

Dubbo学习系列之十六(ELK海量日志分析框架)
外卖公司如何匹配骑手和订单?淘宝如何进行商品推荐?或者读者兴趣匹配?还有海量数据存储搜索、实时日志分析、应用程序监控等场景,Elasticsearch或许可以提供一些思路,作为业界最具影响力的海量搜索与分析产品,搜索软件公司 Elastic 上市了!首日市值翻倍!Elastic 从小工具「逆袭」成为上市公司,依靠其技术影响者众多企业,并促进整个行业发展的模式变革,向众多渴望创业的程序员证明了一个道理:技术创业是可行的,并且有着良好的前景。你要不要试试呢?
准备:
Idea2019.03/Gradle5.6.2/JDK11.0.4/RHEL7.6/VMware15Pro/Lombok0.27/logback1.2.3/SpringBoot2.2.0RELEASE/ElasticSearch7.2.0/LogStash7.2.0/Kibana7.2.0/NodeJs10.14.2/npm6.4.1/Git2.18.0
难度:新手--战士--老兵--大师
目标:
1.Logback使用复习
2.Linux下ELK框架搭建
3.Springboot整合ELK实现海量日志处理框架
4.Springboot下使用ES的API
步骤:
为了遇见各种问题,同时保持时效性,我尽量使用最新的软件版本。代码地址:其中的day21,https://github.com/xiexiaobiao/dubbo-project.git
Part1 Linux下的ELK
1.先介绍下ELK套件:
- ElasticSearch:(以下简称ES)搜索引擎。基于Lucene打造,特点是分布式、零配置、自动发现、索引自动分片、索引副本机制,最方便的就是Restful接口。能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。
- Logstash:数据采集器。可同一时刻采集多来源的数据,以连续流传输,并能实时解析和转换数据,能自定义过滤器,最后将数据发送到指定存储库, 当然,ES 是其首选存储库。其采用可插拔框架,拥有 200 多个插件。可将不同的输入选择、过滤器和输出选择混合搭配。
- Kibana:ES数据可视化工具,如柱状图、线状图、饼图、旭日图等,这些类似于常用的报表工具,支持权限访问控制,还有特定的查询语法来进行复杂的查询操作。
其实:ES可以用作文档型存储,类似MongoDB,适用于非事务型分布式存储场景。API十分丰富,但也存在一定的难度和复杂度。
典型的 ELK 套件方案:

- Beats:如果考虑到机器负载问题,还有轻量级(相比Logstash)的beat组件级数据采集器,能从成千上万台机器和系统向 Logstash 或 ES 发送数据,Beats是一个系列,有Filebeat/Packetbeat/Winlogbeat/Heartbeat/Auditbeat等,用于采集不同来源类别的数据。如果再加上缓冲层,可演变为如下强大架构,并发能力更上一层楼!
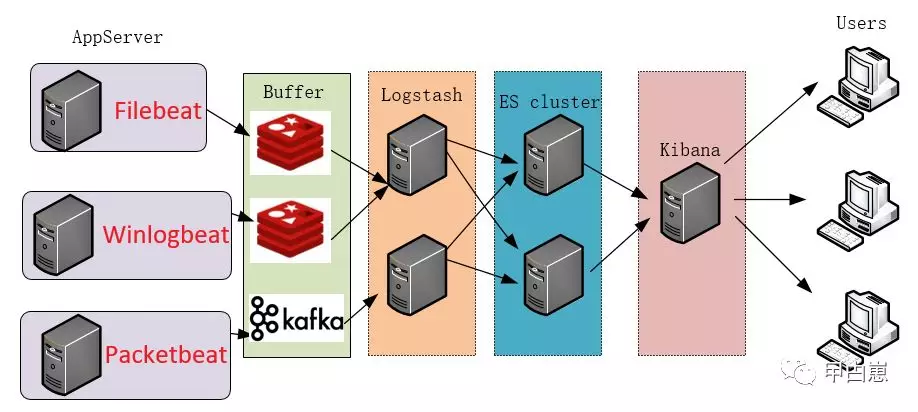
2.Linux虚拟机的安装、网络、文件共享、YUM安装见我下篇,或者网搜,想必进入这个文章的linux也该略有基础了。
3.我这里 ELK 三者全部安装在一台Linux虚拟机(IP:192.168.1.204)上,注意下载的ELK版本要一致,目前最新为V7.4.2,但下载实在蜗牛速度,只好先用点已有的旧货上场,抱歉!
4.开始ES的安装:下载elasticsearch-7.2.0-linux-x86_64.tar.gz,放/usr/elastic下,并解压,ES不能使用root用户启动,会提示错误!

切换为普通用户,并将文件主更新为普通用户,再启动:
[root@localhost ~]# chown -Rv biao /usr/elastic/
[biao@localhost usr]$ ./elastic/elasticsearch-7.2.0/bin/elasticsearch
5.首次启动测试:
[root@localhost ~]# curl localhost:9200
[root@localhost ~]# curl localhost:9300
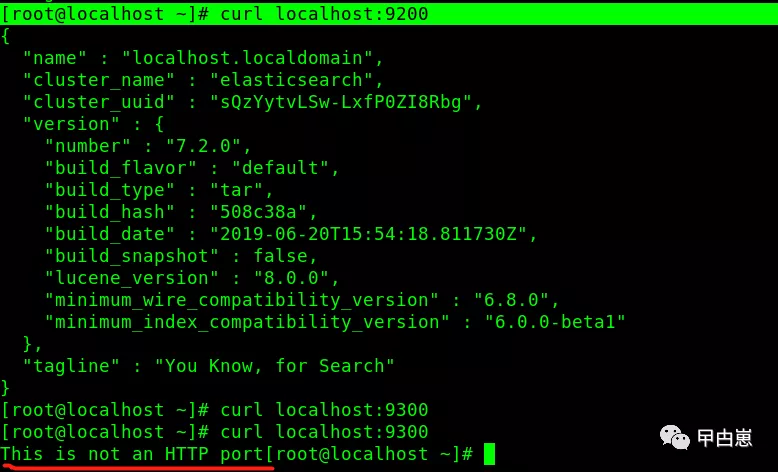
6.默认情况下,ES 只允许本机访问,如果需要远程访问,可以修改 ES 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,并将它的值改成所在OS的IP:192.168.1.204,然后重新启动 ES。
[root@localhost ~]# vim /usr/elastic/elasticsearch-7.2.0/config/elasticsearch.yml
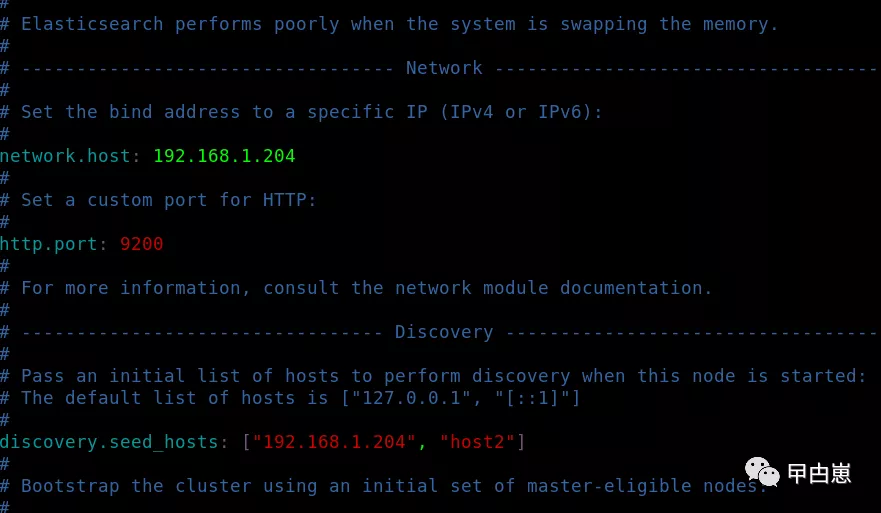
如果需要从window主机访问,注意打开Linux相应的端口或直接关闭防火墙, URL访问:http://192.168.1.204:9200/再次启动出现错误,提示有3个问题,各个击破!

每个进程最大同时打开文件数太小:
[root@localhost usr]# sysctl -w vm.max_map_count=262144
vm.max_map_count = 262144
ulimit 用于限制 shell 启动进程所占用的资源:
[root@localhost usr]# vim /etc/security/limits.conf
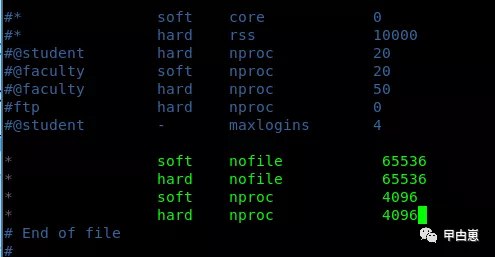
查看设置后的值:
[root@localhost usr]# ulimit -Hn
[root@localhost usr]# ulimit -Sn
最后设置一个seed_host,见步骤6中的第一图,按Ctrl+c退出。
7.开始安装elasticsearch-head:一款ES集群可视化管理工具,可直接操作ES的数据,这也太野了吧,生产中必须要加以限制!这个工具有多种方式安装,比如doker/plugin/npm等,因linux上环境欠缺,我就直接在window上使用npm安装了(window上先安装node.js环境即可使用npm),这其实是将elasticsearch-head独立运行,参考后面的(整合ELK整体目标架构图):
D盘根目录下,使用git bash命令,下载源码:
git clone git://github.com/mobz/elasticsearch-head.git
下载源码完成后CMD命令行操作:
C:\Users\KOOL>D: D:\>cd D:\elasticsearch-head D:\elasticsearch-head>npm install -g cnpm --registry=https://registry.npm.taobao.org D:\elasticsearch-head>npm install D:\elasticsearch-head>npm run start
如下图即为安装成功!
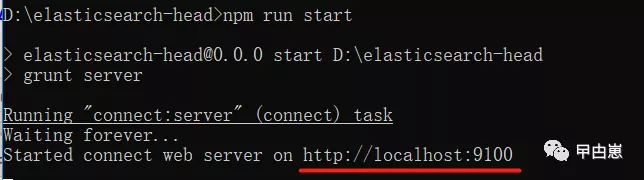
8.访问:http://localhost:9100/
输入ES的 IP+port --> connect, 如果此时显示空白,请先使用 http://192.168.1.204:9200/ 测试确保外部可以连接ES,然后查看:
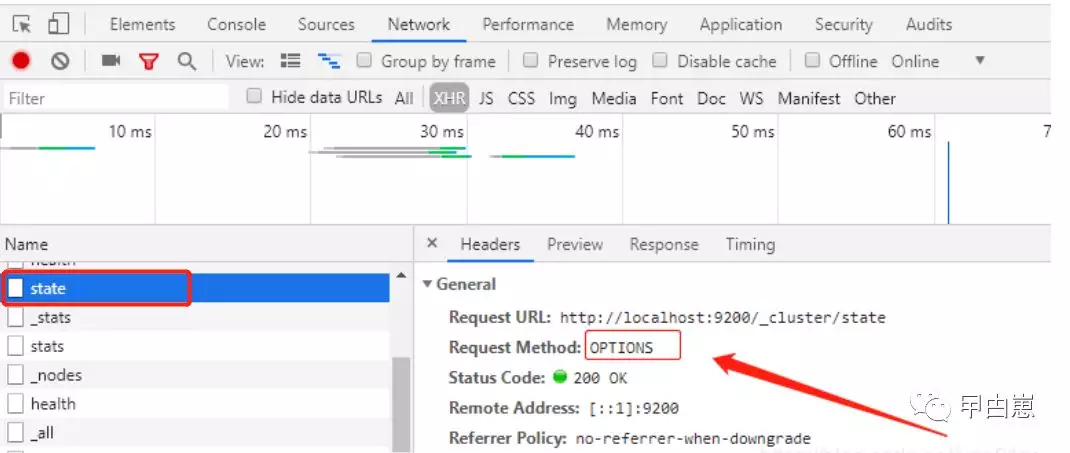
即可确认为跨域问题,需修改ES配置文件elasticsearch.yml,在文件末尾加入以下配置,注意冒号后的空格!
- http.cors.enabled: true #是否允许跨域
- http.cors.allow-origin: "*"

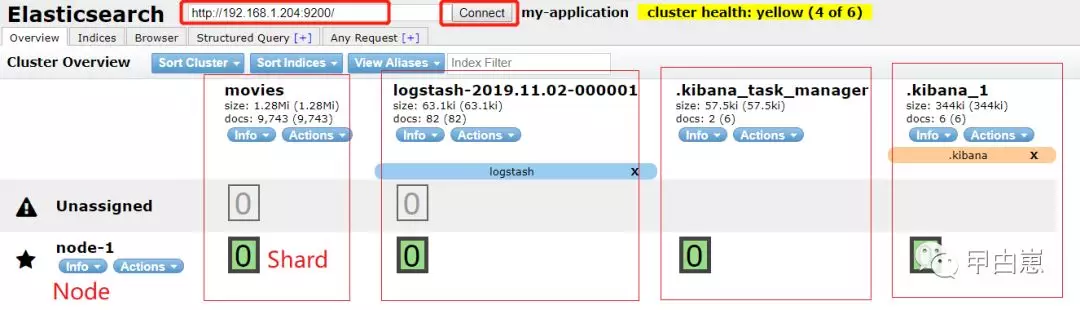
9.再重启ES,连接ES端,可以发现ES对logstash/kibana都做了存储,果然是自家的,特殊照顾,前缀有点号区分:
查看indices信息,以下为已经启动了Logstash和Kibana的状态:
node信息:
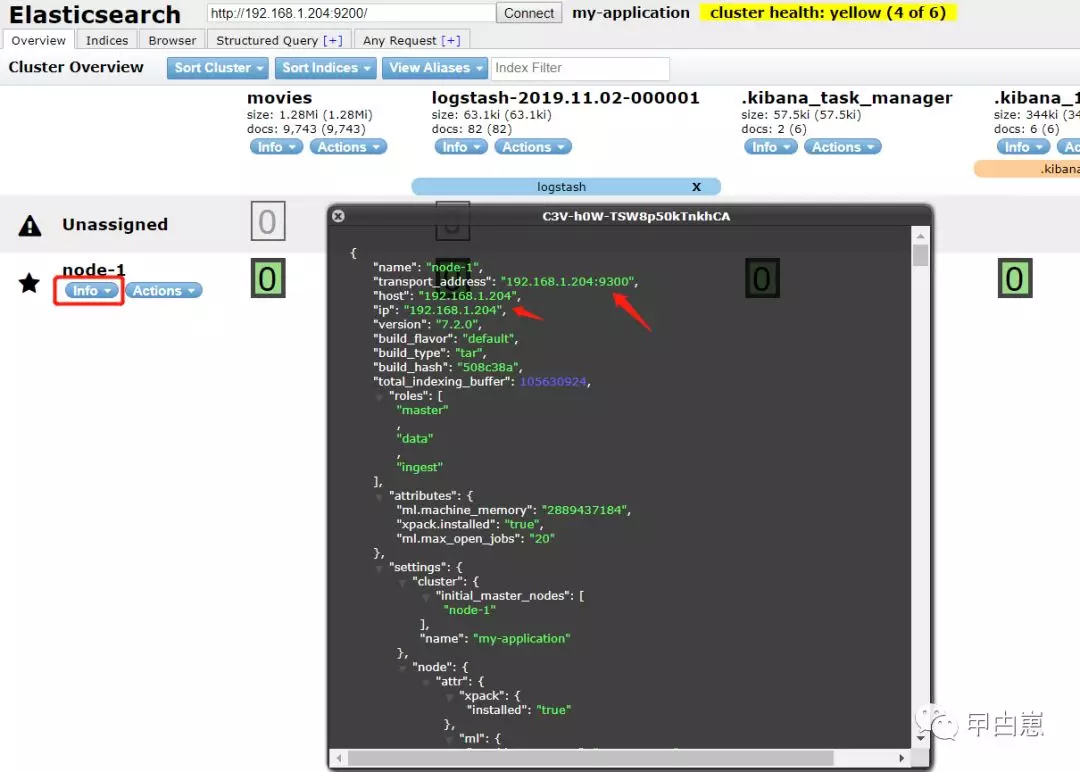
查看shard信息:
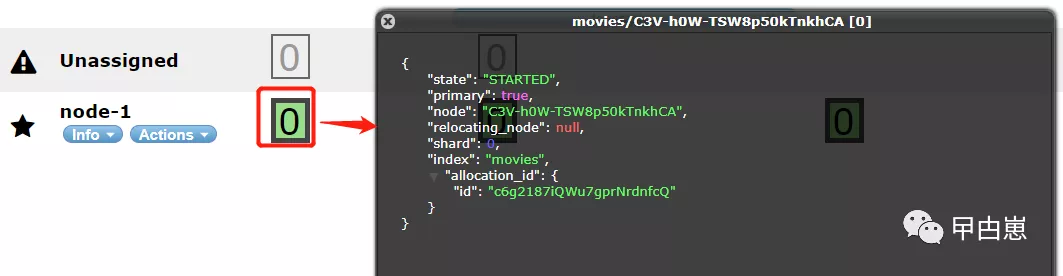
10.开始Logstash安装:
下载文件logstash-7.2.0.tar.gz,略,放/usr/logstash下,解压,测试logstash启动是否正常:
[root@localhost logstash]cd logstash-7.2.0
[root@localhost logstash-7.2.0]# ./bin/logstash -e 'input { stdin { } } output { stdout {} }'
启动后,输入hello world,如下则成功!ctrl+D退出。

另外,可以下载测试数据做测试:
[root@localhost logstash-7.2.0]# wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip [root@localhost logstash-7.2.0]# unzip ml-latest-small.zip [root@localhost logstash-7.2.0]# vim config/logstash-test.conf
logstash-test.conf内容如下:
input { file { path => "/usr/logstash/logstash-7.2.0/ml-latest-small/movies.csv" #注意修改为自己的目录 start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["id","content","genre"] } mutate { split => { "genre" => "|" } remove_field => ["path", "host","@timestamp","message"] } mutate { split => ["content", "("] add_field => { "title" => "%{[content][0]}"} add_field => { "year" => "%{[content][2]}"} } mutate { convert => { "year" => "integer" } strip => ["title"] remove_field => ["path", "host","@timestamp","message","content"] } } output { elasticsearch { hosts => http://192.168.1.204:9200 #注意修改为自己的ES index => "movies" document_id => "%{id}" } stdout {} }
运行下测试数据,注意先启动ES:
[root@localhost logstash-7.2.0]# ./bin/logstash -f /usr/logstash/logstash-7.2.0/config/logstash-test.conf
报错:There is insufficient memory for the Java Runtime Environment to continue.虚拟机的内存不够,如下命令查看内存情况:
[root@localhost logstash-7.2.0]# free -h
建议直接虚拟机修改为 4G 内存,再跑此测试数据!运行成功后,先放着。
11.开始Kibana安装:下载,略,kibana-7.2.0-linux-x86_64.tar.gz复制到目录/usr/kibana下,解压:
[root@localhost ~]# cp /mnt/hgfs/00sharetoVM/kibana-7.2.0-linux-x86_64.tar.gz /usr/kibana
以root启动会提示不能使用root运行,可使用加 --allow-root 参数解决,这里我直接换成普通用户:
[root@localhost usr]# chown -Rv biao /usr/kibana/ [biao@localhost kibana-7.2.0-linux-x86_64]$ pwd /usr/kibana/kibana-7.2.0-linux-x86_64 [biao@localhost kibana-7.2.0-linux-x86_64]$ vim config/kibana.yml
#以下为配置项目:
server.port: 5601 server.host: "192.168.1.204" #虚拟机的IP elasticsearch.hosts: ["http://192.168.1.204:9200"] kibana.index: ".kibana"
启动Kibana,注意先启动ES:
[biao@localhost kibana-7.2.0-linux-x86_64]$ ./bin/kibana
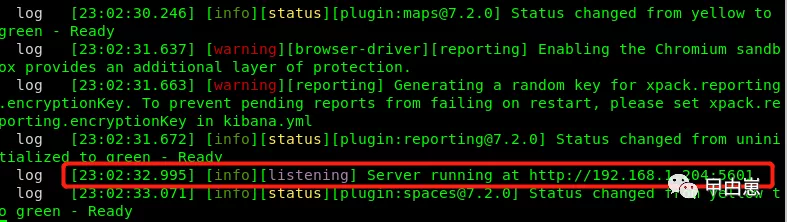
再配合上面处于启动状态的Logstash测试数据,外部打开URL地址:http://192.168.1.204:5601/
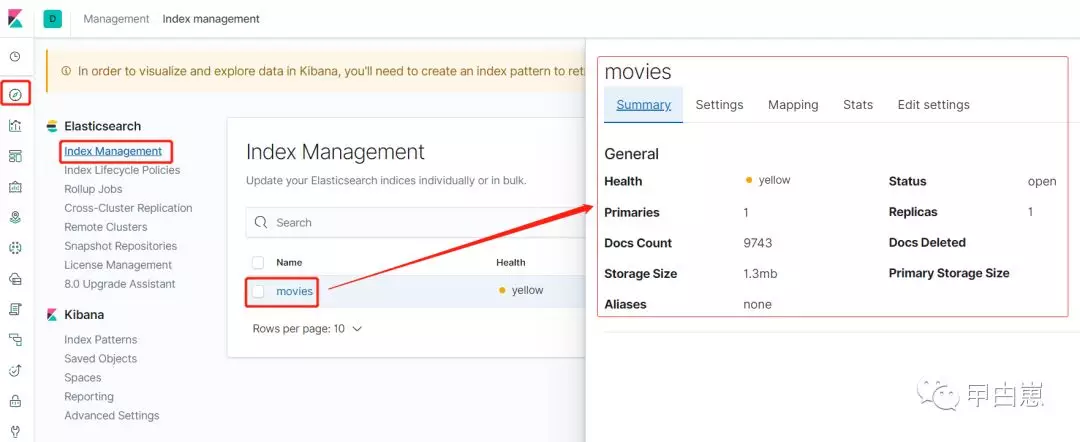
12.启动Kibana,如遇到错误:Elasticsearch cluster did not respond with license information.只需仔细配置 ES ,不是缺少xpack插件,7.X已经集成该插件了!
[biao@localhost elasticsearch-7.2.0]$ vim config/elasticsearch.yml
以下为配置项:
cluster.name: my-application node.name: node-1 path.data: /tmp/es/data path.logs: /tmp/es/logs network.host: 192.168.1.204 #建议不要写为网上的0.0.0.0 http.port: 9200 discovery.seed_hosts: ["192.168.1.204"] cluster.initial_master_nodes: ["node-1"]
Part2 验收测试
1.先实现Springboot应用整合ELK做日志处理:整体目标架构如下图:

2.创建springboot工程,我使用idea直接建一个简单的gradle project,终于摆脱前面的mall项目了!

3.引入依赖,非常建议逐步引入,使用过程中观察缺少依赖对应用的影响,这样能更好的学习各个组件的作用:
dependencies { testCompile group: 'junit', name: 'junit', version: '4.12' // https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-parent compile group: 'org.springframework.boot', name: 'spring-boot-starter-parent', version: '2.2.0.RELEASE', ext: 'pom' //Core starter, including auto-configuration support, logging and YAML compile group: 'org.springframework.boot', name: 'spring-boot-starter', version: '2.2.0.RELEASE' //Starter for testing Spring Boot applications with libraries including JUnit, Hamcrest and Mockito testCompile group: 'org.springframework.boot', name: 'spring-boot-starter-test', version: '2.2.0.RELEASE' //Starter for building web, including RESTful, applications using Spring MVC. Uses Tomcat as the default embedded container compile group: 'org.springframework.boot', name: 'spring-boot-starter-web', version: '2.2.0.RELEASE' // testCompile group: 'ch.qos.logback', name: 'logback-classic', version: '1.2.3' // https://mvnrepository.com/artifact/net.logstash.logback/logstash-logback-encoder compile group: 'net.logstash.logback', name: 'logstash-logback-encoder', version: '6.2' // 本来这里的scope应该为providedCompile,即只存在于编译和测试阶段,但似乎gradle无法识别,maven环境下未测试 compile group: 'org.projectlombok', name: 'lombok', version: '1.18.10' // https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client compile group: 'org.elasticsearch.client', name: 'elasticsearch-rest-high-level-client', version: '7.2.0' // https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch compile group: 'org.elasticsearch', name: 'elasticsearch', version: '7.2.0' // https://mvnrepository.com/artifact/org.elasticsearch.client/transport compile group: 'org.elasticsearch.client', name: 'transport', version: '7.2.0' }
4.创建类,注意这里直接将Controller放入口类ApplicationMain里面的,简单粗暴!
@RestController @SpringBootApplication //@Slf4j public class ApplicationMain { private final Logger log = LoggerFactory.getLogger(ApplicationMain.class); public static void main(String[] args) { SpringApplication.run(ApplicationMain.class,args); System.out.println("ELK Application started.>>>>>>>>>>>>>>>>>>>>>>>>>>>"); } @RequestMapping("/test") public String test() throws InterruptedException { for (int i = 0; i < 10; i++) { Thread.sleep(1000); log.info("log from ELK app time: {}",System.currentTimeMillis()); } return "ELK test success"; } }
5.创建logback-spring文件,再复习下logback的使用,SLF4J是集合了各种日志组件的框架,使用了门面模式,appender/logger/root是其中三大件,这里就是使用logback将日志传给Logstash。另外,我还定义了一个file类型的log输出,可以看到项目代码所在的目录下的log文件:
<?xml version="1.0" encoding="UTF-8"?>
<!--该日志将日志级别不同的log信息保存到不同的文件中 -->
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<!--springProperty:在properties/yml文件中找到对应的配置项 -->
<springProperty scope="context" name="springAppName" source="spring.application.name" />
<springProperty scope="context" name="logFilePath" source="logging.config.path" />
<!-- 日志在工程中的输出位置 -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}" />
<!-- 控制台的日志输出样式 -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" />
<!-- 控制台输出 appender-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<!-- 日志输出编码 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- 为logstash输出的JSON格式的Appender -->
<appender name="logstash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.1.204:9665</destination>
<!-- 日志输出编码 -->
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<!--文件格式输出appender-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--定义日志输出的路径-->
<!--这里的scheduler.manager.server.home 没有在上面的配置中设定,所以会使用java启动时配置的值-->
<!--比如通过 java -Dscheduler.manager.server.home=/path/to XXXX 配置该属性-->
<file>${logging.path}/spring-boot/elk.log</file>
<!--定义日志滚动的策略-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--定义文件滚动时的文件名的格式-->
<fileNamePattern>${scheduler.manager.server.home}/logs/${app.name}.%d{yyyy-MM-dd.HH}.log
</fileNamePattern>
<!--60天的时间周期,日志量最大20GB-->
<maxHistory>60</maxHistory>
<!-- 该属性在 1.1.6版本后 才开始支持-->
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<!--每个日志文件最大100MB-->
<maxFileSize>100MB</maxFileSize>
</triggeringPolicy>
<!--定义输出格式-->
<encoder>
<pattern>%d [%thread] %-5level %logger{36} [%file : %line] - %msg%n</pattern>
</encoder>
</appender>
<!--logger 用来设置某一个包或者具体的某一个类的日志打印级别以及指定appender-->
<!--通过 LoggerFactory.getLogger("mytest") 可以获取到这个logger-->
<!--由于这个logger自动继承了root的appender,root中已经有stdout的appender了,自己这边又引入了stdout的appender-->
<!--如果没有设置 additivity="false" ,就会导致一条日志在控制台输出两次的情况,通过appender-ref做好分工,root负责console和logstash
此logger负责file输出-->
<!--additivity表示要不要使用rootLogger配置的appender进行输出-->
<logger name="test" level="INFO" additivity="false">
<appender-ref ref="file"/>
</logger>
<!-- 根logger,也是一种logger,且只有一个level属性 -->
<root level="INFO">
<appender-ref ref="console" />
<appender-ref ref="logstash" />
</root>
</configuration>
6.创建application.yml文件,用于上面的文件中做值引用:
spring:
application:
name: ELK Application
logging:
config:
path: ./logs
7.新建一个logstash启动配置文件:
[root@localhost logstash-7.2.0]# vim config/logstash-java.conf
内容如下,注意这里的port是应用接入的端口,output则是ES:
input{ tcp { port => 9665 codec => json_lines } } output{ elasticsearch{ hosts => ["192.168.1.204:9200"] } }
8.启动logstash:
[root@localhost logstash-7.2.0]# ./bin/logstash -f /usr/logstash/logstash-7.2.0/config/logstash-java.conf
如应用启动后出现错误:
Log destination 192.168.1.204:2004: connection failed. java.net.ConnectException: Connection refused: connect
请仔细检查logstash-java.conf 和logback-spring.xml 的端口配置,必须一致!
9.启动顺序:
ES --> Kibana --> Logstash --> ELK Application
10.URL访问:http://localhost:8080/test,应用产生log:
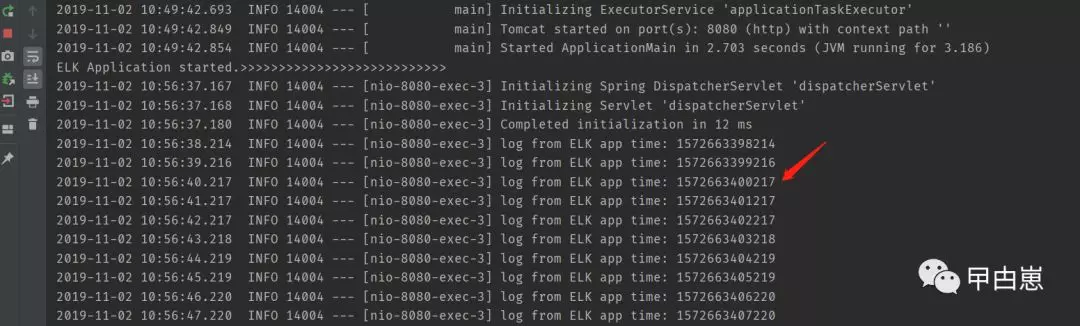
URL访问Kibana ,略作下配置:http://192.168.1.204:5601/

下一步:

下一步:
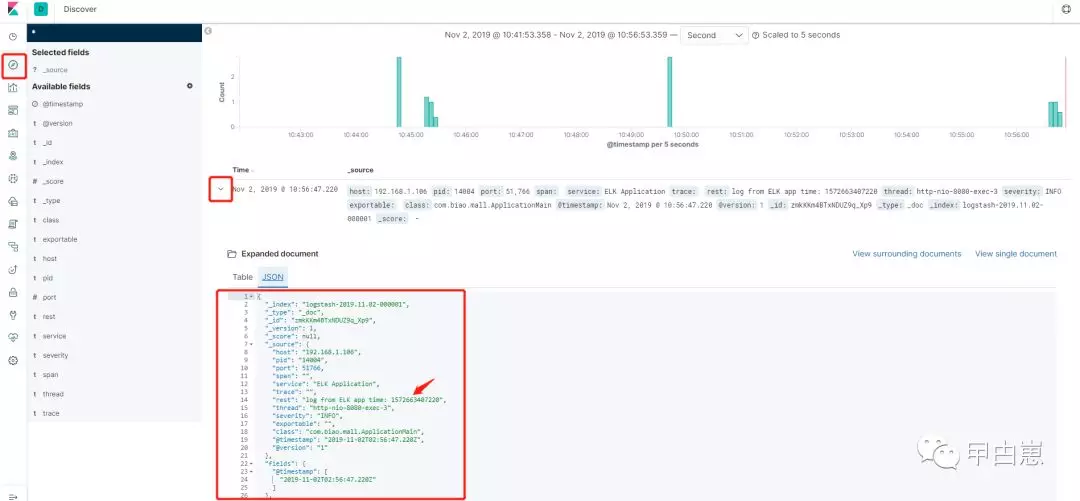
至此,海量日志分析框架完成!哪来的海量???这还不简单,上面的代码中循环 i 改为一百亿,去掉sleep!特此声明,对海量实验结果概不负责!至于kibana那些丰富多彩的展现和KQL查询,各位自行去探索吧!
11.来操作一把 ES Java API:
官方文档中有使用 org.elasticsearch.client.transport.TransportClient 做 ES 的外部 client ,再去操作ES,但使用后却发现已经 deprecated !换一个吧,我找到io.searchbox.client.JestClient,结果最新是2018年的,这?!再进行寻找一番,有个 org.elasticsearch.client.RestHighLevelClient 是最新的,且支持同步和异步调用,赶紧又换掉前面的,唉,就像猴子下山一样,好累,代码换了三波!这里只是使用了一个保存API,其他还有很多,可参考官网,使用方式类似。
代码就是在ApplicationMain中再添加一个APItest测试方法:
@RequestMapping("/api")
public String APItest() throws InterruptedException, IOException {
/** scheme 选项 http/tcp
* 1. java客户端的方式是以tcp协议在9300端口上进行通信
* 2. http客户端的方式是以http协议在9200端口上进行通信
*/
RestHighLevelClient client = new RestHighLevelClient(
//builder可以继续添加多个HttpHost
RestClient.builder(
new HttpHost("192.168.1.204", 9200, "http")));
/** 有四种不同的方式来产生JSON格式的文档(document)
.Manually (aka do it yourself) using native byte[] or as a String
.Using a Map that will be automatically converted to its JSON equivalent
.Using a third party library to serialize your beans such as Jackson
.Using built-in helpers XContentFactory.jsonBuilder()
*/
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("user", "biao");
builder.timeField("postDate", new Date());
builder.field("message", "trying out Elasticsearch");
}
builder.endObject();
String index = "my_temp_index";
IndexRequest indexRequest = new IndexRequest(index)
.id("1")
.timeout(TimeValue.timeValueSeconds(1))
.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL)
.opType(DocWriteRequest.OpType.INDEX)
.source(builder);
//Synchronous execution
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//asynchronous execution,
// client.indexAsync(indexRequest, RequestOptions.DEFAULT, listener);
client.close();
return "ELK API test success";
}
ActionListener listener = new ActionListener() {
@Override
public void onResponse(Object o) {
System.out.println("ELK API ASYN test success");
}
@Override
public void onFailure(Exception e) {
System.out.println("ELK API ASYN test failed");
}
};
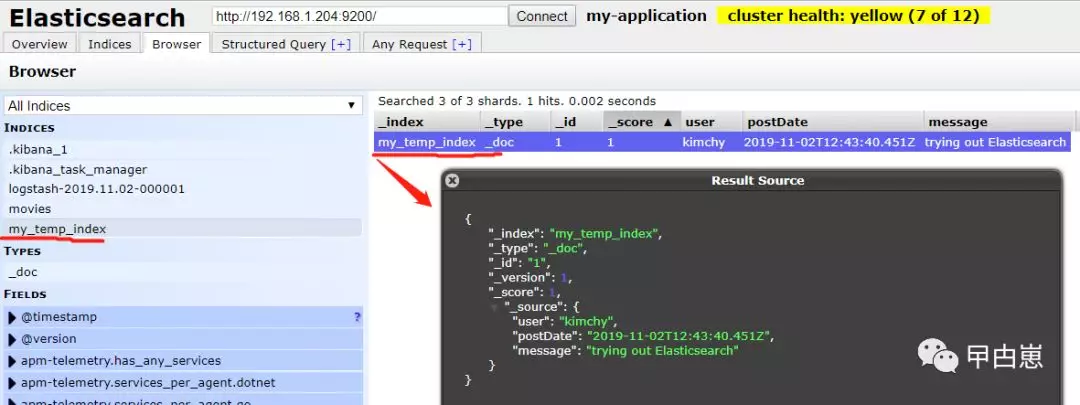
同步测试:URL访问:http://localhost:8080/api

结果如下,Index保存成功,达到测试目标!
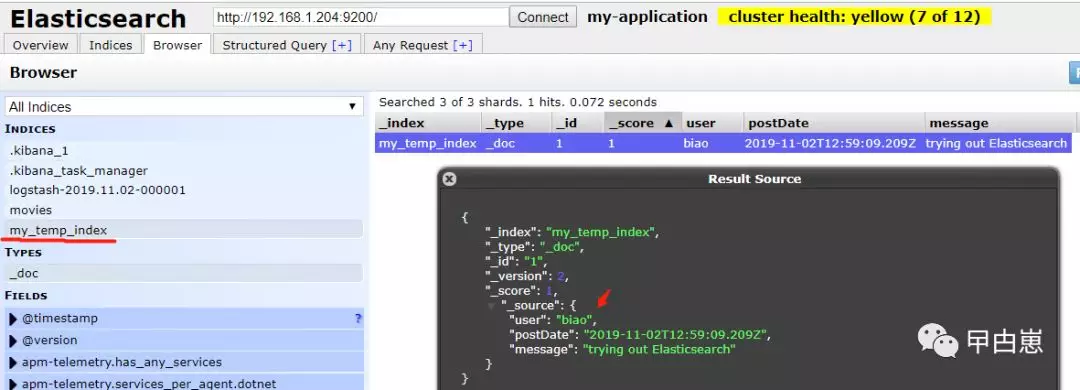
异步测试:特别注意要将 client.close() 注释掉,并实现 ActionListener 类:URL访问:http://localhost:8080/api
结果如下,Index保存成功,覆盖了上面同步测试生成的index内容(是否覆盖可配置),达到测试目标!

复盘记:
1.ELK是一个可伸缩的框架,可按需进行裁剪,其中Logstash是一个 点对点 的信息采集器,如果流量巨大,可以加入MQ或Redis缓冲,
2.ES出身就是分布式的,所以集群方式可以做到多Node,多Shard,使用主从复制与冗余存储备份策略,自动平衡数据存储点负载,
3.对于ES的概念,有个很好的对比图,如果用过Mongodb,应该就好理解,只注意“文档”一词,不是指我们常说的word/pdf文件,而是一种有格式的描述型结构化数据,比如JSON:

4.再次注意ELK中各conf文件的IP绑定概念,不建议使用0.0.0.0,事实上生产环境也不会直接全开!具体分析我在前篇《Linux下Redis集群》中有解释,这里的bind类似,不再赘述。
5.ES分库分片设置:
- number_of_shards:每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。
- number_of_replicas:每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
以下使用ES-Head方式,创建一个index,并配置为一个node上3个shard,每个shard有2个replica:
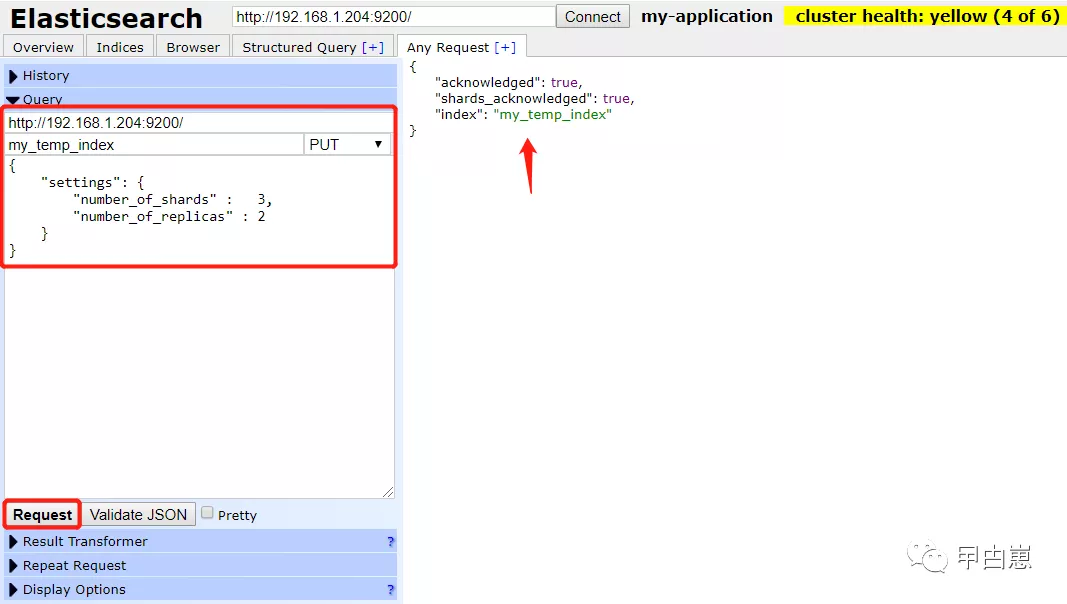
以上也可使用CURL方式:
curl -X PUT "localhost:9200/my_temp_index?pretty" -H 'Content-Type: application/json' -d' { "settings": { "number_of_shards" : 1, "number_of_replicas" : 0 } } '
具体展现如下:
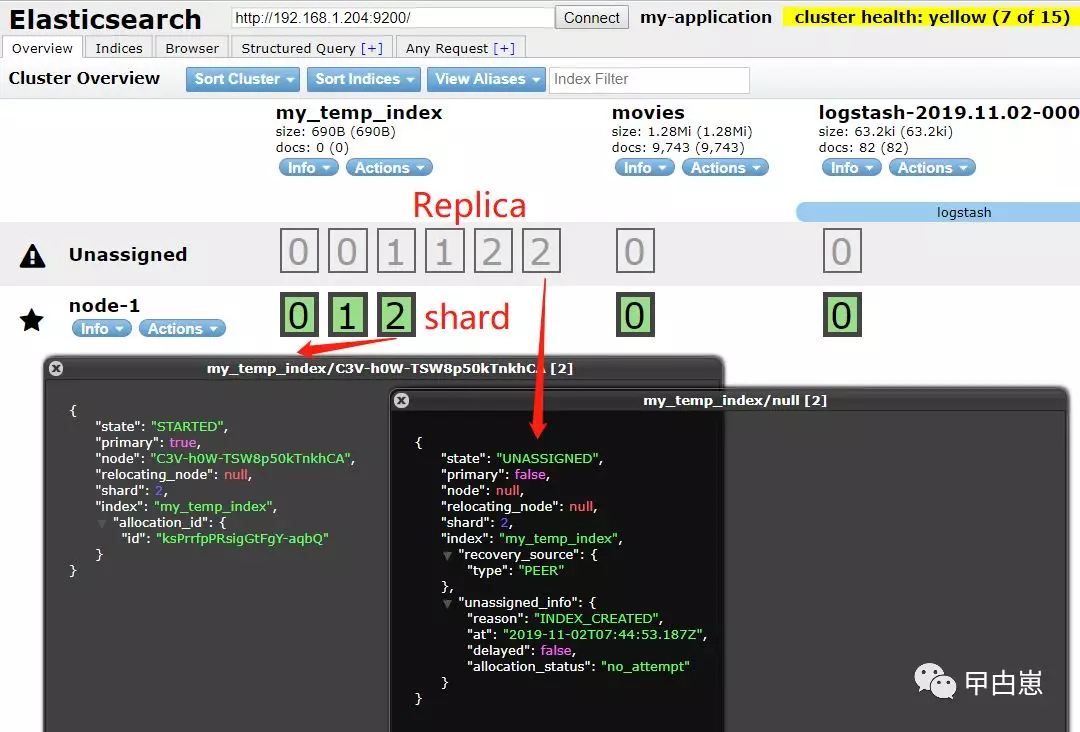
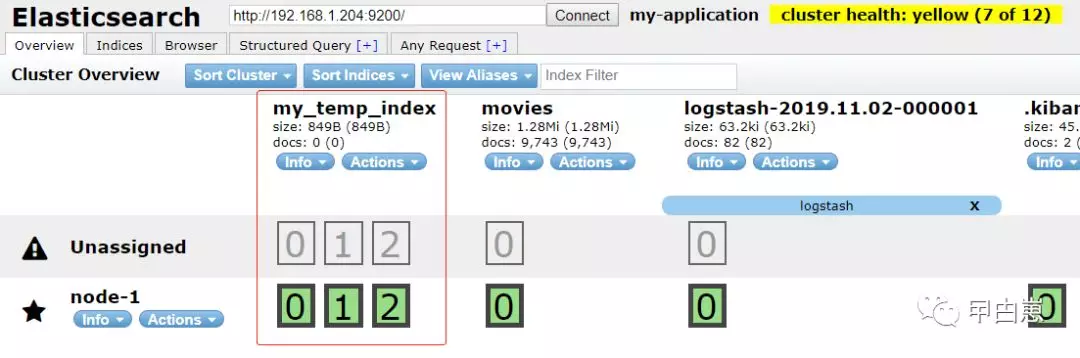
然后,我们可以用 update-index-settings API 动态修改副本数,也可使用CURL方式:

修改后的效果:
5.ES为什么快!?核心就是倒序索引和特殊的文件压缩,至于详细,内容略多,在此仅作个引子。
6.本文完全没用到dubbo,只是为了标题的连贯,故保留。
本文结束!
推荐阅读:
- Linux下Redis集群
- Dubbo学习系列之十五(Seata分布式事务方案TCC模式)
- Dubbo学习系列之十四(Seata分布式事务方案AT模式)
- Dubbo学习系列之十三(Mycat数据库代理)
- Dubbo学习系列之十二(Quartz任务调度)
我的微信公众号,只写原创文章!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号