常用文档格式转换是被我玩通了,不信你看看
代码:
#coding=utf-8 import os, sys, re, math import mammoth import inspect import pypandoc import fitz from win32com import client from pdf2docx import Converter from docx import Document from docx.shared import Inches, Cm from lxml import etree from pydocx import PyDocX from PIL import Image from win32 import win32api, win32gui, win32print from win32.lib import win32con from win32.win32api import GetSystemMetrics def doc2docx(doc_file, docx_file): if not os.path.exists(doc_file): print('file[%s] is not exists' % doc_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(doc_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(docx_file, 12) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def doc2pdf(doc_file, pdf_file): if not os.path.exists(doc_file): print('file[%s] is not exists' % doc_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(doc_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(pdf_file, 17) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def doc2html(doc_file, html_file, encoding='utf-8'): if not os.path.exists(doc_file): print('file[%s] is not exists' % doc_file) return False style_map = """ p[style-name='Section Title'] => h1:fresh p[style-name='Subsection Title'] => h2:fresh """ htmltmp = "" try: with open(doc_file, "rb") as f: res = mammoth.convert_to_html(f, style_map=style_map) htmltmp = res.value except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False try: htmltmp = htmltmp.decode(encoding='utf-8' ,errors ='ignore') except Exception as e: pass try: htmltmp = htmltmp.encode(encoding=encoding ,errors ='ignore') except Exception as e: pass try: h = open(html_file, "wb") h.write(htmltmp) h.close() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def doc2jpg(doc_file, jpg_file): pdf_file = doc_file.replace('.doc', '-tmp.pdf') if doc2pdf(doc_file, pdf_file): if pdf2jpg(pdf_file, jpg_file): os.unlink(pdf_file) return True return False def doc2txt(doc_file, txt_file): if not os.path.exists(doc_file): print('file[%s] is not exists' % doc_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(doc_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(txt_file, 4) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def docx2doc(docx_file, doc_file): if not os.path.exists(docx_file): print('file[%s] is not exists' % docx_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(docx_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(doc_file, 0) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def docx2pdf(docx_file, pdf_file): if not os.path.exists(docx_file): print('file[%s] is not exists' % docx_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(docx_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(pdf_file, 17) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def docx2html(docx_file, html_file, encoding='utf-8'): if not os.path.exists(docx_file): print('file[%s] is not exists' % docx_file) return False style_map = """ p[style-name='Section Title'] => h1:fresh p[style-name='Subsection Title'] => h2:fresh """ htmltmp = "" try: with open(docx_file, "rb") as f: res = mammoth.convert_to_html(f, style_map=style_map) htmltmp = res.value except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False try: htmltmp = htmltmp.decode(encoding='utf-8' ,errors ='ignore') except Exception as e: pass try: htmltmp = htmltmp.encode(encoding=encoding ,errors ='ignore') except Exception as e: pass try: h = open(html_file, "wb") h.write(htmltmp) h.close() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def docx2jpg(docx_file, jpg_file): pdf_file = docx_file.replace('.docx', '-tmp.pdf') if docx2pdf(docx_file, pdf_file): if pdf2jpg(pdf_file, jpg_file): os.unlink(pdf_file) return True return False def docx2txt(docx_file, txt_file): if not os.path.exists(docx_file): print('file[%s] is not exists' % docx_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(docx_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(txt_file, 4) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def pdf2doc(pdf_file, doc_file): if not os.path.exists(pdf_file): print('file[%s] is not exists' % pdf_file) return False try: cv = Converter(pdf_file) cv.convert(doc_file) cv.close() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def pdf2docx(pdf_file, docx_file): if not os.path.exists(pdf_file): print('file[%s] is not exists' % pdf_file) return False try: cv = Converter(pdf_file) cv.convert(docx_file) cv.close() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def pdf2html(pdf_file, html_file): doc_file = pdf_file.replace('.pdf', '-tmp.doc') if pdf2doc(pdf_file, doc_file): if doc2html(doc_file, html_file): os.unlink(doc_file) return True return False def pdf2jpg(pdf_file, jpg_file): if not os.path.exists(pdf_file): print('file[%s] is not exists' % pdf_file) return False dirname = os.path.dirname(jpg_file) basename = os.path.basename(jpg_file) names = basename.split('.') basename = '.'.join(names[0:len(names)-1]) try: doc = fitz.open(pdf_file) i=0 tar_h = 0 for page in doc: page = doc.load_page(i) pix = page.get_pixmap() tar_h += pix.height #jpg_file = dirname+'\\'+basename+'_'+str(i)+'.jpg' #pix.save(jpg_file) i += 1 src = doc[0].get_pixmap() tar_pix = fitz.Pixmap(src.colorspace, (0, 0, src.width, tar_h), src.alpha) i = 0 for page in doc: page = doc.load_page(i) pix = page.get_pixmap() pix.set_origin(0, pix.height * i) tar_pix.copy(pix, pix.irect) i += 1 tar_pix.save(jpg_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def pdf2txt(pdf_file, txt_file): if not os.path.exists(pdf_file): print('file[%s] is not exists' % pdf_file) return False all_text = '' try: doc = fitz.open(pdf_file) i=0 for page in doc: page = doc.load_page(i) text = page.get_text() all_text += "\n\n"+text.strip() i += 1 while "\n " in all_text: all_text = all_text.replace("\n ", "\n") while "\n\n\n" in all_text: all_text = all_text.replace("\n\n\n", "\n\n") while all_text.startswith("\n"): all_text = all_text[1:len(all_text)] except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False try: h = open(txt_file, "w") h.write(all_text) h.close() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def html2doc(html_file, doc_file): if not os.path.exists(html_file): print('file[%s] is not exists' % html_file) return False try: pypandoc.convert_file(html_file, 'docx', outputfile=doc_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def html2docx(html_file, docx_file): if not os.path.exists(html_file): print('file[%s] is not exists' % html_file) return False try: pypandoc.convert_file(html_file, 'docx', outputfile=docx_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def html2pdf(html_file, pdf_file): doc_file = html_file.replace('.html', '-tmp.doc') if html2doc(html_file, doc_file): if doc2pdf(doc_file, pdf_file): os.unlink(doc_file) return True return False def html2jpg(html_file, jpg_file): doc_file = html_file.replace('.html', '-tmp.doc') if html2doc(html_file, doc_file): if doc2jpg(doc_file, jpg_file): os.unlink(doc_file) return True return False def html2txt(html_file, txt_file): doc_file = html_file.replace('.html', '-tmp.doc') if html2doc(html_file, doc_file): if doc2txt(doc_file, txt_file): os.unlink(doc_file) return True return False def jpg2doc(jpg_file, doc_file): docx_file = jpg_file.replace('.jpg', '-tmp.docx') if jpg2docx(jpg_file, docx_file): if docx2doc(docx_file, doc_file): os.unlink(docx_file) return True return False def jpg2docx(jpg_file, docx_file): if not os.path.exists(jpg_file): print('file[%s] is not exists' % jpg_file) return False img = Image.open(jpg_file) width = img.width height = img.height perheight = 800.00 pagenum = math.ceil(height / perheight) i = 0 try: document = Document() while i < pagenum: upper = int(i*perheight) if (i+1)*perheight > height: lower = int(upper + height - i*perheight) else: lower = int(upper + perheight) # 从左上角开始 剪切 200*200的图片 #(左、上、右、下坐标) #(left, upper, right, lower) # img2 = img.crop((0, 0, 200, 200)) jpg_file_tmps = [] shape = (0, upper, width, lower) try: jpg_file_tmp = jpg_file.replace('.jpg', '-tmp-%s.jpg' % str(i)) region = img.crop(shape) region.save(jpg_file_tmp) jpg_file_tmps.append(jpg_file_tmp) img_tmp = region width_tmp = img_tmp.width / getdpi() * 2.54 height_tmp = img_tmp.height / getdpi() * 2.54 document.add_picture(jpg_file_tmp, width=Cm(width_tmp), height=Cm(height_tmp)) os.unlink(jpg_file_tmp) i += 1 except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() i += 1 return False document.save(docx_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() i += 1 return False return True def jpg2pdf(jpg_file, pdf_file): patten = re.compile("[\.|_\d]") patten2 = re.compile("[\.|_]") dirname = os.path.dirname(jpg_file) basename = os.path.basename(jpg_file) names = patten.split(basename) filename = '.'.join(names[0:len(names)-1]) ext = names[-1] nums = [] for i in os.listdir(dirname): tmp_names = patten.split(i) tmp_names2 = patten2.split(i) tmp_names = [j for j in tmp_names if j != ''] tmp_filename = '.'.join(tmp_names[0:len(tmp_names)-1]) tmp_ext = tmp_names[-1] if tmp_ext == ext and tmp_filename == filename and len(tmp_names2) >= 3: nums.append(int(tmp_names2[-2])) if len(nums) > 0: minnum = min(nums) maxnum = max(nums) else: minnum = 0 maxnum = 0 filepaths = [] if os.path.exists(jpg_file): filepaths.append(jpg_file) for i in range(minnum, maxnum+1): filepath = os.path.join(dirname, filename+'_'+str(i)+'.'+ext) if os.path.exists(filepath): filepaths.append(filepath) try: doc = fitz.open() for filepath in filepaths: img = fitz.open(filepath) pdfbytes = img.convert_to_pdf() imgpdf = fitz.open("pdf", pdfbytes) doc.insert_pdf(imgpdf) doc.save(pdf_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def jpg2html(jpg_file, html_file): docx_file = jpg_file.replace('.jpg', '-tmp.docx') if jpg2docx(jpg_file, docx_file): if docx2html(docx_file, html_file): os.unlink(docx_file) return True return False def jpg2txt(jpg_file, txt_file): print('Not Supported func jpg2txt') return False def txt2doc(txt_file, doc_file): docx_file = jpg_file.replace('.txt', '-tmp.docx') if txt2docx(txt_file, docx_file): if docx2doc(docx_file, doc_file): os.unlink(docx_file) return True return False def txt2docx(txt_file, docx_file): if not os.path.exists(txt_file): print('file[%s] is not exists' % txt_file) return False try: text = '' with open(txt_file, 'r') as f: text = f.read() document = Document() document.add_paragraph(text) document.save(docx_file) except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def txt2pdf(txt_file, pdf_file): if not os.path.exists(txt_file): print('file[%s] is not exists' % txt_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(txt_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(pdf_file, 17) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def txt2html(txt_file, html_file): if not os.path.exists(txt_file): print('file[%s] is not exists' % txt_file) return False try: word = client.Dispatch("Word.Application") doc = word.Documents.Open(txt_file) #doc=0, txt=2,3,4,5,7, html=8,10, docx=12,16, pdf=17, 11=xml doc.SaveAs(html_file, 8) doc.Close() word.Quit() except Exception as e: print('文件:%s' % __file__) print('行:%s' % str(inspect.currentframe().f_lineno)) print('错误:%s' % e) print() return False return True def txt2jpg(txt_file, jpg_file): pdf_file = txt_file.replace('.txt', '-tmp.pdf') if txt2pdf(txt_file, pdf_file): if pdf2jpg(pdf_file, jpg_file): os.unlink(pdf_file) return True return False def ext2ext(src_file, desc_file): patten = re.compile("[\.|_\d]") dirname = os.path.dirname(src_file) basename = os.path.basename(src_file) names = patten.split(basename) filename = '.'.join(names[0:len(names)-1]) ext = names[-1] existsflag = False if os.path.exists(src_file): existsflag = True else: for i in os.listdir(dirname): tmp_names = patten.split(i) tmp_names = [j for j in tmp_names if j != ''] tmp_filename = '.'.join(tmp_names[0:len(tmp_names)-1]) tmp_ext = tmp_names[-1] if tmp_filename == filename and tmp_ext == ext: existsflag = True if existsflag == False: print('file[%s] is not exists' % src_file) return False src_ext = src_file.split('.')[-1] desc_ext = desc_file.split('.')[-1] func = '%s2%s' % (src_ext, desc_ext) if not func in globals().keys(): print('func[%s] is not defined' % func) return False res = eval(func+"(r'"+src_file+"', r'"+desc_file+"')") return res def get_real_resolution(): """获取真实的分辨率""" hDC = win32gui.GetDC(0) # 横向分辨率 w = win32print.GetDeviceCaps(hDC, win32con.DESKTOPHORZRES) # 纵向分辨率 h = win32print.GetDeviceCaps(hDC, win32con.DESKTOPVERTRES) return w, h def get_screen_size(): """获取缩放后的分辨率""" w = GetSystemMetrics (0) h = GetSystemMetrics (1) return w, h def getdpi(): real_resolution = get_real_resolution() screen_size = get_screen_size() screen_scale_rate = round(real_resolution[0] / screen_size[0], 2) screen_scale_rate = screen_scale_rate * 100 return screen_scale_rate if __name__ == '__main__': doc_file = os.getcwd()+'\\'+'test.doc' docx_file = os.getcwd()+'\\'+'test.docx' html_file = os.getcwd()+'\\'+'test.html' pdf_file = os.getcwd()+'\\'+'test.pdf' jpg_file = os.getcwd()+'\\'+'test.jpg' txt_file = os.getcwd()+'\\'+'test.txt' ext2ext(jpg_file, txt_file)
执行结果:
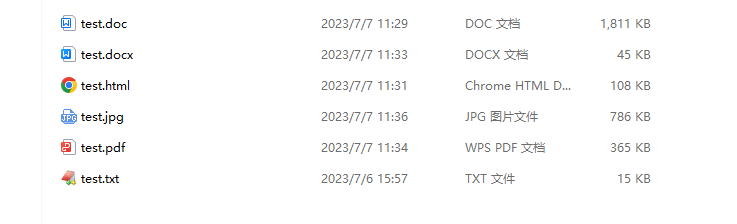

本文来自博客园,作者:河北大学-徐小波,转载请注明原文链接:https://www.cnblogs.com/xuxiaobo/p/17534564.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号