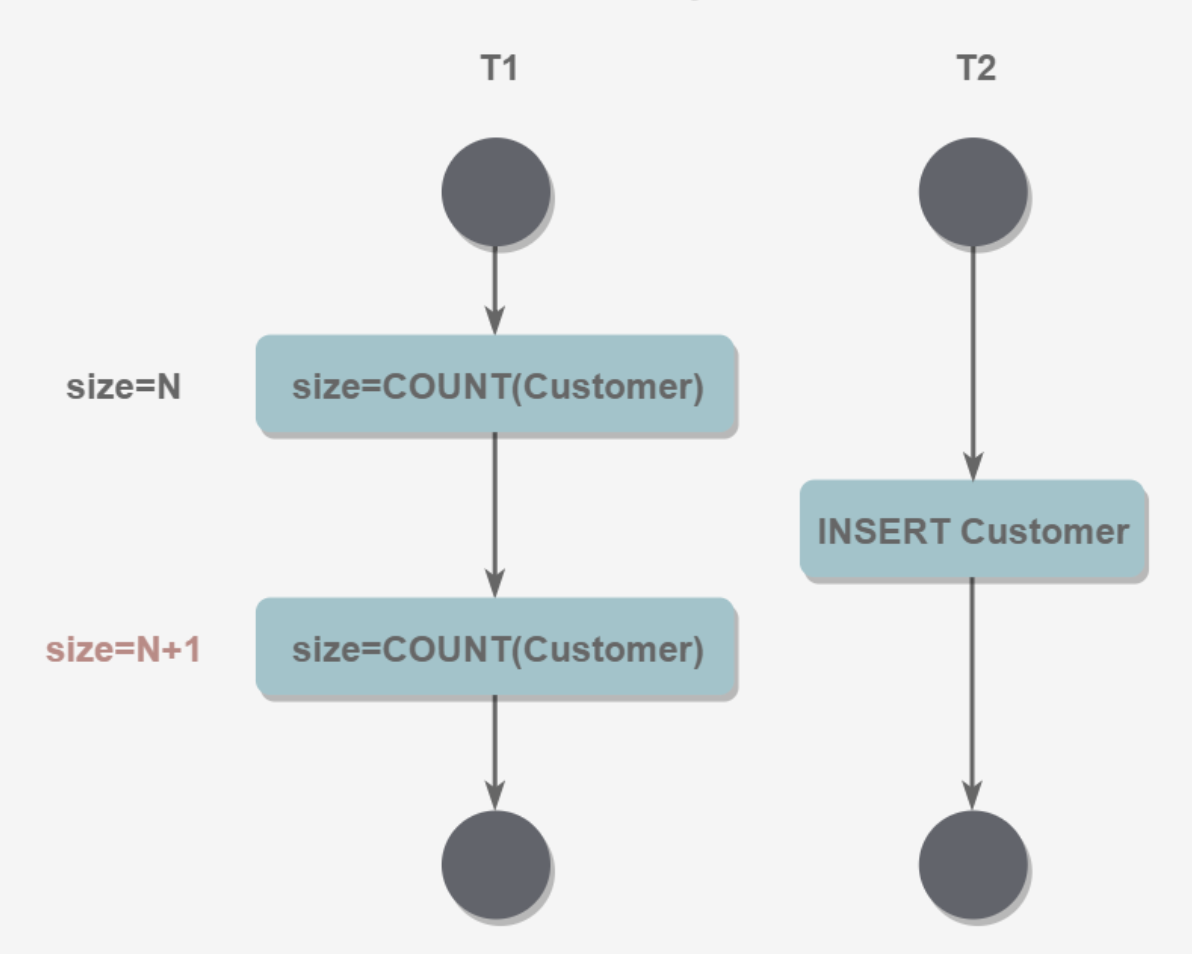
T1读取某个范围的数据,T2执行了插入操作,T1再次读取这个范围的数据,两次的结果不同。
产生并发不一致的主要原因是破坏了事务的隔离性。
三. 封锁
1. 封锁力度
1)应当尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能性就越小,系统的并发程度就越高。
2)加锁需要消耗资源,锁的各种操作(获取、释放、检查状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
3)在选择封锁粒度时,需要在锁开销和并发程度间做权衡。
2.封锁类型
1)读写锁
互斥锁(X锁,写锁),共享锁(S锁,读锁)。
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
3.封锁协议
1)三级封锁协议
一级封锁协议:事务T要修改数据A时,必须加X锁,直到T结束才能释放锁。 —— 解决丢失修改问题
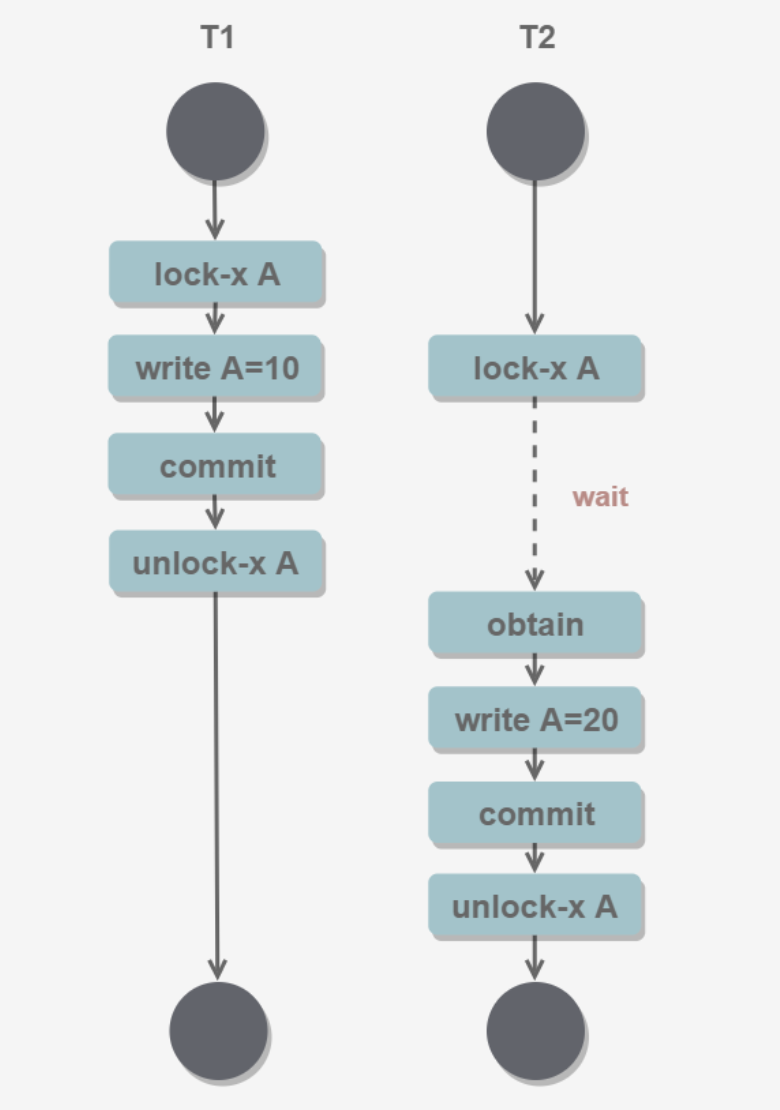
二级封锁协议: 读取数据A必须加S锁,读取完马上释放S锁。—— 可以解决读取脏数据问题

三级封锁协议:读取数据A时必须增加S锁,事务结束后释放。—— 解决不可重复读问题
2)两段锁协议
加锁和解锁分为两个阶段进行。
可串形化调度:通过并发控制,使得并发执行的事务结果与某个串形执行的事务结果相同。
四. 隔离级别
1.未提交读
事务中的修改,即使没有提交,其他事务也是可见的
2.提交读
一个事务只能读取已经提交的修改
3.可重复读
保证同一个事务中多次读取数据的结果是相同的
4.可串形化
强制事务串形化执行,这样多个事务互不干扰。该隔离级别需要加锁实现
五. 关系数据库设计理论
函数依赖
记A -> B 表示函数A决定函数B,也可以说B函数依赖于A。
如果 {A1, A2, ... , An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其他所有属性并且是最小的,那么该集合就称为键码。
对于 A -> B, 如果能找到A的真子集A', 使得 A' -> B, 那么 A-> B 就是部分函数依赖,否则就是完全函数依赖
对于 A -> B, B -> C, 那么 A -> C 是一个传递函数依赖。
异常
不符合范式的关系,会产生很多异常。
冗余数据:某个数据出现了多次
修改异常:修改了一个记录中的信息,另一个记录中的相同信息没有被修改
删除异常:删除了一个信息,其他信息也会丢失。
插入异常:插入一个新的数据信息(这个数据其他键值可能为空)
范式
范式理论是为了解决上面的四种异常,高级别范式依赖于低级别范式,1NF是最低级别的范式
第一范式:属性不可分
第二范式:每个非主属性完全依赖于键码
第三范式:表中所有的数据元素不但能唯一地被主关键字所标识,而且它们之间还必须相互独立,不存在其他的函数关系
六. ER图
有三个组成部分:实体、属性、联系,用来进行关系型数据库的设计。
实体的三种联系
一对一、一对多、多对多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号