CentOS7.9安装K8S高可用集群(三主三从)
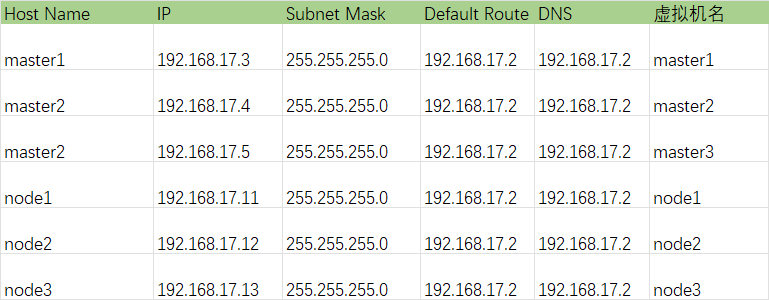
服务器规划见下表(均为4核4G配置):
按上表准备好服务器后,对所有服务器节点的操作系统内核由3.10升级至5.4+(Haproxy、Keepalived和Ceph存储等需要用到),步骤如下:
#导入用于内核升级的yum源仓库ELRepo的秘钥 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org #启用ELRepo仓库yum源 rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm #查看当前可供升级的内核版本 yum --disablerepo="*" --enablerepo="elrepo-kernel" list available #安装长期稳定版本的内核(本例中为5.4.231-1.el7.elrepo) yum --enablerepo=elrepo-kernel install kernel-lt -y #设置GRUB的默认启动内核为刚刚新安装的内核版本(先备份,再修改) cp /etc/default/grub /etc/default/grub.bak vi /etc/default/grub
/etc/default/grub文件原来的内容如下:
GRUB_TIMEOUT=5 GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)" GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos_jumpserver/root rd.lvm.lv=centos_jumpserver/swap rhgb quiet" GRUB_DISABLE_RECOVERY="true"
将其的 GRUB_DEFAULT=saved 的值由 saved 改为 0 即可(即 GRUB_DEFAULT=0)保存退出,接着执行以下命令:
#重新生成启动引导项配置文件,该命令会去读取/etc/default/grub内容 grub2-mkconfig -o /boot/grub2/grub.cfg #重启系统 reboot -h now
重启完成后,查看一下当前的操作系统及内核版本:
[root@master1 ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) [root@master1 ~]# uname -rs Linux 5.4.231-1.el7.elrepo.x86_64
更新一下yum源仓库CentOS-Base.repo的地址,配置阿里云镜像地址,用于加速后续某些组件的下载速度:
#先安装一下wget工具 yum install -y wget #然后备份 CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak #使用阿里云镜像仓库地址重建CentOS-Base.repo wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#运行yum makecache生成缓存
yum makecache
关闭所有服务器的防火墙(在某些组件(例如Dashboard)的防火墙端口开放范围不是很清楚的情况下选择将其关闭,生产环境最好按照K8S和相关组件官网的说明,保持防火墙开启状态下选择开放相关端口):
#临时关闭防火墙
systemctl stop firewalld
#永久关闭防火墙(禁用,避免重启后又打开)
systemctl disable firewalld
设置所有服务器的/etc/hosts文件,做好hostname和IP的映射:
cat >> /etc/hosts << EOF
192.168.17.3 master1 192.168.17.4 master2 192.168.17.5 master3 192.168.17.11 node1 192.168.17.12 node2 192.168.17.13 node3 192.168.17.200 lb # 后面将用于Keepalived的VIP(虚拟IP),如果不是高可用集群,该IP可以是master1的IP
EOF
设置所有服务器的时间同步组件(K8S在进行某些集群状态的判断时(例如节点存活)需要有统一的时间进行参考):
#安装时间同步组件 yum install -y ntpdate #对齐一下各服务器的当前时间 ntpdate time.windows.com
禁用selinux(K8S在SELINUX方面的使用和控制还不是非常的成熟):
#临时禁用Selinux setenforce 0 #永久禁用Selinux sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
关闭操作系统swap功能(swap功能可能会使K8S在内存方面的QoS策略失效,进而影响内存资源紧张时的Pod驱逐):
#临时关闭swap功能 swapoff -a #永久关闭swap功能 sed -ri 's/.*swap.*/#&/' /etc/fstab
在每个节点上将桥接的IPv4流量配置为传递到iptables的处理链(K8S的Service功能的实现组件kube-proxy需要使用iptables来转发流量到目标pod):
#新建 /etc/sysctl.d/k8s.conf 配置文件 cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness = 0 EOF #新建 /etc/modules-load.d/k8s.conf 配置文件 cat > /etc/modules-load.d/k8s.conf << EOF br_netfilter overlay EOF #加载配置文件 sysctl --system #加载br_netfilter模块(可以使 iptables 规则在 Linux Bridges 上面工作,用于将桥接的流量转发至iptables链) #如果没有加载br_netfilter模块,并不会影响不同node上的pod之间的通信,但是会影响同一node内的pod之间通过service来通信 modprobe br_netfilter #加载网络虚拟化技术模块 modprobe overlay
#检验网桥过滤模块是否加载成功
lsmod | grep -e br_netfilter -e overlay
K8S的service有基于iptables和基于ipvs两种代理模型,基于ipvs的性能要高一些,但是需要手动载入ipvs模块才能使用:
#安装ipset和ipvsadm yum install -y ipset ipvsadm #创建需要加载的模块写入脚本文件(高版本内核nf_conntrack_ipv4已经换成nf_conntrack) cat > /etc/sysconfig/modules/ipvs.modules << EOF #!/bin/bash modprobe ip_vs modprobe ip_vs_rr modprobe ip_vs_wrr modprobe ip_vs_sh modprobe nf_conntrack EOF #为上述为脚本添加执行权限 chmod +x /etc/sysconfig/modules/ipvs.modules #执行上述脚本 /bin/bash /etc/sysconfig/modules/ipvs.modules #查看上述脚本中的模块是否加载成功 lsmod | grep -e -ip_vs -e nf_conntrack
在master1节点上使用RSA算法生成非对称加密公钥和密钥,并将公钥传递给其他节点(方便后面相同配置文件的分发传送,以及从master1上免密登录到其他节点进行集群服务器管理):
#使用RSA算法成生密钥和公钥,遇到输入,直接Enter即可 ssh-keygen -t rsa #将公钥传送给其他几个节点(遇到(yes/no)的一路输入yes,并接着输入相应服务器的root密码) for i in master1 master2 master3 node1 node2 node3;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'node3'"
and check to make sure that only the key(s) you wanted were added.
配置所有节点的limits:
#在所有节点上临时修改limits ulimit -SHn 65536 #先在master1节点永久修改limits vi /etc/security/limits.conf #在最后添加以下内容 * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 * soft memlock unlimited * soft memlock unlimited
然后将master1上的/etc/security/limits.conf文件复制到其他服务器节点上
scp /etc/security/limits.conf root@master2:/etc/security/limits.conf scp /etc/security/limits.conf root@master3:/etc/security/limits.conf scp /etc/security/limits.conf root@node3:/etc/security/limits.conf scp /etc/security/limits.conf root@node2:/etc/security/limits.conf scp /etc/security/limits.conf root@node1:/etc/security/limits.conf
在所有节点上安装Docker(K8S v1.24后推荐使用符合CRI标准的containerd或cri-o等作为容器运行时,原来用于支持Docker作为容器运行时的dockershim从该版本开始也已经从K8S中移除,如果还要坚持使用Docker的话,需要借助cri-dockerd适配器,性能没containerd和cri-o好):
#卸载旧docker相关组件 yum remove -y docker* yum remove -y containerd* #下载docker-ce仓库的yum源配置 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo #安装特定版本的docker(要符合目标版本K8S的docker版本要求) yum install -y docker-ce-19.03.15 docker-ce-cli-19.03.15 containerd.io #配置docker(国内华中科技大学的镜像仓库、cgroup驱动为systemd等) mkdir -p /etc/docker cat > /etc/docker/daemon.json << EOF { "exec-opts": ["native.cgroupdriver=systemd"], "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"], "log-driver":"json-file", "log-opts": {"max-size":"500m", "max-file":"3"} } EOF #立即启动Docker,并设置为开机自动启动 systemctl enable docker --now
设置下载K8S相关组件的仓库为国内镜像yum源(国外的太慢了,这里设置为阿里云的):
cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
在master1、master2和master3节点上安装kubeadm、kubectl和kubelet三个工具(不要太新的版本,也不要太旧,否则很多基于K8S的周边工具和应用无法配对,比如kubeSphere、Rook等):
yum install -y kubeadm-1.20.2 kubectl-1.20.2 kubelet-1.20.2 --disableexcludes=kubernetes
在node1、node2和node3节点上安装kubeadm和kubelet两个工具:
yum install -y kubeadm-1.20.2 kubelet-1.20.2 --disableexcludes=kubernetes
在所有节点上将kubelet使用的cgroup drver与前面安装配置Docker时的对齐,都设置为systemd :
#先在master1上修改"/etc/sysconfig/kubelet"文件的内容 vi /etc/sysconfig/kubelet #cgroup-driver使用systemd驱动 KUBELET_EXTRA_ARGS="--cgroup-driver=systemd" #kube-proxy基于ipvs的代理模型 KUBE_PROXY_MODE="ipvs"
然后将master1上的 /etc/sysconfig/kubelet 文件复制到其他节点上
scp /etc/sysconfig/kubelet root@master2:/etc/sysconfig/kubelet scp /etc/sysconfig/kubelet root@master3:/etc/sysconfig/kubelet scp /etc/sysconfig/kubelet root@node3:/etc/sysconfig/kubelet scp /etc/sysconfig/kubelet root@node2:/etc/sysconfig/kubelet scp /etc/sysconfig/kubelet root@node1:/etc/sysconfig/kubelet
在所有节点上立即启动kubelet,并设置为开机自动启动
#立即启动kubelet,并设置为开机自动启动 systemctl enable kubelet --now #查看各节点上kubelet的运行状态(由于网络组件还没安装,此时kubelet会不断重启,属于正常现象) systemctl status kubelet
在master1、master2和master3节点上安装HAProxy和Keepalived高可用维护组件(仅高可用集群需要):
yum install -y keepalived haproxy
在master1节点上修改HAproxy配置文件/etc/haproxy/haproxy.cfg,修改好后分发到master2和master3:
#先备份HAProxy配置文件 cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak #修改HAProxy配置文件 vi /etc/haproxy/haproxy.cfg
global maxconn 2000 ulimit-n 16384 log 127.0.0.1 local0 err stats timeout 30s defaults log global mode http option httplog timeout connect 5000 timeout client 50000 timeout server 50000 timeout http-request 15s timeout http-keep-alive 15s frontend monitor-in bind *:33305 mode http option httplog monitor-uri /monitor listen stats bind *:8006 mode http stats enable stats hide-version stats uri /stats stats refresh 30s stats realm Haproxy\ Statistics stats auth admin:admin frontend k8s-master bind 0.0.0.0:16443 bind 127.0.0.1:16443 mode tcp option tcplog tcp-request inspect-delay 5s default_backend k8s-master backend k8s-master mode tcp option tcplog option tcp-check balance roundrobin default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100 # 下面的配置根据实际情况修改 server master1 192.168.17.3:6443 check server master2 192.168.17.4:6443 check server master3 192.168.17.5:6443 check
然后将master1节点上的 /etc/haproxy/haproxy.cfg 文件复制到master2和master3节点上
scp /etc/haproxy/haproxy.cfg root@master2:/etc/haproxy/haproxy.cfg scp /etc/haproxy/haproxy.cfg root@master3:/etc/haproxy/haproxy.cfg
在master1、master2和master3节点上修改Keepalived的配置文件(注意各节点不一样的地方,红色标记):
#先备份Keepalived的配置文件 cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak #修改HAProxy配置文件 vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
## 标识本节点的字符串,通常为 hostname
router_id master1
script_user root
enable_script_security
}
## 检测脚本
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。如果脚本执行结果非 0,并且 weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
# 每2秒检查一次
interval 2
# 一旦脚本执行成功,权重减少5
weight -5
fall 3
rise 2
}
## 定义虚拟路由,VR_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VR_1 {
## 主节点为 MASTER,对应的备份节点为 BACKUP
state MASTER
## 绑定虚拟 IP 的网络接口(网卡),与本机 IP 地址所在的网络接口相同
interface ens32
# 主机的IP地址
mcast_src_ip 192.168.17.3
# 虚拟路由id
virtual_router_id 100
## 节点优先级,值范围 0-254,MASTER 要比 BACKUP 高
priority 100
## 优先级高的设置 nopreempt 解决异常恢复后再次抢占的问题
nopreempt
## 组播信息发送间隔,所有节点设置必须一样,默认 1s
advert_int 2
## 设置验证信息,所有节点必须一致
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
## 虚拟 IP 池, 所有节点设置必须一样
virtual_ipaddress {
## VIP,可以定义多个
192.168.17.200
}
track_script {
chk_apiserver
}
}
在master1节点上新建节点存活监控脚本 /etc/keepalived/check_apiserver.sh :
vi /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 5)
do
check_code=$(pgrep kube-apiserver)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 5
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
然后将master1节点上的 /etc/keepalived/check_apiserver.sh 文件复制到master2和master3节点上:
scp /etc/keepalived/check_apiserver.sh root@master2:/etc/keepalived/check_apiserver.sh scp /etc/keepalived/check_apiserver.sh root@master3:/etc/keepalived/check_apiserver.sh
各节点修改 /etc/keepalived/check_apiserver.sh 文件为可执行权限:
chmod +x /etc/keepalived/check_apiserver.sh
各节点立即启动HAProxy和Keepalived,并设置为开机启动:
#立即启动haproxy,并设置为开机启动 systemctl enable haproxy --now #立即启动keepalived,并设置为开机启动 systemctl enable keepalived --now
测试Keepalived维护的VIP是否畅通:
#在宿主机上(本例为Windows) ping 192.168.17.200 正在 Ping 192.168.17.200 具有 32 字节的数据: 来自 192.168.17.200 的回复: 字节=32 时间=1ms TTL=64 来自 192.168.17.200 的回复: 字节=32 时间<1ms TTL=64 来自 192.168.17.200 的回复: 字节=32 时间=1ms TTL=64 来自 192.168.17.200 的回复: 字节=32 时间<1ms TTL=64 192.168.17.200 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失), 往返行程的估计时间(以毫秒为单位): 最短 = 0ms,最长 = 1ms,平均 = 0ms #在K8S各节点上 ping 192.168.17.200 -c 4 PING 192.168.17.200 (192.168.17.200) 56(84) bytes of data. 64 bytes from 192.168.17.200: icmp_seq=1 ttl=64 time=0.058 ms 64 bytes from 192.168.17.200: icmp_seq=2 ttl=64 time=0.055 ms 64 bytes from 192.168.17.200: icmp_seq=3 ttl=64 time=0.077 ms 64 bytes from 192.168.17.200: icmp_seq=4 ttl=64 time=0.064 ms --- 192.168.17.200 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3112ms rtt min/avg/max/mdev = 0.055/0.063/0.077/0.011 ms
接下来我们在master1节点生成并配置kubeadm工具用于初始化K8S控制平面(即Master)的配置文件(这里命名为kubeadm-config.yaml):
#进入 /etc/kubernetes/ 目录 cd /etc/kubernetes/ #使用以下命令先将kubeadm默认的控制平台初始化配置导出来 kubeadm config print init-defaults > kubeadm-config.yaml
生成的kubeadm-config.yaml文件内容如下(红色部分为要注意根据情况修改的,蓝色是为高可用集群新加的配置):
apiVersion: kubeadm.k8s.io/v1beta2 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.17.3 #当前节点IP(各节点不同) bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock name: master1 #当前节点hostname(各节点不同) taints: - effect: NoSchedule key: node-role.kubernetes.io/master --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: "192.168.17.200:16443" #Keepalived维护的VIP和HAProxy维护的Port controllerManager: {} dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers #K8S内部拉取镜像时将使用的镜像仓库地址 kind: ClusterConfiguration kubernetesVersion: v1.20.0 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/16 #K8S内部生成Service资源对象的IP时将使用的CIDR格式网段 podSubnet: 10.244.0.0/16 #K8S内部生成Pod资源对象的IP时将使用的CIDR格式网段,宿主机、Service、Pod三者的网段不能重叠 scheduler: {}
添加的podSubnet配置项与在命令行中的参数 --pod-network-cidr是同一个参数,表明使用CNI标准的Pod的网络插件(后面的Calico就是)
然后将master1节点上的 /etc/kubernetes/kubeadm-config.yaml 文件复制到master2和master3节点上,并修改上述标红的(各节点不同)部分:
scp /etc/kubernetes/kubeadm-config.yaml root@master2:/etc/kubernetes/kubeadm-config.yaml scp /etc/kubernetes/kubeadm-config.yaml root@master3:/etc/kubernetes/kubeadm-config.yaml
所有master节点使用刚刚的控制平台初始化配置文件 /etc/kubernetes/kubeadm-config.yaml 提前下载好初始化控制平台需要的镜像:
kubeadm config images pull --config /etc/kubernetes/kubeadm-config.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.20.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.20.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.20.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.20.0
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.2
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.4.13-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.7.0
然后将master1选为主节点(对应Keepalived的配置),使用配置文件/etc/kubernetes/kubeadm-config.yaml进行K8S控制平面的初始化(会在/etc/kubernetes目录下生成对应的证书和配置文件):
kubeadm init --config /etc/kubernetes/kubeadm-config.yaml --upload-certs
[init] Using Kubernetes version: v1.20.0 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1] and IPs [10.96.0.1 192.168.17.3 192.168.17.200] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [192.168.17.3 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [192.168.17.3 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "admin.conf" kubeconfig file [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "kubelet.conf" kubeconfig file [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "controller-manager.conf" kubeconfig file [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 16.635364 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: 1f0eae8f50417882560ecc7ec7f08596ed1910d9f90d237f00c69eb07b8fb64c [mark-control-plane] Marking the node master1 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)" [mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: abcdef.0123456789abcdef [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.17.200:16443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4316261bbf7392937c47cc2e0f4834df9d6ad51fea47817cc37684a21add36e1 \ --control-plane --certificate-key 1f0eae8f50417882560ecc7ec7f08596ed1910d9f90d237f00c69eb07b8fb64c Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.17.200:16443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4316261bbf7392937c47cc2e0f4834df9d6ad51fea47817cc37684a21add36e1
如果初始化失败,可以使用以下命清理一下,然后重新初始化:
kubeadm reset -f ipvsadm --clear rm -rf ~/.kube
初始化完master1节点上的k8s控制平面后生成的文件夹和文件内容如下图所示:
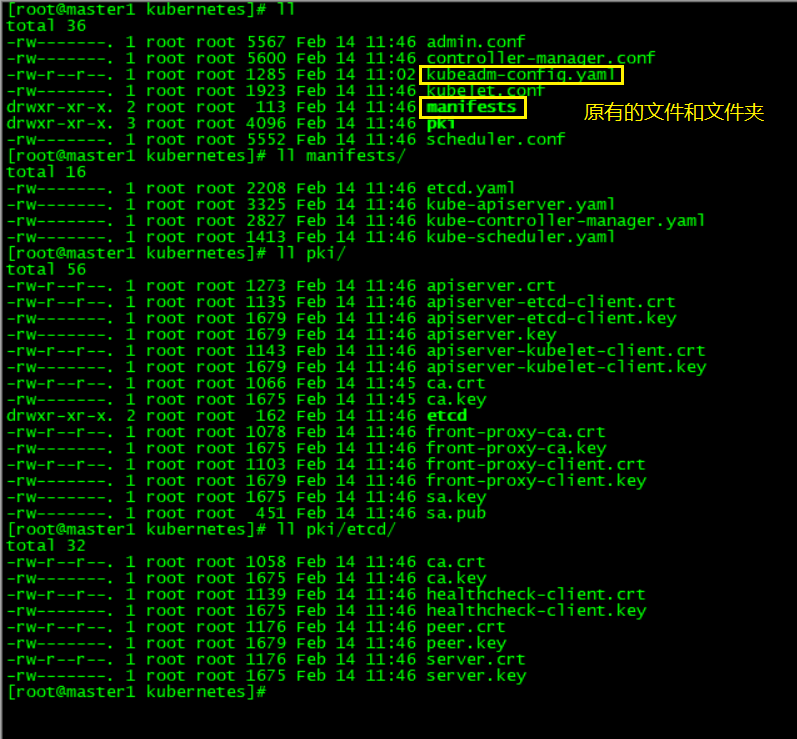
根据master1上控制平台初化始成功后的提示,我们继续完成高可用集群搭建的剩余工作。
为常规的普通用户执行以下命令:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
为 root 用户执行以下命令:
export KUBECONFIG=/etc/kubernetes/admin.conf
请确保你一定执行了上述命令,否则你可能会遇到如下错误:
[root@master1 kubernetes]# kubectl get cs The connection to the server localhost:8080 was refused - did you specify the right host or port?
在master2和master3节点上分别执行以下命令将相应节点加入到集群成为控制平面节点(即主节点):
kubeadm join 192.168.17.200:16443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4316261bbf7392937c47cc2e0f4834df9d6ad51fea47817cc37684a21add36e1 \ --control-plane --certificate-key 1f0eae8f50417882560ecc7ec7f08596ed1910d9f90d237f00c69eb07b8fb64c
This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane (master) label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.
根据提示,在master2和master3节点上分别执行以下命令:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
在node1、node2和node3节点上分别执行以下命令将相应节点加入到集群成为工作节点:
kubeadm join 192.168.17.200:16443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4316261bbf7392937c47cc2e0f4834df9d6ad51fea47817cc37684a21add36e1
此时查看集群的节点列表,发现均处于 NotReady 状态:
[root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 5m59s v1.20.2 master2 NotReady control-plane,master 4m48s v1.20.2 master3 NotReady control-plane,master 4m1s v1.20.2 node1 NotReady <none> 30s v1.20.2 node2 NotReady <none> 11s v1.20.2 node3 NotReady <none> 6s v1.20.2
此时查看集群的Pod列表,发现coredns相关的pod也处理 Pending 状态:
[root@master1 ~]# kubectl get pods -ALL NAMESPACE NAME READY STATUS RESTARTS AGE L kube-system coredns-7f89b7bc75-252wl 0/1 Pending 0 6m12s kube-system coredns-7f89b7bc75-7952s 0/1 Pending 0 6m12s kube-system etcd-master1 1/1 Running 0 6m19s kube-system etcd-master2 1/1 Running 0 5m6s kube-system etcd-master3 1/1 Running 0 4m20s kube-system kube-apiserver-master1 1/1 Running 0 6m19s kube-system kube-apiserver-master2 1/1 Running 0 5m9s kube-system kube-apiserver-master3 1/1 Running 1 4m21s kube-system kube-controller-manager-master1 1/1 Running 1 6m19s kube-system kube-controller-manager-master2 1/1 Running 0 5m10s kube-system kube-controller-manager-master3 1/1 Running 0 3m17s kube-system kube-proxy-68q8f 1/1 Running 0 34s kube-system kube-proxy-6m986 1/1 Running 0 5m11s kube-system kube-proxy-8fklt 1/1 Running 0 29s kube-system kube-proxy-bl2rx 1/1 Running 0 53s kube-system kube-proxy-pth46 1/1 Running 0 4m24s kube-system kube-proxy-r65vj 1/1 Running 0 6m12s kube-system kube-scheduler-master1 1/1 Running 1 6m19s kube-system kube-scheduler-master2 1/1 Running 0 5m9s kube-system kube-scheduler-master3 1/1 Running 0 3m22s
上述状态都是因为集群还没有安装Pod的网格插件,接下来就为集群安装一个名为Calico的网络插件!
使用 "kubectl apply -f [podnetwork].yaml" 为K8S集群安装Pod网络插件,用于集群内Pod之间的网络连接建立(不同节点间的Pod直接用其Pod IP通信,相当于集群节点对于Pod透明),我们这里选用符合CNI(容器网络接口)标准的calico网络插件(flanel也是可以的):
首选,从Calico的版本发行说明站点 https://docs.tigera.io/archive 找到兼容你所安装的K8S的版本,里面同时也有安装配置说明,如下截图所示:


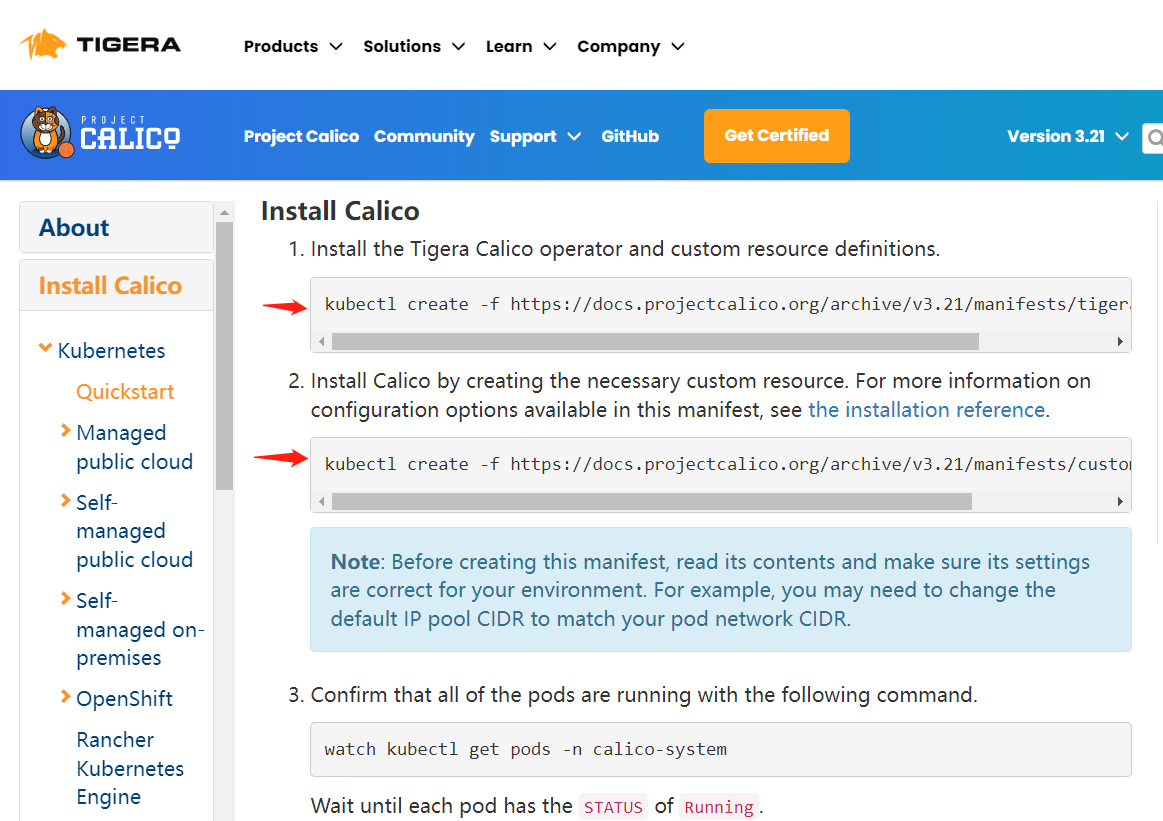
根据安装提示,我们执行以下命令进行Calico网络插件的安装:
#安装Calico Operator kubectl create -f https://docs.projectcalico.org/archive/v3.19/manifests/tigera-operator.yaml
也可以直接在浏览器打开目标URL,将内容复制下来创建一个yaml文件(例如创建一个 /etc/kubernetes/calico-operator.yaml 文件(其内容就是tigera-operator.yaml文件的内容)),然后直接用这个本地yaml文件安装Calico Operator:
kubectl create -f /etc/kubernetes/calico-operator.yaml
接下来是Calico的资源定义文件的应用,这里我不直接使用在线文件进行应用,而是在浏览器打开目标URL,将内容复制下来创建一个yaml文件再应用(例如创建一个 /etc/kubernetes/calico-resources.yaml 文件),更改一下cidr网段配置,对齐之前kubeadm-config.yaml文件里的 podSubnet 的值;另外,为了防止在虚拟网络设备非常多的master节点上的calico-node一直无法进入Ready状态(日志一般会报出“calico/node is not ready: BIRD is not ready”,主要原因是Master节点上的calico的BGP网卡设备识别错误导致),我们要明确指定一下nodeAddressAutodetectionV4的判断方法(以你自己的网卡名称开头的正规表达式),修改好后部署该资源文件即可:
#直接应用在线文件的方式(我们这里不这样做,因为要修改cidr地址,直接用浏览打开下面这个网卡或用下载工具下载它) kubectl create -f https://docs.projectcalico.org/archive/v3.19/manifests/custom-resources.yaml
# This section includes base Calico installation configuration. # For more information, see: https://docs.projectcalico.org/v3.19/reference/installation/api#operator.tigera.io/v1.Installation apiVersion: operator.tigera.io/v1 kind: Installation metadata: name: default spec: # Configures Calico networking. calicoNetwork: # Note: The ipPools section cannot be modified post-install. ipPools: - blockSize: 26 cidr: 10.244.0.0/16 encapsulation: VXLANCrossSubnet natOutgoing: Enabled nodeSelector: all() nodeAddressAutodetectionV4: interface: ens.*
kubectl create -f /etc/kubernetes/calico-resources.yaml
执行完相关命令后,可以使用以下命令监控Calico相关Pod的部署进度(下载镜像需要一定时间,耐心等待!):
watch kubectl get pods -n calico-system
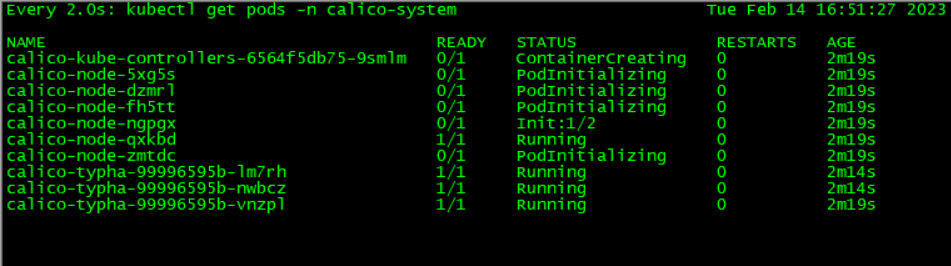
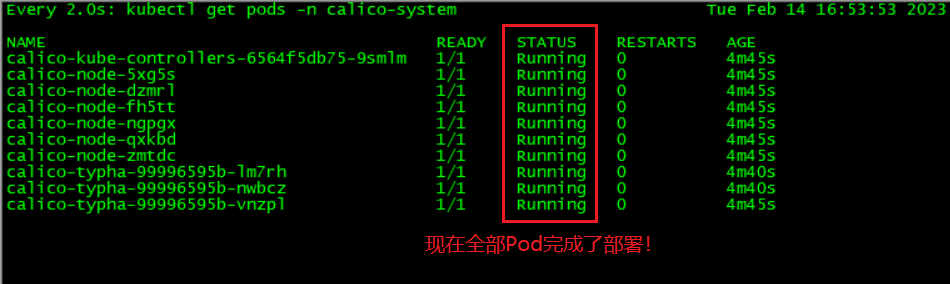
待等Calico的部署完成后,使用以下命令查看一下当前集群内所有Pod的运行状态(发现所有Pod都处于 Running 状态了):


[root@master1 kubernetes]# kubectl get pods -ALL NAMESPACE NAME READY STATUS RESTARTS AGE L calico-system calico-kube-controllers-6564f5db75-9smlm 1/1 Running 0 7m34s calico-system calico-node-5xg5s 1/1 Running 0 7m34s calico-system calico-node-dzmrl 1/1 Running 0 7m34s calico-system calico-node-fh5tt 1/1 Running 0 7m34s calico-system calico-node-ngpgx 1/1 Running 0 7m34s calico-system calico-node-qxkbd 1/1 Running 0 7m34s calico-system calico-node-zmtdc 1/1 Running 0 7m34s calico-system calico-typha-99996595b-lm7rh 1/1 Running 0 7m29s calico-system calico-typha-99996595b-nwbcz 1/1 Running 0 7m29s calico-system calico-typha-99996595b-vnzpl 1/1 Running 0 7m34s kube-system coredns-7f89b7bc75-252wl 1/1 Running 0 39m kube-system coredns-7f89b7bc75-7952s 1/1 Running 0 39m kube-system etcd-master1 1/1 Running 0 39m kube-system etcd-master2 1/1 Running 0 38m kube-system etcd-master3 1/1 Running 0 37m kube-system kube-apiserver-master1 1/1 Running 0 39m kube-system kube-apiserver-master2 1/1 Running 0 38m kube-system kube-apiserver-master3 1/1 Running 1 37m kube-system kube-controller-manager-master1 1/1 Running 1 39m kube-system kube-controller-manager-master2 1/1 Running 0 38m kube-system kube-controller-manager-master3 1/1 Running 0 36m kube-system kube-proxy-68q8f 1/1 Running 0 33m kube-system kube-proxy-6m986 1/1 Running 0 38m kube-system kube-proxy-8fklt 1/1 Running 0 33m kube-system kube-proxy-bl2rx 1/1 Running 0 33m kube-system kube-proxy-pth46 1/1 Running 0 37m kube-system kube-proxy-r65vj 1/1 Running 0 39m kube-system kube-scheduler-master1 1/1 Running 1 39m kube-system kube-scheduler-master2 1/1 Running 0 38m kube-system kube-scheduler-master3 1/1 Running 0 36m tigera-operator tigera-operator-6fdc4c585-lk294 1/1 Running 0 8m1s [root@master1 kubernetes]#
待等Calico的部署完成后,使用以下命令查看当前集群节点的状态(发现所有的节点都已处理 Ready 状态了):
[root@master1 kubernetes]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane,master 49m v1.20.2 master2 Ready control-plane,master 48m v1.20.2 master3 Ready control-plane,master 47m v1.20.2 node1 Ready <none> 43m v1.20.2 node2 Ready <none> 43m v1.20.2 node3 Ready <none> 43m v1.20.2
如果你打算让Master节点也参与到平常的Pod调度(生产环境一般不会这样做,以保证master节点的稳定性),那么你需要使用以下命令将Master节点上的 taint(污点标记)解除:
kubectl taint nodes --all node-role.kubernetes.io/master-
最后我们使用以下命令查看当前集群的状态,发现Scheduler和Controller Manager组件处理不健康状态:
[root@master1 ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused etcd-0 Healthy {"health":"true"}
解决上述问题需要将每个Master节点上的 /etc/kubernetes/manifests/kube-scheduler.yaml 和 /etc/kubernetes/manifests/kube-controller-manager.yaml 文件中的- --port=0注释掉(即前面加一个#),这里以 /etc/kubernetes/manifests/kube-scheduler.yaml文件为例:
[root@master1 ~]# vi /etc/kubernetes/manifests/kube-scheduler.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: component: kube-scheduler tier: control-plane name: kube-scheduler namespace: kube-system spec: containers: - command: - kube-scheduler - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf - --bind-address=127.0.0.1 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true #- --port=0 image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.20.0 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 8 httpGet: host: 127.0.0.1 path: /healthz port: 10259 scheme: HTTPS initialDelaySeconds: 10
然后重启一下各Master节点上的kubelet即可:
systemctl restart kubelet
[root@master1 ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"}
最后,我们再为K8S部署一个Web应用经常用到的服务路由和负载均衡组件——Ingress。
K8S Ingress是一个将K8S集群外部请求(南北流量)转发到集群内service的后端pod的七层负载均衡器,它转发的流量会跳过K8S集群内的kube-proxy直达目标pod(kube-proxy是集群内的四层负载均衡器,管理集群内pod间的东西流量的),下图是K8S官网给出的Ingress流量转发示意图:

使用Ingress进行服务路由时,Ingress Controller基于Ingress规则将客户端请求直接转发到Service对应的后端Endpoint(Pod)上,这样会跳过kube-proxy自动设置的路由转发规则,以提高网络转发效率。目前Ingress只能为HTTP和HTTPS提供服务,对于TCP/IP协议,可以通过设置Service的类型(type)为NodePort或LoadBalancer对集群外部的客户端提供服务。注意,Ingress是用于转发策略定义的,提供转发服务的的Ingress Controller,Ingress Controller会持续监控K8S API Server的/ingress接口的变化(即用户定义的后端服务的转发规则),当后端服务信息发生变化时,Ingress Controller会自动更新其转发规则。
目前K8S官方维护的Ingress控制器有三个: AWS、 GCE 和 Nginx Ingress,前两个为专门针对亚马逊公有云和Google公有云的,这里我们选择中立的 Nginx Ingress(还有其他很多第三方的 Ingress ,例如Istio Ingress、Kong Ingress、HAProxy Ingress等等)
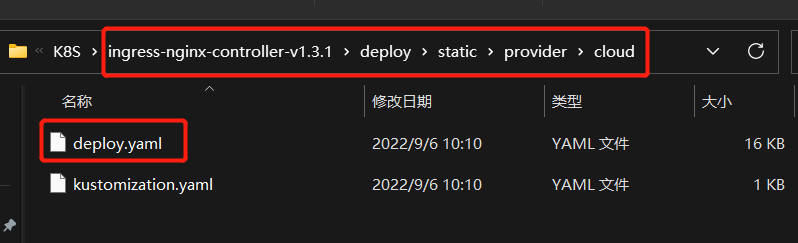
从Github上的 Ingress NGINX Controller 项目的readme页面找到支持当前K8S版本(v1.20.2)的Ingress-Nginx版本为v1.0.0~v1.3.1,这里我们选择v1.3.1版本(对应的Nginx版本为1.19.10+)。从Github上的tag列表里下载相应版本的Source code包,解压后从deploy\static\provider\cloud目录中找到deploy.yaml文件,该文件包含了Ingress-Nginx的所有K8S资源定义:
Ingress Nginx Controller 可以以 DaemonSet 或 Deployment 模式进行部署,通常可以考虑通过设置 nodeSelector 或亲和性调度策略将调度到固定的几个Node上提供服务,换句话说Ingress Nginx Controller在K8S集群内也是以Pod形式运行的,它自身要怎么接收外部客户端的访问的呢?这可以在容器级别设置hostPort,将80和433端口映射到宿主机上(确保端口没被用),这样外部客户端就可以通过URL地址“ http://<NodeIP>:80 ”或“ https://<NodeIP>:443 ”访问Ingress Nginx Controller了(hostPort为容器所在主机需要监听的端口号,未设置时默认与conainerPort相同;显示设置时,因端口占用同一台宿主机将无法启动该容器的第2份副本)。这样只需要K8S集群的部分Node当作边缘路由(前端接入路由)用于接入南北流量即可,接下来我们来修改deploy.yaml文件中的以下资源定义(红色为修改过的部分):
--- apiVersion: apps/v1 kind: DaemonSet metadata: labels: app.kubernetes.io/component: controller app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx app.kubernetes.io/version: 1.3.1 name: ingress-nginx-controller namespace: ingress-nginx spec: ...省略... image: registry.aliyuncs.com/google_containers/nginx-ingress-controller:v1.3.1 imagePullPolicy: IfNotPresent lifecycle: ...省略... ports: - containerPort: 80 name: http protocol: TCP hostPort: 80 - containerPort: 443 name: https protocol: TCP hostPort: 443 - containerPort: 8443 name: webhook protocol: TCP hostPort: 8443 ...省略... dnsPolicy: ClusterFirst nodeSelector: kubernetes.io/os: linux nodeRole: ingress-nginx-controller serviceAccountName: ingress-nginx ...省略... --- apiVersion: batch/v1 kind: Job metadata: labels: app.kubernetes.io/component: admission-webhook app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx app.kubernetes.io/version: 1.3.1 name: ingress-nginx-admission-create namespace: ingress-nginx spec: ...省略... image: registry.aliyuncs.com/google_containers/kube-webhook-certgen:v1.3.0 imagePullPolicy: IfNotPresent name: create ...省略... --- apiVersion: batch/v1 kind: Job metadata: labels: app.kubernetes.io/component: admission-webhook app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx app.kubernetes.io/version: 1.3.1 name: ingress-nginx-admission-patch namespace: ingress-nginx spec: ...省略... image: registry.aliyuncs.com/google_containers/kube-webhook-certgen:v1.3.0 imagePullPolicy: IfNotPresent name: patch ...省略... --- apiVersion: networking.k8s.io/v1 kind: IngressClass metadata: labels: app.kubernetes.io/component: controller app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx app.kubernetes.io/version: 1.3.1 name: nginx annotations: ingressclass.kubernetes.io/is-default-class: "true" spec: controller: k8s.io/ingress-nginx ...省略...
其中 ingressclass.kubernetes.io/is-default-class: "true" 注解将 ingress-nginx作为K8S集群的默认Ingress Class。
在deploy.yaml文件的修改过程中,我们将部署模式由 Deployment 改成了 DaemonSet ,并将宿主机的80、443和8443端口绑定给了Ingress Nginx Controller;另外,我们为Ingress Nginx Controller的节点选择器(nodeSelector)添加了额外的标签要求(nodeRole: ingress-nginx-controller),因此要先给目标节点打上该标签,例如我们选节集群里的node1和node2节点作为目标节点(边缘路由节点):
#在master节点为目标节点打上标签
kubectl label nodes node1 node2 nodeRole=ingress-nginx-controller
一切就绪后,将修改好的deploy.yaml文件上传到master1节点的 /etc/kubernetes/ingress/nginx 目录下(mkdir -p创建),接着在master1节点上使用以下命令就可以部署好Ingress Nginx Controller了:
kubectl apply -f /etc/kubernetes/ingress/nginx/deploy.yaml #使用以下命令监控部署进度(ingress-nginx为命名空间) watch kubectl get pods -n ingress-nginx

在宿主机浏览器上用http和https验证一下两个边缘路由节点,发现已经可以接到Ingress Nginx Controller的响应了(返回404是因为我们没有进行任何的有效Ingress策略配置)
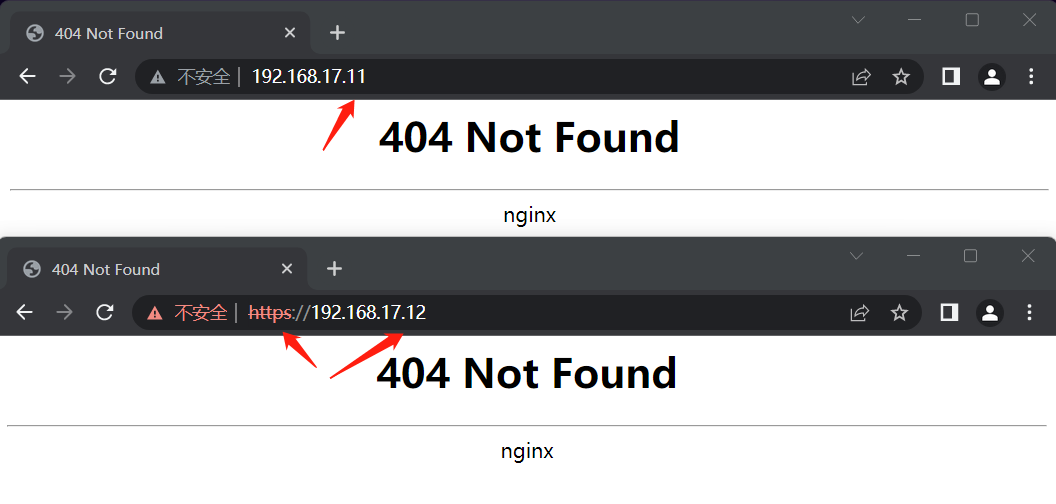
在生产环境上可以将域名绑定到充当边缘路由节点的IP,进行公网环境的服务暴露;如果客户端只能通过域名访问服务,那么就要求这客户端或DNS能直接将域名解析到边缘路由节点的真实IP上,测试时客户端可以在hosts文件上配置映射来模拟DNS解析。
至此,恭喜你已经成功搭建好一个高可用的三主三从的K8S集群!
以后部署任何应用时,记得第一个想想能否直接跑在K8S集群上!
在此基础上我们可以尝试一下直接使用 containerd 作为容器运行时的高可用K8S集群搭建!
最后,K8S是Service Mesh的基础,是云原生的核心基础!
后面千万不要在系统上执行yum update和yum upgrade,否则你的集群将毁于一旦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号