

一、逻辑回归
逻辑斯蒂是统计学习中的经典分类算法!




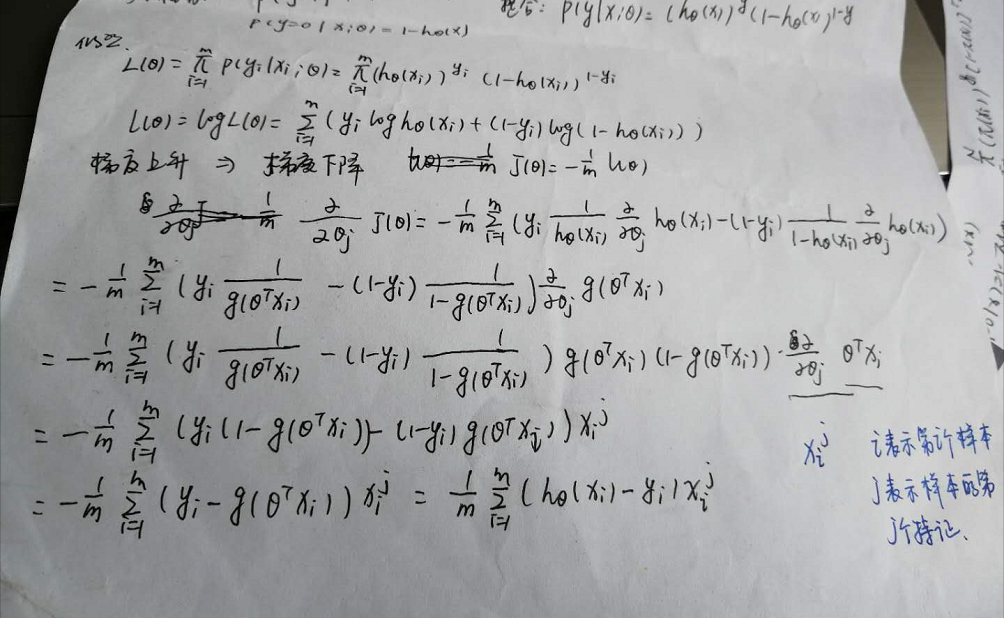

二、虚拟变量
定义:虚拟变量又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的质变量,通常取值为0或1。引入哑变量可使线形回归模型变得更复杂,但对问题描述更简明,一个方程能达到俩个方程的作用,而且接近现实。例如,反映文程度的虚拟变量可取为:1:本科学历;0:非本科学历
一般地,在虚拟变量的设置中:基础类型、肯定类型取值为1;比较类型,否定类型取值为0。
设置原则:
在模型中引入多个虚拟变量时,虚拟变量的个数应按下列原则确定:
1)如果有m种互斥的属性类型,在模型中引入(m-1)个虚拟变量,否则会导致多重共线性。称作虚拟变量陷阱。 例如,性别有2个互斥的属性,引用2-1=1个虚拟变量;再如,文化程度分小学、初中、高中、大学、研究生5类,引用4个虚拟变量。
2)关于定型变量中哪个取0哪个取1是任意的,不影响检验结果。
3)若定型变量取值为0,所对应的类别称为基础类别。
4)对于多于两个类别的定型变量可采用设一个虚拟变量,而对于不同类别采取赋值不同的方法处理。
三、逻辑回归实例(包含R代码和Python代码)
该数据集是共包含4个变量,其中admit为因变量,gre、gpa、prestige为自变量,且prestige有1,2,3,4四个等级,需要设置虚拟变量。
(a)R代码
data<-read.csv("C:/Users/ymz/Downloads/binary.csv",header=TRUE)
head(data)
names(data)<-c("admit","gre","gpa","prestige")#其中数据集中prestige名是后来更换,原本是rank
data$prestige<-as.factor(data$prestige)
library(nnet)
dummy<-class.ind(data$prestige)#设置虚拟变量
head(dummy)#得到虚拟变量向量
dummy<-as.data.frame(dummy)#将格式转化成数据框
names(dummy)<-c('prestige_1','prestige_2','prestige_3','prestige_4')#对数据框每一列重命名
head(dummy)
#ndata<-merge(x = data, y = dummy, by = NULL)#合并数据框(但是好像顺序打乱?数据量数目不对)
#head(ndata)
ndata<-cbind(data,dummy)#合并数据框,按列合并,数据数目对应相同
head(ndata)
newdata1<-ndata[,c(-4,-5)]#去掉因变量和一个为基准的虚拟变量
head(newdata1)
#glm.fit=glm(data$admit~data$gre+data$gpa+dummy$prestige_2+dummy$prestige_3+dummy$prestige_4,family=binomial(link="logit"))#注意,虚拟变量取N-1个进入模型,未进入模型的作基准。
glm.fit=glm(admit~.,data=newdata1,family=binomial(link="logit"))
summary(glm.fit)#查看参数估计结果
predict <- predict(glm.fit,type='response',newdata=newdata1)
real <- newdata$admit
res <- data.frame(real,predict =ifelse(predict>0.5,'1','0'))
table(real,predict =ifelse(predict>0.5,'1','0'))#计算正确率
代码结果显示:
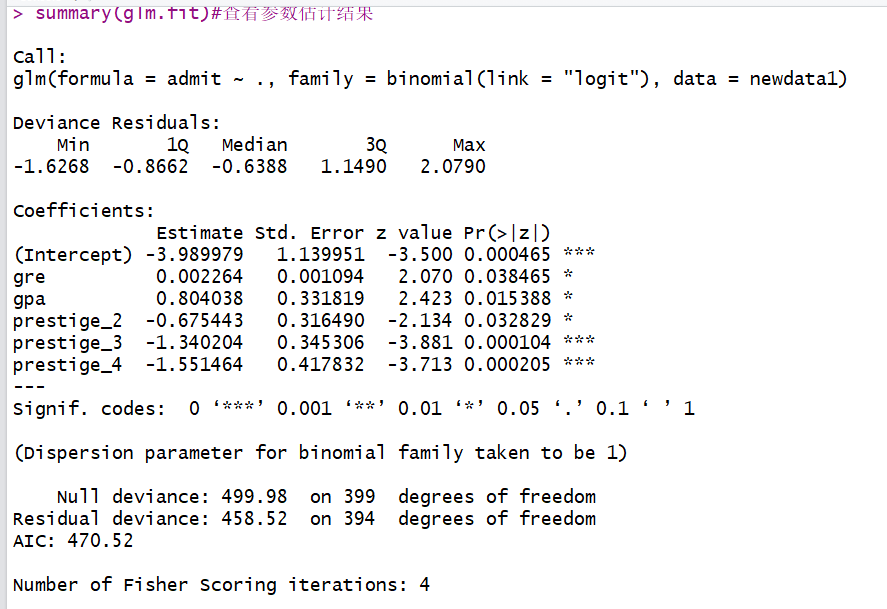

由代码显示结果知:正确率为(254+30)/(254+19+97+30)=0.71.
(b)python代码
1 import numpy as np 2 import pandas as pd 3 import statsmodels.api as sm 4 import pylab as pl 5 from pandas.core import datetools 6 from scipy.stats import chisquare 7 8 9 df=pd.read_csv("C:/Users/ymz/Downloads/binary.csv") 10 print(df.head()) 11 df.columns = ["admit", "gre", "gpa", "prestige"] #对数据集中的rank重命名为prestige 12 #print(df.columns) 13 print(df.describe())#与R中summary相似,描述数据的情况,比如每一列数数目情况、均值、标准差、分位数等。 14 print(df.std())#输出每一列的标准差 15 16 # 频率表,表示prestige与admin的值相应的数量关系 17 print(pd.crosstab(df['admit'], df['prestige'], rownames=['admit'])) 18 # plot all of the columns 19 # df.hist() 20 # pl.show() 21 #虚拟变量,也叫哑变量,可用来表示分类变量、非数量因素可能产生的影响。在计量经济学模型,需要经常考虑属性因素的影响。例如,职业、文化程度、季节等属性因素往往很难直接度量它们的大小。只能给出它们的“Yes—D=1”或”No—D=0”,或者它们的程度或等级。为了反映属性因素和提高模型的精度,必须将属性因素“量化”。通过构造0-1型的人工变量来量化属性因素。 22 23 #pandas提供了一系列分类变量的控制。我们可以用get_dummies来将”prestige”一列虚拟化。 24 25 #get_dummies为每个指定的列创建了新的带二分类预测变量的DataFrame,在本例中,prestige有四个级别:1,2,3以及4(1代表最有声望),prestige作为分类变量更加合适。当调用get_dummies时,会产生四列的dataframe,每一列表示四个级别中的一个。 26 dummy_ranks = pd.get_dummies(df['prestige'], prefix='prestige')#创建虚拟变量(哑变量) 27 print (dummy_ranks.head()) 28 # 为逻辑回归创建所需的data frame 29 # 除admit、gre、gpa外,加入了上面常见的虚拟变量(注意,引入的虚拟变量列数应为虚拟变量总列数减1,减去的1列作为基准) 30 cols_to_keep = ['admit', 'gre', 'gpa'] 31 data = df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])#将自变量数据整合到一起 32 print(data.head()) 33 data['intercept']=1.0#注意,python中需要加入截距项常数项,而R中不需要 34 #这样,数据原本的prestige属性就被prestige_x代替了,例如原本的数值为2,则prestige_2为1,prestige_1、prestige_3、prestige_4都为0。 35 36 #将新的虚拟变量加入到了原始的数据集中后,就不再需要原来的prestige列了。在此要强调一点,生成m个虚拟变量后,只要引入m-1个虚拟变量到数据集中,未引入的一个是作为基准对比的。 37 38 #最后,还需加上常数intercept,statemodels实现的逻辑回归需要显式指定 39 40 #实际上完成逻辑回归是相当简单的,首先指定要预测变量的列,接着指定模型用于做预测的列,剩下的就由算法包去完成了。 41 42 #本例中要预测的是admin列,使用到gre、gpa和虚拟变量prestige_2、prestige_3、prestige_4。prestige_1作为基准,所以排除掉,以防止多元共线性(multicollinearity)和引入分类变量的所有虚拟变量值所导致的陷阱(dummy variable trap)。 43 44 # 指定作为训练变量的列,不含目标列`admit` 45 train_cols = data.columns[1:]#第一列到最后一列,去掉第零列 46 # Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object) 47 48 logit = sm.Logit(data['admit'], data[train_cols])#建立模型 49 50 # 拟合模型 51 result = logit.fit() 52 53 import copy 54 55 combos = copy.deepcopy(data) 56 57 # 数据中的列要跟预测时用到的列一致 58 predict_cols = combos.columns[1:] 59 60 # 预测集也要添加intercept变量 61 combos['intercept'] = 1.0 62 # 进行预测,并将预测评分存入 predict 列中 63 combos['predict'] = result.predict(combos[predict_cols]) 64 # 预测完成后,predict 的值是介于 [0, 1] 间的概率值 65 # 我们可以根据需要,提取预测结果 66 # 例如,假定 predict > 0.5,则表示会被录取 67 # 在这边我们检验一下上述选取结果的精确度 68 total = 0 69 hit = 0 70 for value in combos.values: 71 # 预测分数 predict, 是数据中的最后一列 72 predict = value[-1] 73 # 实际录取结果 74 admit = int(value[0]) 75 76 # 假定预测概率大于0.5则表示预测被录取 77 if predict > 0.5: 78 total += 1 79 # 表示预测命中为1 80 if admit == 1: 81 hit += 1 82 83 84 85 # 输出结果 86 print('Total: %d, Hit: %d, Precision: %.2f' % (total, hit, 100.0 * hit / total)) 87 # Total: 49, Hit: 30, Precision: 61.22 88 print(result.summary2())#查看逻辑回归详细结果 89 90 #在最后进行模型解释时,所有类别哑变量的回归系数,均表示该哑变量与参照相比之后对因变量的影响。 91 print(result.conf_int())#查看系数的置信区间 92 print(np.exp(result.params))
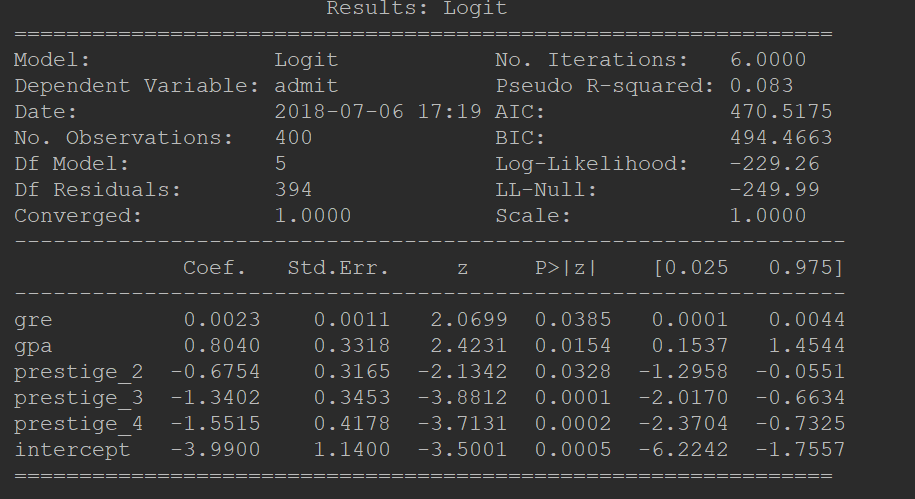

这计算的是Precsion ,预测为1中正确的数和预测为1的数的比例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号