谈谈influxdb2.7在物联网平台的运用、以及即将到来的influxdb3.0会有哪些变化
influxdb 概念普及
key、value数据库存储引擎
influxdb的本质还是key、value数据库。因此先介绍下key、value数据库相关知识。
BigTable论文,就是关于key、value数据库的论文。它的实现:
(1) levelDB
(2)rocksDB
他们的特点:
1、数据往磁盘上写入过程中,永远是append。同一个key的value如果发生变化,在磁盘上的格式如下:
key1, value1
key1, value2
查询时,同一个key,会使用最后一条数据作为结果。即查询出来key1的值是value2
key如果被删除,同样是会append一行,value用一个特殊的标记,标记这个key被删除了 (墓碑消息)。
2、数据合并。
如果某一个key被频繁更新,磁盘上会存在大量的冗余数据(只有最后一条是有效的)。因此,数据库会定期做数据合并。数据合并只要做两件事:
(1)同样的key,只保留最后一条,节省磁盘空间。
(2)根据key进行排序。这个文件叫SSTable。它的格式如下:
a1,valueA1
a2,valueA2
b2,valueB1
也就是说,邻近的key的数据在磁盘上是存储在一起的。这样有个好处,方便范围查询。
对于物联网平台来说,我们可以把“设备ID、时间戳”拼接一起作为key,这时我们要查询同一个设备一段时间的指标数据,就根据key进行范围查询就可以了,性能非常高。因为要查询的数据在磁盘上是连续存储的(存储在几个文件中),省去了磁盘寻道的开销,并且降低IO次数。
这里“数据合并”的算法,是很关键的。如何低成本做到“让相邻的key的数据存在一起”。主要涉及两个知识:
1、MemTable。往LevelDB(或者RocksDb)写入数据时,数据会先写入内存中(叫MemTable),在内存中会对数据按照key进行排序。当内存数据写满之后,数据会同步到SSTable(磁盘),也就是说,SSTable中的数据本来就是有序的。
2、“数据合并”操作,其实就是把多个SSTable合并成一个。这里就涉及到归并排序的思想。举例,两个已经拍好序(身高升序)的队伍,合并成一个队伍。算法如下:
(1)从两个队头,找出最矮的,出队。加入新的队列
(2)重复第一步。
局部有序之后,再排序,开销是比较低的。
https://www.cnblogs.com/chengxiao/p/6194356.html
前面提到数据开始只写入内存,那么如何保证持久性呢? 数据在写入内存之前,要先往磁盘写入WAL(write ahead log、预写日志)。这样即使数据库挂了,重启时可以WAL日志中恢复数据。WAL日志中的数据是append的,它的key不是有序的。排序是对SSTable中的数据做的操作。
这里介绍的存储方式,官方有个名字叫LSM(Log Structured Merge Tree),B+ Tree是数据库的另外一种技术流派(如Mysql、Mongodb)。
基于LSM存储引擎的数据库的使用场景
1、适合大部分是顺序写入的数据。对于物联网指标数据来讲(key用【设备ID、时间戳】),同一个设备的数据,大多是按照时间顺序写入的。这样就能保证该设备的磁盘数据(SSTable)基本是不会变化的,因为它本来就有序了。
举例,设备A的SSTable文件可能是这样的:
文件1 (SSTable1) 存储 1.1 - 1.2号的数据:
deviceA_20240101_10:00 , "speed : 1, lat: 30.0000, lng: 120.0000 "
deviceA_20240101_11:00 , "speed : 2, lat: 30.0000, lng: 120.0000 "
deviceA_202401012_10:00 , "speed : 2, lat: 30.0000, lng: 120.0000 "
文件2(SSTable2)存储 1.3号开始的数据。
假如今天是1.3号,在没有数据补传的情况下,要保证“磁盘上的数据永远按照Key排序”,只要对文件2进行修改就行了。
如果1.3号补传了1.1号的数据,为了保证key有序,就要对文件1、文件2进行合并来重新排序。
如果大量存在非时间顺序写入的场景,数据合并的开销就会非常大。
2、适合根据唯一key查询、或者根据key进行范围查询的场景。
3、不适合频繁update、delete的场景。原因和1中阐述的一致,会导致几乎所有的SSTable频繁做合并。
4、没有分组聚合能力,不适合做数据分析。
influxdb 和key、value数据库的关系
https://docs.influxdata.com/influxdb/v2/get-started/
- Tags: Key-value pairs with values that differ, but do not change often. Tags are meant for storing metadata for each point–for example, something to identify the source of the data like host, location, station, etc.
- Fields: Key-value pairs with values that change over time–for example: temperature, pressure, stock price, etc.
- Timestamp: Timestamp associated with the data. When stored on disk and queried, all data is ordered by time.
The following are important definitions to understand when using InfluxDB:
- Point: Single data record identified by its measurement, tag keys, tag values, field key, and timestamp.
- Series: A group of points with the same measurement, tag keys, and tag values.
Series 是一个很重要的概念。
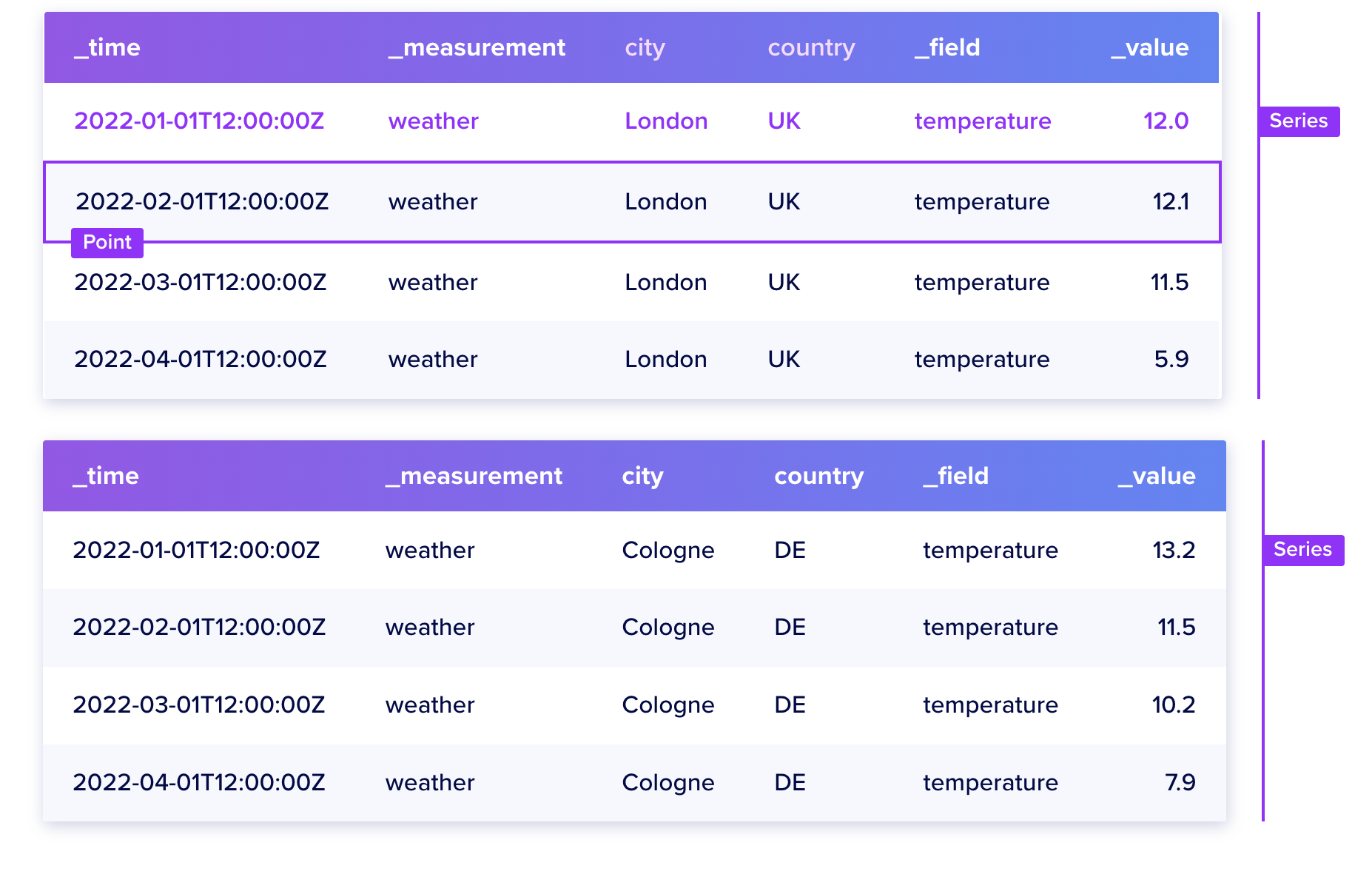
拿物联网指标数据举例:
1、Tags: 设备ID、设备所在的城市,是标签(Tag)
2、Fields: 设备的每一个指标,都是一个filed
Tags + Fields , 是唯一的。influxdb把它们合并起来,叫做一个Series(序列)。
同一个Series的数据,在磁盘上存储在一起。举例:
文件1(存储【设备A、北京、温度】这个序列的数据)内容:
20240101_10:00, "30度"
20240102_11:00, "31度"
20240102_11:00, "31度"
文件2(存储【设备A、北京、速度】这个序列的数据)内容:
20240101_10:00, 30.0
20240102_11:00, 120.0
20240102_11:00, 110
根据前面的理论,我们可以推断出,如果查询语句跨的Series越少,性能越高。因为要扫描的文件越少。
influxdb内核相关
https://docs.influxdata.com/influxdb/v2/reference/internals/storage-engine/#time-structured-merge-tree-tsm
https://www.youtube.com/watch?v=C5sv0CtuMCw&t=370s
简单讲两个内核相关的概念:
1、Time-Structured Merge Tree (TSM)
TSM 和LSM(Log Structured Merge)有的类似。
2、倒排索引
举例:
select * from device_metric where city = '上海' and time > 'xxx';
influxdb收到这个查询请求之后,它需要知道这个sql,都涵盖哪些Series。通俗来讲,就是这个城市都有哪些设备。
找Series的过程,用的就是倒排索引。
influxdb 2.7 在项目中使用情况
项目是一个物联网平台,会收集大量的物联网设备指标数据,每天有大于2000万行数据。一共要存储几十亿行数据,数据库技术选型至关重要。数据查询场景:
- 查询一个设备一段时间的指标
- 空间索引。查询某一段时间进入一个区域的所有车辆
技术演变如下:
1、Mongodb、机械硬盘
表结构:
| 列 | 说明 |
|---|---|
| deviceId | |
| timestamp | |
| metric | 一个json,key是指标名称,value是指标指 |
Mongodb还是B+ Tree结构。它的磁盘存储特点:
虽然我们可以根据设备ID建立索引,索引节点上的数据是有序的。但是相邻node对应的磁盘文件可以是不相邻的(有指针指向磁盘位置)。这就导致我们在查询一个设备的指标数据时,虽然可以命中索引,但是查询速度仍然不尽如人意。因为要去扫描很多磁盘块,来load设备一段时间的指标数据。
举例,一个设备一天有5000条指标数据,从索引中找到这些数据之后,可能要去上百个磁盘文件中load指标数据。
优化策略:
对数据做合并存储,一个设备一小时的数据只存一行。
优化之后,查询一个设备一段时间的指标数据,性能大幅提升(200ms左右)。
经验:
让查询结果中涵盖的数据,尽可能在磁盘上连续存储,减少机械硬盘寻道、以及IO次数,是数据库查询性能提升中关键一环。
指标查询问题解决了,但是用MongoDB做空间索引查询时,始终很慢(有些要几秒)。
空间查询我们的用法:
- 空间索引和指标查询用两张表,空间索引用的表数据不做合并。即表中每天新增2000万行以上的数据。
- 空间索引的需求:查询某一个区域内一段时间内有哪些车辆的轨迹。
- 尝试过对这张表进行分表,性能有所改善,但是不明显(某些场景还是大于1s)
于是,我们就推测,空间索引不是Mongodb强项。于是就计划尝试用Postgresql来做空间索引。
技术探索:使用Postgresql + Postgis作为物联网平台存储数据库
1、表结构和MongoDb使用的表结构类似。
| 列 | 说明 |
|---|---|
| deviceId | |
| timestamp | |
| loc | 类型geometry |
2、利用pg自带分区特性,每天、每个客户数据存一个分区。
先说空间索引解决方案:
给[loc、deviceId] 列创建了一个联合索引(空间索引、B tree联合索引)。https://developer.aliyun.com/article/109832
这样空间索引的查询,就用到了覆盖索引(索引中的字段,涵盖了查询需要的所有字段),速度很快 (200ms内)。
方案细节参考我的另外一篇文章:https://www.cnblogs.com/xushengbin/p/17919856.html
设备指标查询方案
1、数据不做合并,一天表新增2000万行数据。此种方案无论怎么加索引,机械硬盘下速度就是快不了,原因和MongoDb类似,避免了上百次次磁盘扫描的开销。
2、数据做合并,一个设备一小时的数据存一行。查询速度明细提升
最终方案
指标数据,存两张表(冗余存储):
1、表一,存储合并之后的数据(一个设备1小时数据进行合并后存储、一个设备一天最多24行数据),用来做设备指标查询
2、表二,只存储位置、时间、设备ID三个字段,可以满足空间索引查询需求。
两类查询,时间都在500ms以内。同时,使用并发100进行压测测试,性能杠杠的,压测期间磁盘IO负载正常。
这个方案的缺点就是需要做数据合并,开发成本、以及因为合并导致的业务复杂度(调试成本)提升了很多。方案并不完美。
技术探索:RocksDB
首先RocksDB不支持空间索引。
使用【设备ID、时间戳】拼接字符串,用作RocksDb的Key,数据写入、查询,都有极致的性能。(快的不可思议)
技术探索:InfluxDB
查询性能较RocksDB稍有下降,但是并发100情况下仍然在500ms内。
最终我们决定选用InfluxDB,原因:
1、专业的时序数据库。
2、在时序数据存储方面,受欢迎程度远远高于RocksDB
3、存储空间相比MongoDB、PG降低10倍。(RocksDB、InfluxDB都很节省存储空间)
4、数据查询便捷性。InfluxDB UI查询指标数据非常方便。我们前面做的行数据合并方案,合并之后查询数据就非常不方便了
influxdb 2.x 使用场景
适合场景
1、时序数据写入、查询
2、物联网平台数据存储
不适合的场景
1、大量非时间先后顺序写入的场景。
2、跨time series查询。
3、大量更新、删除操作的场景
4、key基数很大(超过百万)的场景。如我们有超过千万的设备,使用influxdb就会耗用过多的内存。
https://docs.influxdata.com/influxdb/v1/concepts/schema_and_data_layout/#avoid-too-many-series
influxdb 3.0 会带来哪些变化
1、带来了新的存储引擎
https://www.influxdata.com/blog/influxdb-engine/
它的特点:
1、2.x之前的版本,聚焦在能够高性能地读、写指标数据。 新版本对事件数据(不规则时序数据)支持也很好。
Today’s announcement represents the largest leap forward for InfluxDB since we introduced our TSM storage engine in 2016. At that time, we built a storage engine optimized for what our users most wanted from InfluxDB: fast performance for ingesting and querying metrics data. However, we’ve always had the vision that InfluxDB should be useful for event data (i.e. irregular time series) as well as metric data (i.e. regular time series). The new storage engine represents the next phase of InfluxDB’s life where we bring metric data and event data time series into a single database core, giving users the ability to create time series on the fly from raw, high-precision event data.
也就是说,3.0版本还是聚焦在时序数据。至于什么是“不规则的时序数据”,我分析应该指的是数据的key也可以千变万化。
对于指标数据来说,它的key就是指标的类型,如速度、里程、温度,不同时间点的数据集中key基本是固定的。
2、基数没有任何限制。
3、原生支持sql,甚至可以使用psql(postgresql客户端)连接influxdb。未来,会推出Apache Arrow FlightSQL,让用户可以高效查询时序数据。
IOx supports SQL natively and our cloud customers can connect using Postgres-compatible clients like psql, Grafana’s Postgres data source, and BI tools like PowerBI and Tableau. We will also be rolling out Apache Arrow FlightSQL as the standard matures, giving users high- performance access to millions of rows of time series data.
4、跨time series查询性能有指数级提升。
使用2.7版本时,查询一个表中最近1分钟的所有数据(5万条左右),速度相当慢(5-10s),就是因为查询跨上千个time series。
作为对比,我们查询一个设备10天的指标数据(同样是5万条左右),速度要快几十倍。
而这一问题,在3.0版本会得到极大改善。3.0版本也使得跨基数的数据分析成为可能。
influxdb 和竞品差异
https://stackshare.io/stackups/influxdb-vs-rocksdb
https://www.influxdata.com/blog/influxdb-is-27x-faster-vs-mongodb-for-time-series-workloads/
关于数据库新的认识
最近1个月,空余时间大多都花在数据库上面了。技术选型是个很费时间的工作:
1、先了解一种数据库的原理,推断它是否适合我们的业务场景。
2、api了解、压力测试
3、结合压测结果,验证先前的推断是否准确,然后修正自己的知识。
功夫不负有心人,经过这段时间探索,对于数据库有几点新的认识:
1、SSD不是万能的。用PG存储指标数据,不做数据合并的情况下,用SSD的查询性能,不如“机械硬盘下数据做合并方案”的性能。
原因我推测如下:
- 数据不合并的情况下,IO次数指数级增长。 SSD虽然能加快磁盘寻道开销,但是上百、上千次IO查询导致的时间开销是避免不了的。
2、让查询结果中需要的数据,尽可能在磁盘上连续存储,减少机械硬盘寻道、以及IO次数,是数据库查询性能提升中关键一环。
- 我们做的行数据合并存储、RocksDB中按照key顺序存储、以及时序数据库同一个series数据存放在一起,都是为了让特定的数据存放在一起,减少IO次数。
3、数据库选型重要,但是如何使用数据库更重要。 我们的方案中对比了数据是否进行行合并的性能差异,差别非常大。
4、了解了基于LSM存储引擎的数据库流派、以及基于BigTable论文的数据库实现。
5、在通用数据库之外,专业数据库同样大有可为。如我们调研的时序数据库,它为我们的特定场景,提供了超越通用数据库的性能,并且大大降低时序数据的存储成本(相比mongodb,存储空间降低10倍)、运维成本(过期数据自动删除等)、开发成本(窗口函数、时序数据去重等)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号