



数据分析(三)
集合
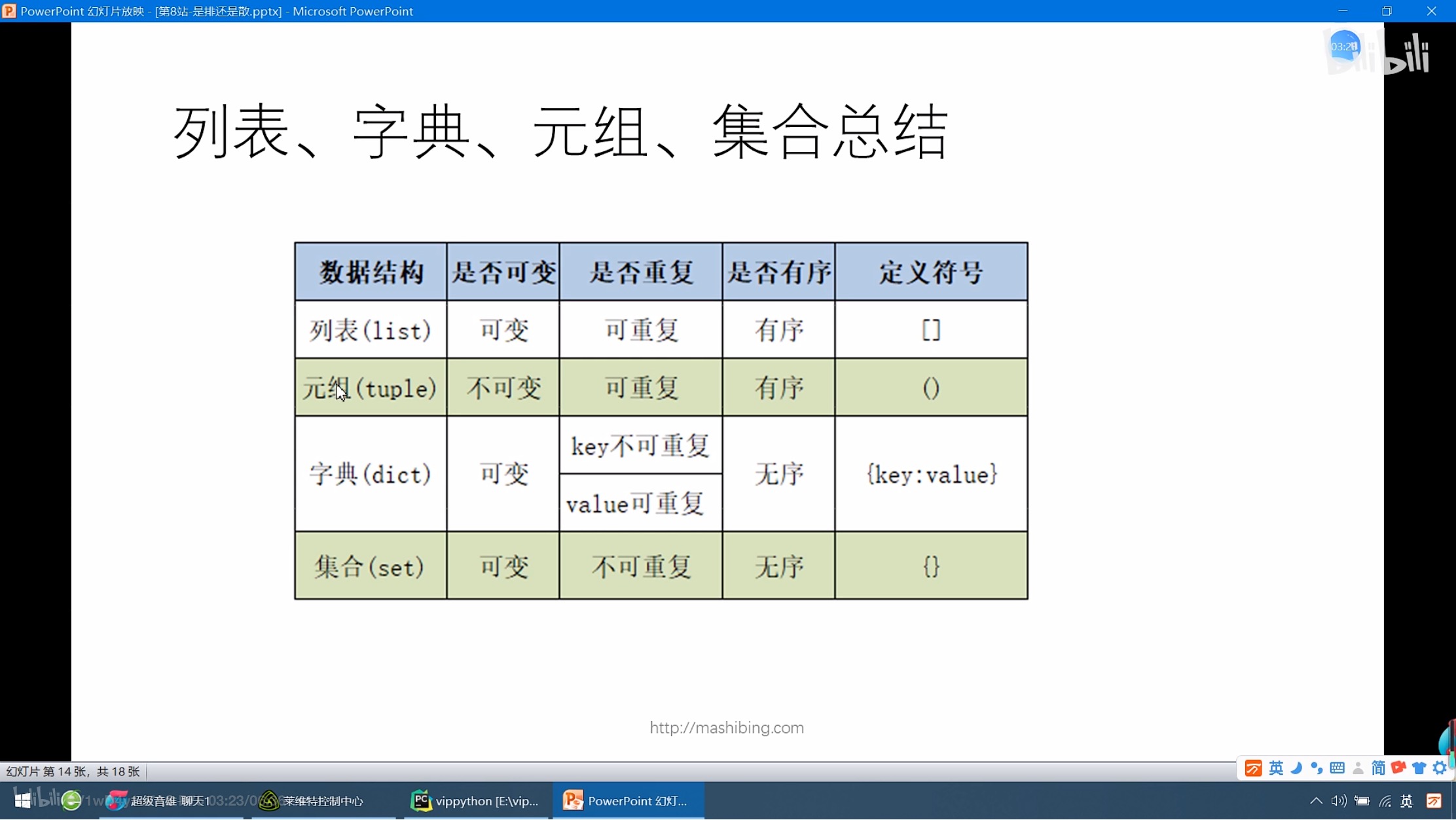
Python语言提供的内置数据结构
与列表、字典一样都属于可变类型的序列 (可变序列是可以进行增删改)
集合是没有value的字典 也是使用{}定义,但是没有value值,只有键
集合的创建方式
直接{} s={‘Python’,‘hello’,9} 集合中的元素不允许重复,会去掉重复的
使用内置函数set()
s=set(range(6)) 产生0到5的整数序列通过set转换为集合
s=set([3,4,56,78 ]) 产生列表,通过set将列表转为集合且去掉重复元素
s=set((3,4,56,78 )) 通过set将元组转换为集合,且集合是无序的,所以元组转换为集合时顺序可能会改变
s=set('Python') 可以通过set将字符串转换为集合中的元素 打印输出{‘n’,‘h’,‘p’,‘y’,‘t’,‘o’}
s=set({124,5,78,0}) 将集合通过set转为集合元素
s=set() 定义一个空集合 因为直接使用s={} 是字典空的定义
集合的判断操作
in 或者 not in
集合的新增操作
调用add()方法,依次添加一个元素
调用update()犯法付,至少添加一个元素
集合的删除操作
调用remove()方法,一次删除一个指定元素,指定元素不存在抛出异常KeyError
调用discard()方法,一次删除一个指定元素,指定元素不存在不抛出异常
调用pop()方法,一次只删除一个任意元素 删除的是什么不确定 不能指定参数
调用clear()方法,清空集合
s={10,23,1,45,5,34}
print(10 in s)
#集合元素的新增操作
s.add(99)
print(s)
s.update({200,400,300})
print(s)
s.update([9876,5347,3483]) #可以添加列表
print(s)
s.update((9876,5347,0,9)) #可以添加元组 重复的就自动去除了
print(s)
True
{1, 34, 99, 5, 23, 10, 45}
{1, 34, 99, 5, 200, 10, 300, 45, 400, 23}
{1, 34, 99, 5347, 5, 200, 10, 300, 45, 400, 9876, 23, 3483}
{0, 1, 34, 99, 5347, 5, 200, 9, 10, 300, 45, 400, 9876, 23, 3483}
集合间的关系 集合的元素是无序的,所以说元素的排序不会影响集合关系的判断
两个集合是否相等 使用运算符== 或者!=进行判断
一个集合是否是另一个集合的子集 调用方法issubset进行判断 s2.issubset(s1) s2是s1的子集吗
一个集合是否是另一个集合的超集 可以调用方法issuperset s2.issuperset(s1) s2是s1的超集吗
两个集合是否没有交集 可以调用方法isdisjoint进行判断 s2.isdiajoint(s1) s2和s1有交集吗 没有交集是True
集合的数学操作
交集 intersection 或者&
s1={10,20,30,40}
s2={20,30,40,50,60}
print(s1.intersection(s2)) #s1和s2的交集
print(s1 & s2) #&是并且求交集的意思 与intersection是等价的意思
并集 union 或者 |
print(s1.union(s2)) #s1和s2的交集
print(s1 | s2) # |是或 求并集
交和并集之后原来的集合是没有发生变化的
差集 difference
print(s1.difference(s2)) #s1有而s2没有的元素
print(s1-s2)
对称差集
print(s1.symmetric_difference(s2)) #s1有而s2没有的 和 s2有s1没有的
print(s1^s2)
集合的生成式
{i*i for i in range (1,10)}
将{}修改为【】就是列表生成式 没有元组生成式 且元素的排列是无序的
字符串
基本数据类型 不可变的字符序列
字符串驻留机制:仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,后续创建相同的字符串时,不会开辟新的空间,而是把该字符串的地址赋给新创建的变量
定义 单引号 双引号 三引号都可以
存在驻留机制的字符串(交互模式)
1. 字符串的长度为0或者1时
2. 符合标志符的字符串 含有字母数字下划线
3.字符串只在编译时进行驻留,而非运行时 运行时会开辟新的空间 a=‘abc’ b=‘’.join(['ab','c']) a is b (a和b的存储空间地址不一致) 因为c是在运行时形成的abc字符串,自然会开辟新空间 地址不一样 c=‘a’+‘bc’ a is c 这个的地址一样在编译时驻留
4.【-5,256】之间的整数数字
强制驻留
import sys
a=sys.intern(b) 强制两个字符指向同一个对象
PyCharm对字符串进行了优化处理
字符串驻留机制的优缺点 :避免重复的创建和销毁,提升效率和节约内存,但是拼接字符串和修改字符串是会比较影响性能的
需要字符串拼接时建议使用str类型的join方法,而非+ 只neew一次对象
字符串的查询操作
index() 查找子串substr第一次出现的位置,不存在抛出ValueError s.index('l')
rindex()查找子串substr最后一次出现的位置,如果查找的子串不存时,抛出ValueError s.rindex('l')
find() 查找子串substr第一次出现的位置,不存在返回-1 建议使用find
rfind()查找子串最后一次出现的位置,如果查找的子串不存在时,返回-1 建议使用rfind
字符串大小写转换操作 字符串转换之后会产生新的对象 原来是小写,再转换为小写之后还是会产生新的对象
upper() 把字符串中所有字符都转成大写字母
lower() 把字符串中所有字符都转成小写字母
swapcase()把字符串中所有大写字母转成小写字母,所有小写字母都转成大写字母
capitalize() 把第一个字符转换为大写,其余字符转换成小写
title()把每一个单词的第一个字符转换成大写,把每个单词的剩余字符转换成小写
字符串内容对齐操作的方法
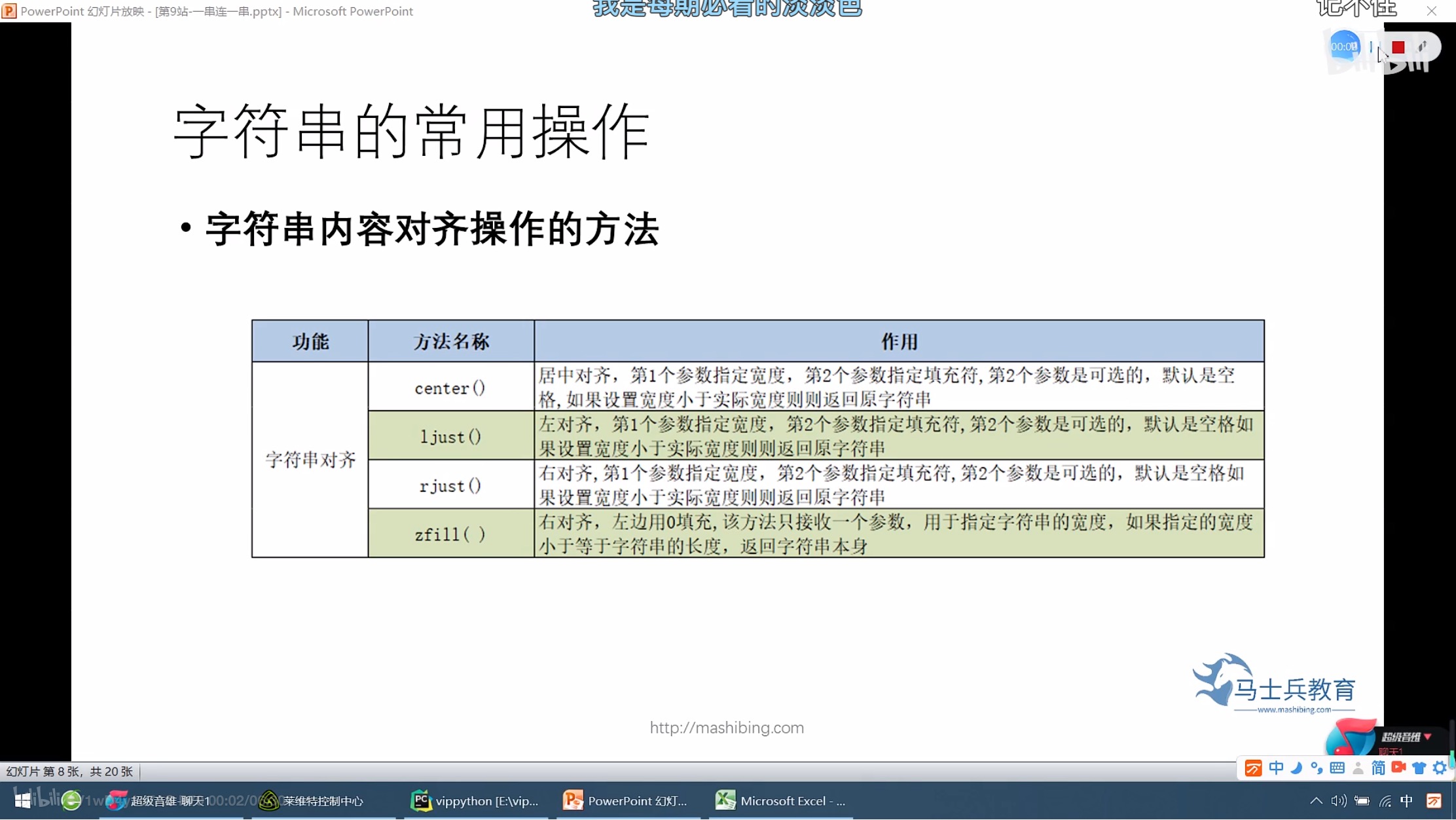
居中对齐
s='hello,Python' # 宽度20,原字符是12(12个字符),要扩充成20,20-12=8,左右各四个
print(s.center(20,'*'))
****hello,Python****
左对齐
print(s.ljust(20,'&'))
hello,Python&&&&&&&& #所有的填充符都是放在最右侧
print(s.ljust(10,'&'))
hello,Python #宽度小于原来的字符,输出原来的字符
右对齐
print(s.rjust(20,'&'))
&&&&&&&&hello,Python #所有的填充符都是放在最左侧
右对齐 0填充
print(s.zfill(20))
00000000hello,Python
字符串劈分操作的方法
split()从字符串的左边开始劈分,默认劈分操作的字符是空格字符串,返回的值都是一个列表
以通过参数sep指定劈分字符串的劈分符
通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分
rsplit()从字符串的右边开始劈分,默认劈分操作的字符是空格字符串,返回的值都是一个列表
以通过参数sep指定劈分字符串的劈分符
通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分
s='hello world Python'
lst=s.split()
print(lst)
['hello', 'world', 'Python'] 以s中的空格作为分隔符
s='hello,world,Python'
lst=s.split(sep=',') 将,作为分隔符
print(lst)
['hello', 'world', 'Python']
s='hello,world,Python'
lst=s.split(sep=',',maxsplit=1) 最大的分割次数为1
['hello', 'world,Python']
判断字符串操作的方法
isidentifier() 判断指定的字符串是不是合法的标志符 ‘张三_’是合法的字符,因为python默认把汉字识别为字母
isspace() 判断指定的字符串是否全部由空白字符组成(回车、换行,水平制表符,也属于空白字符)
isalpha() 判断指定的字符串是否全部由字母组成
isdecimal() 判断指定的字符串是否全部由十进制的数字组成 罗马数字不是十进制数字
isnumeric() 判断指定的字符串是否全部由数字组成 罗马数字也是数字,序列号也是数字
isalnum() 判断指定的字符串是否全部由字母和数字组成
字符串替换 replace() 第一个参数指定被替换的子串,第二个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,
调用该方法时可以通过第三个参数指定最大替换次数
s='hello,Python'
s.replace('Python','Java')用Java替换s中的Python
s='hello,Python,Python,Python,Python'
s.replace('Python','Java',2) 用java把python换掉,换前两次
字符串的 合并 join() 将列表或元组中的字符串合并成一个字符串
lst=['hello','java','python'] 列表
'|'.join(lst) 产生的结果是hello|java|python
‘’.join(lst) 产生的结果是hellojavapython
t=('hello','java','python') 元组
'|'.join(t) 产生的结果是hello|java|python
‘*’.join('Python') 产生的结果P*y*t*h*o*n
字符串的比较操作
运算符> >= < <= == !=
先比较两个字符串中的第一个字符串,如果相等继续比较下一个字符,依次比较下去,直到两个字符不等,,之后的字符将不再被比较
两个字符进行比较时,比较的是其原始值,调用函数ord可以得到指定字符的原始值,内置函数chr指定原始值可以得到其对应字符 chr(98)为b
==比较的是值是否相等 而is比较的是id是否相等(即内存地址)
字符串的切片操作
字符串时不可变类型 不具备增删改等操作 切片操作产生新的对象
s[:5] q 起始位置是从0开始 【0,4) 从s中切片之后,id改变
s[6:] 从6开始到末尾最后一个 从s中切片之后,id改变 切片[start:end:step] 步长为-1 倒序默认从字符串的最后一个位置开始,到字符串的第一 个位置结束
格式化字符串
一定格式输出的字符串
格式化字符串的两种方式
%作占位符, %s 字符串 %i或者%d 整数 %浮点数 ‘我的名字叫:%s,今年%d岁了‘ % (name,age)实际值
‘’%10d‘%99是宽度,左边前8个是空格最后两个位置是99
保留三位小数 ‘%.sf’ %3.1415926
同时表示宽度和精度‘%10.3f’ 10是宽度 .3是精度
name='张三'
age=20
print('我叫%s,今年%d岁' % (name,age))
{}作占位符,‘我的名字叫:{0},今年{1}岁了,我真的叫{0} ’.format(name,age) 0和1是索引
print('我叫{0},今年{1}岁了,我真的叫:{0}'.format (name,age))
字符串的编码转换
编码--将字符串转换成二进制数据 s=‘明月几时有’ print(s.encode(encoding='GBK)) #在GBK中一个中文占两个字符print(s.encode(encoding='UTF-8'))一个中文占三个字符
解码--将二进制数据转换成字符串数据byte=s.encode(encoding='GBK') 编码 byte.decode(encoding='GBK') byte二进制数据,解码 GBK编就用GBK解


 浙公网安备 33010602011771号
浙公网安备 33010602011771号