


python-爬取糗事百科热图
此次运用requests和beautifulSoup爬取糗事百科热图,常用的网络库有:urllib,urllib3,requests,选取其中之一就行了;HTML/XML解析器有:lxml,BeautifulSoup,html5lib,selenium,re等。
如果经常爬虫,觉得可以固定选择一种网络库和页面解析器,否则太多了不容易记住,主要思路就是访问页面(网络库)--分析页面元素(可通过浏览区F12查看)--提取需要的数据(页面解析器)。
在爬取的过程中发现,最好headers信息填的全一些,否则会报404错。示例代码:
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup import requests import re import os def parseHtml(allPageUrls,headers): imgUrls = [] for i in allPageUrls: html = requests.get(i, headers=headers).text soup = BeautifulSoup(html, 'lxml').find_all('img', class_="illustration") for url in soup: #imgUrls.append('http:' + re.findall('src="(\S+)"', str(url))[0]) #也可用正则查找 imgUrls.append('http:' + url['src']) return imgUrls def downloadImages(urls,path): global count if not os.path.exists(path): print("Download path error!") pass else: path = path.rstrip('/') for i in urls: count += 1 img = requests.get(i).content with open(path + '//{0}.jpg'.format(count),'wb') as f: f.write(img) def getAllPageUrls(baseUrl,headers): allPageUrls = [] allPageUrls.append(baseUrl) html = requests.get(baseUrl, headers=headers).text pageNum = BeautifulSoup(html,'lxml').find_all('span',class_='page-numbers')[-1].text.strip() for num in range(int(pageNum)): if num >= 2: allPageUrls.append(baseUrl + 'page/{0}/'.format(num)) return allPageUrls def main(): baseUrl = "https://www.qiushibaike.com/imgrank/" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:67.0) Gecko/20100101 Firefox/67.0", # "Host":"static.qiushibaike.com", "Accept": "text/css,*/*;q=0.1", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Connection": "keep-alive", "Cookie": 'Hm_lvt_2670efbdd59c7e3ed3749b458cafaa37=1564111558; Hm_lpvt_2670efbdd59c7e3ed3749b458cafaa37=1564111562; BAIDU_SSP_lcr=https://www.baidu.com/link?url=jWhGNGV5ALzyB_BRJKkXdeb60lmYQ3_Lewk3NHsLe_C9fvNwKDdTPwZDtD2GrY15&wd=&eqid=b4f829d300000e94000000045d3a72c3; _qqq_uuid_="2|1:0|10:1564111558|10:_qqq_uuid_|56:OWQxZTVlNjY4MWY2MjVmOTdjODkwMDE3MTEwZTQ0ZTE2ZGU4NTA1NA==|971036a31548dd5a201f29c949b56990b4895dee0e489693b7b9631f363ca452"; _ga=GA1.2.126854589.1564111558; _gid=GA1.2.839365496.1564111558; _gat=1', "TE": "Trailers" } allPageUrls = getAllPageUrls(baseUrl, headers) #获取所有页面的访问地址 allImageUrls = parseHtml(allPageUrls, headers) #获取所有页面中图片地址 downloadImages(allImageUrls,'e://qiushibaike') #下载图片 if __name__ == '__main__': count = 0 main()
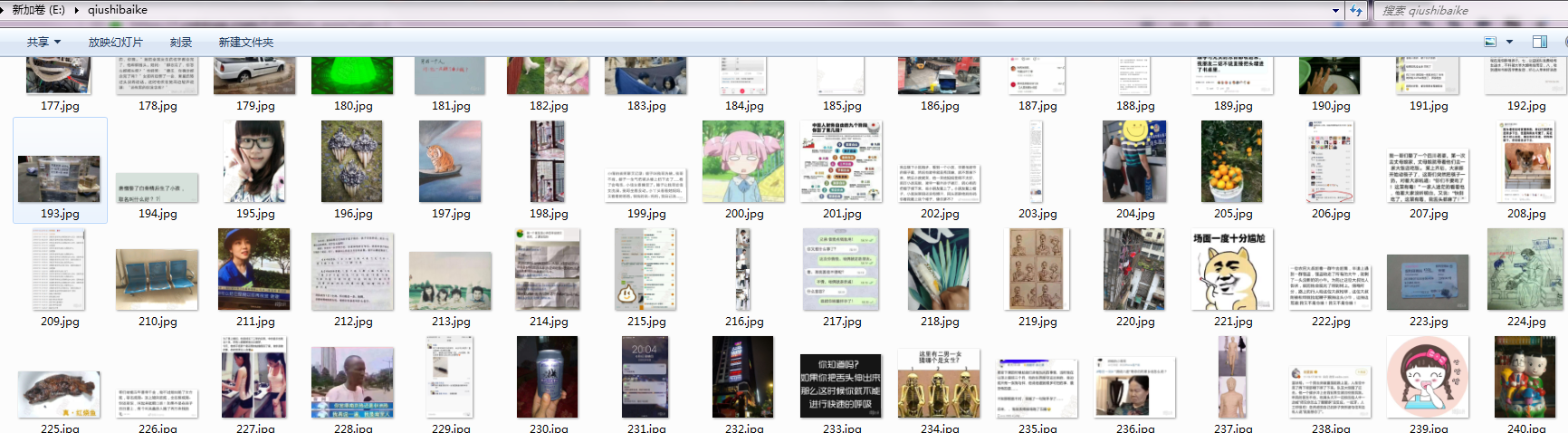
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号