

transform
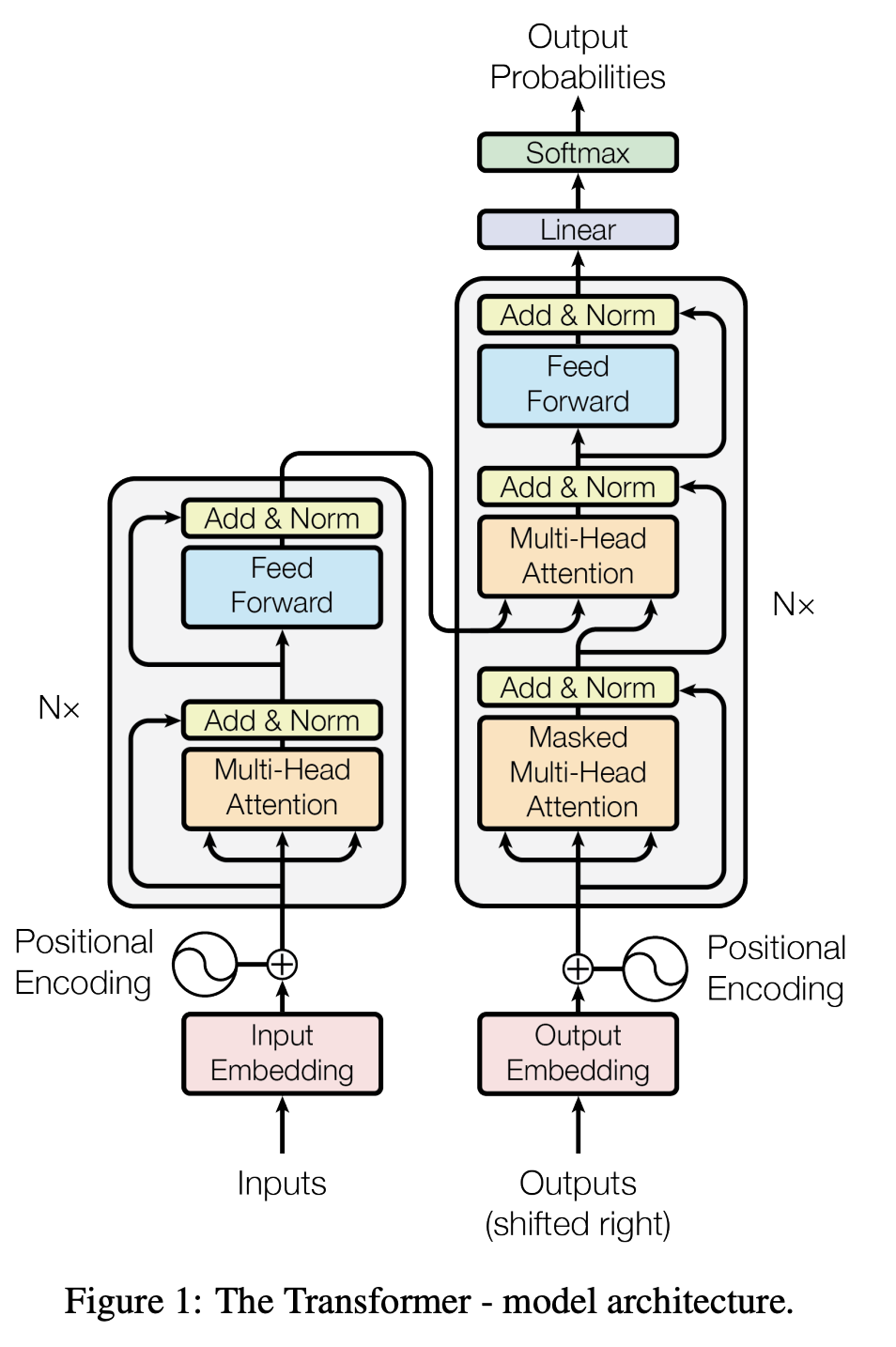
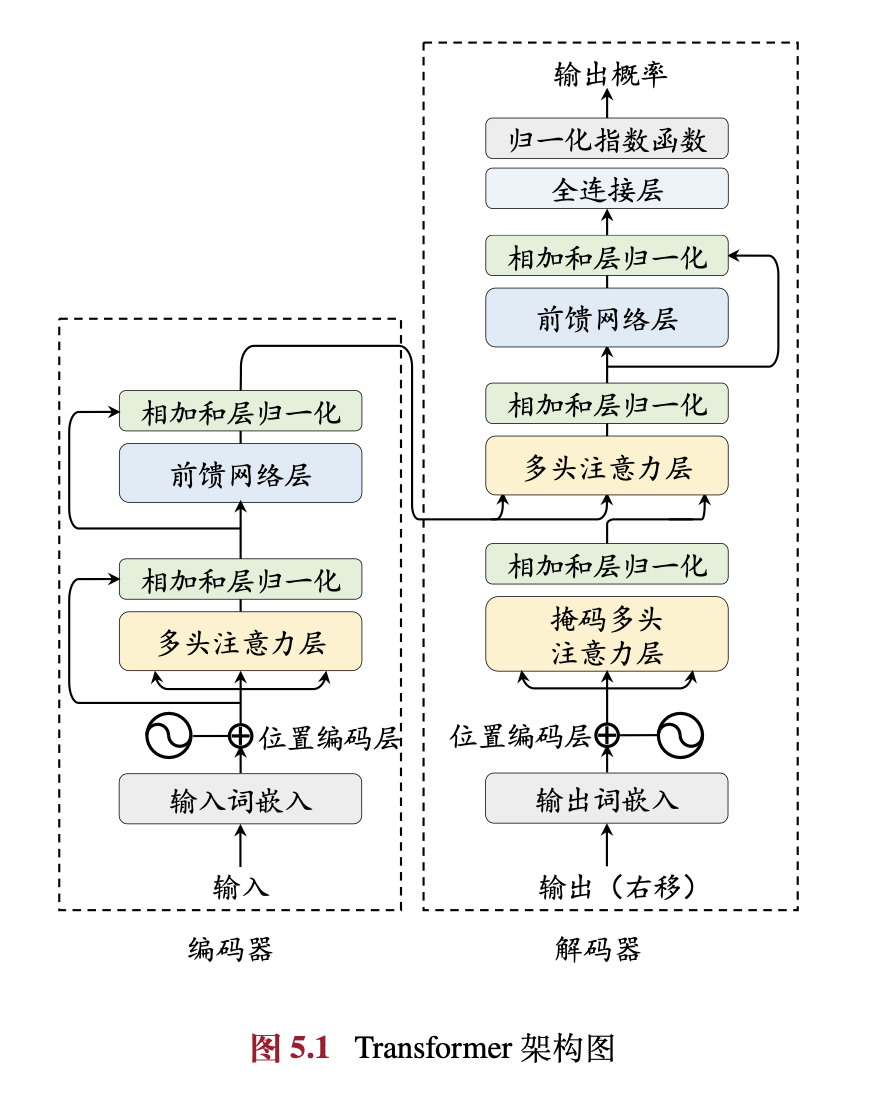
模型结构
transform模型结构由以下几个部分组成:
- 左边的解码部分:由多个encoder结构堆叠而成,输入src emb 和 position emb的和,输出编码后结果memory
- 右边的编码部分:由多个decoder结构堆叠而成,输入tgt emb 和 position emb的和以及编码结果memory,,输出编码后的结果
- ffn + softmax:把解码后的最后一个位置的结果映射成next token的预估概率


class Transform(nn.Module): def __init__(self, encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N): super(Transform, self).__init__() self.encoders = nn.ModuleList([copy.deepcopy(encoder) for _ in range(N)]) self.decoders = nn.ModuleList([copy.deepcopy(decoder) for _ in range(N)]) self.proj = nn.Linear(d_model, tgt_vocab) # 线性投影层,将 d_model 维度的向量映射到词汇表大小的维度 self.src_embed = src_embed self.tgt_embed = tgt_embed self.d_model = d_model self.max_len=5000 # 编码最大长度 pe = torch.zeros(self.max_len, d_model) # 初始化位置编码矩阵 position = torch.arange(0, self.max_len).unsqueeze(1) # 位置索引 div_term = torch.exp( torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) # 计算频率 ) pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数编码 pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数编码 pe = pe.unsqueeze(0) # 增加一个维度,用于批次处理 self.register_buffer("pe", pe) # 将位置编码矩阵注册为缓冲区,不参与模型的训练 def positional_encoding(self, x): return x + self.pe[:, : x.size(1)].requires_grad_(False) def encode(self, src): x = self.positional_encoding(self.src_embed(src)) for encoder in self.encoders: x = encoder(x) return x def decode(self, memory, tgt, mask): x = self.positional_encoding(self.tgt_embed(tgt)) for decoder in self.decoders: x = decoder(x, memory, mask) return x def generator(self, x): return log_softmax(self.proj(x), dim=-1) def forward(self, src, tgt, mask): x = self.positional_encoding(self.src_embed(src)) for encoder in self.encoders: x = encoder(x) memory = x x = self.positional_encoding(self.tgt_embed(tgt)) for decoder in self.decoders: x = decoder(x, memory, mask) return self.generator(x)
编码器
encoder输入:token embedding和position embedding求和,shape(batch,suqence len,input_dim)
encoder输出:编码后的embedding,shape(batch,suqence len, input_dim)
主要由以下几个部分组成:
- multi_self_attention(src, src, src):捕捉输入token之间的依赖关系
- add & norm:残差结构减少梯度消失,并采用LayerNorm归一化,提高训练稳定性
- FFN:前馈神经网络先对emb升维再降维,捕捉emb内的依赖关系,完成特征交互,提高模型表达能力
class Encoder(nn.Module): def __init__(self, d_model, d_ff, multi_attn): super(Encoder, self).__init__() self.multi_attn = multi_attn self.layer_norm = nn.ModuleList([LayerNorm(d_model) for _ in range(2)]) self.ffn = nn.Sequential( nn.Linear(d_model, d_ff), nn.ReLU(), nn.Linear(d_ff, d_model) ) def forward(self, x): x1 = self.multi_attn(x, x, x) x2 = self.layer_norm[0](x + x1) x3 = self.ffn(x2) x4 = self.layer_norm[1](x2 + x3) return x4
解码器
主要由以下几个部分组成:
- masked_multi_self_attention(tgt, tgt, tgt, mask):捕捉输入tgt token之间的依赖关系,对当前预估及之后的token做了mask,防止信息泄漏,得到tgt_memory
- cross_multi_self_attention(tgt_memory, memory, memory):用输入tgt token交互表示后的结果从encoder编码后的结果中解码出预估结果
- add & norm:残差结构减少梯度消失,并采用LayerNorm归一化,提高训练稳定性
- FFN:前馈神经网络先对emb升维再降维,捕捉emb内的依赖关系,完成特征交互,提高模型表达能力
class Decoder(nn.Module): def __init__(self, d_model, d_ff, multi_attn): super(Decoder, self).__init__() self.mask_multi_attn = copy.deepcopy(multi_attn) self.cross_multi_attn = copy.deepcopy(multi_attn) self.ffn = nn.Sequential( nn.Linear(d_model, d_ff), nn.ReLU(), nn.Linear(d_ff, d_model) ) self.layer_norm = nn.ModuleList([LayerNorm(d_model) for _ in range(3)]) def forward(self, x, memory, mask): x1 = self.mask_multi_attn(x, x, x, mask) x2 = self.layer_norm[0](x + x1) x3 = self.cross_multi_attn(x2, memory, memory) x4 = self.layer_norm[1](x2 + x3) x5 = self.ffn(x4) x6 = self.layer_norm[2](x4 + x5) return x6
模型训练
def train_test(d_model=32, d_ff=64, h=8, src_vocab=11, tgt_vocab=11, N=2): encoder = Encoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) decoder = Decoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) src_embed = Embeddings(d_model, src_vocab) tgt_embed = Embeddings(d_model, tgt_vocab) model = Transform(encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N) model.train() # 将模型设置为训练模式 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) data_iter = data_gen(11, 3, 10) for i, batch in enumerate(data_iter): optimizer.zero_grad() # 梯度清零 outputs = model.forward(batch.src, batch.tgt, batch.tgt_mask) # 前向传播 loss = criterion(outputs.contiguous().view(-1, outputs.size(-1)), batch.tgt_y.contiguous().view(-1)) # 计算损失 print('loss: ', loss) loss.backward() # 反向传播 optimizer.step() # 更新参数
模型预估
def inference_test(d_model=32, d_ff=64, h=8, src_vocab=11, tgt_vocab=11, N=2): encoder = Encoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) decoder = Decoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) src_embed = Embeddings(d_model, src_vocab) tgt_embed = Embeddings(d_model, tgt_vocab) test_model = Transform(encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N) test_model.eval() # 将模型设置为评估模式 src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]) # 测试数据 memory = test_model.encode(src) print('memory shape: ', memory.shape) tgt = torch.zeros(1, 1).type_as(src) # 逐步生成目标序列 for i in range(9): out = test_model.decode( memory, tgt, subsequent_mask(tgt.size(1)).type_as(src.data) ) print('out shape: ', out.shape) prob = test_model.generator(out[:, -1]) # 根据最后一个位置的embedding生成下一个词的概率分布 # print('prob: ', prob) _, next_word = torch.max(prob, dim=1) # 选择概率最大的词的索引 next_word = next_word.data[0] # print('next_word: ', next_word) # 将生成的词添加到目标序列中 tgt = torch.cat( [tgt, torch.tensor([[next_word]], dtype=torch.long)], dim=1 ) print("Example Untrained Model Prediction:", tgt)
完整代码
import os from os.path import exists import torch import torch.nn as nn from torch.nn.functional import log_softmax, pad import math import copy import time from torch.optim.lr_scheduler import LambdaLR import pandas as pd import altair as alt from torch.utils.data import DataLoader class Transform(nn.Module): def __init__(self, encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N): super(Transform, self).__init__() self.encoders = nn.ModuleList([copy.deepcopy(encoder) for _ in range(N)]) self.decoders = nn.ModuleList([copy.deepcopy(decoder) for _ in range(N)]) self.proj = nn.Linear(d_model, tgt_vocab) # 线性投影层,将 d_model 维度的向量映射到词汇表大小的维度 self.src_embed = src_embed self.tgt_embed = tgt_embed self.d_model = d_model self.max_len=5000 # 编码最大长度 pe = torch.zeros(self.max_len, d_model) # 初始化位置编码矩阵 position = torch.arange(0, self.max_len).unsqueeze(1) # 位置索引 div_term = torch.exp( torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) # 计算频率 ) pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数编码 pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数编码 pe = pe.unsqueeze(0) # 增加一个维度,用于批次处理 self.register_buffer("pe", pe) # 将位置编码矩阵注册为缓冲区,不参与模型的训练 def positional_encoding(self, x): return x + self.pe[:, : x.size(1)].requires_grad_(False) def encode(self, src): x = self.positional_encoding(self.src_embed(src)) for encoder in self.encoders: x = encoder(x) return x def decode(self, memory, tgt, mask): x = self.positional_encoding(self.tgt_embed(tgt)) for decoder in self.decoders: x = decoder(x, memory, mask) return x def generator(self, x): return log_softmax(self.proj(x), dim=-1) def forward(self, src, tgt, mask): x = self.positional_encoding(self.src_embed(src)) for encoder in self.encoders: x = encoder(x) memory = x x = self.positional_encoding(self.tgt_embed(tgt)) for decoder in self.decoders: x = decoder(x, memory, mask) return self.generator(x) class Encoder(nn.Module): def __init__(self, d_model, d_ff, multi_attn): super(Encoder, self).__init__() self.multi_attn = multi_attn self.layer_norm = nn.ModuleList([LayerNorm(d_model) for _ in range(2)]) self.ffn = nn.Sequential( nn.Linear(d_model, d_ff), nn.ReLU(), nn.Linear(d_ff, d_model) ) def forward(self, x): x1 = self.multi_attn(x, x, x) x2 = self.layer_norm[0](x + x1) x3 = self.ffn(x2) x4 = self.layer_norm[1](x2 + x3) return x4 class Decoder(nn.Module): def __init__(self, d_model, d_ff, multi_attn): super(Decoder, self).__init__() self.mask_multi_attn = copy.deepcopy(multi_attn) self.cross_multi_attn = copy.deepcopy(multi_attn) self.ffn = nn.Sequential( nn.Linear(d_model, d_ff), nn.ReLU(), nn.Linear(d_ff, d_model) ) self.layer_norm = nn.ModuleList([LayerNorm(d_model) for _ in range(3)]) def forward(self, x, memory, mask): x1 = self.mask_multi_attn(x, x, x, mask) x2 = self.layer_norm[0](x + x1) x3 = self.cross_multi_attn(x2, memory, memory) x4 = self.layer_norm[1](x2 + x3) x5 = self.ffn(x4) x6 = self.layer_norm[2](x4 + x5) return x6 class LayerNorm(nn.Module): def __init__(self, features, eps=1e-6): super(LayerNorm, self).__init__() self.a_2 = nn.Parameter(torch.ones(features)) self.b_2 = nn.Parameter(torch.zeros(features)) self.eps = eps def forward(self, x): mean = x.mean(-1, keepdim=True) std = x.std(-1, keepdim=True) return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 class MultiHeadedAttention(nn.Module): def __init__(self, h, d_model): super(MultiHeadedAttention, self).__init__() assert d_model % h == 0 self.d_k = d_model // h self.h = h self.linears = nn.ModuleList([copy.deepcopy(nn.Linear(d_model, d_model)) for _ in range(4)]) # 复制四个线性层,用于投影查询、键、值和输出 self.attn = None def attention(self, query, key, value, mask=None): d_k = query.size(-1) scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) # 如果有掩码,将掩码为 0 的位置的分数设为负无穷 p_attn = scores.softmax(dim=-1) return torch.matmul(p_attn, value), p_attn def forward(self, query, key, value, mask=None): if mask is not None: mask = mask.unsqueeze(1) nbatches = query.size(0) # 将查询、键、值分别通过线性层投影,并分割成多个头 query, key, value = [ lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for lin, x in zip(self.linears, (query, key, value)) ] # 计算注意力 x, self.attn = self.attention(query, key, value, mask=mask) # 将多头的输出拼接起来,并通过最后一个线性层 x = ( x.transpose(1, 2) .contiguous() .view(nbatches, -1, self.h * self.d_k) ) return self.linears[-1](x) class Embeddings(nn.Module): def __init__(self, d_model, vocab): super(Embeddings, self).__init__() # 嵌入层,将词汇表大小的索引映射到 d_model 维度的向量 self.lut = nn.Embedding(vocab, d_model) # 模型的维度 self.d_model = d_model def forward(self, x): # 将输入的词索引转换为词向量,并乘以 sqrt(d_model) 进行缩放 return self.lut(x) * math.sqrt(self.d_model) # 生成后续掩码的函数,用于防止解码器在预测时看到未来的信息 def subsequent_mask(size): # 掩码的形状 attn_shape = (1, size, size) # 生成上三角矩阵,对角线以上元素为 1,以下(包含对角线)为 0 subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type( torch.uint8 ) # 将上三角矩阵转换为布尔矩阵,对角线以上为 False,以下(包含对角线)为 True return subsequent_mask == 0 class Batch: """Object for holding a batch of data with mask during training.""" def __init__(self, src, tgt=None, pad=0): # pad: 序列不够长度的填充标志 self.src = src if tgt is not None: self.tgt = tgt[:, :-1] # 解码器输入(右移一位,第一位用 1 填充) self.tgt_y = tgt[:, 1:] # 解码器真实标签 self.tgt_mask = self.make_std_mask(self.tgt, pad) # 解码器掩码标签 self.ntokens = (self.tgt_y != pad).data.sum() @staticmethod def make_std_mask(tgt, pad): "Create a mask to hide padding and future words." tgt_mask = (tgt != pad).unsqueeze(-2) tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as( tgt_mask.data ) return tgt_mask def data_gen(V, batch_size, nbatches): "Generate random data for a src-tgt copy task." for i in range(nbatches): data = torch.randint(1, V, size=(batch_size, 10)) data[:, 0] = 1 src = data.requires_grad_(False).clone().detach() tgt = data.requires_grad_(False).clone().detach() yield Batch(src, tgt) def train_test(d_model=32, d_ff=64, h=8, src_vocab=11, tgt_vocab=11, N=2): encoder = Encoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) decoder = Decoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) src_embed = Embeddings(d_model, src_vocab) tgt_embed = Embeddings(d_model, tgt_vocab) model = Transform(encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N) model.train() # 将模型设置为训练模式 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) data_iter = data_gen(11, 3, 10) for i, batch in enumerate(data_iter): optimizer.zero_grad() # 梯度清零 outputs = model.forward(batch.src, batch.tgt, batch.tgt_mask) # 前向传播 loss = criterion(outputs.contiguous().view(-1, outputs.size(-1)), batch.tgt_y.contiguous().view(-1)) # 计算损失 print('loss: ', loss) loss.backward() # 反向传播 optimizer.step() # 更新参数 def inference_test(d_model=32, d_ff=64, h=8, src_vocab=11, tgt_vocab=11, N=2): encoder = Encoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) decoder = Decoder(d_model,d_ff,MultiHeadedAttention(h,d_model)) src_embed = Embeddings(d_model, src_vocab) tgt_embed = Embeddings(d_model, tgt_vocab) test_model = Transform(encoder, decoder, src_embed, tgt_embed, d_model, tgt_vocab, N) test_model.eval() # 将模型设置为评估模式 src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]) # 测试数据 memory = test_model.encode(src) print('memory shape: ', memory.shape) tgt = torch.zeros(1, 1).type_as(src) # 逐步生成目标序列 for i in range(9): out = test_model.decode( memory, tgt, subsequent_mask(tgt.size(1)).type_as(src.data) ) print('out shape: ', out.shape) prob = test_model.generator(out[:, -1]) # 根据最后一个位置的embedding生成下一个词的概率分布 # print('prob: ', prob) _, next_word = torch.max(prob, dim=1) # 选择概率最大的词的索引 next_word = next_word.data[0] # print('next_word: ', next_word) # 将生成的词添加到目标序列中 tgt = torch.cat( [tgt, torch.tensor([[next_word]], dtype=torch.long)], dim=1 ) print("Example Untrained Model Prediction:", tgt) train_test() inference_test()
CNN 和 self-attention区别?
共同点:CNN和self-attention都是一种加权求和的方式
差别:CNN只是简单对一个区域像素做归纳总结,而self-attention是用输入query去和其他embedding计算相似度,CNN和query无关,self-attention和query有关
多头attention的优点?
可以从多个维度(子空间)捕获信息,建模能力更强
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
\[ \text{Head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \]
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{Head}_1, \text{Head}_2, \cdots, \text{Head}_h)W^O \]
单头attention时间复杂度:O(n2d)
多头attention时间复杂度:O(n2d//h * h) = O(n2d)
单头attention和多头attention时间复杂度基本一样,多头attention多了拼接多头结果过非线性层
参考资料
详解Transformer (Attention Is All You Need)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号