



3123004806软件工程查重项目
3123004806软件工程个人项目
| 这个作业属于哪个课程 | <https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024> |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <设计一个能处理长文本的论文查重算法> |
GitHub链接:xuuuyueyue/3123004806: 软件工程作业
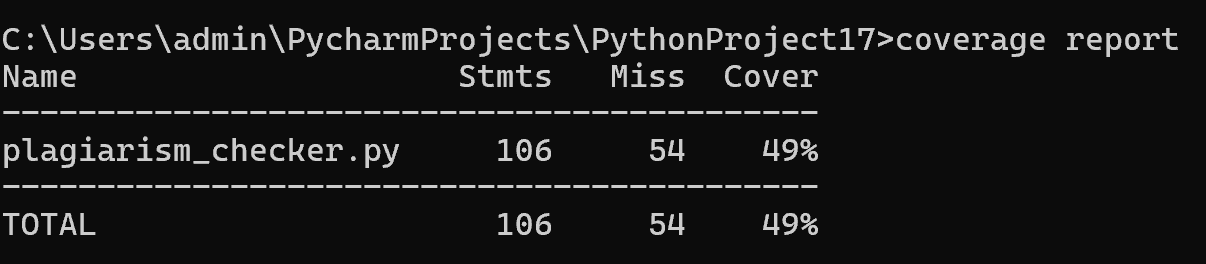
测试环境为python 3.12
PSP表格相关记录
| PSP2 1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| Estimate | 估计这个任务需要多少时间 | 330 | 480 |
| Development | 开发 | 15 | 30 |
| Analysis | 需求分析(包括学习新技术) | 30 | 45 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 | 15 | 15 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 120 | 200 |
| Code Review | 代码复审 | 5 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 15 | 30 |
| Reporting | 报告 | 15 | 15 |
| Test Report | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 10 |
模块接口的设计与实现过程
一、设计概述
本系统基于词袋模型与余弦相似度算法,实现了文本查重功能。通过面向对象的方式设计 PlagiarismChecker 类,对文本的预处理、特征提取、相似度计算、以及查重结果输出等功能进行了模块化封装。程序主流程由 main() 函数控制,同时支持性能分析模式,便于评估系统性能瓶颈。
流程图如下
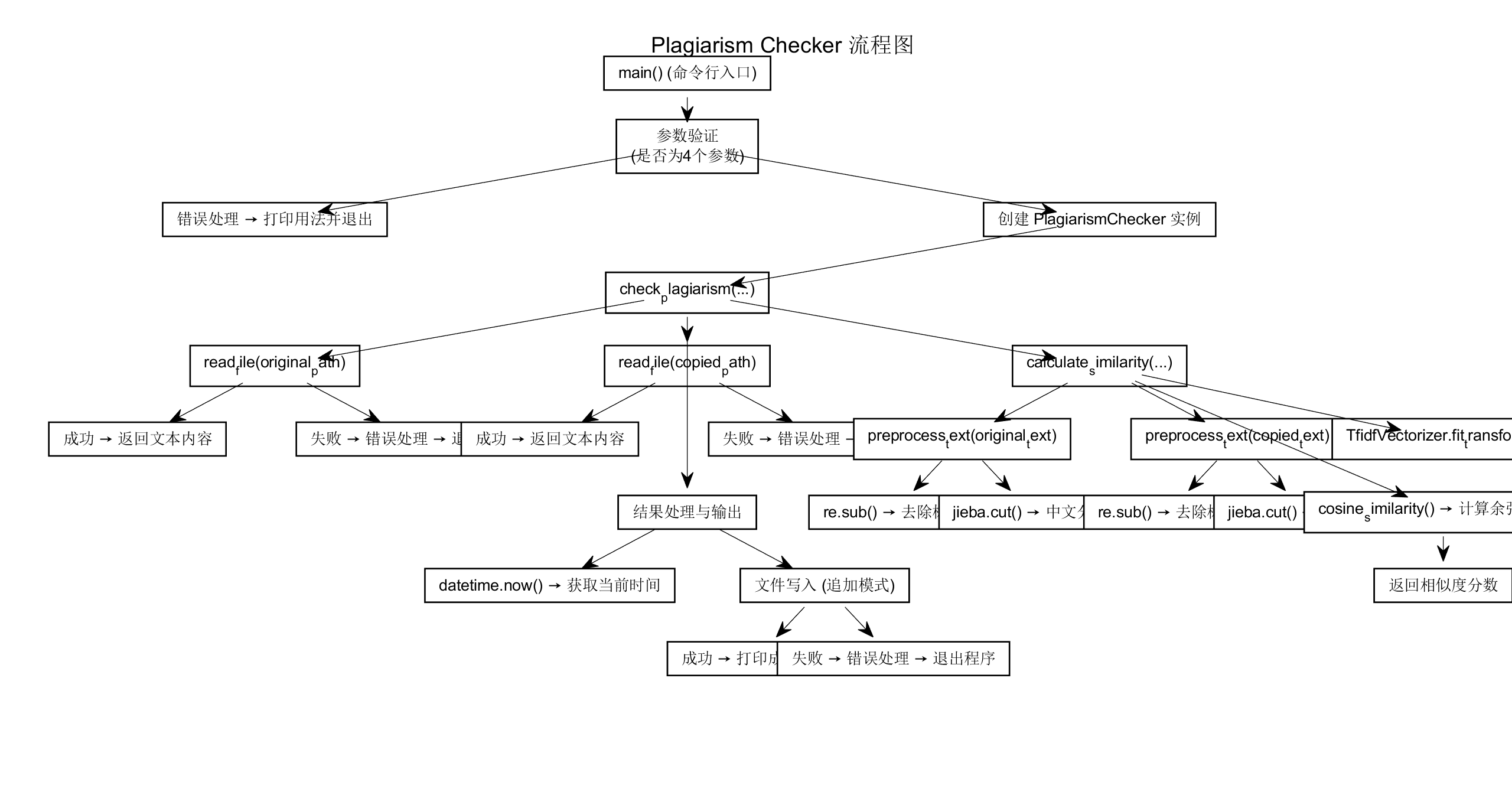
二、核心类与函数设计
PlagiarismChecker 类
该类封装了文本预处理、相似度计算和查重逻辑。核心方法如下:
__init__()
初始化方法,创建 TF-IDF 向量器实例。read_file(file_path)
负责读取指定路径的文件内容,带异常处理,确保程序稳健性。preprocess_text(text)
对文本进行预处理,包括:去除标点符号;使用jieba进行中文分词;返回词语之间用空格分隔的字符串,供后续向量化处理。calculate_similarity(original_text, copied_text)
计算两个文本的相似度:分别进行预处理;使用TfidfVectorizer构建向量;使用cosine_similarity计算余弦相似度;返回一个[0, 1]区间的相似度分数。check_plagiarism(original_path, copied_path, output_path)
主查重方法,负责整体流程:加载原文与抄袭文本;计算相似度;生成当前时间;结果追加写入输出文件;控制台反馈重复率与输出状态。
三、辅助函数模块
run_performance_analysis()
性能测试模块,提供三种分析方式:
- 方法1 - 使用 cProfile 追踪函数调用开销
- 方法2 - 手动统计运行时间
- 方法3 - 函数级时间分析
四、主控制函数
main()
程序的入口函数,主要职责如下:
1,解析命令行参数;
2,判断是否进入 --profile 性能分析模式;
3,验证参数合法性;
4,创建 PlagiarismChecker 实例并执行查重。
接口性能改进对比
最初始的代码的性能如图
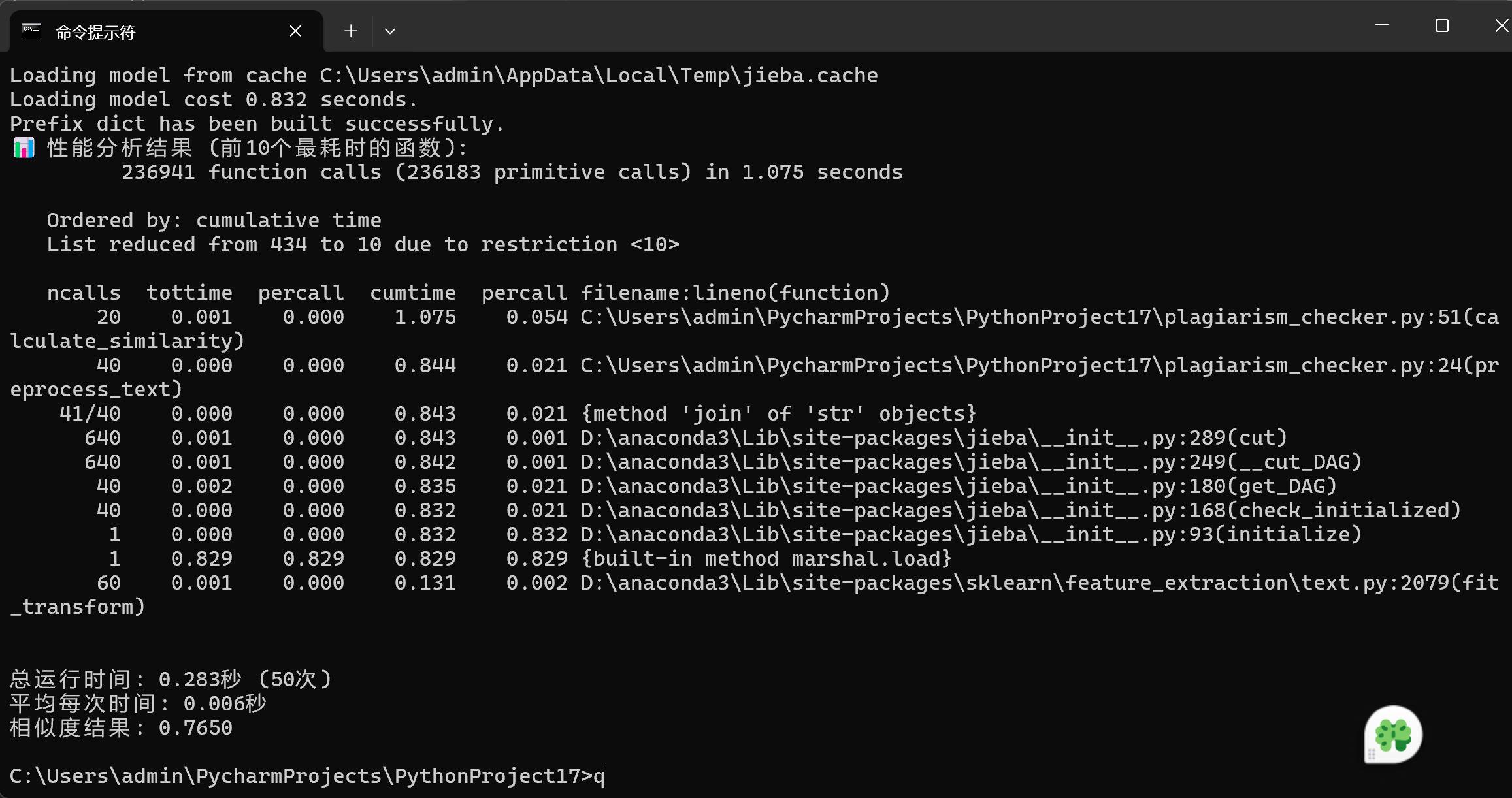
主要缺点在于其结构较为复杂且冗余,导致代码执行效率降低。额外的步骤和重复计算不仅使代码逻辑显得啰嗦冗长,还明显降低了程序的运行性能,增加了维护难度,对最终的查重结果没有实质性的提升,实用性较差。
不过好在重查率(如下图)是对的,只是代码过于繁琐。
于是我进行了对代码的改进,性能图和相似度如下
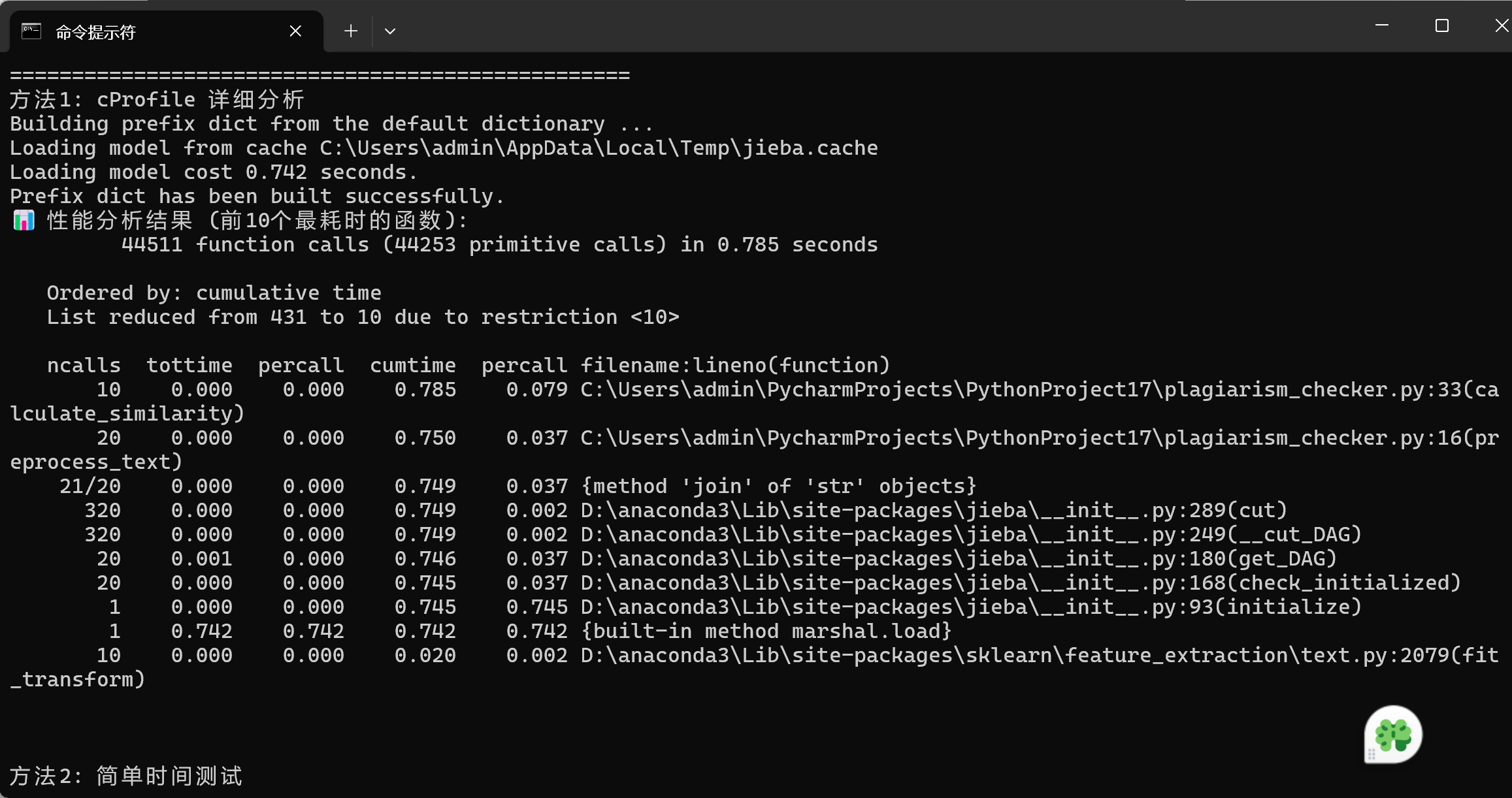

这个代码设计结构清晰,具有较高的实用性和可维护性。各个功能模块划分明确,从文件读取、文本预处理到相似度计算和结果输出,避免了不必要的重复操作和资源浪费。
五个样本的运行结果如下
五个样本测试无问题




测试代码部分展示
计算相似度:
def calculate_similarity(self, original_text, copied_text):
original_processed = self.preprocess_text(original_text)
copied_processed = self.preprocess_text(copied_text)
tfidf_matrix = self.vectorizer.fit_transform([original_processed, copied_processed])
similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
return similarity[0][0]
测试样例:
checker = PlagiarismChecker()
text1 = "机器学习是人工智能的重要分支,深度学习是机器学习的子领域。"
text2 = "人工智能包含机器学习,而深度学习又是机器学习的一个特定分支。"
print("🔍 开始性能分析...")
print("=" * 50)
# 方法1: cProfile 详细分析
print("方法1: cProfile 详细分析")
profiler = cProfile.Profile()
profiler.enable()
for _ in range(10): # 循环次数更少,更快
checker.calculate_similarity(text1, text2)
覆盖率如下
可能出现的异常处理说明
1,引用库说明
import sys
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import re
import datetime
import cProfile
import pstats
import time
要在pycharm要安装以上的库才可以运行
2,环境混淆
1,可能在多个 Python 环境(比如系统自带的 Python、Anaconda 环境)中工作,虽然你在其中一个环境安装了 jieba,但运行代码时使用的是另一个没有安装该库的环境。需要再在终端安装一下。
2,系统中可能存在多个版本的 NumPy,导致了冲突,需要打开命令提示,强制彻底卸载 NumPy,也卸载 scipy 和 scikit-learn,清除 pip 缓存,重新安装 NumPy:
模型的改进建议和使用说明
模型改进建议
- 分词精度提升
目前使用的是 jieba.cut() 的基础分词方法,在处理复杂文本或专业术语时可能无法准确切分。建议尝试引入更先进的中文分词工具,以提升分词的上下文理解能力。
- 相似度算法优化
当前系统使用的是 TF-IDF 与余弦相似度算法,适用于基础文本比对,但无法捕捉深层语义信息。可以考虑模型,通过向量语义表示实现更加精准的相似度计算.。
- 查重结果可视化
当前结果为纯文本输出,建议扩展功能,生成图形化查重报告。例如用 matplotlib 绘制相似度热力图,或使用 pyecharts 实现在线对比报告,有助于提升查重结果的可读性和表现力。
使用说明
- 程序输入
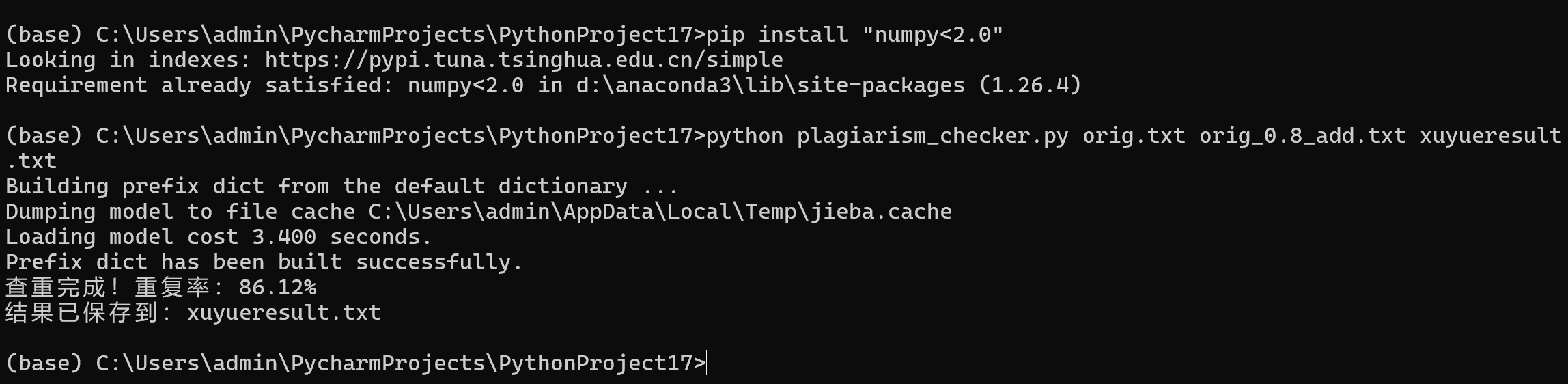
该程序为命令行工具,支持用户输入三个参数:原文路径、对比文路径、结果输出路径。例如:
python plagiarism_checker.py orig.txt copied.txt result.txt
系统会读取原文与对比文件内容,执行查重流程,并将查重结果以追加形式写入输出文件中。所以,我每次只需要修改copied.txt即可
txt如图
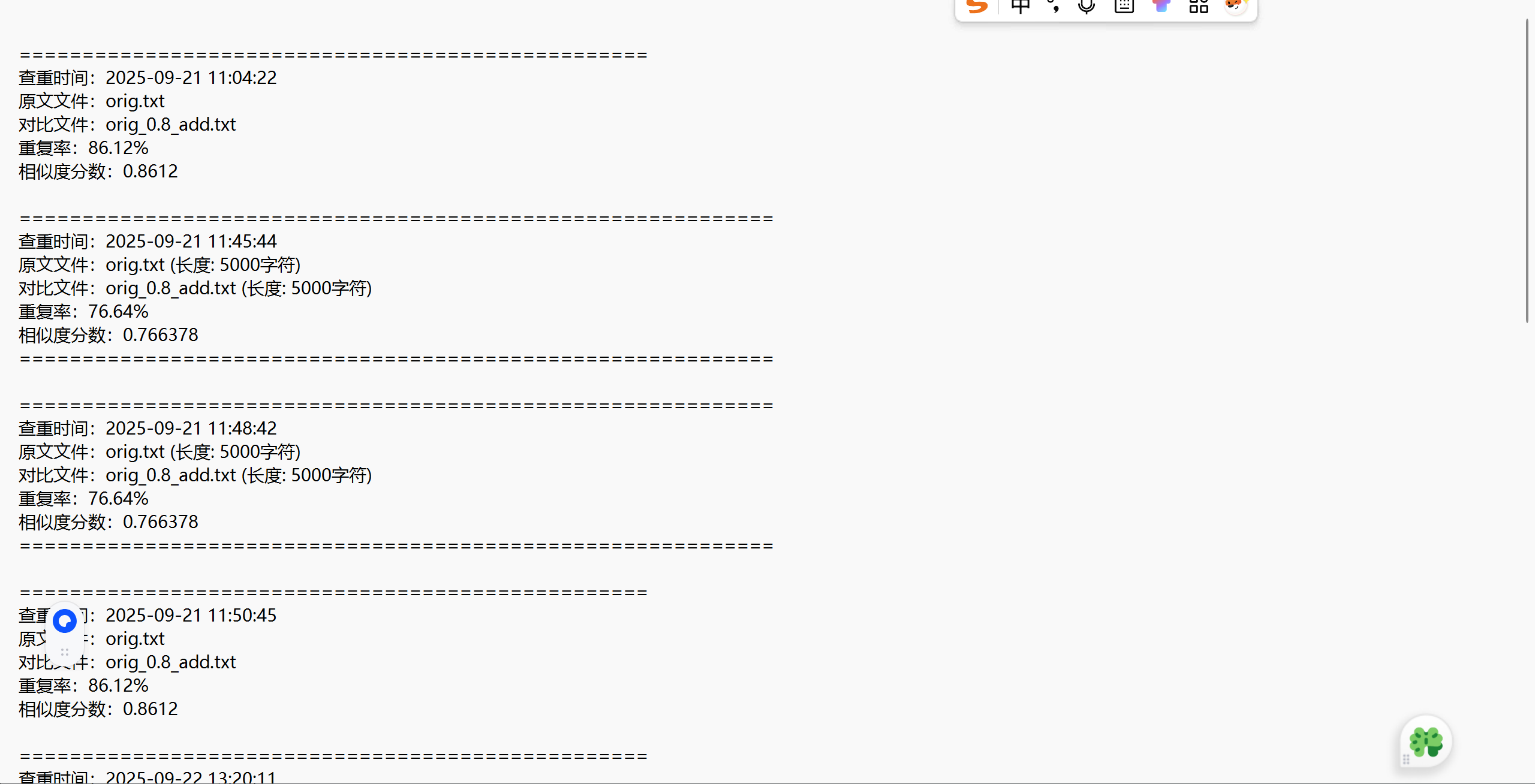
- 查重逻辑说明
程序会将两个文本文档进行预处理(去除标点 + 中文分词),使用 TF-IDF 建模词频,并利用余弦相似度计算两者的相似程度。查重完成后会输出重复率(百分比)及具体相似度分数(浮点值),并附上时间戳。
- 性能分析模式
程序支持性能分析模式,只需在命令行中使用 --profile 参数启动:
python plagiarism_checker.py --profile
该模式会运行预设的测试文本,输出包括:cProfile 分析的最耗时函数(前10名),计算总耗时与平均耗时,预处理与计算模块各自所占耗时比例,相似度结果值。
- 输出内容格式
查重完成后,程序会将结果以如下格式追加保存至输出文件:
==================================================
查重时间:2025-09-22 22:22:22
原文文件:orig.txt
对比文件:copied.txt
重复率:75.56%
相似度分数:0.7556

 浙公网安备 33010602011771号
浙公网安备 33010602011771号