
第三次作业
目录
1.第一题

1.1主要代码
从当当网页,提取数据,单线程和多线程均使用BeautifulSoup来解析网页。
多线程主要代码:
def load_picture(data, page_num):
global count
if count is None:
count = 0
if not data:
print("页面数据为空,跳过")
return
soup = BeautifulSoup(data, 'lxml')
img_tags = soup.find_all('img')
for img in img_tags:
with lock:
if count >= max_count:
return
img_src = img.get('data-original') ##有点地方的'src'只是一个占位符,所以先提取'data-original'
if (not img_src or
'url_none.png' in img_src or
'erweima' in img_src or
'validate.gif' in img_src or
'logo' in img_src.lower() or
'icon' in img_src.lower()):
continue
if img_src:
if not img_src.startswith('http'):
img_src = 'https:' + img_src
with lock:
if count < max_count:
count += 1
current_count = count
# 简单下载
try:
response = requests.get(img_src, timeout=10)
filename = f'book_images/image_{current_count}.jpg'
with open(filename, 'wb') as f:
f.write(response.content)
print(f"第{page_num}页下载第{current_count}张图片:{img_src}")
except:
print(f"第{page_num}页第{current_count}张图片下载失败")
def crawl_page(page_num):
url = f'https://search.dangdang.com/?key=%CA%E9%B0%FC%D0%A1%D1%A7%C9%FA%C4%D0&act=input&page_index={page_num}'
print(f"正在爬取第{page_num}页...")
html_data = get_html(url)
load_picture(html_data,page_num)
单线程主要代码:
def load_picture(data, page_num):
global count
if count is None:
count = 0
if not data:
print("页面数据为空,跳过")
return
soup = BeautifulSoup(data, 'lxml')
img_tags = soup.find_all('img')
for img in img_tags:
if count >= max_count:
return
img_src = img.get('data-original') # 有的地方的'src'只是一个占位符,所以提取'data-original'
if (not img_src or
'url_none.png' in img_src or
'erweima' in img_src or
'validate.gif' in img_src or
'logo' in img_src.lower() or
'icon' in img_src.lower()):
continue
if img_src:
if not img_src.startswith('http'):
img_src = 'https:' + img_src
if count < max_count:
count += 1
current_count = count
try:
response = requests.get(img_src, timeout=10)
filename = f'book1_images/image_{current_count}.jpg'
with open(filename, 'wb') as f:
f.write(response.content)
print(f"第{page_num}页下载第{current_count}张图片:{img_src}")
except Exception as e:
print(f"第{page_num}页第{current_count}张图片下载失败: {e}")
def crawl_page(page_num):
url = f'https://search.dangdang.com/?key=%CA%E9%B0%FC%D0%A1%D1%A7%C9%FA%C4%D0&act=input&page_index={page_num}'
print(f"正在爬取第{page_num}页...")
html_data = get_html(url)
load_picture(html_data, page_num)
通过上述的代码中可以看出:
-多线程:必须使用 lock = threading.Lock()和在修改 count时使用 with lock:语句块,确保计数准确。
-单线程:不需要锁,直接操作count即可进行计数。
img_src = img.get('data-original') # 有的地方的'src'只是一个占位符,所以提取'data-original'
if (not img_src or
'url_none.png' in img_src or
'erweima' in img_src or
'validate.gif' in img_src or
'logo' in img_src.lower() or
'icon' in img_src.lower()):
continue
同时按照上述方式进行提取,从页面分析来看,提取照片应该使用src,但是特别注意在提取照片时有下面照片未加载,只会放置一个占位符,所以通过src提取并不正确,所以要采用data-original提取真实的图片,以及注意爬取时存在验证码和图标等照片,需要进行排除掉。
1.2实验结果
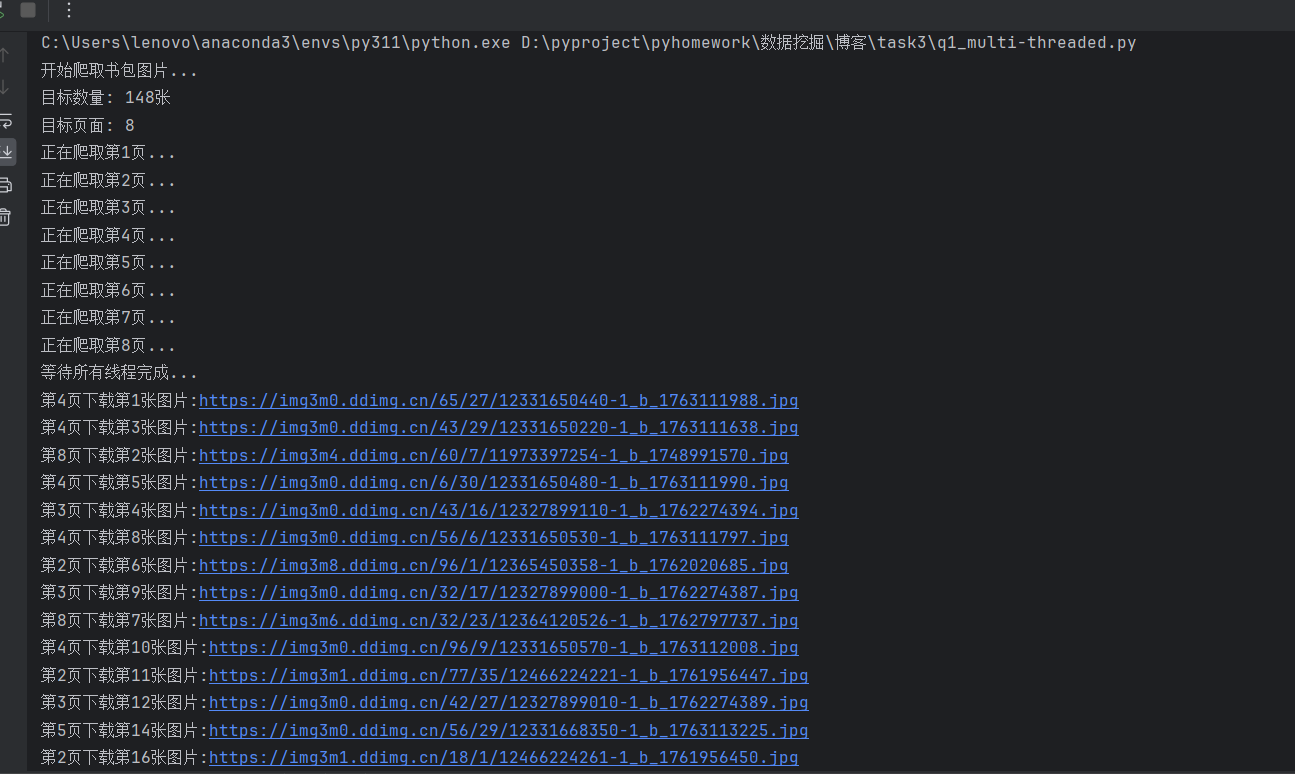

单线程结果:
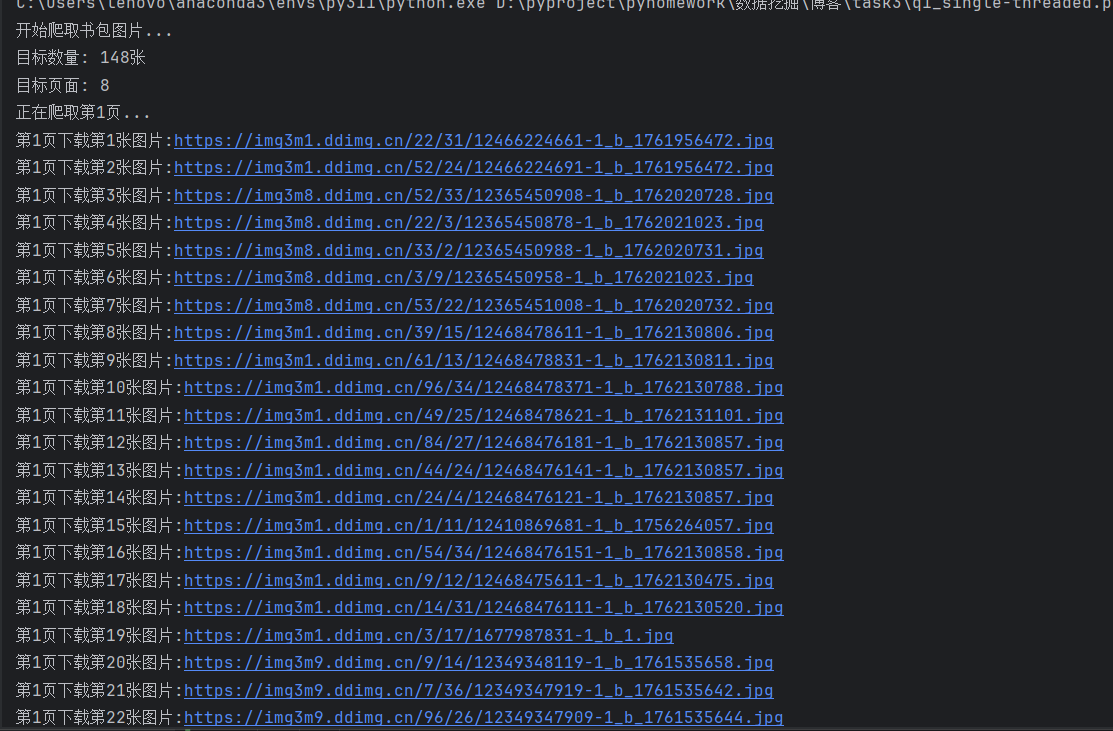

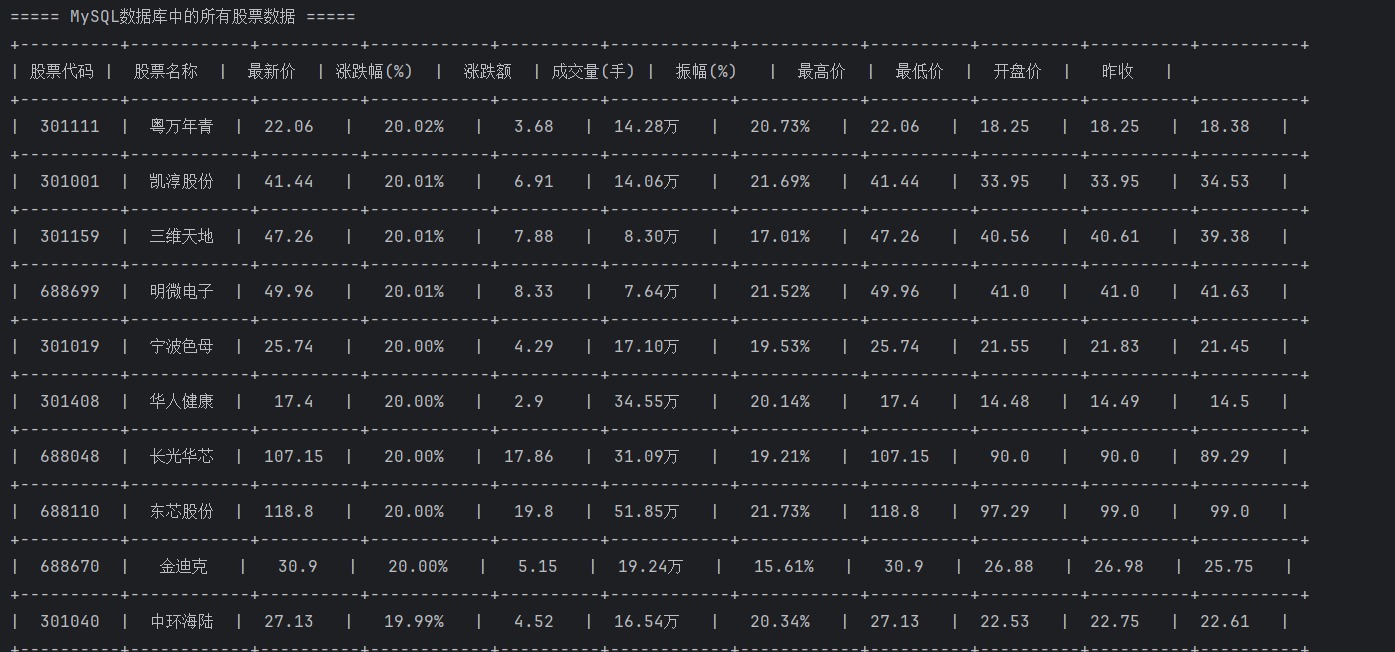
通过上述的运行结果,可以看出单线程是顺序执行:输出日志严格按页码顺序排列。程序完整地处理完第1页的所有22张图片后,才会开始处理第2页。而多线程是并发执行:输出日志杂乱无章。程序几乎同时启动了所有8个页面的爬取任务。日志中先后顺序为“第4页 -> 第8页 -> 第3页 -> 第2页 -> 第5页”,完全打乱了页码顺序。
1.3心得提会
在本次实验中我们能够明显感觉到,多线程的执行效率要远高于单线程,多线程能极大提升I/O密集型任务的效率,但是多线程也引入了复杂度,需重点解决“线程安全”问题,所以必须引入锁。所以当任务量小,对执行时间不敏感的实验可以首选单线程,当需要处理大量I/O操作、对性能有较高要求是便应该选择多线程。
2.第二题

可以看出图中网站是动态页面,所以并不能直接对HTML进行爬取数据,因此需要在scrapy架构里面的midleware中,加入selenium来模拟浏览器来进行读取。
2.1主要代码
class EastmoneySpider(scrapy.Spider):
name = 'mySpider'
allowed_domains = ['eastmoney.com']
def start_requests(self):
url = "https://quote.eastmoney.com/center/gridlist.html#hs_a_board"
yield scrapy.Request(url, self.parse)
#对解析后的网页中的数据进行提取
def parse(self, response):
stock_rows = response.xpath('//table//tbody/tr[td[2]/a[contains(@href, "quote.eastmoney.com")]]')
count = 0
for row in stock_rows:
item = DemoItem()
item['stock_code'] = row.xpath('.//td[2]//a/text()').get(default='').strip()
item['stock_name'] = row.xpath('.//td[3]//a/text()').get(default='').strip()
# 提取价格数据
item['last_price'] = row.xpath('.//td[5]//text()').get()
item['change_percent'] = row.xpath('.//td[6]//text()').get(default='').strip()
item['change_amount'] = row.xpath('.//td[7]//text()').get(default='').strip()
item['volume'] = row.xpath('.//td[8]//text()').get(default='').strip()
item['amplitude'] = row.xpath('.//td[10]//text()').get()
item['high_price'] = row.xpath('.//td[11]//text()').get()
item['low_price'] = row.xpath('.//td[12]//text()').get()
item['open_price'] = row.xpath('.//td[13]//text()').get()
item['close_price'] = row.xpath('.//td[14]//text()').get()
count += 1
yield item
在使用Xpath提取时,使用:
'//table//tbody/tr[td[2]/a[contains(@href, "quote.eastmoney.com")]]'相当于加上一个过滤条件,表示tr标签下的的td[2]下的a标签,有一个href属性的可以,进行进一步限制。否则会出现一行题头,应该给过滤掉。
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import logging
class SeleniumMiddleware:
#selenium中间件类,用于处理需要JavaScript渲染的动态网页
def __init__(self):#初始化方法,创建浏览器驱动实例
#使用绝对路径给出驱动位置
edge_driver_path = r'C:\Users\lenovo\anaconda3\envs\py311\Scripts\msedgedriver.exe'
service = Service(edge_driver_path)
self.driver = webdriver.Edge(service=service)
self.logger = logging.getLogger(__name__)
self.logger.info(f"已使用路径 {edge_driver_path} 初始化驱动")
@classmethod
def from_crawler(cls, crawler):
middleware = cls()
crawler.signals.connect(middleware.spider_closed, signal=signals.spider_closed)
return middleware
def process_request(self, request, spider):
# 检查请求URL是否包含'eastmoney.com',只处理东方财富网的请求
if 'eastmoney.com' in request.url:
self.driver.get(request.url)
try:
wait = WebDriverWait(self.driver, 15)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "table")))
self.logger.info("股票数据表格已加载")
except Exception as e:
spider.logger.warning(f"等待数据加载超时: {e}")
time.sleep(3)
body = self.driver.page_source.encode('utf-8')
return HtmlResponse(self.driver.current_url, body=body, encoding='utf-8', request=request)
def spider_closed(self, spider):
self.logger.info("正在关闭浏览器...")
if hasattr(self, 'driver'):
self.driver.quit()
self.logger.info("浏览器已关闭")
东方财富网大量使用JavaScript动态加载数据,普通爬虫只能获取初始HTML,无法拿到完整的股票数据。因此使用selenium进行处理动态页面
2.2实验结果
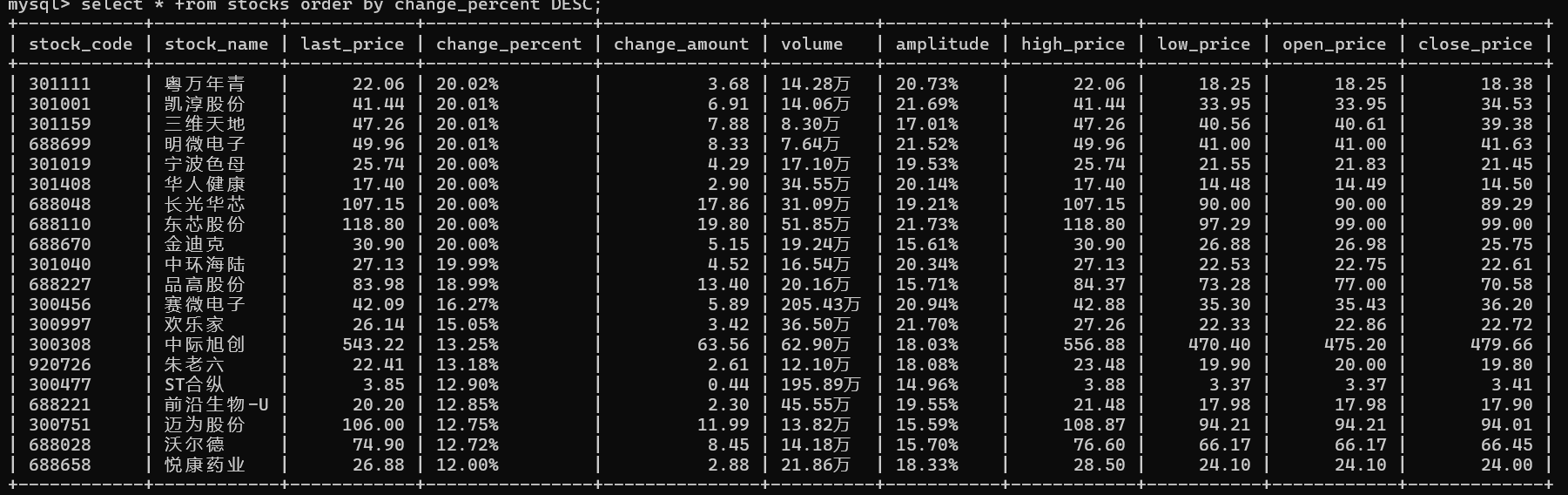
终端输出:
2.3心得体会
本次实验中相比于上次作业的找到API,抓取数据包里面,使用Selenium可以直接爬取数据,而不需要像上次一样,再对数据单位和格式进行转化,同时通过这次实验,感受到了Scrapy 擅长批量爬取静态页面,框架完善且效率高,非常适合结构化数据提取,Selenium 能模拟浏览器行为,轻松破解动态渲染和 JS 加载,用 Scrapy 搭建爬虫架构保证效率,遇动态内容时嵌入 Selenium 处理渲染。。
3.第三题

第三题并不是一个动态页面,因此可以直接进行对HTML进行提取操作
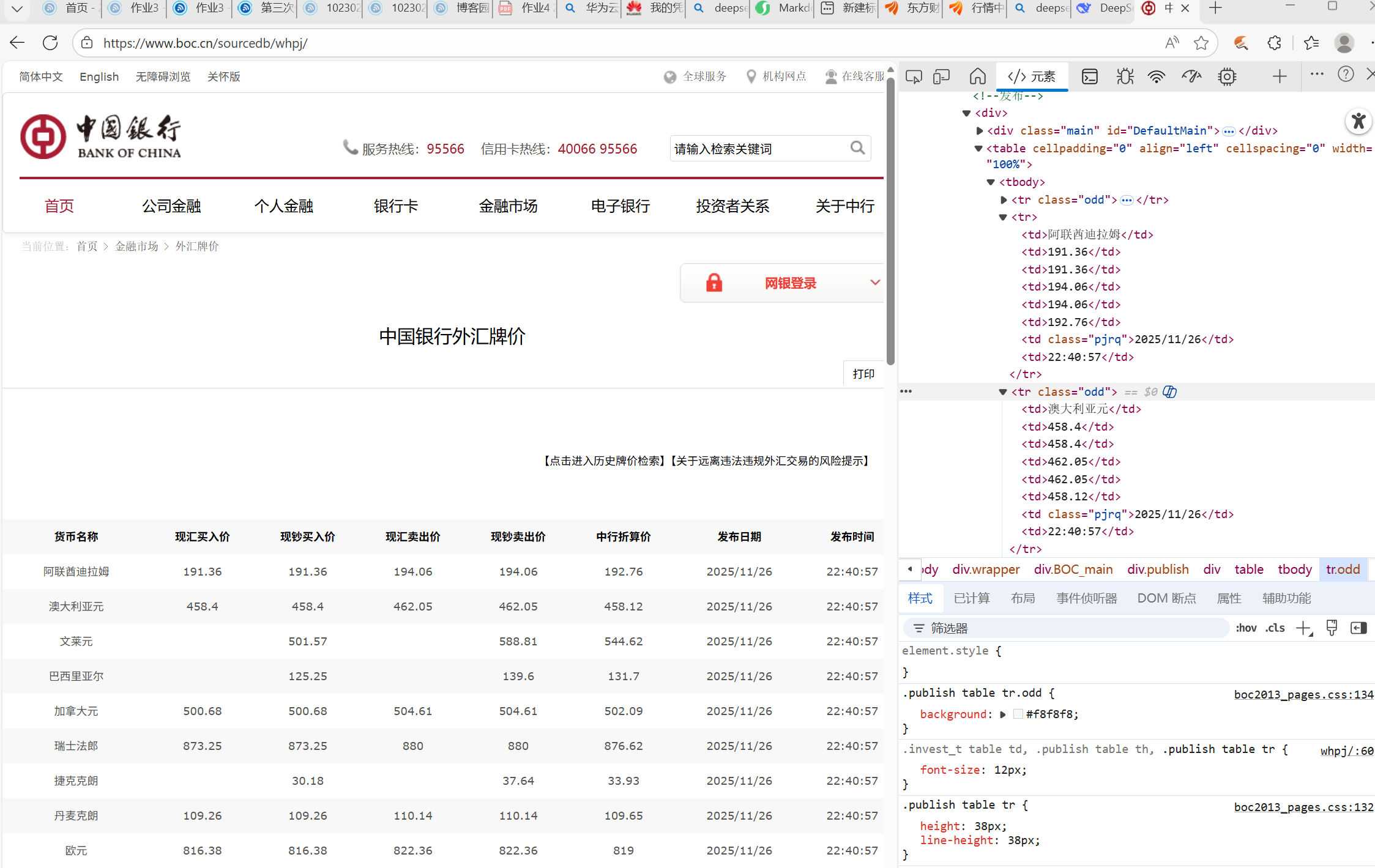
3.1主要代码
import scrapy
from blanks.items import BlanksItem
class Blankspider(scrapy.Spider):
name = 'mySpider'
allowed_domains = ['boc.cn']
def start_requests(self):
url= "https://www.boc.cn/sourcedb/whpj/"
yield scrapy.Request(url,self.parse)
def parse(self, response):
blank_rows = response.xpath('//tr[td[1] and td[7][contains(@class, "pjrq")]]')
count=0
for row in blank_rows:
item = BlanksItem()
item['current'] = row.xpath('./td[1]/text()').get(default='').strip()
item['spot_buy'] = row.xpath('./td[2]/text()').get(default='').strip()
item['cash_buy'] = row.xpath('./td[3]/text()').get(default='').strip()
item['spot_sell'] = row.xpath('./td[4]/text()').get(default='').strip()
item['cash_sell'] = row.xpath('./td[5]/text()').get(default='').strip()
item['bank_rate'] = row.xpath('./td[6]/text()').get(default='').strip()
full_date = row.xpath('./td[7]/text()').get(default='').strip()
publish_date = full_date.split(' ')[0]
item['publish_date'] = publish_date
item['publish_time'] = row.xpath('./td[8]/text()').get(default='').strip()
count +=1
yield item
在使用Xpath提取时,需要使用:
'//tr[td[1] and td[7][contains(@class, "pjrq")]]',筛选掉第一个tr标签,因为第一个并不是我们需要的,而是题头,以及在提取日期时,要进行分割。
class BlanksPipeline:
def __init__(self):
self.db = None
self.cursor = None
def open_spider(self, spider):
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='826922',
database='stocks_db',
charset='utf8mb4',
port=3306
)
self.cursor = self.db.cursor()
spider.logger.info("MySQL数据库连接成功")
# 连接成功后才创建表
self.create_table(spider)
except Exception as e:
spider.logger.error(f"MySQL连接失败: {e}")
self.db = None
self.cursor = None
def create_table(self, spider):
try:
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS exchange_rates (
id INTEGER PRIMARY KEY AUTO_INCREMENT,
current VARCHAR(50) NOT NULL,
spot_buy DECIMAL(10,2),
cash_buy DECIMAL(10,2),
spot_sell DECIMAL(10,2),
cash_sell DECIMAL(10,2),
bank_rate DECIMAL(10,2),
publish_date DATE NOT NULL,
publish_time TIME,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(current, publish_date)
)
""")
spider.logger.info("数据表 stocks 创建成功或已存在")
except Exception as e:
spider.logger.error(f"创建表失败: {e}")
def process_item(self, item, spider):
if not self.db or not self.cursor:
spider.logger.error("数据库未连接,跳过数据插入")
return item
adapter = ItemAdapter(item)
try:
# 2. 插入数据到数据库
self.cursor.execute('''
REPLACE INTO exchange_rates (
current, spot_buy, cash_buy, spot_sell, cash_sell,
bank_rate, publish_date, publish_time
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
''', (
adapter.get('current'),
adapter.get('spot_buy') or None, # 空值存为 NULL
adapter.get('cash_buy') or None,
adapter.get('spot_sell') or None,
adapter.get('cash_sell') or None,
adapter.get('bank_rate') or None,
adapter.get('publish_date'),
adapter.get('publish_time') or None
))
self.db.commit()
spider.logger.debug(f"数据插入成功: {adapter.get('current')}")
except Exception as e:
self.db.rollback()
spider.logger.error(f"数据插入失败: {e}")
return item
def close_spider(self, spider):
# 关闭数据库连接
if self.db:
self.db.close()
spider.logger.info("数据库连接已关闭")
多插入一些info便于找出问题的存在,这一点很重要。
3.2实验结果
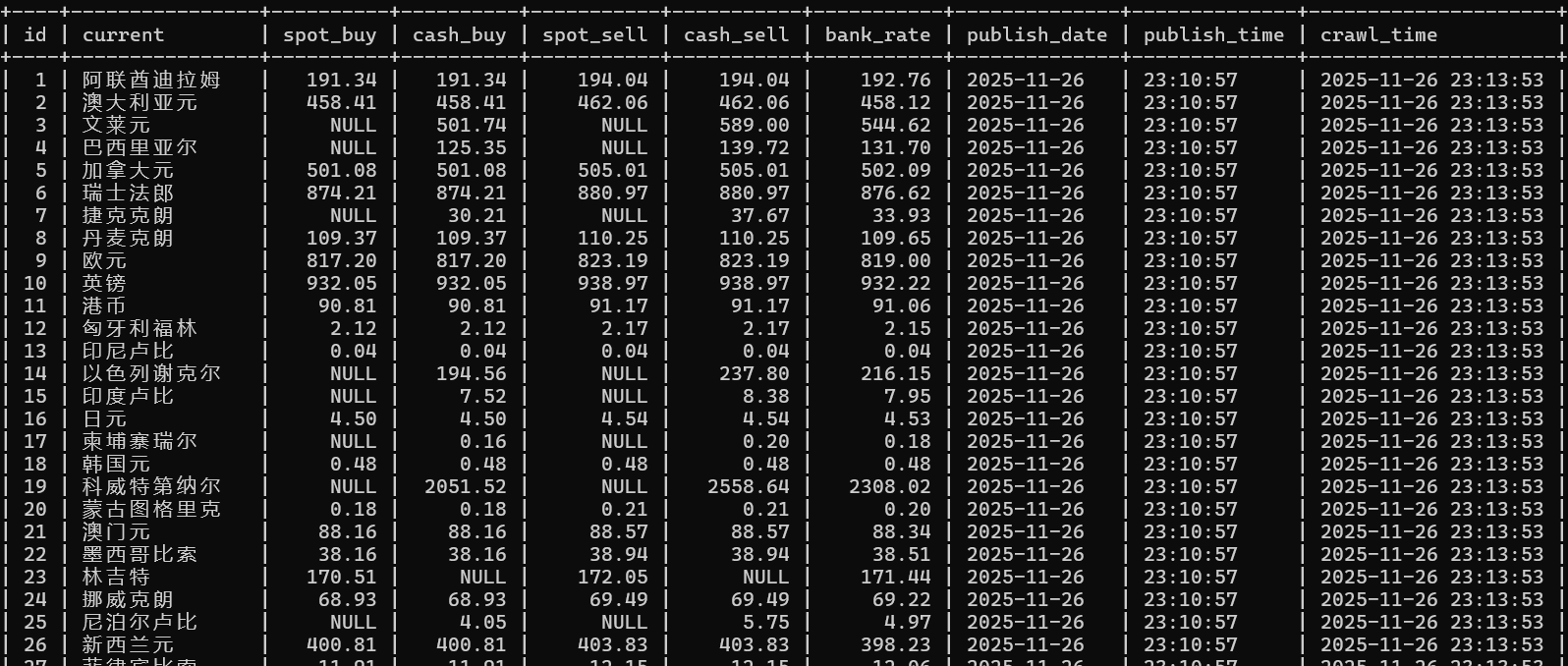
3.3心得体会
本次的页面并非动态页面,可以直接使用Scrapy 框架结合 XPath 精准提取了货币名称、现汇买入价、现钞卖出价等核心字段,再借助 Pipeline 将数据有序存储到 MySQL 数据库,通过本次实验,我更加认识到Scrapy 擅长批量爬取静态页面,框架完善且效率高,对于结构化数据提取非常适合,Scrapy框架的分工明显。同时通过这次实验让我认识到,一个完整的数据爬取项目需要各组件的紧密配合,从数据提取到持久化存储的每个环节都至关重要,为后续复杂爬虫开发奠定了坚实基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号