Transformer网络
Transformer网络
-
传统的序列模型(如RNN、GRU和LSTM)在处理长序列时存在渐变消失问题,导致难以捕捉长距离依赖。这些模型采用逐步处理方式,每次只能处理一个单词或记号,因此存在信息流瓶颈。随着模型复杂性的增加(例如,从RNN到GRU,再到LSTM),处理复杂性也显著增加。
Transformer网络的核心创新是基于注意力机制的表示和CNN风格的并行处理相结合。不同于RNN、GRU和LSTM的顺序计算,Transformer架构允许并行处理整个序列,通过自注意力机制捕捉序列中的远距离依赖关系。Transformer能够同时处理句子中的所有单词,而不是逐个顺序处理,从而提高了计算效率和模型的表现力,不再受到单词顺序的限制,可以通过并行计算大大加速处理过程。
Transformer架构的关键在于自注意力(Self-Attention)机制和多头注意力(Multi-Head Attention)机制。
-
自注意力机制可以让序列中的每个单词“看到”整个句子,并以不同的权重关注其他单词,从而更好地理解上下文信息。不同于 RNN 依赖序列计算,Transformer 可以同时计算所有单词的注意力,加速训练。自注意力使单词的表示不再固定,而是根据上下文变化,使模型更具表达能力。
以
Jane visite l'Afrique en septembre.为例,想要计算每个单词的注意力表示,例如单词l'Afrique应根据其在句子中的不同上下文,形成适应性表示。例如,l'Afrique在Jane visite l'Afrique en septembre.中的语义可能与句子L'Afrique est un continent.中的语义不同,因为它可能表示目的地、历史遗迹或地理位置。Transformer处理的输入是词嵌入,输入序列的每个单词对应一个 \(d\) 维度的嵌入向量。对于每个输入单词 \(X_i\) ,通过三组不同的可训练权重矩阵(\(W_Q, W_K, W_V\))计算其 Query(查询)、Key(键)和 Value(值)向量:
\[Qᵢ = W_Q Xᵢ, \quad Kᵢ = W_K Xᵢ, \quad Vᵢ = W_V Xᵢ \]其中,\(Q\) (Query, 查询向量)表示当前单词想要关注的信息。\(K\) (Key, 键向量)表示该单词所提供的信息。\(V\) (Value, 值向量)表示该单词的内容,用于加权后生成新的表示。
在示例句中, \(Q_3\)(查询)表示
l'Afrique希望找到它的上下文信息,比如“Jane 访问了它”。\(K_2\)(键)表示单词visite(访问),它提供了一种可能的关系。\(V_2\)(值)是visite的信息,它可能用于增强l'Afrique的表示。随后,通过查询Q与键K的点积计算相似度,并通过Softmax归一化生成注意力权重:
\[\text{Attention}(Q, K, V) = \text{Softmax} \left(\frac{Q K^T}{\sqrt{d_k}}\right) V \]其中, \(QK^T\) 表示 Query 和 Key 之间的点积相似性,衡量 Query 需要关注 Key 的程度。 \(\sqrt{d_k}\) 表示缩放因子,避免点积值过大影响梯度。
例如,在示例句中,计算
l'Afrique的注意力:\[\alpha_3 = \text{Softmax} \left( \frac{Q₃ \cdot [K₁, K₂, K₃, K₄, K₅]}{\sqrt{d_k}} \right) \]得到的 \(\alpha_3=[\alpha_{31},\alpha_{32},\alpha_{33},\alpha_{34},\alpha_{35}]\) 表示
l'Afrique关注每个单词的程度,如果 \(\alpha_{32}\) 较高,表示l'Afrique关注visite。如果 \(\alpha_{31}\) 较低,表示l'Afrique不太关注Jane。最终,新的 \(A_3\) (即
l'Afrique的新表示)是 V 向量的加权和:\[A_3 = \sum_{i=1}^{5} \alpha_{3i} V_i \]这也意味着
l'Afrique通过注意力权重从visite处获取最多信息,因为visite是最相关的单词。这样得到的 \(A_3\) 不再是一个固定的词嵌入,而是结合了整个句子信息的动态表示。 -
在自注意力机制计算每个单词的表示时,都会考虑整个序列中的其他单词,并通过查询、键和值的运算得到加权求和的结果。然而,这种方式仅使用单一视角来关注信息,在同一时间只能关注一种类型的关系。
多头注意力机制不是只进行一次自注意力计算,而是同时进行多次计算,每次计算使用不同的学习参数,让模型关注不同的上下文信息。
在示例句中,单头注意力可能只关注单一信息,如
l'Afrique关注visite表示访问关系。而多头注意力可以同时关注不同的语义关系,如l'Afrique是否是访问的目的地?l'Afrique发生的时间?l'Afrique和主语Jane的关系?在多头注意力中,我们不只计算一次自注意力,而是使用多个不同的参数集(\(W_Q, W_K, W_V\))计算多个不同的自注意力头。
对于输入序列 \(X = [X_1, X_2, X_3, ..., X_n]\) ,每个单词 \(X_i\) 都有对应的 \(d\) 维词嵌入,我们使用 \(H\) 组不同的权重矩阵来计算 \(H\) 组 \(Q, K, V\):
\[Q_h = X W_Q^h, \quad K_h = X W_K^h, \quad V_h = X W_V^h \]其中,\(W_Q^h, W_K^h, W_V^h\) 是第 \(h\) 个不同的参数矩阵,每个头都有独立的参数。
然后对每个注意力头独立计算自注意力,每个头得到一组不同的注意力分数,关注不同的句子特征。
\[\text{Attention}_h(Q_h, K_h, V_h) = \text{Softmax} \left( \frac{Q_h K_h^T}{\sqrt{d_k}} \right) V_h \]所有注意力头计算完成后,将它们的输出拼接在一起:
\[\text{MultiHead}(Q, K, V) = \text{Concat} (\text{head}_1, \text{head}_2, ..., \text{head}_H) W_O \]其中,\(W_O\) 是一个线性变换矩阵,用于将拼接后的向量转换回 Transformer 需要的维度。
矩阵表示:
\[\text{MultiHead}(Q, K, V) = \text{Concat} (A_1, A_2, ..., A_H) W_O \]其中 \(A_h\) 是第 \(h\) 个头的注意力输出。
-
Transformer整体是由编码器和解码器组成,两者均由多个 Transformer Block 堆叠而成。
Transformer整体结构包括以下几个关键部分:
-
输入嵌入(Input Embedding)
输入句子首先被转换为词嵌入,即 \(X=[X_1,X_2, ..., X_n]\) ,每个单词 \(X_i\) 都转换为一个固定维度的词向量。这些词嵌入随后被送入 Transformer 网络。
-
位置编码(Positional Encoding)
由于自注意力机制不考虑序列顺序,需要添加位置编码,让模型感知词语的顺序。
位置编码使用正弦和余弦函数:
\[PE(pos, 2i) = \sin(pos / 10000^{2i/d}) \\ PE(pos, 2i+1) = \cos(pos / 10000^{2i/d}) \]这样,每个单词的位置编码是一个与词向量相同维度的向量。这种方式保证不同位置的编码不同,并且随着位置增加,相对位置仍然能被模型识别。位置编码最终被加到输入词向量中,让 Transformer 知道单词的顺序。
-
编码器(Encoder)
编码器由 \(N\) 个相同的 Transformer Block 组成,通常 N=6。每个编码器块包含:
-
多头自注意力(Multi-Head Self-Attention)
首先计算查询、键、值:
\[Q = X W_Q, \quad K = X W_K, \quad V = X W_V \]然后计算注意力权重:
\[\text{Attention}(Q, K, V) = \text{Softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V \]并行计算多个注意力头,学习不同特征:
\[\text{MultiHead}(Q, K, V) = \text{Concat} (\text{head}_1, ..., \text{head}_H) W_O \] -
前馈神经网络(Feed Forward Network, FFN)
通过两个全连接层进行非线性变换,并采用 ReLU 作为激活函数,提升模型表达能力。
\[\text{FFN}(x) = \max(0, xW_1 + b_1) W_2 + b_2 \] -
残差连接(Residual Connection)+ 层归一化(LayerNorm)
Transformer 使用残差连接,保持信息流畅,并加入归一化(LayerNorm)稳定训练。
\[\text{Output} = \text{LayerNorm}(x + \text{Sublayer}(x)) \]
-
-
解码器(Decoder)
解码器用用类似编码器的结构,但是加入了掩码多头自注意力(Masked Multi-Head Attention)避免模型在预测时看到未来的信息,以及编码器-解码器注意力(Encoder-Decoder Attention)让解码器关注编码器的输出。
在解码过程中,第一步输入
SOS(句子起始符),第二步计算 Masked Multi-Head Attention 避免未来信息泄露,第三步使用 Encoder-Decoder Attention 关注编码器输出的上下文信息,第四步送入前馈神经网络,最后送入输出层,通过线性层和Softmax预测下一个单词。整个解码器采用自回归方式,第一步输入
SOS生成Jane,第二步输入SOS + Jane生成visite,第三步输入SOS + Jane + visite生成L'Afrique。 -
输出层(Linear + Softmax)
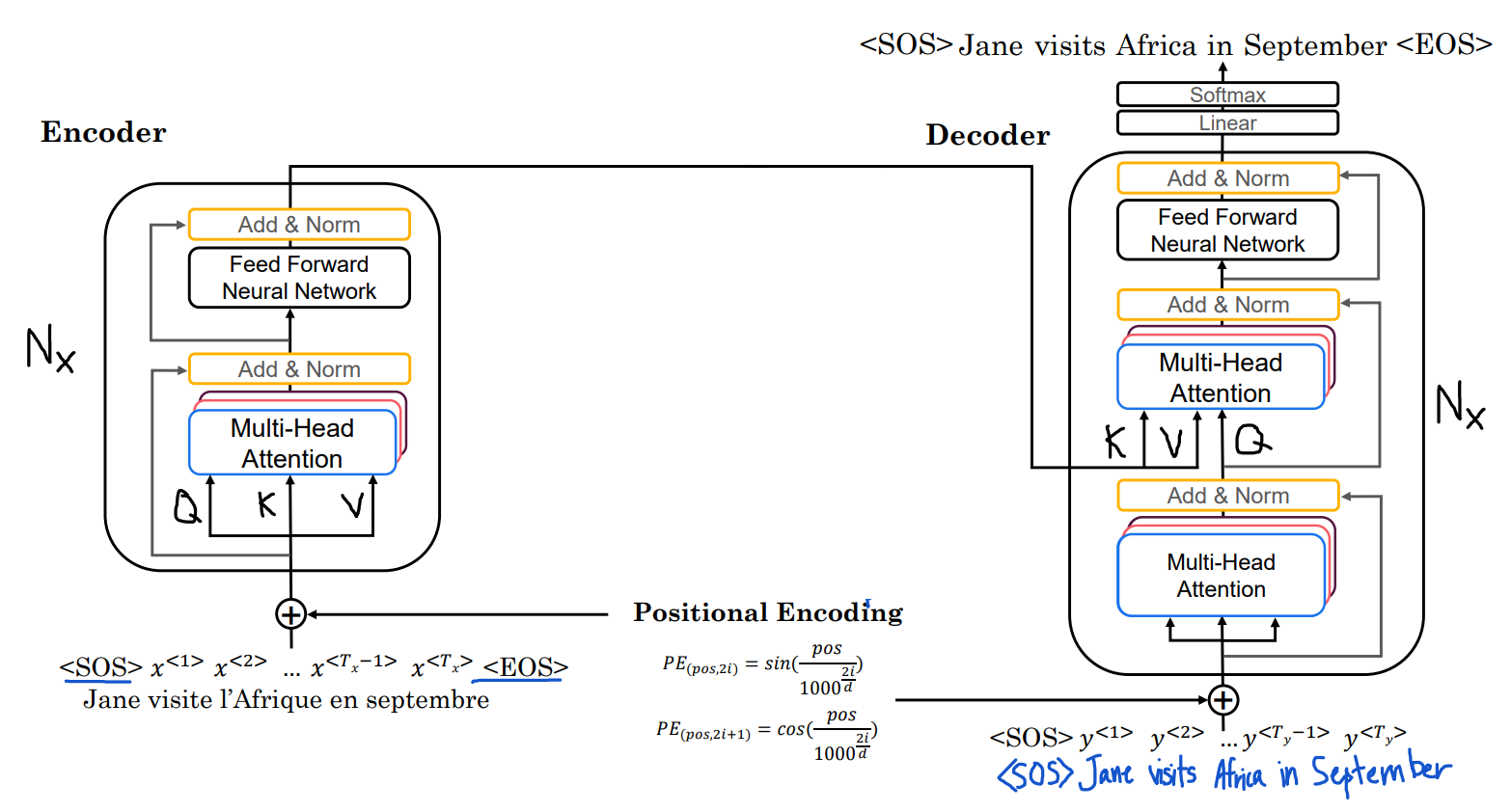
整体来说,Transformer可以实现并行计算,由于不依赖时间步,可以一次性计算所有单词的注意力,显著加快训练速度。可以实现长距离依赖,通过自注意力直接捕捉远距离的单词关系,而 RNN 需要逐步传播信息。可以实现灵活上下文,词的表示不再固定,而是随着上下文动态变化,适用于翻译、文本生成、摘要等任务。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号