

LLM4Rec:字节HLLM
背景
目前主流的推荐模型都是ID-based,这种ID-based的模型依赖user合item的交互信息,无法利用item和user的多模态信息,对冷启动不友好。
随着近年来LLM的突破性进展, 业界也在不断探索LLM在推荐系统中的应用, 这里大概可以分成三类:
- 信息增强: 利用LLM为推荐系统提供一些精细化的信息, 例如做Item的特征增强
- 对话式处理: 将推荐系统转换为与LLM兼容的对话驱动形式
- 直接输入ID: 修改LLM不再仅处理文本输入/输出, 比如直接输入ID特征给LLM
当前, LLM4Rec还面临着一些挑战, 比如在处理相同时间跨度的用户行为序列时, 相比于ID-based方法, 将用户行为历史作为文本输入LLM的方法, 每个行为都对应若干个token, 显然需要处理更长的序列长度, 且计算复杂度更高。此外, 基于LLM的方法相较于传统方法的性能提升并不显著, 远没有其它领域那么显著的提升。
作者提出, 关于LLM4Rec还有三个关键问题还需要再探索的:
- 预训练LLM权重的真正价值: LLM大规模预训练本质上是在做一个世界知识的压缩, 其权重蕴含着世界知识, 但使用大规模推荐数据训练时, 这些权重的真正价值还尚未挖掘。
- 有必要对推荐任务进行微调吗? 还不清楚进一步使用推荐任务微调是否有收益。
- LLM在推荐场景中能否呈现Scaling Law? 在更大规模的参数下, LLM4Rec是否也能像其它场景一样具有Scaling Law呢, 还未有结论。
基于此, 作者提出了Hierarchical Large Language Model(HLLM)方法,下面进行详细介绍。
模型结构
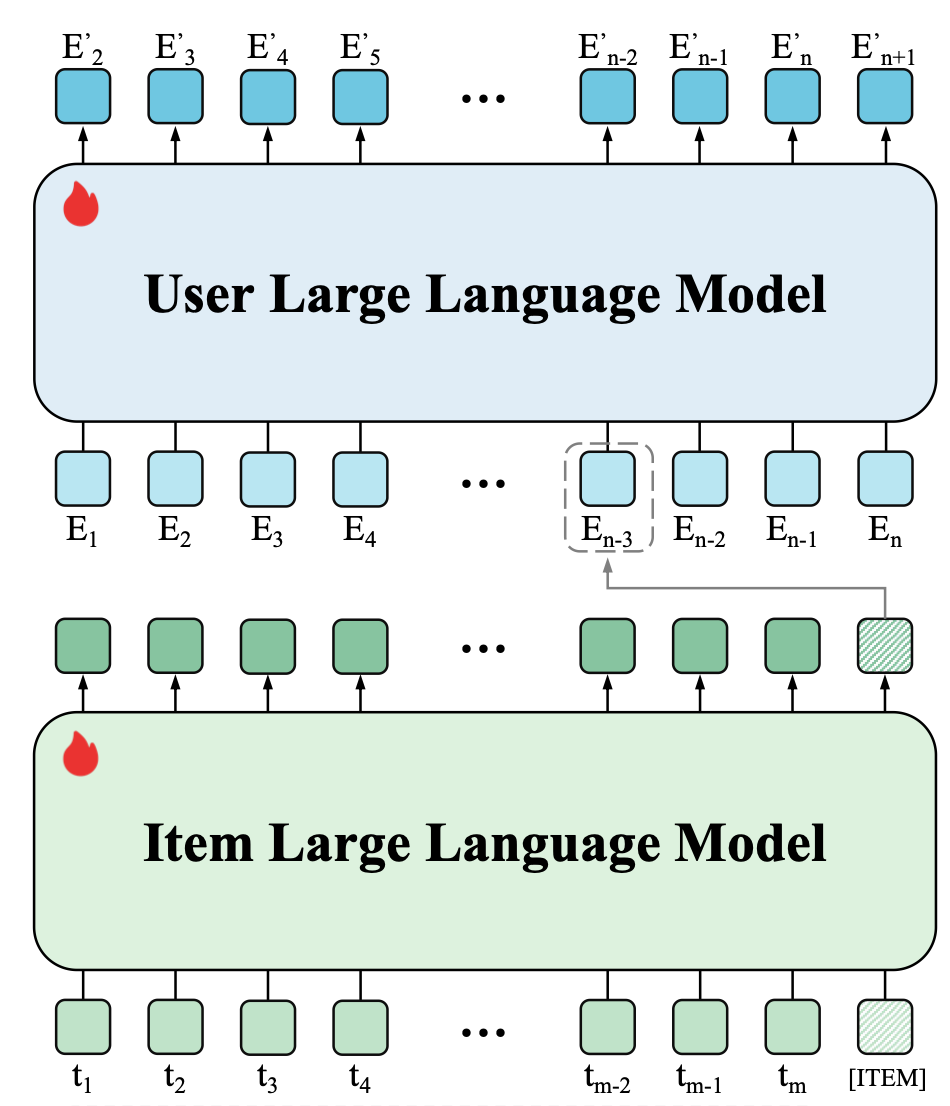
HLLM是一个分层模型,包含了item LLM 和 user LLM两个结构:
item LLM
item LLM其实就是一个item embedding提取器,输入如下item文本描述(在最后位置额外增加了一个特殊Token[ITEM]), 特殊Token对应的输出的隐含状态则作为该Item的Embedding

user LLM
User LLM的输入是用户历史交互序列$U=\{I_1,I_2,\ldots,I_n\}$,前面的Item LLM就起到传统深度模型的Embedding Lookup Table的作用, 这样就将用户行为序列转化成$\{E_1,E_2,\ldots,E_n\}$,然后, 再将这些Embedding作为输入, 进行Next Item Prediction, 预测下一位置的Item Embedding。这里User LLM对于Next Item Prediction的训练目标, 按照训练方式的差异, 可以分成生成式推荐与判别式推荐
生成式推荐
使用大模型自回归的训练方式, 使用InfoNCE作为生成损失,负样本从当前序列之外的item中随机采样
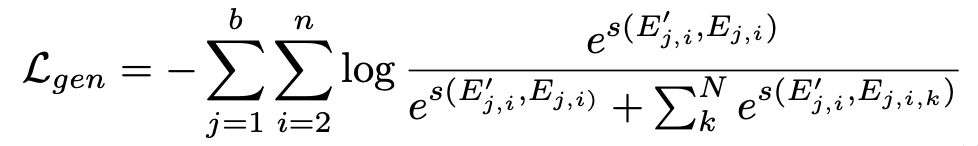
判别式推荐
判别式推荐就是给定一个用户行为序列和target item,预测用户是否会对这个item发生正反馈,采用了交叉熵损失来训练:
![]()
判别式推荐有两种训练方式:
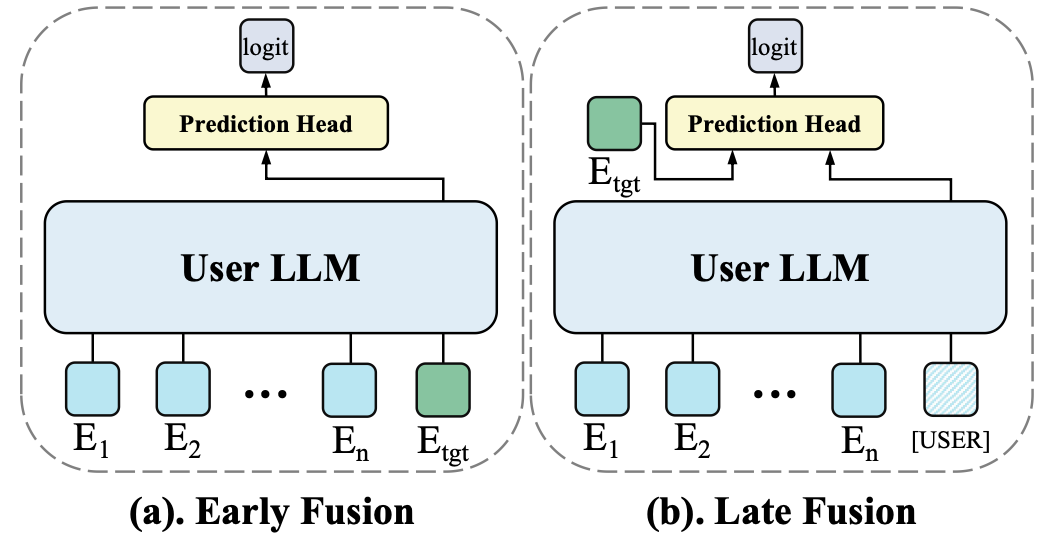
Early fusion
Early Fusion是将Target Item的Embedding 拼接在用户行为序列的最后, 再输入给User LLM, 然后再将对应位置的输出做分类预测。Early Fusion方式的优点是, Target Item可与用户行为序列在User LLM中进行充分的特征交叉, 它的效果一般会更好, 但效率较低。
Late Fusion
Late Fusion首先在用户行为序列的最后拼接一个特殊Token [USER], 类似Item LLM的方式, 再使用User LLM编码用户行为序列, 提取得到用户的Embedding(即[USER]位置对应的输出), 然后和item embedding计算相似度,其实就是一个双塔模型。Late Fusion在后期再实现特征交叉, 效果一般会差一些, 但在推理时效率更高。
最终,可以把生成式推荐的loss作为辅助loss和判别式推荐loss结合一起训练:
![]()
训练过程
具体地, 训练过程分成3个阶段:
- Stage1: 对HLLM的所有参数进行End2End训练,包括Item LLM和User LLM,采用判别损失函数。另外, 为加速训练,用户历史序列长度被截断至150。
- Stage2: 首先使用使用Stage1训练好的Item LLM对所有Item进行编码并存储其Embedding, 然后再继续训练User LLM。这个过程由于仅训练User LLM, 训练成本没那么高, 因此, 作者把用户序列长度从 150扩展至1000,以进一步提升User LLM的效果
- Stage3: 经过前两个阶段的大规模数据训练后,HLLM模型参数不再更新。作者为所有用户提取User LLM的User Embedding,并将其与Item LLM输出的Embedding以及其他现有特征结合,输入在线推荐模型进行训练。
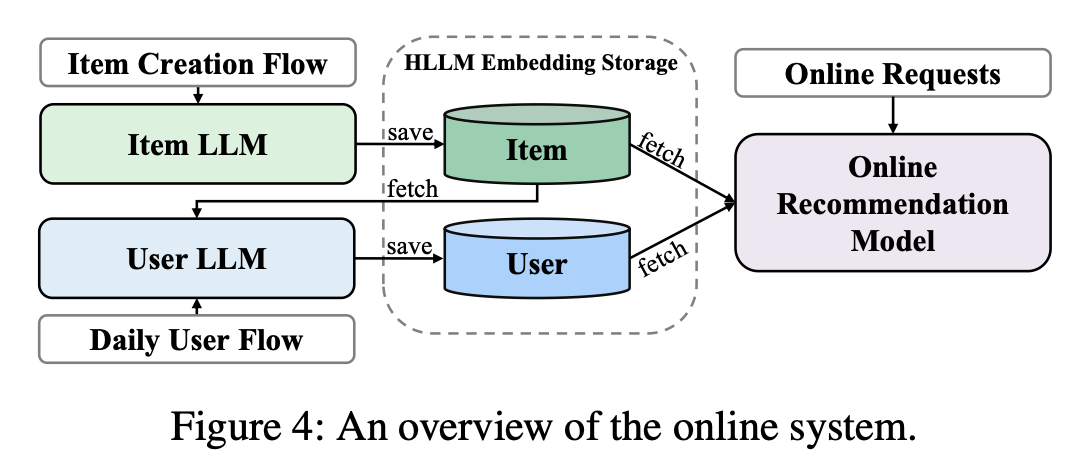
serving过程
item embed- dings are extracted when they are created, and user embeddings are updated on a daily basis only for users who had activity the previous day. Embeddings of items and users are stored for online model training and serving. Under this approach, the inference time of the online recommendation system is virtually unchanged.
实验和结论
1. LLM有无预训练对推荐效果的影响?
无论是Item LLM还是User LLM,基于预训练微调更好,预训练使用的Token越多, 推荐效果越好, 此外, 增加对话场景的SFT对推荐场景并无收益。
2. 使用推荐目标做微调的影响?
无论是Item LLM还是User LLM,都非常有必要使用推荐目标做微调
3. HLLM是否具有Scaling Law?
有
参考资料
代码:https://github.com/bytedance/HLLM
字节HLLM:在推荐系统落地User-Item分层的LLM方案
大模型与搜广推(二):论文精读之 HLLM, 字节抖音, arXiv 09 Sep 2024

 浙公网安备 33010602011771号
浙公网安备 33010602011771号