
面试
一、Redis怎么修改密码
第一种方法(命令行修改):
1、 运行redis
打开redis所在目录–>在目录行输入cmd然后回车—>输入redis-server.exe启动redis服务~
2、运行redis-cli.exe设置密码
另外打开一个cmd窗口–>输入redis-cli.exe回车—>config get requirepass获取密码(此时密码为空)—>config set requirepass 123456(设置密码123456)–>config get requirepass获取密码(此时提示需要密码)—>auth 123456(验证密码)—>config get requirepass获取密码(此时显示了刚设置好的密码)—>然后测试一下redis—>set name abc(加入姓名abc)—>get name(取出name)
3、提示
此方法修改的密码为临时密码,redis关闭后则失效,下次启动还需再次设置
第二种方法(配置文件修改)
1、修改配置文件
打开redis目录下的redis.windows.conf文件—>找到requirepass foobared位置,在下面添加一行requirepass+你想要的设置的密码(注意前面不要留空格)
二、Mybatis防sql注入、$加工后的sql语句什么样子?
mybatis是如何处理sql注入的?
假设mapper.xml文件中sql查询语句为:
<select id="findById" resultType="String">
select name from user where id = #{userid};
</select>
对应的接口为:
public String findById(@param("userId")String userId);
当传入的参数为3;drop table user; 当我们执行时可以看见打印的sql语句为:
select name from usre where id = ?;
不管输入何种参数时,都可以防止sql注入,因为mybatis底层实现了预编译,底层通过prepareStatement预编译实现类对当前传入的sql进行了预编译,这样就可以防止sql注入了。
如果将查询语句改写为:
<select id="findById" resultType = "String">
select name from user where id=${userid}
</select>
当输入参数为3;drop table user; 执行sql语句为
select name from user where id = 3;drop table user ;
mybatis没有进行预编译语句,它先进行了字符串拼接,然后进行了预编译。这个过程就是sql注入生效的过程。
总结
因此在编写mybatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止sql注入攻击。
三、Mybatis二级缓存
一、什么是缓存
缓存是存在于内存中的临时数据。
使用缓存减少和数据库的交互次数,提高执行效率。
MyBatis 也提供了对缓存的支持,分为一级缓存和二级缓存,来看下下面这张图:
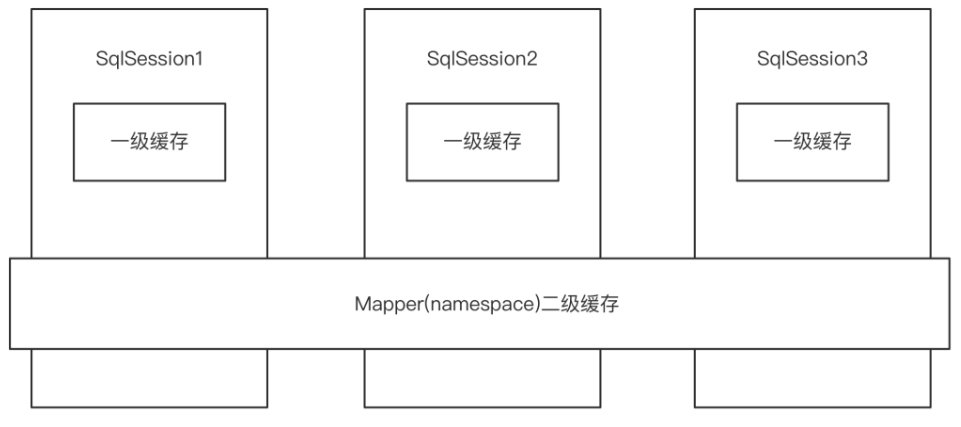
一级缓存是 SqlSession 级别的缓存。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的是 SqlSession 之间的缓存数据区(HashMap)是互相不影响。
二级缓存是 Mapper 级别的缓存,多个 SqlSession 去操作同一个 Mapper 的 sql 语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
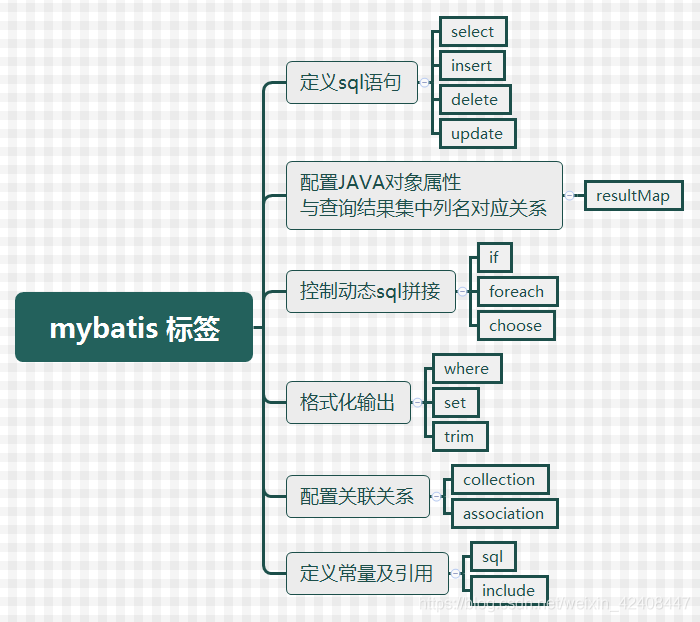
四、Mybatis标签
五、Mybatis与Jdbc区别
1、使用传统方式JDBC访问数据库:
(1)使用JDBC访问数据库有大量重复代码(比如注册驱动、获取连接、获取传输器、释放资源等);
(2)JDBC自身没有连接池,会频繁的创建连接和关闭连接,效率低;
(3)SQL是写死在程序中,一旦修改SQL,需要对类重新编译;
(4)对查询SQL执行后返回的ResultSet对象,需要手动处理,有时会特别麻烦;
...
2、使用mybatis框架访问数据库:
(1)Mybatis对JDBC对了封装,可以简化JDBC代码;
(2)Mybatis自身支持连接池(也可以配置其他的连接池),因此可以提高程序的效率;
(3)Mybatis是将SQL配置在mapper文件中,修改SQL只是修改配置文件,类不需要重新编译。
(4)对查询SQL执行后返回的ResultSet对象,Mybatis会帮我们处理,转换成Java对象。
...
总之,JDBC中所有的问题(代码繁琐、有太多重复代码、需要操作太多对象、释放资源、对结果的处理太麻烦等),在Mybatis框架中几乎都得到了解决!!
六、@ResponseBody
七、@autowired和@resource区别
@Autowired和@Resource区别
1.提供方不同
@Autowired 是Spring提供的,@Resource 是J2EE提供的。
2.装配时默认类型不同
@Autowired只按type装配,@Resource默认是按name装配。
3、使用区别
(1)@Autowired与@Resource都可以用来装配bean,都可以写在字段或setter方法上
(2)@Autowired默认按类型装配,默认情况下必须要求依赖对象存在,如果要允许null值,可以设置它的required属性为false。如果想使用名称装配可以结合@Qualifier注解进行使用。
(3)@Resource,默认按照名称进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行名称查找。如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource(name=“beanName”)=Resource
@Resource
由J2EE提供,默认按照Name自动注入
@Resource有两个重要的属性:name和type
Spring将@Resource注解的name属性解析为bean的名字,type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序:
(1)如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
(2)如果指定了name,则从Spring上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
(3)如果指定了type,则从Spring上下文中找到类型匹配的唯一bean进行装配,找不到或找到多个,都抛出异常
(4)如果既没指定name,也没指定type,则自动按照byName方式进行装配。如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入。
九、负载均衡策略
7 种负载均衡策略
1.轮询策略
轮询策略:RoundRobinRule,按照一定的顺序依次调用服务实例。比如一共有 3 个服务,第一次调用服务 1,第二次调用服务 2,第三次调用服务 3,依次类推。
2.权重策略
权重策略:WeightedResponseTimeRule,根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。它的实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大。
3.随机策略
随机策略:RandomRule,从服务提供者的列表中随机选择一个服务实例。
4.最小连接数策略
最小连接数策略:BestAvailableRule,也叫最小并发数策略,它是遍历服务提供者列表,选取连接数最小的⼀个服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取。
5.重试策略
重试策略:RetryRule,按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null。
6.可用性敏感策略
可用敏感性策略:AvailabilityFilteringRule,先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例。此策略的配置设置如下:
7.区域敏感策略
区域敏感策略:ZoneAvoidanceRule,根据服务所在区域(zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号