python进程
一.进程
# 进程:一个新鲜的字眼,可能有些人并不了解,它是系统某个运行程序的载体,
这个程序可以有单个或者多个进程,一般来说,进程是通过系统CPU 内核数来分配并设置的,我们可以来看下系统中的进程:
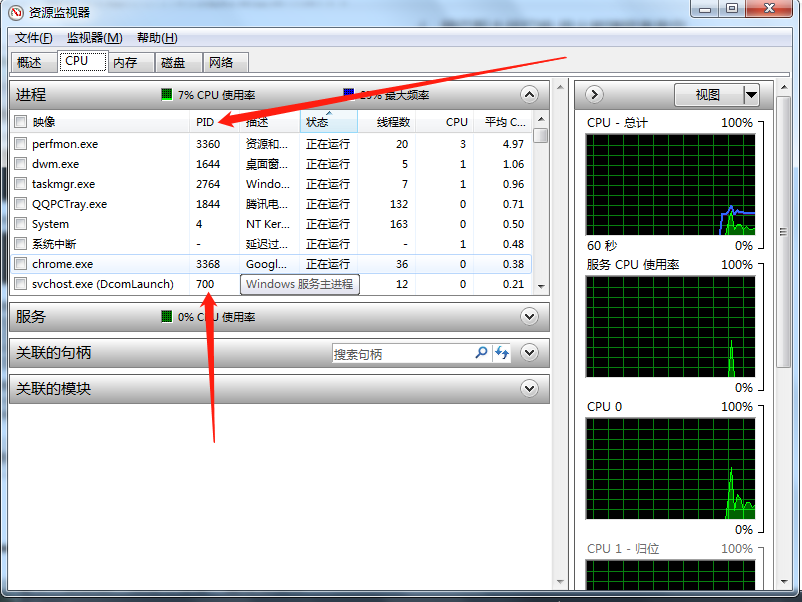
通过资源监视器可以查看CPU占用情况 也就是PID
# 进程作用:我们都知道一个程序运行会创建进程,所以程序在创建这些进程的时候,为了让它们更能有条不紊的工作,肯定也加入了线程
# 那么一条进程里面就会有多个线程协同作战,但是进程不可以创建过多,不然会消耗资源,除非你开发的是一个大型的系统。那么,我们现在就来创建一个进程吧。
二.创建进程
创建进程方法调用模块方法
from multiprocessing import Process
import time
# 定义函数 接受行参 name
def task(name):
print('%s 这个是子进程' % name)
time.sleep(2)
print('%s 子进程2号' % name)
# 创建进程
if __name__ == '__main__': # 创建进程
j = Process(target=task, args=('thn',)) # 调用函数,传参
j.start() # 启动进程
print('这个是进程主进程') # 打印结果
target=task:调用函数
args=('thn',):参数元祖
name:子进程名称
"""
进程打印结果是优先执行主进程在执行子进程
面向对象也一样但是可以修改
不同的系统使用的方法也是不同的
"""
from multiprocessing import Process
import time
# 定义面向对象 创建一类继承Process
class MyProcess(Process):
def __init__(self, name):
self.name = name
super().__init__()
def run(self):
print('子进程',self.name)
time.sleep(2)
print('子进程2号',self.name)
if __name__ == '__main__':
j = MyProcess('thn')
j.start()
print('这是主进程')
三join方法
join让主进程等待子进程结束之后,再执行主进程
from multiprocessing import Process
import time
def task(name,n):
print(f'这是子进程1{name}')
time.sleep(2)
print(f'这是子进程2{name}')
if __name__ == '__main__':
p1 = Process(target=task, args=('黄忠',1))
p2 = Process(target=task, args=('马超', 2))
p3 = Process(target=task, args=('关羽', 3))
p4 = Process(target=task, args=('张飞', 4))
p5 = Process(target=task, args=('赵云', 5))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p1.join()
p2.join()
p3.join()
p4.join()
p5.join()
# join让主进程等待子进程结束之后,再执行主进程。
end_time = time.time() - start_time
print(f'这是主要进程耗时{end_time}')
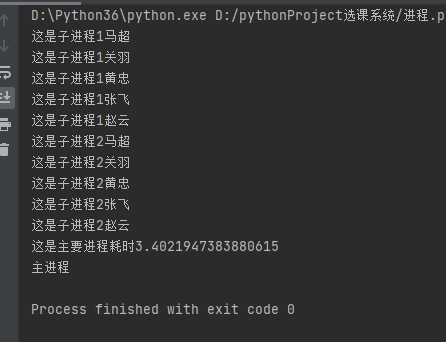
eg:启动了join方法使先运行子进程:会同时等待最后一个子进程结束后执行 主进程,但是内部编号顺序是无序的
四.进程间数据默认隔离
from multiprocessing import Process
x = 99
def task():
global x
x = 333
print(x)
# 1.只有在调用阶段才能 修改全局变量打印333
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(x)
# 2.通过进程隔离了修改打印的永远是99
五.进程对象属性和方法
# 1.查看进程号的两种方法
from multiprocessing import Process, current_process
import os
res = current_process().pid # 查看进程号
res1 = os.getpid() # 查看进程号
print(res) # 6528
print(res1) # 6528
# 2.杀死子进程
tnermiate()
# 3.判断子进程是否存活
is_alive()
六.僵尸进程与孤儿进程(比喻)
1.僵尸进程:
# 所有的子进程在运行结束之后会编程(僵尸)进程(未死但能动)
# 因为还保留着pid和一些运行过程,通过主进程可以短时间内保存
# 但信息时间过长会被注进程进行回收(垃圾回收也好)
1.主进程正常结束后,回收
2.调用join方法,回收
2.孤儿进程
# 子进程还在,主进程意外结束
# 子进成会被操作系统接管(收容所)
七.守护进程
from multiprocessing import Process
import time
def tack(name):
print(f'子进程{name}')
time.sleep(3)
print(f'子进程2{name}')
if __name__ == '__main__':
p = Process(target=tack,args=('哎',))
p.daemon = True # 将子程序设置为守护进程
p.start()
print('主进程')
# 将子程序设置为守护进程主程序接受后 子程序立即结束
八.互斥锁
# 1.什么是互斥锁
2.互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
也就是说,一个进程在进入临界区时应得到锁;它在退出临界区时释放锁。函数 acquire() 获取锁,而函数 release() 释放锁
3.每个互斥锁有一个布尔变量 available,它的值表示锁是否可用。如果锁是可用的,那么调用 acquire() 会成功,并且锁不再可用。当一个进程试图获取不可用的锁时,它会阻塞,直到锁被释放。
4.互斥所
互斥锁加锁失败后,线程会释放CPU,给其他线程。加锁的代码就会被阻塞。
5.自旋锁加锁失败后,线程会忙等待,也就是一直请求加锁,直到它拿到锁
6.读写锁由读锁和写锁两部分构成,如果只读共享资源用读锁加锁,如果需要修改共享资源则用写锁加锁
7.前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很高,但是冲突的概率足够低的话,还是可以接受的。可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号