

阿里pdn召回《Path-based Deep Network for Candidate Item Matching in Recommenders》
背景
目前最常见的召回可以分两类:
- 以item cf为代表的i2i召回
- 以双塔模型为代表的u2i召回
下面是这两种召回的优缺点:
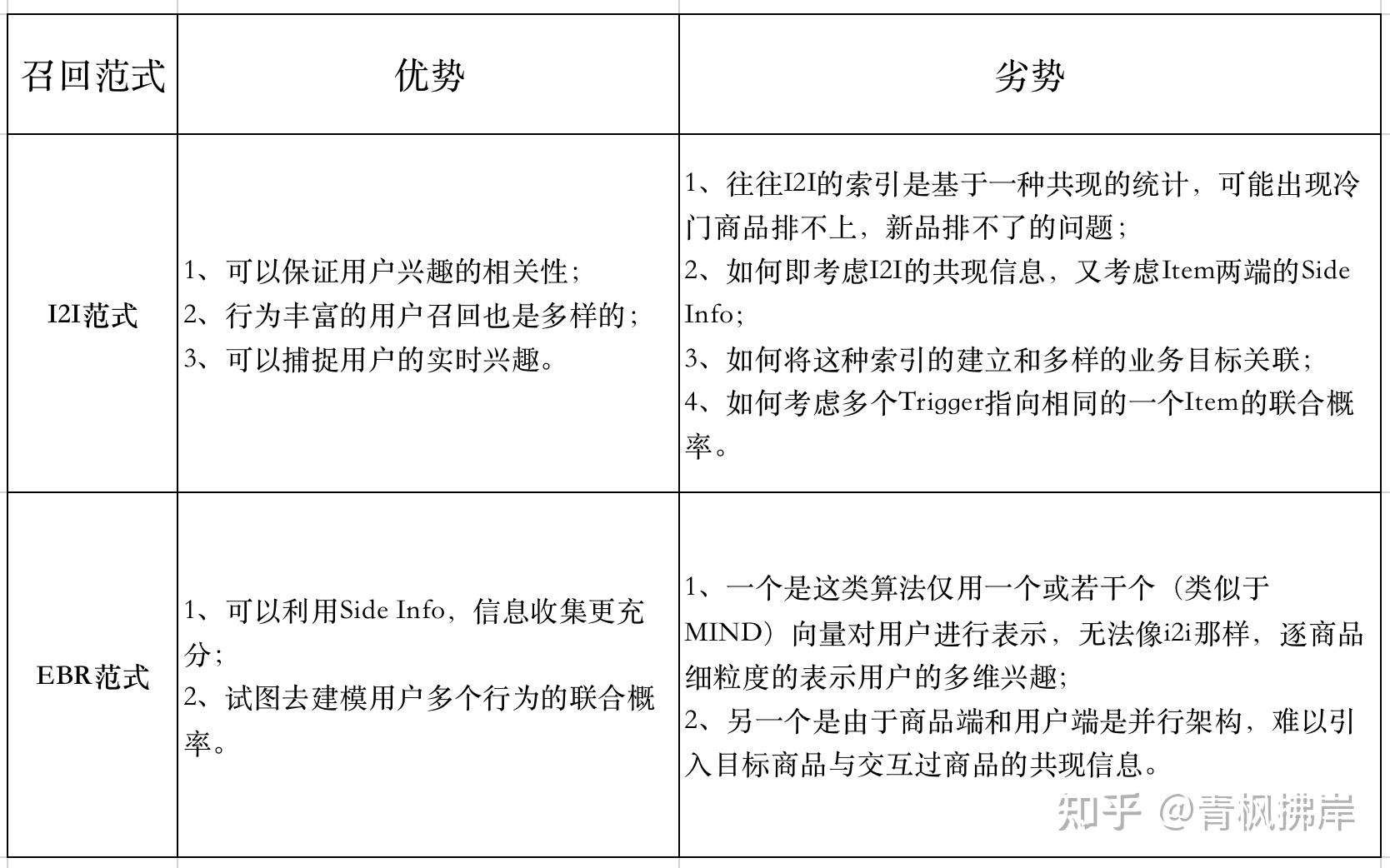
总结来说就是i2i不好加入side info信息,对物品冷启动不友好,u2i不好逐个行为粒度的表示用户兴趣,PDN算法正是结合两种方法的优点
方法

符号定义
- $x_i$:target item特征,包括item id, brand id, category id,月销售额等等;
- $z_u$:用户特征,包括年龄、性别、点击次数、每个类别的购买次数等等;
- $\{a_{uj_k}\}_{k = 1}^{n}$:用户交互过的item上的交互信息,包括停留时间、购买时间等;
- $\{x_{j_k}\}_{k = 1}^{n}$:与用户$u$交互过items的特征;
- $\{c_{j_ki}\}_{k = 1}^{n}$:交互items与target item之间的相关信息,从基于itemCF算法或基于项目共现模式的统计相关性度量中获得。
模型结构
PDN模型结构如上图所示,整体包含3个部分
- Dirct Net:就是一个普通u2i的双塔
- TrigNet&&SimNet:对用户序列中的每个item和target item、user进行建模(用户序列多长就有多少个这样的结构),捕捉用户行为粒度的兴趣
- Bias Net:Position Bias纠偏网络,只训练不serving
PDN模型可以用下式表示:
\[ \hat{y}_{ui} = \text{AGG}\left(f_d(z_u, x_i), \{\text{PATH}_{uji}\}\right) \text{ with } j \in N(u) \]
\[ \text{PATH}_{uji} = \text{MEG}(\text{TrigNet}(z_u, a_{uj}, x_j), \text{SimNet}(x_j, c_{ji}, x_i)) \]
也可以表示为:
\[ \hat{y}_{ui} = \mathbf{p}_u \mathbf{q}^T_i + \sum_{j \in N(u)} \text{MEG}(\text{TrigNet}(z_u, a_{uj}, x_j), \text{SimNet}(x_j, c_{ji}, x_i)) \]
下面详细介绍TrigNet&&SimNet的结构
TrigNet
TrigNet 可以看出用户行为粒度的U2I建模(可以表示用户的多兴趣),其计算方式可以用下式表示:
\[ t_{uj} = \text{TrigNet}(z_u, a_{uj}, x_j) = \text{MLP}\left(\text{CAT}(E(z_u), E(a_{uj}), E(x_j))\right) \]
Similarity Net
SimNet可以看作是带side info的i2i,SimNet的计算方式如下所示:
\[ s_{ji} = \text{SimNet}(x_j, c_{ji}, x_i) = \text{MLP}\left(\text{CAT}(E(x_j), E(c_{ji}), E(x_i))\right) \]
MEG
最后融合TrigNet和SimNet的计算结果,计算方式如下:
\[ \text{PATH}_{uji} = \text{MEG}(t_{uj}, s_{ji}) = \ln(1 + e^{t_{uj}} e^{s_{ji}}) \]
为了确保PDN收敛到更优的区域,在Trigger Net、Similarity Net的最后一层,我们利用exp()代替其他激活函数来约束输出为正,为什么不允许两个网络输出结果为负,文中给出了解释:
如果允许负权重的输出,导致PDN在更宽泛的参数空间中搜索局部最优值,这很容易导致过度拟合。由于在真实使用的时候,Similarity Net是用于生成Index,而Trigger Net是用于Trigger Selection。这种过拟合的后果可不是效果差一些,而很可能导致学习出来的索引不可用。
损失函数
用户是否会点击该商品可以被看作是二分类任务。因此,PDN融合了n+1条路径的权重以及偏差得分得到用户与商品的相关性得分,并将其转化为点击概率:
\[ \hat{y}_{u,i} = \text{softplus}(d_{u,i}) + \sum_{j = 1}^{n} \text{PATH}_{uji} + \text{softplus}(y_{\text{bias}}) \]
\[ p_{u,i} = 1 - \exp(-\hat{y}_{u,i}) \]
由于softplus的引入,导致$\hat{y}_{u,i} \in [0, +\infty]$,因此,我们利用1-exp()将预测值投影到0到1之间。我们采取交叉熵损失训练该模型:
最终采取交叉熵损失作为PDN的loss function:
\[ l_{u,i} = - (y_{u,i} \log(p_{u,i}) + (1 - y_{u,i}) \log(1 - p_{u,i})) \]
在线服务
在线检索的流程如下:
- Index generation (Step 1): 基于SimNet, 将每个商品K个相似商品及相似分数建立索引,由于商品池很大,我们需要压缩相似度矩阵$\mathrm{R}^{N \times N} \to \mathrm{R}^{N \times k}$,以保证离线的计算效率和存储资源。具体包含三个步骤:
- 步骤一,候选商品对枚举:我们主要基于两个策略生成候选pair对,一个是同一个Session中共现过的商品,另一个是基于商品的信息,例如同品牌/同店铺的商品。
- 步骤二,候选对排序:利用SimNet对每一个pair对进行打分。
- 步骤三,索引构建:对每个商品,基于simNet的得分按照某种规则进行排序截断,构造$N \times k$的索引表。
- Trigger extraction (Step 2): 当用户打开淘宝后, 基于TrigNet对用户历史交互行为进行打分, 取Top-m结果及相关得分
- Top-K retrieval (Step 3): 检索Top-m item在数据库中的I2I结果, 得到m * k个候选商品, 并按照下方公式进行最终打分。 \[ \hat{s}_{u,i} = \text{softplus}(d_{u,i}) + \sum_{j = 1}^{m} \text{softolus}(t_{uj} + s_{ji}) \]
总结
优点:对用户行为粒度进行I2I建模,能捕捉用户的多兴趣
缺点:
- 无法采用ANN检索的方式,资源消耗太大
- 构建topk相似索引的时候只对部分item进行了计算,效果有损
- 分了多阶段,不是端到端的实现
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号