

美团多场景多任务学习论文《HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction》阅读
背景
这是一篇美团到店多场景多任务建模的论文,我们直接来看模型结构
模型结构
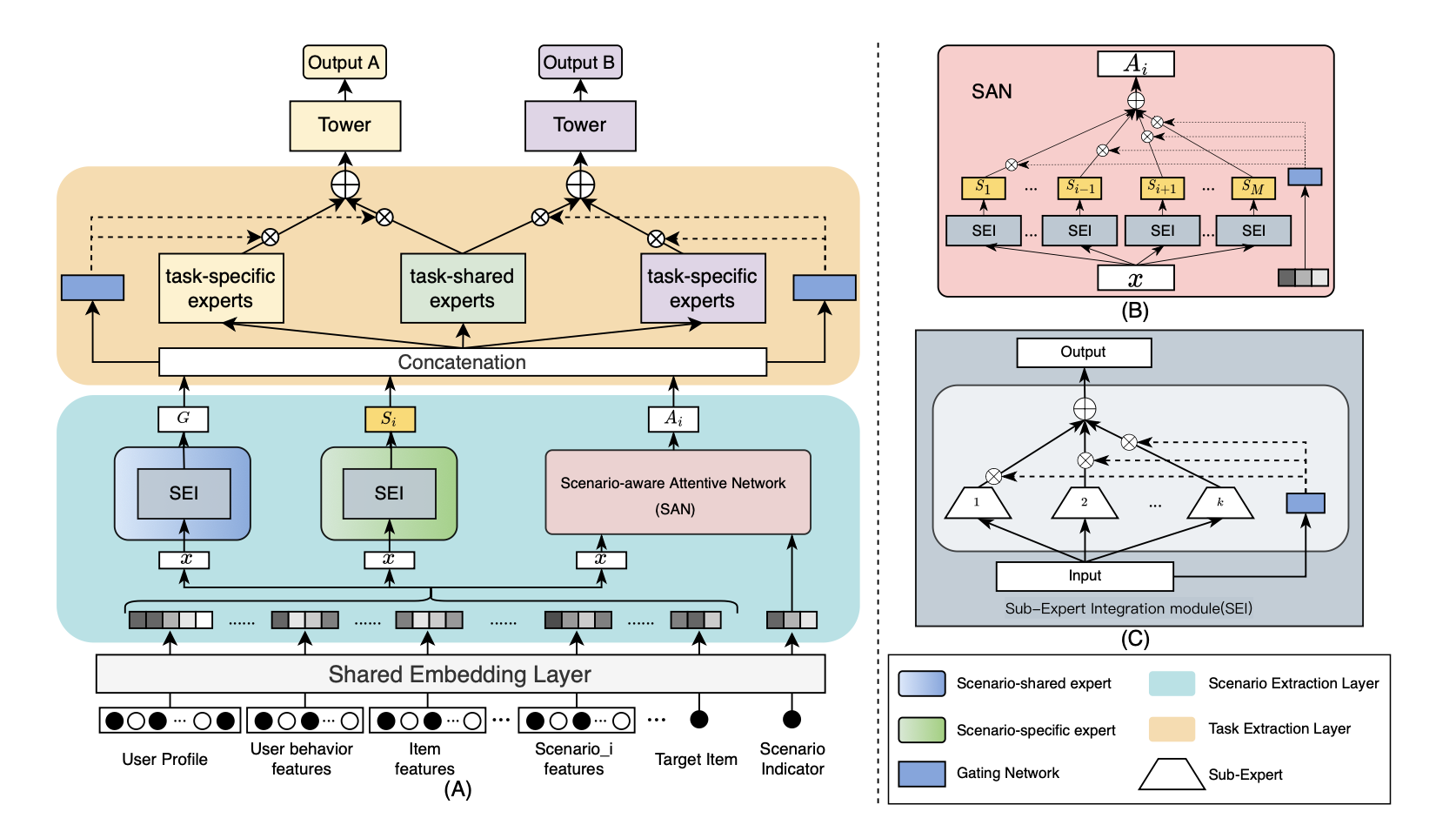
HiNet模型主要分上下两部分,下面浅蓝色区域的场景抽取层和上面黄色区域的任务抽取层
场景抽取层
场景抽取层主要由3个部分组成:
- 场景共享专家(Scenario-shared expert,图中绿色SEI)
- 当前场景特有专家(Scenario-specific expert,图中蓝色SEI)
- 场景感知注意力网络,通过这三部分的信息抽取,最终形成了场景层次的信息表征
场景共享专家
模型中包含一个场景共享专家学习所有场景的共享信息,场景共享专家的结构如上图(c),其实就是一个MMOE结构
具体来说,场景共享专家网络的最终输出为$G$,其公式为: \[ G = \sum_{k = 1}^{K_s} g_{sh}^k(x)Q_{sh}^k(x) \] 其中,$Q_{sh}^k$表示第$k$个子专家网络,该网络是由多层感知器(Multilayer perceptron, MLP)和激活函数组成,$K_s$表示子专家网络$Q_{sh}(\cdot)$的数量,$g_{sh}(x)$表示门控网络的输出,它是通过带有Softmax激活函数的简单线性变换得到: \[ g_{sh}(x) = softmax(W_{sh}x) \]
场景特有专家
除了使用场景共享专家网络提取不同场景间的共享信息,我们还为每个场景分别设计了场景特有专家网络来学习场景特有的信息,该网络也是由SEI模块组成。具体地,第$i$个场景的场景特有专家网络的输出$S_i$表示如下: \[ S_i = \sum_{k = 1}^{K_i} g_{sp}^k(x)Q_{sp}^k(x) \] 其中$Q_{sp}^k$表示第$k$个子专家网络,$K_i$是$Q_{sp}(\cdot)$的数量,$g_{sp}(x)$表示场景特有专家网络所对应的门控网络的输出。
场景感知注意力网络
不同场景之间存在一定程度的相关性,因此来自其他场景的信息也可以对当前场景的信息表征做出贡献,从而增强当前场景的信息表达能力。考虑到不同场景间对彼此的表征能力贡献不同,论文设计了场景感知注意力网络(Scenario-aware Attentive Network,SAN)来衡量其他场景信息对当前场景信息表征贡献的重要性,场景感知注意力网络的结构如上图B所示,计算方式如下所示:
\[ A_i = \sum_{m \neq i}^{M} g_a^i(s_i)S_m \] \[ g_a^i(s_i) = softmax(W_a^i Emb(s_i)) \]
其中Emb(si)表示第i个场景的指示向量,Sm表示其他场景的特有专家算出来的场景表示向量,场景感知注意力网络采用了attention结构计算了其他场景对这个场景的贡献
最终每个场景到任务抽取层的输入为:Ci = Concat(G, Si, Ai)
任务抽取层
就是一个CGC结构
问题讨论
1. 论文中每个SEI都是一个MMOE结构,SEI的数目是场景数+1,场景多了模型复杂度爆炸?个人理解不如阿里M2M模型在MMOE结构基础上融入场景信息来的简单高效
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号