

LLM中的RLHF
我们前面介绍到instructGPT训练过程可以大概分为3个步骤:
- Step1:在监督数据集上微调模型(SFT)
- Step2: 训练reward model
- Step3:通过RLHF训练出符合人类偏好的模型
我们知道,RLHF的目标是减少模型的偏见,产出符合人类偏好的回答,接下来我们详细介绍一下RLHF的流程,如下图所示,RLHF涉及到4个模型:
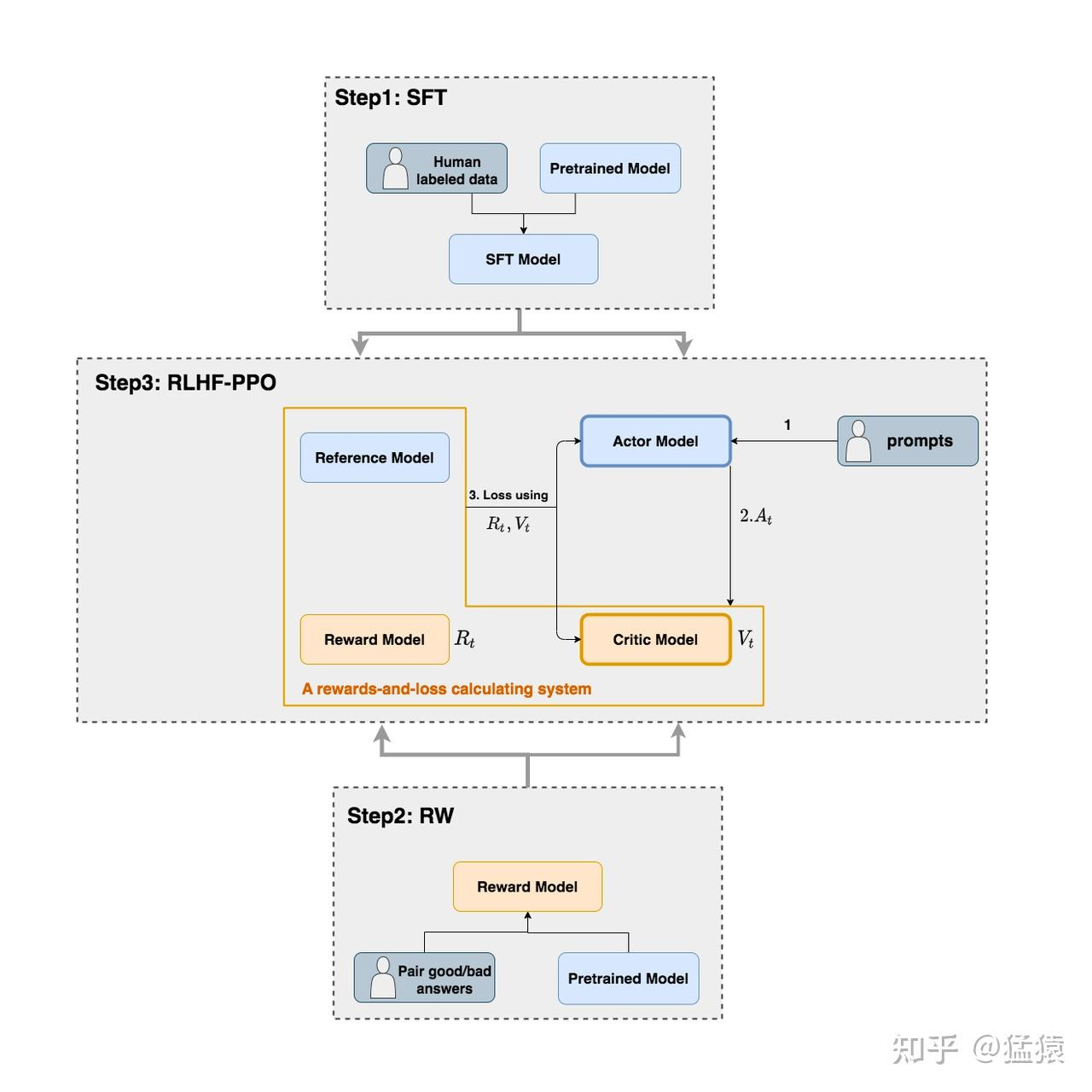
1. Actor Model
演员模型,这就是我们想要训练的目标语言模型,一般用SFT模型初始化
2. Critic Model
评论家模型,它的作用是预估从生成当前token开始到未来的总收益 \( V_t \),模型结构上评论家就是将演员模型的倒数第二层连接到一个新的全连接层上,除了这个全连接层之外,演员和评论家的参数都是共享的
3. Reward Model
奖励模型,它的作用是计算生成当前token的即时收益 \( R_t \) ,该模型在RLHT的前一步已经训练好,在RLHF过程中不更新参数
4. Reference Model
参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪,该模型一般用SFT模型初始化,在RLHF过程中也不更新参数
总结来说,RLHF阶段要训练的模型只有Actor Model和Critic Model,下面以PPO算法为例介绍RLHF训练流程
先回顾一下PPO算法的目标函数:
\[ J^{\theta'}(\theta) = \mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'}} \left[ \frac{p_\theta(a_t \mid s_t)}{p_{\theta'}(a_t \mid s_t)} A^{\theta'}(s_t, a_t) \right] \]
其中$A^{\theta'}(s_t, a_t) = R(\tau^t) - V_t$称为优势函数
在RLHF中,上面的目标函数也就是Actor模型训练的目标函数,但是稍微有些不同,下面解释上式在RLHF中的意义:
- $p_\theta(a_t \mid s_t)$:最新actor模型在t时刻预估的各个token的生成概率
- $p_{\theta'}(a_t \mid s_t)$:旧actor模型(采样数据模型)在t时刻预估的各个token的生成概率
- $V_t$:critic模型在t时刻预估的未来总收益
- $A^{\theta'}(s_t, a_t) = R_t + \gamma * V_{t+1} - V_t$,但在deepspeed-chat的RLHF实践中:
- $\begin{cases} R_t = -kl\_ctl * \left( \log \frac{P(A_t | S_t)}{P_{ref}(A_t | S_t)} \right), t \neq T \\ R_t = -kl\_ctl * \left( \log \frac{P(A_t | S_t)}{P_{ref}(A_t | S_t)} \right) + R_t, t = T \end{cases} $
- $kl\_ctl$:常量,可以理解成是一个控制比例的缩放因子,在deepspeed-chat中默认设为0.1
-
- $- \log \frac{P(A_t | S_t)}{P_{ref}(A_t | S_t)}$:Actor模型和Reference模型间的KL散度,为了防止模型训歪 基于这些,上面这个对 \(R_t\) 的设计可理解成:
- 当 \(t \neq T\) 时,我们更加关心Actor是否有在Ref的约束下生产token \(A_t\)
- 当 \(t = T\) 时,我们不仅关心Actor是否遵从了Ref的约束,也关心真正的即时收益 \(R_t\) ,为什么只有最后一个时刻的 \(R_t\) 被纳入了考量呢?这是因为在Reward模型训练阶段,就是用这个位置的 \(R_t\) 来表示对完整的prompt + response的奖励预测
除了Actor模型外,还有一个Critic模型要训练, Critic模型的训练Loss定义如下:
\(Critic\_loss = (R_t + \gamma * V_{t+1} - V_t)^2\)
RLHF的训练流程可以用如下伪代码表示:
for k in range(20000): # 采样 prompts = sample_prompt() responses, old_log_probs, old_values = respond(policy_model, prompts) # 反馈 scores = reward_model(prompts, responses) ref_log_probs, _ = analyze_responses(ref_policy_model, prompts, responses) rewards = reward_func(scores, old_log_probs, ref_log_probs) # 学习 advantages = advantage_func(rewards, old_values) for epoch in range(4): log_probs, values = analyze_responses(policy_model, prompts, responses) actor_loss = actor_loss_func(advantages, old_log_probs, log_probs) critic_loss = critic_loss_func(rewards, values) loss = actor_loss + 0.1 * critic_loss train(loss, policy_model.parameters())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号