数美验证码-空间推测-爬虫
前言
因为要训练识别验证码的模型,需要爬取源数据。
如果需要其他的类型,自行修改
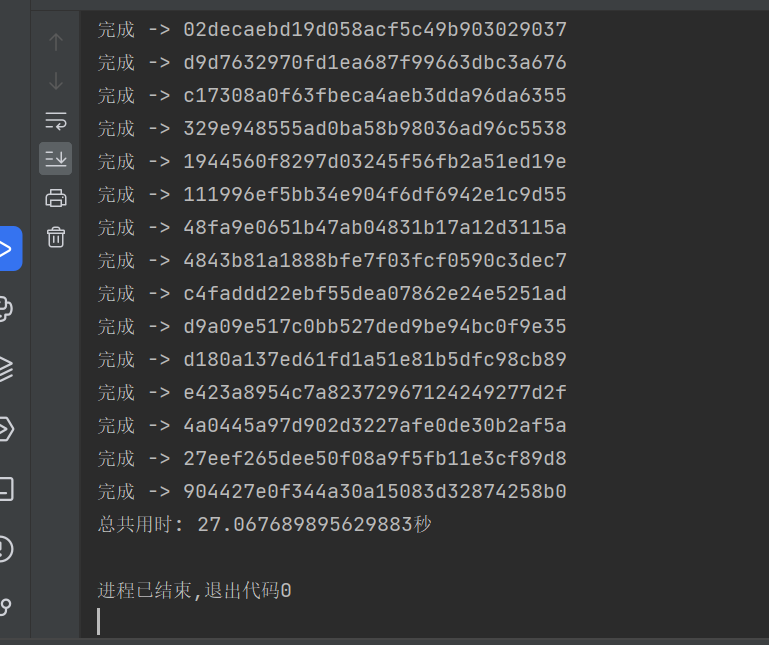
爬取结果

这边把图片跟文本命名一样的。
代码
import time
import json
import requests
def save_image_from_url(url, file_path):
response = requests.get(url)
with open(file_path, 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
"""
@author: xXinG
@dec: 爬取数美验证码空间 逻辑推理图片、文本
@time: 2023/4/26 19:50
"""
execute_count = 100 # 爬取条数
start_time = time.time()
for i in range(execute_count):
url = "https://captcha1.fengkongcloud.cn/ca/v1/register"
querys = {"callback": "0", "channel": "DEFAULT",
"captchaUuid": "20240426194937QdanEmbtwJrRaJwbdG", "rversion": "1.0.4", "lang": "zh-cn",
"data": "{}", "model": "spatial_select", "sdkver": "1.1.3", "organization": "d6tpAY1oV0Kv5jRSgxQr",
"appId": "default"}
response = requests.request("GET", url, params=querys)
data_str = response.text[2:-1] # 去掉字符串开头的'0('和结尾的')'
data_dict = json.loads(data_str) # 将字符串转换为字典
if data_dict['code'] == 1100:
url = data_dict['detail']['bg'] # 图片url, 需要加上 https://castatic.fengkongcloud.cn/
des = data_dict['detail']['order'] # 空间目标描述
last_slash_index = url.rfind('/')
jpg_start_index = url.find('.jpg')
name = url[last_slash_index + 1:jpg_start_index] # 图片命名
save_image_from_url('https://castatic.fengkongcloud.cn' + data_dict['detail']['bg'],
'./result/img/' + name + '.jpg')
with open("./result/label/" + name + '.txt', "w", encoding="utf-8") as f:
f.write(des[0])
print("完成 -> " + name)
end_time = time.time()
print("总共用时: " + str(end_time - start_time) + "秒")
这边测试爬取100张
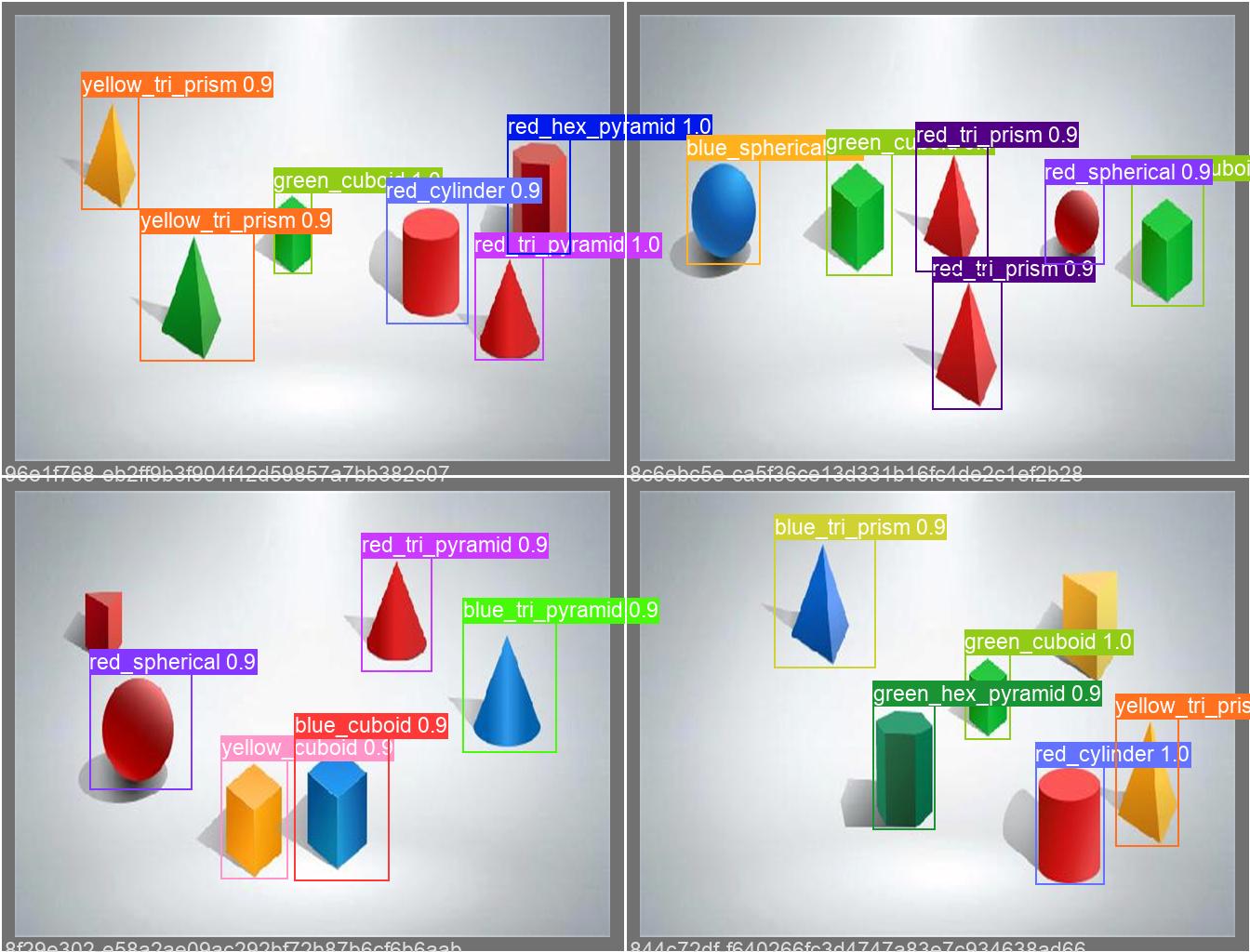
给大家看看训练好的模型 哈哈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号