
cutlass & FA3
GPU mode: Cutlass and FA 3
本次talk的大纲:
- 复习attention和FA
- 从高层次理解FA3算法
- 将算法翻译成cutlass搭建的code
attention机制介绍
$$O=Softmax(QK^T)V$$
attention随着序列长度的变化是二次的scale。
naive的实现受限于内存的读写,会先将$QK^T$的结果存入HBM,之后进行softmax操作时再将其从HBM读取。
GPU的存储模式和内存层级
输入首先存储在HBM中,之后数据会移入计算单元和SRAM来进行计算,最后将结果写入HBM。
如何减少HBM的读和写
使用tiling和recomputation
挑战:
- 不将score matrix materialize(完整计算出来)到HBM,只计算部分输入的softmax。
- backward的时候没有了score matrix
方法:
- 使用tiling和online softmax来进行kernel fusion: 对于Q的一个给定的tile,逐块加载KV的block
- 重算: 不去将attn matrix 存储,而是在backward时重算。
FA2在H100上只能有35-40%的利用率
FA3
-
H100的新指令:
- wgmma: 更高throughput的mma原语, async, 可以由一个warpgroup(=4个连续的warps)一起执行
- TMA: 提供gmem和smem之间更快速的loading, async, saves registers
-
Async
- builds on async wgmma, tma, transaction barrier
- inter-warpgroup overlapping: warp-specialization, pingpong
- intra-warpgroup overlapping: softmax, async matmul
-
low-precision: fp8, in-kernel V transpose
最基本的思想是利用生产者和消费者模型,生产者主要提供对应的KV相应的分块;消费者就执行对应的计算。
我们再研究下async: overlap gemm和softmax
我们主要想让tensor cores忙的时候也做一些ex2的计算。
inter-warpgroup
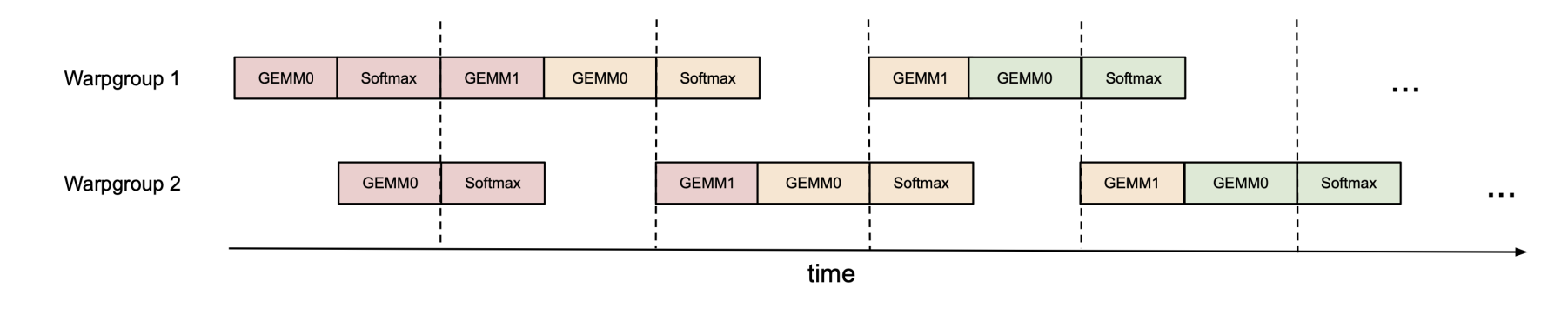
intra-warpgroup

FP8
f8可以达到两倍的wgmma的吞吐,但是tradeoff了精度
fp8 wgmma: 要求操作数 smem tensors是在k-major的
标准的attention通常是bshd;对于gemm0 $QK^T$这是好的;都在d连续;但对于gemm1$PV$,我们需要转置V。解法是在producer warpgroup中transpose V。使用ldsm/stsm等指令,输入自定义的layout以及byte permute
我们也需要reshape scores accumulator的layout;fp32的accumulator不同于fp8 操作数A的layout
注意:我们能使用in-kernel transpose 来进行V的row permutation,避免使用shuffle 指令。
persistent kernels in FA
想法:launch固定数量的CTA,能够overlap 当前work tile的epilogue以及下一个work tile 的 prologue loads.
FA3 for decoding inference
对于decoding来说,q的length为1,但是context length很长。
优化:
- 对 KV 的序列长度进行划分;得到并行
- GQA pack: 将多个query heads pack为单个的query tile
flash decoding和flash attention的区别是,原始的flash attention直接对Q的长度进行分块,每个CTA计算Q块的结果;而在decoding阶段,Q的长度很小,那么我们对KV的长度分块,最后将结果累加即可。
可能想问原始的flash attention为什么不继续对KV做并行?
Flash Attention的并行维度已饱和
训练时通常通过数据并行(Batch) + 张量并行(Heads) 实现多级并行,占用大量SM资源。对Q分块并行已能有效利用计算单元,无需额外引入KV分块。
Flash Decoding需应对长KV缓存
生成式推理的KV_len可能远超GPU核心数(如数万token),必须分块并行处理才能避免单CTA过载,同时隐藏内存访问延迟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号