第2周 神经网络基础题numpy运用
 本章主要联系python中的numpy的相关函数,包含exp()、sum()、dot()等,来解决相关的sigmoid函数,S型梯度,广播和softmax函数以及损失函数
本章主要联系python中的numpy的相关函数,包含exp()、sum()、dot()等,来解决相关的sigmoid函数,S型梯度,广播和softmax函数以及损失函数
1.使用 Numpy 的 Python 基础知识
import math
def basic_sigmoid(x):
s = 1/(1+math.exp(-x)) #math.exp(x):为e的x次方
print(s)
0.9525741268224334
basic_sigmoid(3)
0.9525741268224334
a = [1,2,3]
# basic_sigmoid(a) #会报错
import numpy as np
x = np.array([1,2,3]) #各种序列(如列表、元组等)转换为 NumPy 数组
print(x+3)
[4 5 6]
x = np.array([1,2,3])
print(np.exp(x)) #np.exp(x):求的是e的x次方,可以是列表形式
[ 2.71828183 7.3890561 20.08553692]
1.1 使用 numpy 实现 sigmoid 函数。
x 现在可以是实数、向量或矩阵。我们在 numpy 中用来表示这些形状(向量、矩阵等)的数据结构称为 numpy 数组。您现在不需要了解更多信息。
sigmoid函数:sigmoid(x)=1/(1+e^-x)
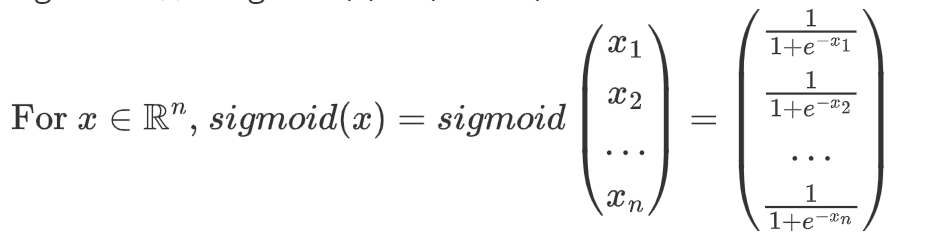
np.array([1,2,3]) #各种序列(如列表、元组等)转换为 NumPy 数组
np.exp(x):求的是e的x次方,可以是列表形式
解题用的函数
np.array([1,2,3]) #各种序列(如列表、元组等)转换为 NumPy 数组
np.exp(x):求的是e的x次方,可以是列表形式
import numpy as np
def sigmoid(x):
s = 1/(1+np.exp(-x))
return s
x = np.array([1,2,3])
s = sigmoid(x)
print(s)
[0.73105858 0.88079708 0.95257413]
1.2 S 形梯度
正如你在讲座中所看到的,你需要计算梯度以使用反向传播来优化损失函数。让我们编写您的第一个 gradient 函数。
实现函数 sigmoid_grad() 来计算 sigmoid 函数相对于其输入 x 的梯度。公式为:
通常分两个步骤编写此函数的代码:
- 将 s 设置为 x 的 sigmoid。您可能会发现 sigmoid(x) 函数很有用。
- 计算 \(\sigma'(x) = s(1-s)\)
def sigmoid_derivative(x):
s = sigmoid(x) #调用上面的sigmoid函数
ds = s*(1-s)
return ds
x = np.array([1, 2, 3])
print (f"sigmoid_derivative(x) = " + str(sigmoid_derivative(x)))
sigmoid_derivative(x) = [0.19661193 0.10499359 0.04517666]
1.3 - 重塑数组
深度学习中使用的两个常见 numpy 函数是 np.shape 和 np.reshape()。
np.shape 用于获取数组的形状,也就是数组各维度的大小。它返回一个元组,元组中的每个元素代表数组对应维度的大小。
np.reshape() 用于改变数组的形状,但不会改变数组中元素的数量和元素的值。它接收两个参数,第一个是要改变形状的数组,第二个是新的形状,用元组表示。
X.shape 用于获取矩阵/向量 X 的形状(维度)。
X.reshape(...) 用于将 X 重塑为其他维度。
练习:实现接受形状为 (length, height, 3) 的输入并返回形状为 (lengthheight3, 1) 的向量。
例如,如果您想将形状为 (a, b, c) 的数组 v 重塑为形状为 (a*b,c) 的向量,您可以这样做:image2vector()
v = v.reshape((v.shape[0]*v.shape[1], v.shape[2])) # v.shape[0] = a ; v.shape[1] = b ; v.shape[2] = c
请不要将 image 的 dimensions 硬编码为常量。相反,请使用 等查找您需要的数量。image.shape[0]
解题用到的numpy函数
np.shape 用于获取数组的形状,也就是数组各维度的大小。它返回一个元组,元组中的每个元素代表数组对应维度的大小。
np.reshape() 用于改变数组的形状,但不会改变数组中元素的数量和元素的值。它接收两个参数,第一个是要改变形状的数组,第二个是新的形状,用元组表示。
若已经使用 a = np.array() :各种序列(如列表、元组等)转换为 NumPy 数组
可直接使用a.shape()和a.reshape()
def image2vector(image):
# 使用动态获取图像的各个维度
# length = image.shape[0]
# height = image.shape[1]
# channels = image.shape[2]
# # 计算新的形状
# new_shape = (length * height * channels, 1) #组成一个元组类型
# # 将图像重塑为列向量
# v = image.reshape(new_shape) #对元组类型的维度进行重新塑造
# v = np.shape(image)
v = image.reshape((image.shape[0]*image.shape[1]*image.shape[2],1)) #image.shape 动态获取输入数组的各个维度
return v
import numpy as np
image = np.array([[[ 0.67826139, 0.29380381],
[ 0.90714982, 0.52835647],
[ 0.4215251 , 0.45017551]],
[[ 0.92814219, 0.96677647],
[ 0.85304703, 0.52351845],
[ 0.19981397, 0.27417313]],
[[ 0.60659855, 0.00533165],
[ 0.10820313, 0.49978937],
[ 0.34144279, 0.94630077]]])
# print(image,type(image))
# v = image2vector(image)
print("image2vector(image)="+str(image2vector(image)))
# print(v.shape)
# print(image.shape[0])
image2vector(image)=[[0.67826139]
[0.29380381]
[0.90714982]
[0.52835647]
[0.4215251 ]
[0.45017551]
[0.92814219]
[0.96677647]
[0.85304703]
[0.52351845]
[0.19981397]
[0.27417313]
[0.60659855]
[0.00533165]
[0.10820313]
[0.49978937]
[0.34144279]
[0.94630077]]
image = np.random.rand(5, 5, 3) #随机生成三维数组
print(image,type(image))
[[[0.24987486 0.85458332 0.39427962]
[0.84700883 0.80261149 0.67827139]
[0.50189242 0.97494552 0.21174211]
[0.29653918 0.04037584 0.36421942]
[0.22754314 0.78031512 0.5792323 ]]
[[0.84213381 0.67844461 0.490335 ]
[0.00748399 0.700573 0.26996999]
[0.13355395 0.96510904 0.0115554 ]
[0.7618202 0.55218258 0.92220161]
[0.39442553 0.3157387 0.59986778]]
[[0.7390022 0.68959494 0.76984036]
[0.31442081 0.14743378 0.22144336]
[0.25154061 0.30938835 0.4364773 ]
[0.57657224 0.64162257 0.37775498]
[0.19523348 0.00456079 0.31074704]]
[[0.21233574 0.10074275 0.86020969]
[0.42523492 0.18896698 0.58298956]
[0.21843096 0.76314584 0.04964143]
[0.19708626 0.93293973 0.99975001]
[0.71430935 0.22718415 0.27839391]]
[[0.9678347 0.21361153 0.60654814]
[0.3955639 0.94836807 0.34534538]
[0.30469452 0.19154872 0.36165117]
[0.85420721 0.95052128 0.62689458]
[0.75893816 0.9162334 0.74103706]]] <class 'numpy.ndarray'>
1.4 - 规范化行
我们在机器学习和深度学习中使用的另一种常见技术是规范化我们的数据。它通常会带来更好的性能,因为梯度下降在归一化后收敛得更快。在这里,归一化是指将 x 更改为$ \frac{x}{| x|} $(将 x 的每个行向量除以其范数)
np.linalg.norm 是 NumPy 库中用于计算向量或矩阵范数的函数。在 np.linalg.norm(x, axis = 1, keepdims = True) 中:
x:表示要计算范数的数组,可以是一维、二维或更高维的数组。
axis = 1:指定按行计算范数。对于二维数组,它会对每一行的元素进行范数计算。如果 x 是一维数组,此参数不适用;如果 x 是三维及以上数组,它会沿着第二个维度进行计算。
keepdims = True:表示保持结果的维度与原数组一致。计算完成后,结果数组的维度不会因为计算范数而减少。
例如,如果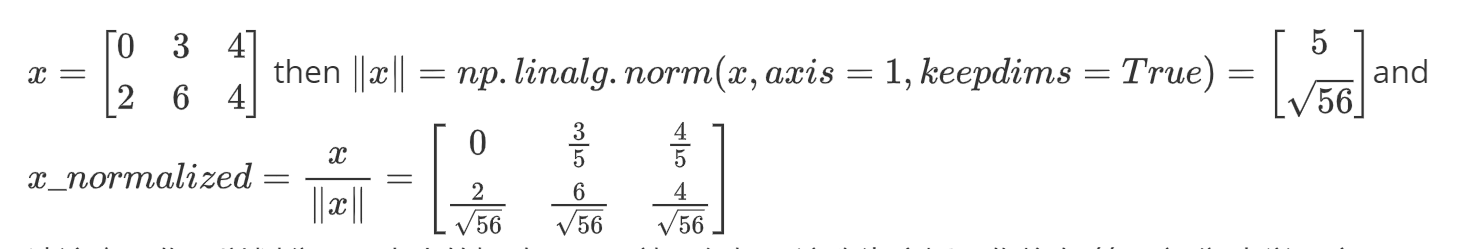
请注意,你可以划分不同大小的矩阵,而且效果很好:这称为广播,你将在 第 5 部分 中学习它。
练习:实现 normalizeRows() 以规范化矩阵的行。将此函数应用于输入矩阵 x 后,x 的每一行都应该是一个单位长度的向量(即长度 1)。
解题用的numpy函数
np.linalg.norm(x,axis=1,keepdims=True)
x:表示要计算范数的数组,可以是一维、二维或更高维的数组。
axis = 1:指定按行计算范数。对于二维数组,它会对每一行的元素进行范数计算。如果 x 是一维数组,此参数不适用;如果 x 是三维及以上数组,它会沿着第二个维度进行计算。
keepdims = True:表示保持结果的维度与原数组一致。计算完成后,结果数组的维度不会因为计算范数而减少。
def normalizeRows(x):
# x:表示要计算范数的数组,可以是一维、二维或更高维的数组。
# axis = 1:指定按行计算范数。对于二维数组,它会对每一行的元素进行范数计算。如果 x 是一维数组,此参数不适用;如果 x 是三维及以上数组,它会沿着第二个维度进行计算。
# keepdims = True:表示保持结果的维度与原数组一致。计算完成后,结果数组的维度不会因为计算范数而减少。
x1 = np.linalg.norm(x,axis=1,keepdims=True)
x = x/x1
return x
x = np.array([[0,3,4],
[1,6,4]])
print("normalizeRows(x)="+str(normalizeRows(x)))
normalizeRows(x)=[[0. 0.6 0.8 ]
[0.13736056 0.82416338 0.54944226]]
1.5 - 广播和 softmax 函数
在 numpy 中需要理解的一个非常重要的概念是 “广播”。它对于在不同形状的数组之间执行数学运算非常有用。有关广播的完整详细信息,您可以阅读官方广播文档。广播文档.
练习:使用 numpy 实现 softmax 函数。您可以将 softmax 视为一个归一化函数,当您的算法需要对两个或多个类进行分类时使用。您将在本专业的第二门课程中了解有关 softmax 的更多信息
做法:

解题用的numpy函数
np.exp(x):计算 e^x次方
np.sum(a,axis=1,keepdims=True) #求出矩阵中每行的和
import numpy as np
def softmax(x):
a = np.exp(x) #计算 e^x次方
sum1 = np.sum(a,axis=1,keepdims=True) #求出矩阵中每行的和
s = a/sum1 #求出softmax(x)的值
return s
# import numpy as np
x = np.array([
[9,2,5,0,0],
[7,5,0,0,0]])
print("softmax(x)="+str(softmax(x)))
softmax(x)=[[9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04
1.21052389e-04]
[8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04
8.01252314e-04]]
2 矢量化
在深度学习中,您需要处理非常大的数据集。因此,非计算最优函数可能会成为算法中的巨大瓶颈,并可能导致模型需要很长时间才能运行。为了确保您的代码在计算上是高效的,您将使用矢量化。例如,尝试区分 dot/outer/elementwise 产品的以下实现。
import time
import numpy as np
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### CLASSIC DOT PRODUCT OF VECTORS IMPLEMENTATION ###
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot+= x1[i]*x2[i]
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC OUTER PRODUCT IMPLEMENTATION ###
tic = time.process_time()
outer = np.zeros((len(x1),len(x2))) # we create a len(x1)*len(x2) matrix with only zeros
for i in range(len(x1)):
for j in range(len(x2)):
outer[i,j] = x1[i]*x2[j]
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC ELEMENTWISE IMPLEMENTATION ###
tic = time.process_time()
mul = np.zeros(len(x1))
for i in range(len(x1)):
mul[i] = x1[i]*x2[i]
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC GENERAL DOT PRODUCT IMPLEMENTATION ###
W = np.random.rand(3,len(x1)) # Random 3*len(x1) numpy array
tic = time.process_time()
gdot = np.zeros(W.shape[0])
for i in range(W.shape[0]):
for j in range(len(x1)):
gdot[i] += W[i,j]*x1[j]
toc = time.process_time()
print ("gdot = " + str(gdot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
dot = 278
----- Computation time = 0.0ms
outer = [[81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0. 0.]
[18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[63. 14. 14. 63. 0. 63. 14. 35. 0. 0. 63. 14. 35. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0. 0.]
[18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0. 0.]
[45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
----- Computation time = 0.0ms
elementwise multiplication = [81. 4. 10. 0. 0. 63. 10. 0. 0. 0. 81. 4. 25. 0. 0.]
----- Computation time = 0.0ms
gdot = [26.61942854 25.12220808 22.33046868]
----- Computation time = 0.0ms
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### VECTORIZED DOT PRODUCT OF VECTORS ###
tic = time.process_time()
dot = np.dot(x1,x2)
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED OUTER PRODUCT ###
tic = time.process_time()
outer = np.outer(x1,x2)
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED ELEMENTWISE MULTIPLICATION ###
tic = time.process_time()
mul = np.multiply(x1,x2)
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED GENERAL DOT PRODUCT ###
tic = time.process_time()
dot = np.dot(W,x1)
toc = time.process_time()
print ("gdot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
dot = 278
----- Computation time = 0.0ms
outer = [[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[63 14 14 63 0 63 14 35 0 0 63 14 35 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
----- Computation time = 0.0ms
elementwise multiplication = [81 4 10 0 0 63 10 0 0 0 81 4 25 0 0]
----- Computation time = 0.0ms
gdot = [26.61942854 25.12220808 22.33046868]
----- Computation time = 0.0ms
您可能已经注意到,矢量化实现更加简洁和高效。对于较大的向量/矩阵,运行时间的差异会变得更大。
请注意,执行矩阵-矩阵或矩阵-向量乘法。这与 和 运算符(相当于 Matlab/Octave 中的运算符)不同,后者执行元素乘法。np.dot() np.multiply().
2.1 实现 L1 和 L2 损失函数
练习: 实现 L1 损失的 numpy 矢量化版本。您可能会发现函数 abs(x) (x 的绝对值) 很有用。
温馨提示: 损失用于评估模型的性能。您的损失越大,您的预测差异就越大 ($ \hat{y} \() 来自 true 值(\)y$)在深度学习中,您可以使用 Gradient Descent 等优化算法来训练模型并最大限度地降低成本。
L1 损失定义为:
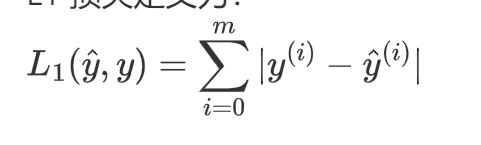
解题用的numpy函数
np.dot() 用于计算两个数组的点积。点积的具体计算方式根据输入数组的维度不同而有所差异:
对于一维数组,它计算的是两个数组对应元素乘积的和,即向量的内积。
对于二维数组,它执行的是矩阵乘法。
对于更高维的数组,np.dot() 的行为遵循特定的规则,但通常用于处理多维数组的点积计算。
np.outer() 用于计算两个一维数组的外积。外积的结果是一个二维数组,其形状为 (len(a), len(b)),其中 a 和 b 是输入的一维数组。外积的计算方式是将第一个数组的每个元素与第二个数组的每个元素相乘。
np.multiply() 用于对两个数组进行逐元素相乘。这意味着它会将两个数组中对应位置的元素相乘,并返回一个与输入数组形状相同的新数组。两个输入数组的形状必须相同,或者可以通过广播机制进行匹配。
np.sum(x):计算x的和
def L1(yhat,y):
# #基础解法
# loss = 0
# for i in range(len(y)):
# loss += abs(yhat[i]-y[i])
# 计算差值的绝对值
diff_abs = np.abs(y - yhat)
# 对所有元素求和
loss = np.sum(diff_abs)
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print(yhat)
print(y)
print("L1 = " + str(L1(yhat,y)))
[0.9 0.2 0.1 0.4 0.9]
[1 0 0 1 1]
L1 = 1.1
练习:
实现 L2 损失的 numpy 矢量化版本。有几种方法可以实现 L2 损失,但您可能会发现函数 np.dot() 很有用。提醒一下,如果\(x = [x_1, x_2, ..., x_n]\)
然后np.dot(x,x) 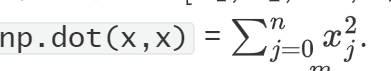
L2 损失定义为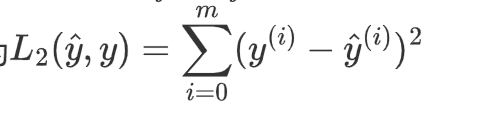
解题用的numpy函数
np.multiply() 用于对两个数组进行逐元素相乘。这意味着它会将两个数组中对应位置的元素相乘,并返回一个与输入数组形状相同的新数组。两个输入数组的形状必须相同,或者可以通过广播机制进行匹配。
np.sum(x): 会计算数组 x 中所有元素的总和。如果 x 是多维数组,它会将数组中的所有元素累加起来得到一个标量值。
语法 :np.sum(x, axis=None, dtype=None, out=None, keepdims=np._NoValue)
x 这是必需的参数,表示要进行求和操作的数组。
axis 该参数是可选的,用于指定沿着哪个轴进行求和。如果 axis 为 None(默认值),则会对数组中的所有元素进行求和;如果 axis 是一个整数,则会沿着指定的轴进行求和。
dtype:可选参数,用于指定返回结果的数据类型。
out:可选参数,用于指定存储结果的数组。
keepdims:可选参数,用于指定是否保持结果的维度与原数组一致。
def L2(yhat,y):
# #基础解法
# loss = 0
# for i in range(len(y)):
# loss += (yhat[i]-y[i])*(yhat[i]-y[i])
a = np.multiply(y-yhat,y-yhat) #数组中每行元素依次相乘
loss = np.sum(a) #计算数组行列总和
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L2 = " + str(L2(yhat,y)))
L2 = 0.43

 浙公网安备 33010602011771号
浙公网安备 33010602011771号