lincoln_transformer阅读介绍
核心结论
本文针对消费级设备无法实时运行50∼100B大语言模型(LLM)的问题,提出设备-架构协同设计方案Lincoln,通过优化Flash存储性能和数据传输机制,在不损失模型精度的前提下实现该目标。
背景与痛点
- 现有LLM服务多依赖云端,存在隐私风险、延迟高、服务不稳定等问题,且厂商运维成本高昂。
- 消费级设备因DRAM容量有限(≤64GB),需将大模型权重存储在Flash中,而Flash的低带宽(仅为DRAM的1/10)导致数据加载成为推理瓶颈,即使经量化等优化也只能支持<13B的小模型。
- Flash性能不足源于两大核心问题:NPU与Flash间的传输接口带宽低,以及Flash存储阵列的内部带宽低。
Lincoln方案设计
设备级优化(提升Flash内部带宽)
- 采用阵列缩减技术,使用更小的SLC阵列,缩短读取延迟(<4us)并增加单芯片并行平面数(最多32个),单芯片读取带宽达∼34GBps,16个芯片可达∼500GBps。
- 结合混合键合技术实现3D堆叠,在Flash层下方集成逻辑层,在不增加芯片尺寸或降低存储密度的前提下,将平面数翻倍。
- 同步解决并行平面运行带来的供电问题。
架构级优化(缓解传输瓶颈)
- 预填充阶段(计算密集型):复用LPDDR DRAM的高速接口和封装,将Flash芯片与DRAM芯片垂直堆叠在LPDDR封装中,使传输带宽提升至>100GBps;通过SRAM缓冲、双缓冲重叠延迟、近Flash ECC替换控制器ECC等方式,解决Flash访问延迟和时序问题。
- 生成阶段(内存密集型):利用混合键合的逻辑层集成近Flash计算单元和ECC引擎,充分发挥Flash内部高带宽;结合推测解码技术,单次迭代可生成多个token,满足实时性要求。
- 额外优化:通过轮询分布权重矩阵、Flash侧延迟隐藏缓冲解决数据布局问题,用读取回收应对读取干扰,经评估散热和存储耐久性均满足要求。
方案效果
Lincoln可支持消费级设备实时运行50∼100B规模的LLM,且不损失原始精度;相比传统SSD系统,预填充阶段速度提升最高13.23倍,生成阶段最高254.1倍。
⸻
🧠 一、Decoder 的整体结构
一个 Transformer Decoder 层通常由以下几个主要部分组成:
输入 → 自注意力(Self-Attention) → 交叉注意力(Cross-Attention)
→ 前馈全连接层(Feed-Forward Network, FFN)
→ 输出
其中,每一层都包含:
• 残差连接 (Residual Connection)
• 层归一化 (Layer Normalization)
⸻
🔹1. 生成方式(线性变换)
对于输入向量
通过三个线性层:
其中:
一般:
其中 h 是多头数(multi-head)。
⸻
🔹2. 计算注意力分数 (Logit)
得到 Q, K, V 之后,计算每个 Query 对所有 Key 的相关性分数:
这个就是所谓的 attention logit,表示 Query 和 Key 的匹配程度。
除以 \sqrt{d_k} 是为了防止内积值过大导致梯度不稳定。
⸻
🔹3. Softmax:计算注意力权重
将上一步的 logit 通过 softmax 变换成概率分布:
此时每一行的和为 1,表示 Query 对所有 Key 的“关注度分配”。
⸻
🔹4. Attend:加权求和得到注意力输出
将权重矩阵乘以 V:
这样就得到了每个 Query 的“聚合信息”——
它根据注意力权重从所有 Value 中取加权平均。
⸻
🔹5. Projection(输出投影)
在多头注意力 (Multi-Head Attention) 中,我们会有多个头,每个头独立执行上述过程。
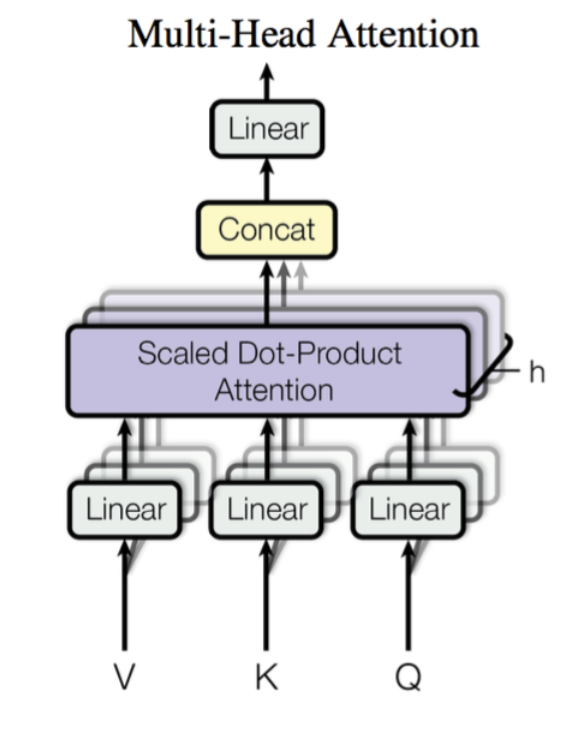
假设有 h 个头:
然后拼接:
其中:
这个线性层 W_O 就是 Projection(输出映射层)。
⸻
🔹6. FFN(Feed Forward Network,全连接前馈层)
经过注意力层后,每个位置的向量再单独经过一个两层的前馈网络:
等价于:
其中:
• W_1, b_1:第一层全连接层的权重和偏置;
• W_2, b_2:第二层全连接层的权重和偏置;
• f(\cdot):激活函数(通常是 ReLU 或 GELU)。
分步形式为:
1️⃣ 第一层全连接:
2️⃣ 激活函数:
3️⃣ 第二层全连接:
输出结果 y 具有与输入相同的维度 d_{\text{model}}。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号