
102302148谢文杰第一次数据采集作业
第一题
核心代码与运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
# 目标URL:2020年中国大学排名页面
url="http://www.shanghairanking.cn/rankings/bcur/2020"
response=requests.get(url)
response.encoding="utf-8"
soup=BeautifulSoup(response.text,"html.parser")
# 查找所有大学数据行:通过特定的data属性定位包含大学信息的表格行
university_rows = soup.find_all('tr', attrs={'data-v-389300f0': ''})
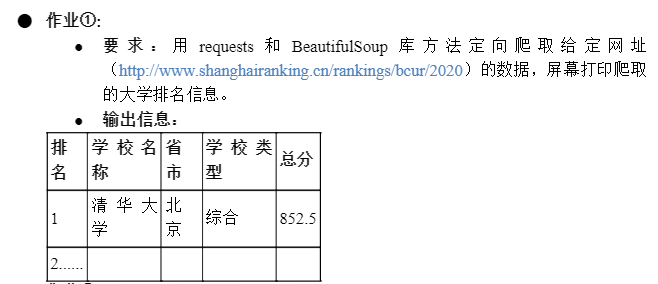
print("排名 学校名称\t\t省市\t类型\t总分")
print("-"*50)
#提取排名,名称,省市,类型,总分
for row in university_rows:
rank_div=row.find("div", class_= "ranking")
if rank_div:
cells = row.find_all('td')
# print(cells)
if len(cells)>=5:
rank=rank_div.get_text().strip()
name_cn=cells[1].find("span", class_="name-cn")
university = name_cn.get_text().strip() if name_cn else "未知"
province = cells[2].get_text().strip()
school_type = cells[3].get_text().strip()
score_school = cells[4].get_text().strip()
print(f"{rank:>2} {university:12} {province:6} {school_type:4} {score_school:4}")
实验成功实现了网页内容获取、编码处理和数据提取等基础功能。通过分析HTML结构,发现大学数据行具有特定的data-v-389300f0属性,利用这一特征成功定位到所有大学信息行,并准确提取出排名、学校名称、省市、类型和总分等关键信息。在数据提取过程中,针对复杂的嵌套标签结构,采用了多层次的查找方法,确保信息获取的准确性。
实验心得
本次实验通过Python的requests和BeautifulSoup库爬取软科中国大学排名网站数据,成功实现了对大学排名信息的提取,但在实践过程中也遇到了显著的技术挑战。
实验过程中遇到了动态内容加载这一关键技术瓶颈。由于目标网站采用JavaScript动态加载内容,传统的requests+BeautifulSoup组合存在明显局限,无法获取通过JS加载的分页数据,只能提取到第一页的静态内容。这种技术限制主要体现在三个方面:requests库只能获取初始HTML而无法执行JavaScript;分页内容通过AJAX请求加载,需要额外分析网络请求;无法模拟用户交互行为如点击下一页操作。这些限制导致无法获得完整的排名数据,影响了数据的全面性。可以使用Selenium等自动化包爬。
通过本次实验,我在技术层面加深了对HTML DOM结构的理解,掌握了BeautifulSoup的多种查找方法,学会了处理复杂嵌套标签结构的技巧,同时认识到静态爬虫与动态网站的技术差异。在实践层面,理解了网站反爬机制的存在意义,学会了分析网页结构定位目标数据的方法。
第二题

核心代码与运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import re
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
response = requests.get(url)
response.encoding = "gbk"
html = response.text
# 正则提取商品名称和价格
product_pattern = r'<li[^>]*ddt-pit="\d+"[^>]*class="line\d+"[^>]*>.*?</li>'
product_matches = re.findall(product_pattern, html, re.S)
print("序号 价格\t\t\t\t\t\t\t 商品名称")
for item in product_matches:
#提取商品序号
ddt_pit_pattern = r'ddt-pit="(\d+)"'
ddt_pit_match = re.search(ddt_pit_pattern, item)
ddt_pit = ddt_pit_match.group(1) if ddt_pit_match else "未知"
#提取商品文字介绍
title_pattern = r'<a title="([^"]+)"'
ddt_title_match = re.search(title_pattern, item)
ddt_title = ddt_title_match.group(1) if ddt_title_match else "未知"
#提取出商品的价格
price_pattern = r'<span class="price_n">\s*¥\s*([\d.]+)\s*</span>'
ddt_price_match = re.search(price_pattern,item)
ddt_price = ddt_price_match.group(1) if ddt_price_match else "未知"
print(f"{ddt_pit:>2} {ddt_price:>6} {ddt_title:35}")

实验心得
实验过程中遇到的主要挑战在于HTML结构的复杂性和数据格式的不一致性。在提取商品价格时,发现网页中使用的是HTML实体“¥”;而非直接的¥符号,这要求正则表达式必须适配这种特殊编码。同时,商品标题的长度不一也给输出排版带来了困难,需要通过字符串格式化控制显示宽度。通过不断调试正则表达式模式,最终实现了数据的准确提取和整齐的表格化输出。
这次实验让我深刻认识到,在实际网络爬虫开发中,网页结构的微小变化都可能对数据提取产生重大影响。正则表达式虽然强大灵活,但也容易因网页结构变动而失效,需要谨慎使用并配合其他解析方法。未来可以考虑引入更稳定的解析方式。
第三题

核心代码和运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin
# 创建保存图片的文件夹,如果已存在则不会报错
os.makedirs('fzu_images', exist_ok=True)
# 遍历6个页面,从第1页到第6页
for page in range(0, 6):
# 构造页面URL:第1页特殊处理,其他页按规律生成
url = f'https://news.fzu.edu.cn/yxfd/{page}.htm' if page >= 1 else 'https://news.fzu.edu.cn/yxfd.htm'
print(f"处理页面: {url}")
# 发送GET请求获取页面内容
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有包含图片的div元素,class为'img slow'
for img in soup.find_all('div', class_='img slow'):
img_tag = img.find('img')
if img_tag and img_tag.get('src'):
img_url = urljoin(url, img_tag['src'])
# 检查图片格式,只下载jpg、jpeg、png格式
if any(img_url.lower().endswith(ext) for ext in ['.jpg', '.jpeg', '.png']):
try:
# 下载图片内容
img_data = requests.get(img_url).content
filename = os.path.basename(img_url)
filepath = os.path.join('fzu_images', filename)
# 处理重复文件名:如果文件已存在,在文件名后添加数字
counter = 1
original_path = filepath
while os.path.exists(filepath):
name, ext = os.path.splitext(original_path)
filepath = f"{name}_{counter}{ext}"
counter += 1
# 以二进制写入模式保存图片
with open(filepath, 'wb') as f:
f.write(img_data)
print(f" 已下载: {os.path.basename(filepath)}")
except Exception as e:
print(f" 下载失败: {e}")
print("所有图片下载完成!保存在 'fzu_images' 文件夹中")
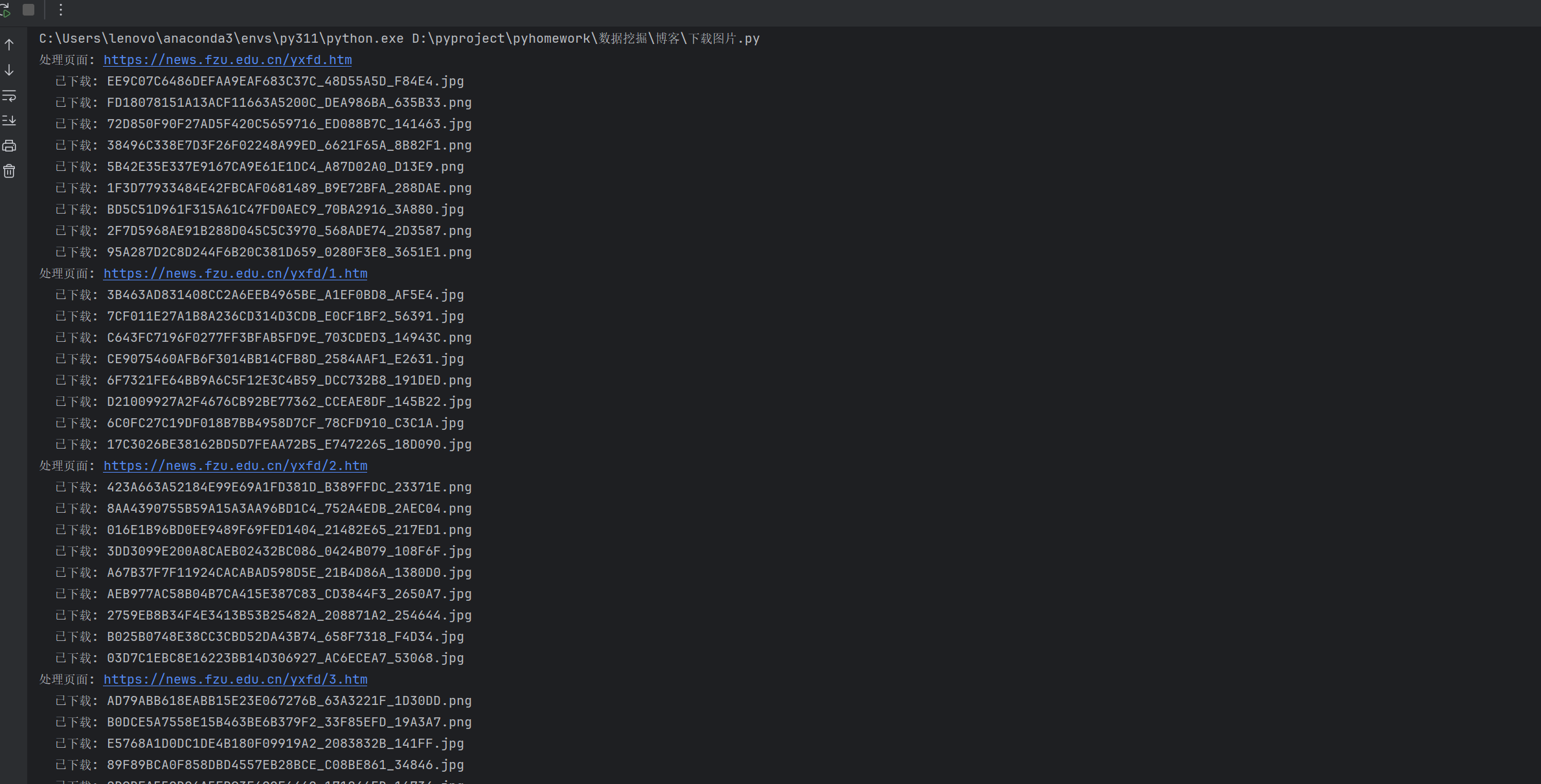
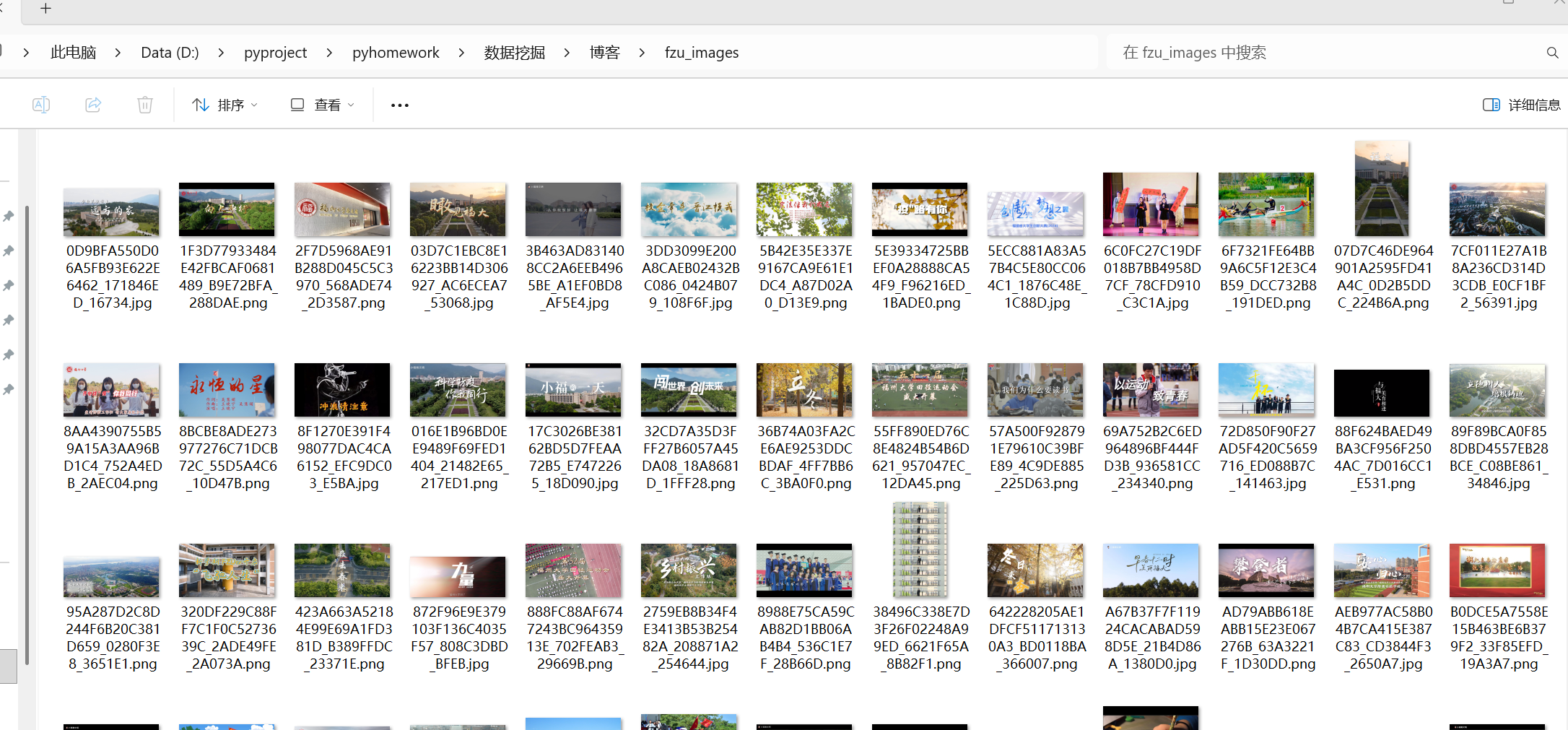
实验心得
本次实验通过Python实现了对福州大学新闻网站图片的自动化批量下载,掌握了网络爬虫和文件操作的核心技术。在实验中,我运用requests库进行网页请求、BeautifulSoup解析HTML内容、os模块管理文件,构建了一套完整的图片采集系统。
关键技术包括URL智能拼接、网页内容解析、图片格式筛选和文件命名去重处理。通过循环遍历多个页面实现批量下载,urljoin函数确保相对路径正确转换,文件命名机制避免重复覆盖。实验过程中,网页编码设置、异常捕获和文件去重等细节处理让我认识到健壮爬虫需要考虑各种边界情况。
通过本次实践,我掌握了静态网页图片采集流程,理解了HTTP请求响应机制,熟悉了HTML解析和文件操作技巧,为后续复杂网络数据采集项目奠定了基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号