
爬取网易云热歌榜评论研究情感价值导向
一、选题的背景
目前网易云每首歌曲都有热评,在歌曲里也会对热门歌曲进行专门榜单的创作,我想借此热评了解大众评论喜好以及热歌榜歌曲评价的价值导向,利用python在网易云音乐网页版爬取相应评论,对评论数据做可视化分析希望能了解大众喜好的评论。
二、设计方案
1.爬虫名称:爬取网易云热歌榜评论
2.爬取内容:爬取网易云热歌榜所有音乐热评
3.方案概述:访问网页,分析网页源代码,找出所需要的的网址歌曲id,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图。
技术难点:做数据分析,因为评论是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
该页面是由发现音乐,我的音乐及关注等组成的网页,其中热歌榜是我探究的主题,该网站源代码中包含数个总标签,分析并提取总标签,即可爬取所需内容。
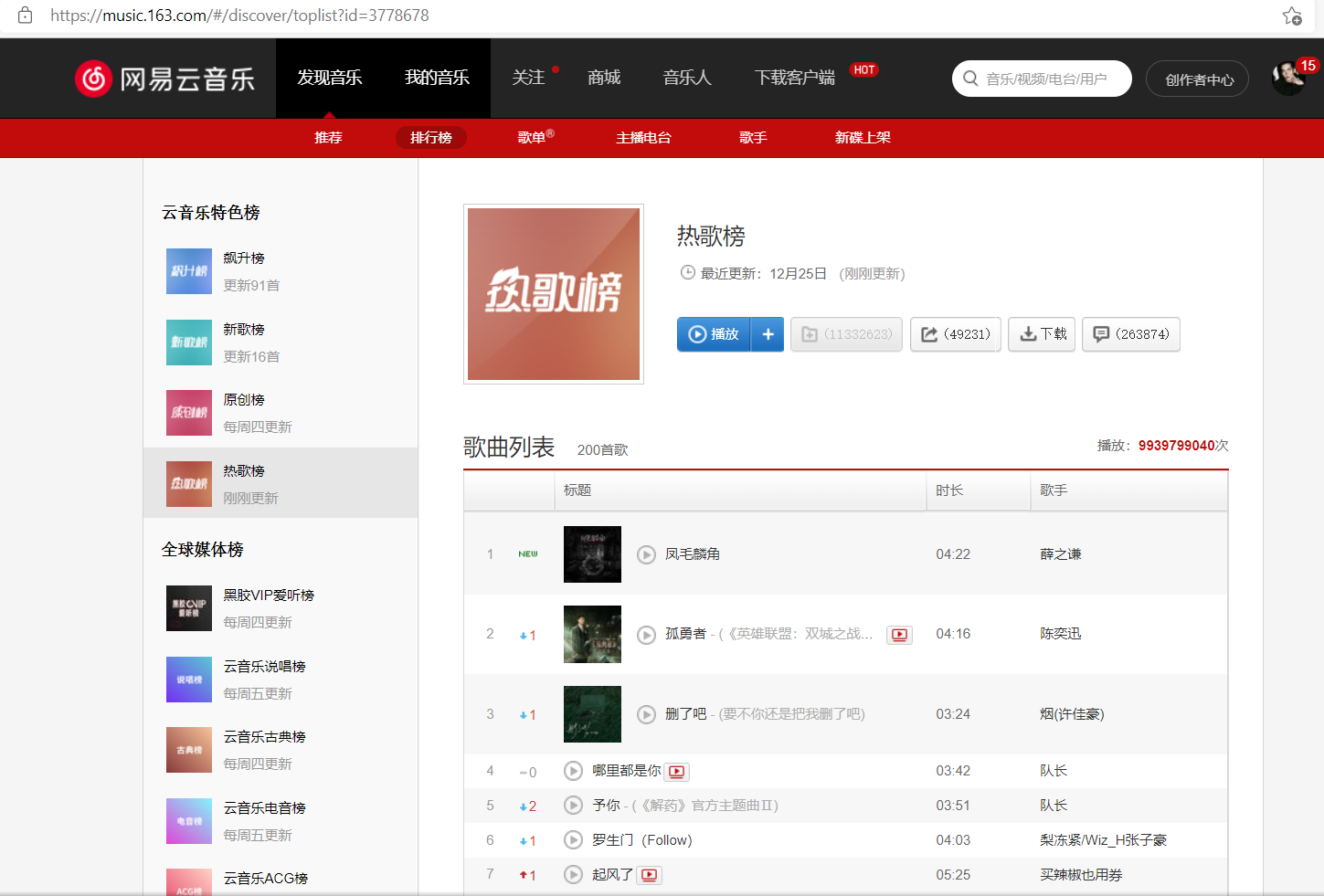
2. Htmls 页面解析
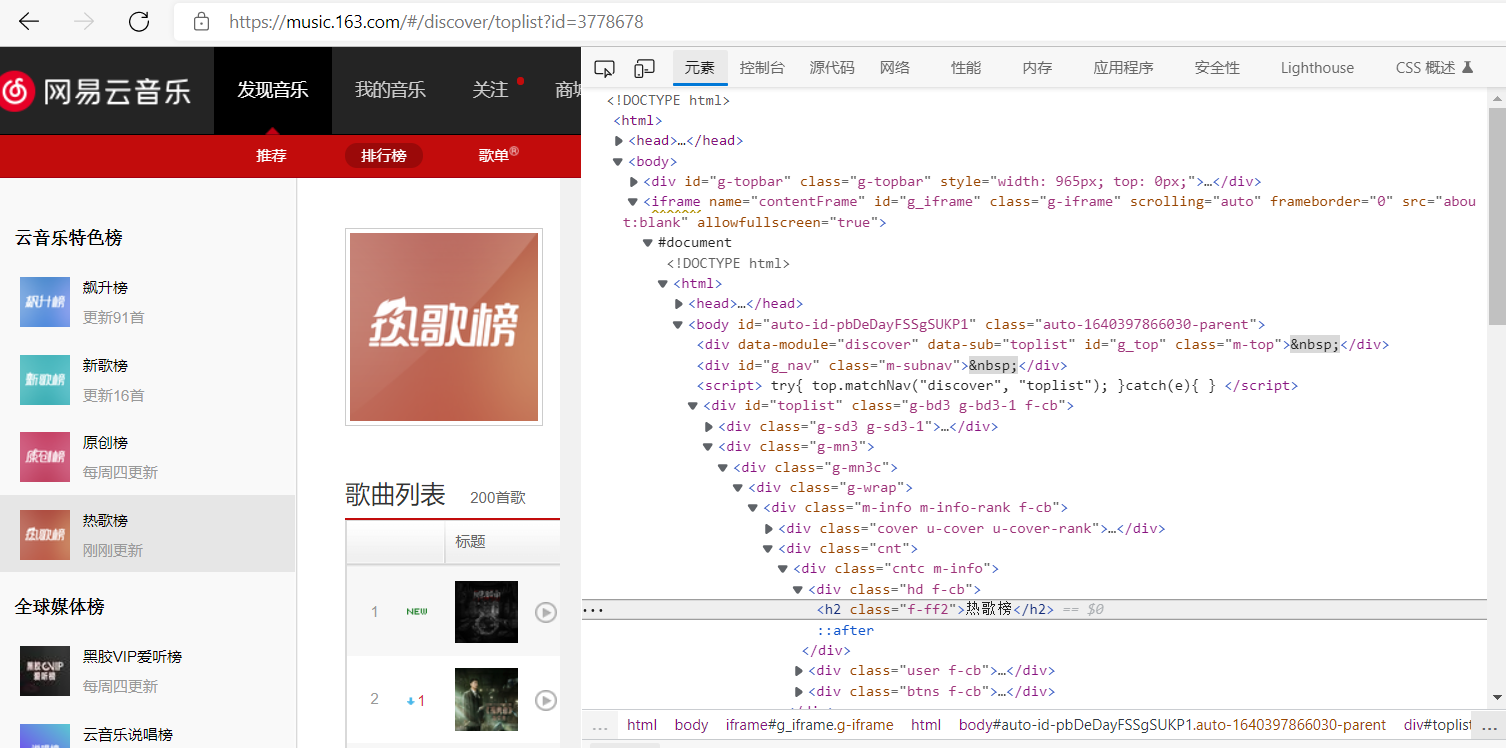
3.节点(标签)查找方法与遍历方法
在html源文件中找到对应数据所在的标签,用find_all()f方法遍历。
四、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后
面提供输出结果的截图。
1.数据爬取与采集
根据获取评论的API,请求URL有3个可变部分:歌曲ID、每页限制数limit和评论总偏移量offset,通过API分析得知:当offeset=0时,返回json数据中包含有评论总数量total,所以根据API可设计爬虫如下:
1 # -*- coding:utf8 -*- 2 3 # python3.6 4 from urllib import request 5 import json 6 import pymysql 7 from datetime import datetime 8 import re 9 10 ROOT_URL = 'http://music.163.com/api/v1/resource/comments/R_SO_4_%s?limit=%s&offset=%s' 11 LIMIT_NUMS = 50 # 每页限制爬取数 12 DATABASE = '' # 数据库名 13 TABLE = '' # 数据库表名 14 # 数据表设计如下: 15 ''' 16 id(int) commentId(varchar) 17 content(text) likedCount(int) 18 userId(varchar) time(datetime) 19 ''' 20 PATTERN = re.compile(r'[\n\t\r\/]') # 替换掉评论中的特殊字符以防插入数据库时报错 21 22 def getData(url): 23 if not url: 24 return None, None 25 headers = { 26 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', 27 "Host": "music.163.com", 28 } 29 print('Crawling>>> ' + url) 30 try: 31 req = request.Request(url, headers=headers) 32 content = request.urlopen(req).read().decode("utf-8") 33 js = json.loads(content) 34 total = int(js['total']) 35 datas = [] 36 for c in js['comments']: 37 data = dict() 38 data['commentId'] = c['commentId'] 39 data['content'] = PATTERN.sub('', c['content']) 40 data['time'] = datetime.fromtimestamp(c['time']//1000) 41 data['likedCount'] = c['likedCount'] 42 data['userId'] = c['user']['userId'] 43 datas.append(data) 44 return total, datas 45 except Exception as e: 46 print('Down err>>> ', e) 47 pass 48 49 def saveData(data): 50 if not data: 51 return None 52 conn = pymysql.connect(host='localhost', user='****', passwd='****', db='****', charset='utf8mb4') # 注意字符集要设为utf8mb4,以支持存储评论中的emoji表情 53 cursor = conn.cursor() 54 sql = 'insert into ' + TABLE + ' (id,commentId,content,likedCount,time,userId) VALUES (%s,%s,%s,%s,%s,%s)' 55 for d in data: 56 try: 57 cursor.execute('SELECT max(id) FROM '+TABLE) 58 id_ = cursor.fetchone()[0] 59 cursor.execute(sql, (id_+1,d['commentId'], d['content'], d['likedCount'], d['time'], d['userId'])) 60 conn.commit() 61 except Exception as e: 62 print('mysql err>>> ',d['commentId'],e) 63 pass 64 65 cursor.close() 66 conn.close() 67 68 if __name__ == '__main__': 69 songId = input('歌曲ID:').strip() 70 total,data = getData(ROOT_URL%(songId, LIMIT_NUMS, 0)) 71 saveData(data) 72 if total: 73 for i in range(1, total//EVERY_PAGE_NUMS+1): 74 _, data = getData(ROOT_URL%(songId, LIMIT_NUMS, i*(LIMIT_NUMS))) 75 saveData(data)
2.对数据进行清洗和处理
在这部分,利用Python的数据处理库pandas进行数据处理,利用可视化库pyecharts进行数据可视化。处理代码如下:
1 # -*- coding:utf8 -*- 2 # python3.6 3 import pandas as pd 4 import pymysql 5 from pyecharts import Bar,Pie,Line,Scatter,Map 6 7 TABLE_COMMENTS = '****' 8 TABLE_USERS = '****' 9 DATABASE = '****' 10 11 conn = pymysql.connect(host='localhost', user='****', passwd='****', db=DATABASE, charset='utf8mb4') 12 sql_users = 'SELECT id,gender,age,city FROM '+TABLE_USERS 13 sql_comments = 'SELECT id,time FROM '+TABLE_COMMENTS 14 comments = pd.read_sql(sql_comments, con=conn) 15 users = pd.read_sql(sql_users, con=conn) 16 17 # 评论时间(按天)分布分析 18 comments_day = comments['time'].dt.date 19 data = comments_day.id.groupby(comments_day['time']).count() 20 line = Line('评论时间(按天)分布') 21 line.use_theme('dark') 22 line.add( 23 '', 24 data.index.values, 25 data.values, 26 is_fill=True, 27 ) 28 line.render(r'./评论时间(按天)分布.html') 29 # 评论时间(按小时)分布分析 30 comments_hour = comments['time'].dt.hour 31 data = comments_hour.id.groupby(comments_hour['time']).count() 32 line = Line('评论时间(按小时)分布') 33 line.use_theme('dark') 34 line.add( 35 '', 36 data.index.values, 37 data.values, 38 is_fill=True, 39 ) 40 line.render(r'./评论时间(按小时)分布.html') 41 # 评论时间(按周)分布分析 42 comments_week = comments['time'].dt.dayofweek 43 data = comments_week.id.groupby(comments_week['time']).count() 44 line = Line('评论时间(按周)分布') 45 line.use_theme('dark') 46 line.add( 47 '', 48 data.index.values, 49 data.values, 50 is_fill=True, 51 ) 52 line.render(r'./评论时间(按周)分布.html') 53 54 # 用户年龄分布分析 55 age = users[users['age']>0] # 清洗掉年龄小于1的数据 56 age = age.id.groupby(age['age']).count() # 以年龄值对数据分组 57 Bar = Bar('用户年龄分布') 58 Bar.use_theme('dark') 59 Bar.add( 60 '', 61 age.index.values, 62 age.values, 63 is_fill=True, 64 ) 65 Bar.render(r'./用户年龄分布图.html') # 生成渲染的html文件 66 67 # 用户地区分布分析 68 # 城市code编码转换 69 def city_group(cityCode): 70 city_map = { 71 '11': '北京', 72 '12': '天津', 73 '31': '上海', 74 '50': '重庆', 75 '5e': '重庆', 76 '81': '香港', 77 '82': '澳门', 78 '13': '河北', 79 '14': '山西', 80 '15': '内蒙古', 81 '21': '辽宁', 82 '22': '吉林', 83 '23': '黑龙江', 84 '32': '江苏', 85 '33': '浙江', 86 '34': '安徽', 87 '35': '福建', 88 '36': '江西', 89 '37': '山东', 90 '41': '河南', 91 '42': '湖北', 92 '43': '湖南', 93 '44': '广东', 94 '45': '广西', 95 '46': '海南', 96 '51': '四川', 97 '52': '贵州', 98 '53': '云南', 99 '54': '西藏', 100 '61': '陕西', 101 '62': '甘肃', 102 '63': '青海', 103 '64': '宁夏', 104 '65': '新疆', 105 '71': '台湾', 106 '10': '其他', 107 } 108 return city_map[cityCode[:2]] 109 110 city = users['city'].apply(city_group) 111 city = city.id.groupby(city['city']).count() 112 map_ = Map('用户地区分布图') 113 map_.add( 114 '', 115 city.index.values, 116 city.values, 117 maptype='china', 118 is_visualmap=True, 119 visual_text_color='#000', 120 is_label_show=True, 121 ) 122 map_.render(r'./用户地区分布图.html')
3.文本分析
我在对网易云评论数据分析与可视化利用python selenium
4.数据分析与可视化
首先我们可以选择任意自己喜欢的音乐来采集评论,我这里就以 岁月神偷 为例来采集36万+条评论然后来做可视化分析
导入所需模块
1 import random 2 from selenium import webdriver 3 from icecream import ic 4 import time 5 import csv
打开浏览器并且加载网页内容
1 # 驱动加载 2 3 driver = webdriver.Chrome() 4 5 6 7 # 打开网站 8 9 driver.get('https://music.163.com/#/song?id=28285910') 10 11 12 13 # 等待网页加载完成,不是死等;加载完成即可 14 15 driver.implicitly_wait(10) 16 17 18 19 # 定位iframe 20 21 iframe = driver.find_element_by_css_selector('.g-iframe') 22 23 24 25 # 先进入到iframe 26 27 driver.switch_to.frame(iframe) 28 29 30 31 提取网页信息 32 33 for div in divs: 34 35 user_name = div.find_element_by_css_selector('.cnt.f-brk a').text 36 37 hot_cmts = div.find_element_by_css_selector('.cnt.f-brk').text.split(':')[1] 38 39 cmts_time = div.find_element_by_css_selector('.time.s-fc4').text 40 41 42 43 ic(user_name, hot_cmts, cmts_time) 44 45 46 47 ''' 48 49 ic| user_name: '什么事都让我分心' 50 51 hot_cmts: '上个月你结婚了,新娘和你很般配,嗯。你从当年的小男生长成了大男孩。亲她的时候,我突然想起高二那个中午,你偷亲我,你不知道的是,其实当时我没有睡着。现在我也有了女朋友,准备明年结婚了,祝彼此幸福。' 52 53 cmts_time: '2016年4月13日' 54 55 ic| user_name: '吴繁繁' 56 57 hot_cmts: '枕在奶奶腿上听这首歌,奶奶七十多,像个好奇宝宝一样用手指小心地划着我的手机屏幕,看看歌词看看封面,把手机凑近耳朵听。时间是让人猝不及防的东西。' 58 59 cmts_time: '2015年7月12日' 60 61 ic| user_name: 'jjjkkklllmmm' 62 63 hot_cmts: '刚进大学寝室的时候,发现床板上有人用记号笔画了一张请假条,请假原因是毕业,离校时间是6.20,返校时间是永不。 其实老师唯一没骗我们的一句话就是' 64 65 cmts_time: '2016年5月13日' 66 67 ic| user_name: '南说哦' 68 69 hot_cmts: '大家都说我的性子很慢,其实我也可以很快 比如,后面有狗追我 或者,你在前面等我' 70 71 cmts_time: '2017年5月21日' 72 73 ic| user_name: '_时光慢点_VI' 74 75 hot_cmts: '听歌的时候,旋律永远是第一感觉,然后才是歌词,歌词过后才是细节。 76 77 就像读小说,一开始只对剧情感兴趣,慢慢你开始琢磨小说中的人物,最后才发掘小说的内涵。' 78 79 cmts_time: '2015年2月9日' 80 81 ic| user_name: '刘家鑫很蠢' 82 83 hot_cmts: ('逛留言板上看到的一句话 "我对你这么好 你却总这样不冷不热的 可我毫无办法 谁叫一开始主动的人是我 偶尔也会想想 当我终于消失在追逐你的长途里 ' 84 85 '某个夜里你的手机微微一震 你会不会恍然地以为 还是我给你的温柔"一个恍惚瞬间戳到泪点。') 86 87 cmts_time: '2016年4月26日' 88 89 '''
数据保存
1 f = open('suiyue.csv', mode='a', encoding='utf-8-sig', newline='') 2 3 csv_writer = csv.DictWriter(f, fieldnames=[ 4 5 '用户名称', 6 7 '评论时间', 8 9 '评论内容' 10 11 ]) 12 13 14 15 dit = { 16 17 '用户名称': user_name, 18 19 '评论时间': cmts_time, 20 21 '评论内容': hot_cmts 22 23 } 24 25 csv_writer.writerow(dit)
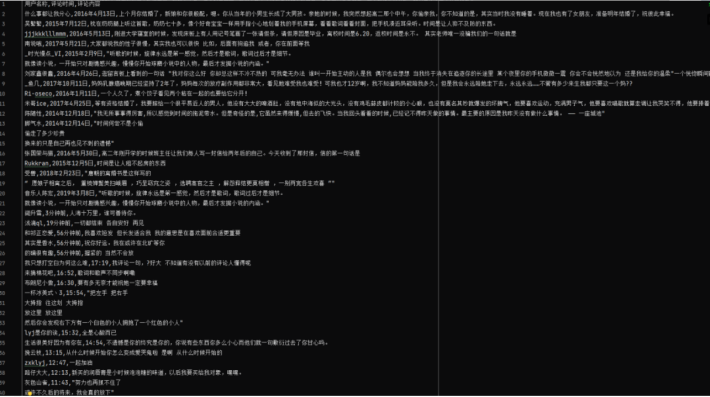
气泡对评论做可视化分析
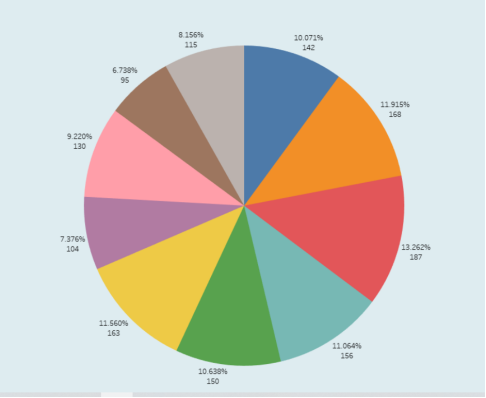
# 词频设置 all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words] wordcount = Counter(all_words).most_common(10) ''' ('我们', '时间', '一个', '喜欢', '现在', '没有', '真的', '自己', '一起', '知道') (187, 168, 163, 156, 150, 142, 130, 115, 104, 95)
'''
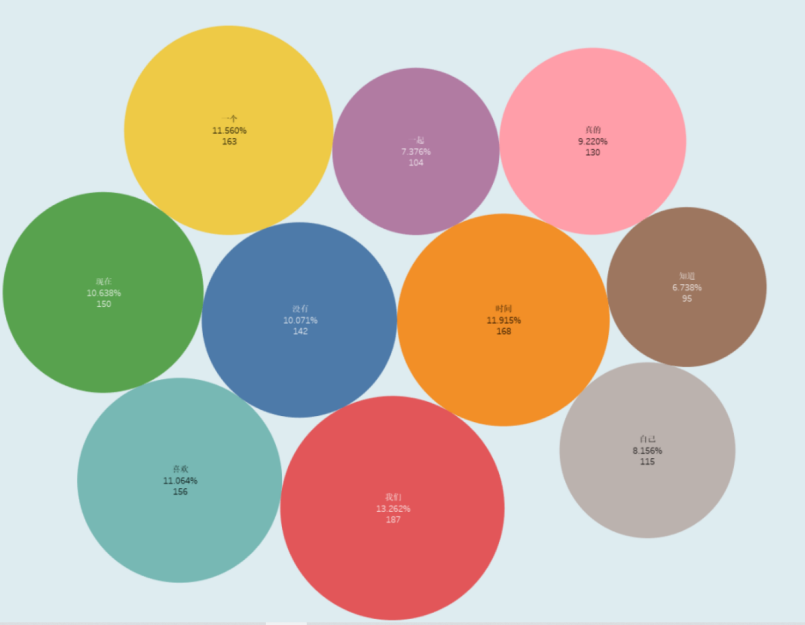
饼状图
本首歌词云展示
1 gen_stylecloud(text=result, 2 3 icon_name='fas fa-comment', 4 5 font_path='msyh.ttc', 6 7 background_color='white', 8 9 output_name=pic, 10 11 custom_stopwords=stop_words 12 13 ) 14 15 print('词云图绘制成功!')


对评论进行分析比较
1 2 3 4 5 def anay_data(): 6 7 all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words] 8 9 positibe = negtive = middle = 0 10 11 for i in all_words: 12 13 pingfen = SnowNLP(i) 14 15 if pingfen.sentiments > 0.7: 16 17 positibe += 1 18 19 elif pingfen.sentiments < 0.3: 20 21 negtive += 1 22 23 else: 24 25 middle += 1 26 27 print(positibe, negtive, middle) 28 29 30 31 ''' 32 33 3856 881 11122 34 35 '''
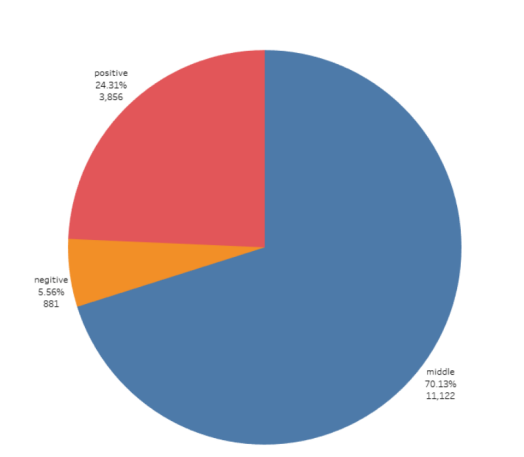
我们将评论分为积极、消极和中等
由图我们可以分析出,大多数评论者的心态还是积极向上的
5.将以上各部分的代码汇总,附上完整程序代码
1 # !/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 import re 5 import urllib.request 6 import urllib.error 7 import urllib.parse 8 import json 9 10 11 def get_all_hotSong(): # 获取热歌榜所有歌曲名称和id 12 url = 'http://music.163.com/discover/toplist?id=3778678' # 网易云云音乐热歌榜url 13 header = { # 请求头部 14 'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' 15 } 16 request = urllib.request.Request(url=url, headers=header) 17 html = urllib.request.urlopen(request).read().decode('utf8') # 打开url 18 html = str(html) # 转换成str 19 pat1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' # 进行第一次筛选的正则表达式 20 result = re.compile(pat1).findall(html) # 用正则表达式进行筛选 21 result = result[0] # 获取tuple的第一个元素 22 23 pat2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' # 进行歌名筛选的正则表达式 24 pat3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' # 进行歌ID筛选的正则表达式 25 hot_song_name = re.compile(pat2).findall(result) # 获取所有热门歌曲名称 26 hot_song_id = re.compile(pat3).findall(result) # 获取所有热门歌曲对应的Id 27 28 return hot_song_name, hot_song_id 29 30 31 def get_hotComments(hot_song_name, hot_song_id): 32 url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' # 歌评url 33 header = { # 请求头部 34 'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' 35 } 36 # post请求表单数据 37 data = { 38 'params': 'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ', 39 'encSecKey': '4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'} 40 postdata = urllib.parse.urlencode(data).encode('utf8') # 进行编码 41 request = urllib.request.Request(url, headers=header, data=postdata) 42 reponse = urllib.request.urlopen(request).read().decode('utf8') 43 json_dict = json.loads(reponse) # 获取json 44 hot_commit = json_dict['hotComments'] # 获取json中的热门评论 45 46 num = 0 47 fhandle = open('./song_comments', 'a', encoding='utf-8') # 写入文件 48 fhandle.write(hot_song_name + ':' + '\n') 49 50 for item in hot_commit: 51 num += 1 52 fhandle.write(str(num) + '.' + item['content'] + '\n') 53 fhandle.write('\n==============================================\n\n') 54 fhandle.close() 55 56 57 hot_song_name, hot_song_id = get_all_hotSong() # 获取热歌榜所有歌曲名称和id 58 59 num = 0 60 while num < len(hot_song_name): # 保存所有热歌榜中的热评 61 print('正在抓取第%d首歌曲热评...' % (num + 1)) 62 get_hotComments(hot_song_name[num], hot_song_id[num]) 63 print('第%d首歌曲热评抓取成功' % (num + 1)) 64 num += 1 65 66 #底下均为一首歌的代码抓取数据分析# 导入所需模块 67 68 import random 69 from selenium import webdriver 70 from icecream import ic 71 import time 72 import csv 73 74 # 驱动加载 75 driver = webdriver.Chrome() 76 77 # 打开网站 78 driver.get('https://music.163.com/#/song?id=28285910') 79 80 # 等待网页加载完成,不是死等;加载完成即可 81 driver.implicitly_wait(10) 82 83 # 定位iframe 84 iframe = driver.find_element_by_css_selector('.g-iframe') 85 86 # 先进入到iframe 87 driver.switch_to.frame(iframe) 88 89 提取网页信息 90 for div in divs: 91 user_name = div.find_element_by_css_selector('.cnt.f-brk a').text 92 hot_cmts = div.find_element_by_css_selector('.cnt.f-brk').text.split(':')[1] 93 cmts_time = div.find_element_by_css_selector('.time.s-fc4').text 94 95 ic(user_name, hot_cmts, cmts_time) 96 97 ''' 98 99 ic| user_name: '什么事都让我分心' 100 hot_cmts: '上个月你结婚了,新娘和你很般配,嗯。你从当年的小男生长成了大男孩。亲她的时候,我突然想起高二那个中午,你偷亲我,你不知道的是,其实当时我没有睡着。现在我也有了女朋友,准备明年结婚了,祝彼此幸福。' 101 cmts_time: '2016年4月13日' 102 ic| user_name: '吴繁繁' 103 hot_cmts: '枕在奶奶腿上听这首歌,奶奶七十多,像个好奇宝宝一样用手指小心地划着我的手机屏幕,看看歌词看看封面,把手机凑近耳朵听。时间是让人猝不及防的东西。' 104 cmts_time: '2015年7月12日' 105 ic| user_name: 'jjjkkklllmmm' 106 hot_cmts: '刚进大学寝室的时候,发现床板上有人用记号笔画了一张请假条,请假原因是毕业,离校时间是6.20,返校时间是永不。 其实老师唯一没骗我们的一句话就是' 107 cmts_time: '2016年5月13日' 108 ic| user_name: '南说哦' 109 hot_cmts: '大家都说我的性子很慢,其实我也可以很快 比如,后面有狗追我 或者,你在前面等我' 110 cmts_time: '2017年5月21日' 111 ic| user_name: '_时光慢点_VI' 112 hot_cmts: '听歌的时候,旋律永远是第一感觉,然后才是歌词,歌词过后才是细节。 113 就像读小说,一开始只对剧情感兴趣,慢慢你开始琢磨小说中的人物,最后才发掘小说的内涵。' 114 cmts_time: '2015年2月9日' 115 ic| user_name: '刘家鑫很蠢' 116 hot_cmts: ('逛留言板上看到的一句话 "我对你这么好 你却总这样不冷不热的 可我毫无办法 谁叫一开始主动的人是我 偶尔也会想想 当我终于消失在追逐你的长途里 ' 117 '某个夜里你的手机微微一震 你会不会恍然地以为 还是我给你的温柔"一个恍惚瞬间戳到泪点。') 118 cmts_time: '2016年4月26日' 119 ''' 120 121 数据保存 122 f = open('suiyue.csv', mode='a', encoding='utf-8-sig', newline='') 123 csv_writer = csv.DictWriter(f, fieldnames=[ 124 '用户名称', 125 '评论时间', 126 '评论内容' 127 ]) 128 129 dit = { 130 '用户名称': user_name, 131 '评论时间': cmts_time, 132 '评论内容': hot_cmts 133 } 134 csv_writer.writerow(dit) 135 # 气泡对评论做可视化分析 136 # 词频设置 137 all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words] 138 wordcount = Counter(all_words).most_common(10) 139 140 ''' 141 ('我们', '时间', '一个', '喜欢', '现在', '没有', '真的', '自己', '一起', '知道') 142 (187, 168, 163, 156, 150, 142, 130, 115, 104, 95) 143 ''' 144 #先进行网页解析 145 #进行文字匹配 146 #制定URL,获取网页数据 147 #进行excel操作 148 #进行SQLite数据库操作 149 #开始爬取数据 150 def get_all_hotSong(): # 获取热歌榜所有歌曲名称和id 151 url = 'http://music.163.com/discover/toplist?id=3778678' # 网易云云音乐热歌榜url 152 header = { # 请求头部 153 'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' 154 } 155 request = urllib.request.Request(url=url, headers=header) 156 html = urllib.request.urlopen(request).read().decode('utf8') # 打开url 157 html = str(html) # 转换成str 158 pat1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' # 进行第一次筛选的正则表达式 159 result = re.compile(pat1).findall(html) # 用正则表达式进行筛选 160 result = result[0] # 获取tuple的第一个元素 161 162 pat2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' # 进行歌名筛选的正则表达式 163 pat3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' # 进行歌ID筛选的正则表达式 164 hot_song_name = re.compile(pat2).findall(result) # 获取所有热门歌曲名称 165 hot_song_id = re.compile(pat3).findall(result) # 获取所有热门歌曲对应的Id 166 167 return hot_song_name, hot_song_id 168 169 170 def get_hotComments(hot_song_name, hot_song_id): 171 url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' # 歌评url 172 header = { # 请求头部 173 'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' 174 } 175 # post请求表单数据 176 data = { 177 'params': 'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ', 178 'encSecKey': '4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'} 179 postdata = urllib.parse.urlencode(data).encode('utf8') # 进行编码 180 request = urllib.request.Request(url, headers=header, data=postdata) 181 reponse = urllib.request.urlopen(request).read().decode('utf8') 182 json_dict = json.loads(reponse) # 获取json 183 hot_commit = json_dict['hotComments'] # 获取json中的热门评论 184 185 num = 0 186 fhandle = open('./song_comments', 'a', encoding='utf-8') # 写入文件 187 fhandle.write(hot_song_name + ':' + '\n') 188 189 for item in hot_commit: 190 num += 1 191 fhandle.write(str(num) + '.' + item['content'] + '\n') 192 fhandle.write('\n==============================================\n\n') 193 fhandle.close() 194 195 196 hot_song_name, hot_song_id = get_all_hotSong() # 获取热歌榜所有歌曲名称和id 197 198 num = 0 199 while num < len(hot_song_name): # 保存所有热歌榜中的热评 200 print('正在抓取第%d首歌曲热评...' % (num + 1)) 201 get_hotComments(hot_song_name[num], hot_song_id[num]) 202 print('第%d首歌曲热评抓取成功' % (num + 1)) 203 num += 1 204 205 #列名 206 col = ("排名","歌名","播放量") 207 208 #创建表头 209 for i in range(0,3): 210 sheet.write(0,i,col[i]) 211 212 #输入数据 213 for i in range(0,15): 214 #将播放量数据转化为纯数字格式 215 datalist[i][2] = datalist[i][2].replace('次播放','') 216 data = datalist[i] 217 for j in range(0,3): 218 sheet.write(i+1,j,data[j]) 219 220 book.save(savepath) 221 222 print('已输出表格!') 223 224 print("爬取完毕!") 225 226 227 228 import pandas as pd 229 230 #导入数据 231 # #显示数据表格 232 #查看是否有重复行,有重复行返回True,没有重复行返回False 233 df_gm.duplicated() 234 235 #判断数据行中书是否存在缺失值,有缺失值返回True,没有缺失值返回False 236 df_gm.isnull().any(axis=1) 237 238 # 查看是否有空值,有空值返回True,没有空值返回False 239 df_gm.isnull() 240 241 #查看是否存在异常值 242 df_gm.describe() 243 244 245 246 #绘制散点折线图 247 import pandas as pd 248 import numpy as np 249 import matplotlib.pyplot as plt 250 251 df_gm = pd.read_excel("豆瓣音乐本周音乐人最热单曲排行榜.xls") 252 253 #散点 254 plt.scatter(df_gm.排名,df_gm.播放量,color='b') 255 256 #折线 257 plt.plot(df_gm.排名,df_gm.播放量,color='r') 258 259 #添加x轴标签和y轴标签 260 plt.xlabel('PM') 261 plt.ylabel('BFL') 262 263 plt.show() 264 265 266 267 #绘制数据柱形图 268 import pandas as pd 269 import numpy as np 270 import matplotlib.pyplot as plt 271 272 kuake_df=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 273 data=np.array(kuake_df['播放量'][0:15]) 274 275 #添加x轴标签和y轴标签 276 plt.xlabel('PM') 277 plt.ylabel('BFL') 278 279 s = pd.Series(data, index) 280 s.plot(kind='bar',color='cyan') 281 282 #添加网格 283 plt.grid() 284 285 plt.show() 286 287 288 289 #线性回归方程 290 import pandas as pd 291 from sklearn import datasets 292 from sklearn.datasets import load_boston 293 from sklearn.linear_model import LinearRegression
个人总结:
经过图表数据分析可以得出:大多数评论者的心态还是积极向上的,留言热评大部分也是积极导向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号