telegraf适合做什么,不适合做什么
前面写过一篇业务中使用 telegraf 的文章。 https://www.cnblogs.com/xushengbin/p/17974981#_label3
当时的业务场景是:把kafka中存储的json数据,写入到influxdb中。
最近又对telegraf的能力做了什么了解。
增加了两个业务使用场景:
场景一:把kafka中存储的 json 数据,根据数据的特点,转发到不同的topic
kafka中数据格式如下:
{
"customerId": 1652,
"deviceId": "13011304383",
"timestamp": 1705637828000,
"parameters": {
"acc": 0,
"locationStatus": 1,
"altitude": 38.0,
"loc": {
"lng": 117.306441,
"lat": 31.93148
},
"latitude": 31.93148,
"brushState": 0,
"speed": 0.0,
"direction": 136.0,
"height": 38.0,
"longitude": 117.306441,
"mileage": 267119.0
},
"componentId": 7,
"entityId": 81495
}
需求一: 把customerId = 1 的数据,转发给客户的 kafka 集群。
需求二: 指标weight > 0 的数据,转发到同一个集群的另外一个 topic。
这俩需求放在一个配置文件,配置如下:
# Configuration for telegraf agent
[agent]
debug = true
interval = "20s"
round_interval = true
metric_batch_size = 10000
metric_buffer_limit = 1000000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "5s"
statefile = "/mnt/data/influxdb/telegraf/statefile"
precision = ""
hostname = ""
## If set to true, do no set the "host" tag in the telegraf agent.
omit_hostname = true
[[processors.starlark]]
order = 1
## The Starlark source can be set as a string in this configuration file, or
## by referencing a file containing the script. Only one source or script
## should be set at once.
## Source of the Starlark script.
source = '''
def apply(metric):
new_metric = deepcopy(metric)
# Add the 'is_weight' tag based on the 'weight' field
if 'originalWeight' in new_metric.fields and new_metric.fields['originalWeight'] > 0:
new_metric.tags['is_weight'] = '1'
new_metric.tags['type'] = '1' # 0:整车称重 1:单桶称重
new_metric.tags['source'] = '1' # 0:第三方对接 1:报文上传
else:
new_metric.tags['is_weight'] = '0'
if 'customerId' in new_metric.tags and new_metric.tags['customerId'] == '2119':
new_metric.tags['is_jinghuan'] = '1'
# Return the modified metric (new object)
return new_metric
'''
#[[processors.printer]]
# order = 10
[[outputs.kafka]]
brokers = ["xxx"]
topic = "weight-handle"
##fieldinclude = ["weight", "originalWeight"]
version = '2.0.0'
data_format = "json"
json_timestamp_units = "1s"
json_transformation = '''
$merge([{"timestamp" : timestamp}, tags, {"parameters" : $merge([fields, {"loc": {"lat": fields.loc_lat, "lng": fields.loc_lng }}])} ])
'''
[outputs.kafka.tagpass]
is_weight = ["1"]
[[outputs.kafka]]
brokers = ["xxx"]
topic = "iot-device-data"
##fieldinclude = ["weight", "originalWeight"]
version = '2.0.0'
data_format = "json"
json_timestamp_units = "1s"
json_transformation = '''
$merge([{"timestamp" : timestamp}, tags, {"parameters" : $merge([fields, {"loc": {"lat": fields.loc_lat, "lng": fields.loc_lng }}])} ])
'''
[outputs.kafka.tagpass]
is_jinghuan = ["1"]
[[outputs.influxdb_v2]]
urls = ["http://xxx"]
token = "$INFLUX_TOKEN"
organization = "tide"
bucket = "iot"
timeout = "15s"
name_override = "weight_metric"
[outputs.influxdb_v2.tagpass]
is_weight = ["1"]
[[inputs.kafka_consumer]]
## Kafka brokers.
brokers = ["xxx"]
## Topics to consume.
topics = ["iot-device-data"]
consumer_group = "influxdb_dispatcher"
offset = "newest"
max_message_len = 1000000
max_undelivered_messages = 100000
## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
data_format = "json_v2"
[[inputs.kafka_consumer.json_v2]]
timestamp_path = 'timestamp'
timestamp_format = 'unix'
timestamp_timezone = 'Asia/Shanghai'
[[inputs.kafka_consumer.json_v2.object]]
# excluded_keys = ["loc"]
path = "parameters"
optional = false
# [[inputs.kafka_consumer.json_v2.field]]
# path = "parameters.loc|@tostr"
# type = "string"
# rename = "loc"
# optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "customerId"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "deviceId"
type = "string"
optional = false
[[inputs.kafka_consumer.json_v2.tag]]
path = "entityId"
type = "string"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "componentId"
type = "string"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "protocolName"
type = "string"
optional = true
要理解这个配置,首先要理解telegraf的数据处理机制。
https://docs.influxdata.com/telegraf/v1/configure_plugins/aggregator_processor/
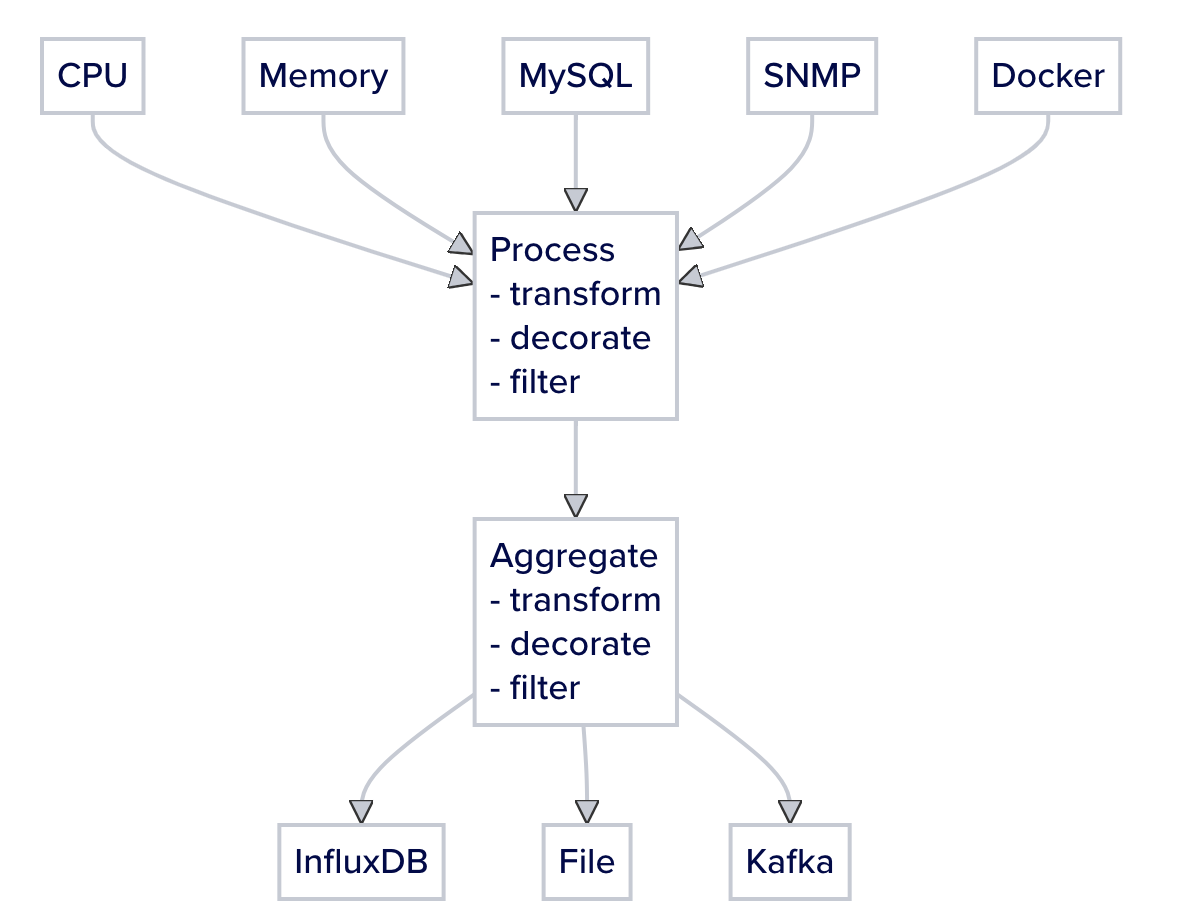
数据经过input、processor、aggregate处理后,得到的数据格式一定是指标格式。
https://docs.influxdata.com/telegraf/v1/metrics/
我们的需求,需要把 json 经过过滤,再写回 kafka,因此需要保证数据格式不要变。
这就是代码中的
$merge([{"timestamp" : timestamp}, tags, {"parameters" : $merge([fields, {"loc": {"lat": fields.loc_lat, "lng": fields.loc_lng }}])} ])
发挥作用的地方:把metric转换成 json。
它是https://docs.jsonata.org/object-functions 这个库提供的能力:
JSONata is a lightweight query and transformation language for JSON data.
而https://github.com/json-path/JsonPath 只提供了json query能力。
用好这些关于 json 处理的库,工作会幸福很多。很多场景通过配置就可以完成,不用天天在那写业务代码解析、转换、构造json
教训:
把metric 转换成 json, 如果原始的 json 中嵌套太多的话,这里会非常费劲。 因此,尽量让原始 json 不要有太多嵌套(如key 的 value 是一个object,先转换成string,再存储)。
telegraf不适合的场景一: 如果原始数据是 json 并且嵌套很多,想经过telegraf处理后再原格式输出,难度会很大。 因为需要处理metric格式转回 json 格式的难题。
场景二:原始的指标数据,数据量太大(5s 一次),并且有很多重复数据(如车辆原地不动也在一直上报位置、电量数据),希望对重复数据做去重后再存储。
案例参考https://github.com/influxdata/telegraf/blob/master/plugins/processors/dedup/README.md
我的配置:
# Configuration for telegraf agent
[agent]
debug = true
interval = "20s"
round_interval = true
metric_batch_size = 10000
metric_buffer_limit = 1000000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "5s"
statefile = "/mnt/data/influxdb/telegraf/statefile"
precision = ""
hostname = ""
## If set to true, do no set the "host" tag in the telegraf agent.
omit_hostname = true
[[processors.dedup]]
## Maximum time to suppress output
dedup_interval = "600s"
[[outputs.influxdb_v2]]
fieldpass = ["chargingStatus", "BMSStateOfCharge"]
urls = ["http://xxx"]
token = "$INFLUX_TOKEN"
organization = "tide"
bucket = "iot"
timeout = "15s"
name_override = "charging_record"
[[inputs.kafka_consumer]]
## Kafka brokers.
brokers = ["xxx"]
## Topics to consume.
topics = ["iot-device-data"]
consumer_group = "influxdb_charging_record"
offset = "newest"
max_message_len = 1000000
max_undelivered_messages = 100000
## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
data_format = "json_v2"
[[inputs.kafka_consumer.json_v2]]
measurement_name = "device_metric"
timestamp_path = 'timestamp'
timestamp_format = 'unix'
timestamp_timezone = 'Asia/Shanghai'
[[inputs.kafka_consumer.json_v2.object]]
included_keys = ["chargingStatus", "BMSStateOfCharge"]
path = "parameters"
optional = false
[[inputs.kafka_consumer.json_v2.tag]]
path = "customerId"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "deviceId"
type = "string"
optional = false
[[inputs.kafka_consumer.json_v2.tag]]
path = "entityId"
type = "string"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "componentId"
type = "string"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "protocolName"
type = "string"
optional = true
我的去重策略是:如果 10 分钟内指标值不变,只记录最后一个指标。如果发生变化,立即记录一次。
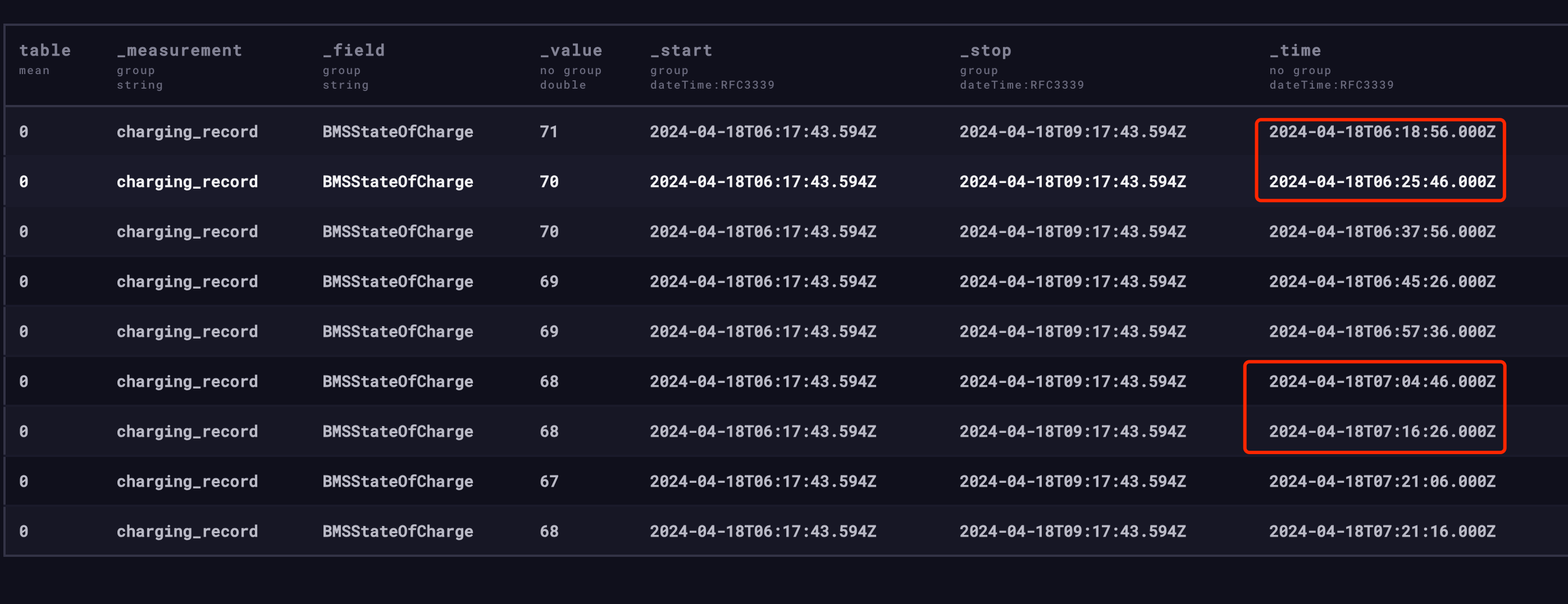
截图是一辆车的剩余电量,正常 10 分钟记录一次(telegraf不保证一定是 10 分钟,可能大于 10 分钟),当电量发生变化了,立即记录一次。
总结
- telegraf适合的场景: 指标数据的收集(input)、存储(output),并且做好存储格式是metric格式。这样开发最方便
- telegraf不适合的场景:输出数据格式不是 metric,并且从 metric 转换成目标格式工作量很大,就不太适合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号