

阿里序列建模论文DIEN
背景
DIN的成功在于采用了attention的方式根据不同的候选,动态的把注意力集中在和候选相关的行为中,但是DIN没有考虑用户行为之间的相关性,以及行为的先后顺序,物品行为的先后顺序常常表示了用户的兴趣的变化趋势。DIEN 通过引入GRU结构来捕捉用户行为之间的相关性以及用户兴趣的进化趋势。
方法
整体结构
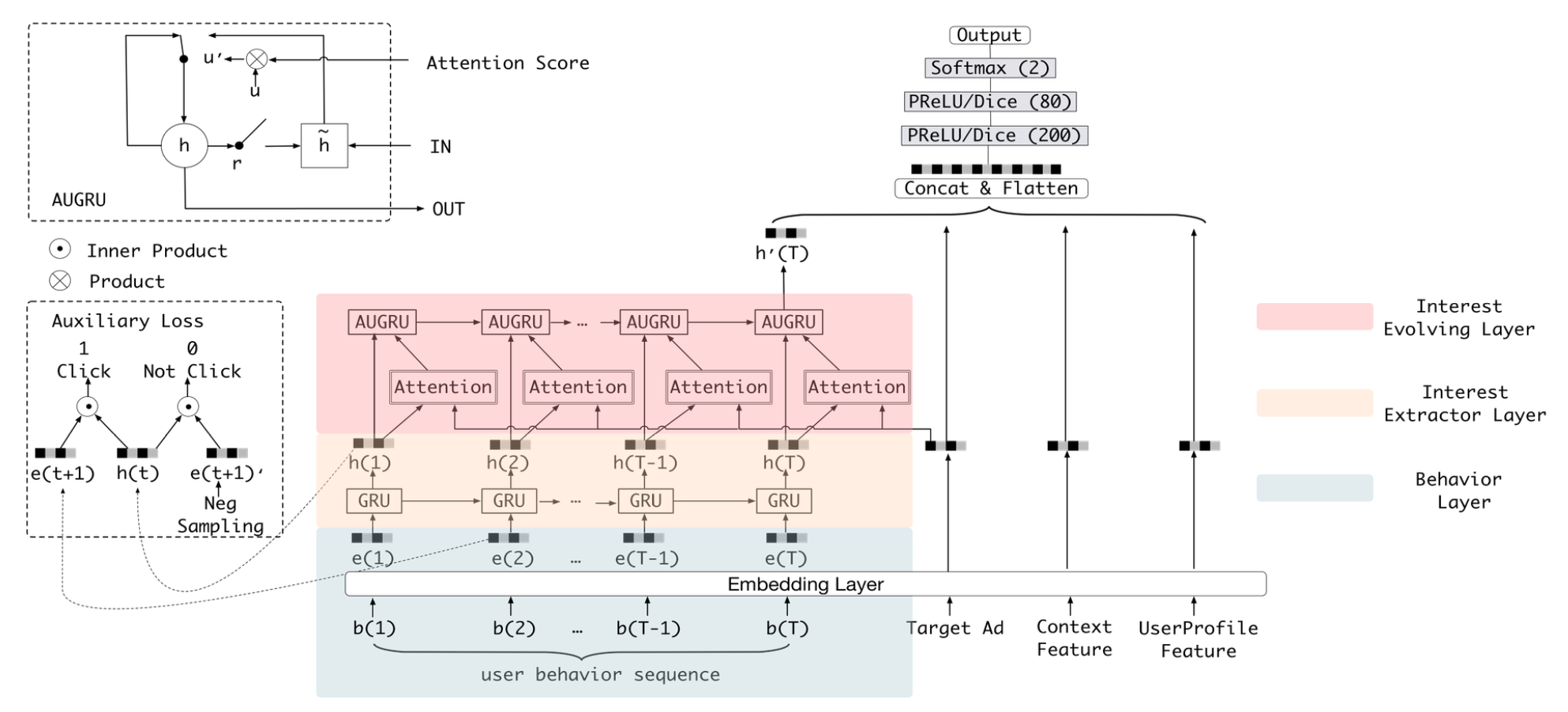
DIEN和常用模型的差异点在序列建模的部分,该部分结构由兴趣提取层和兴趣进化层两个部分组成:
- 兴趣提取层:从用户的行为序列中提取用户的兴趣序列
- 兴趣进化层:建模和target item相关的兴趣进化过程
兴趣提取层
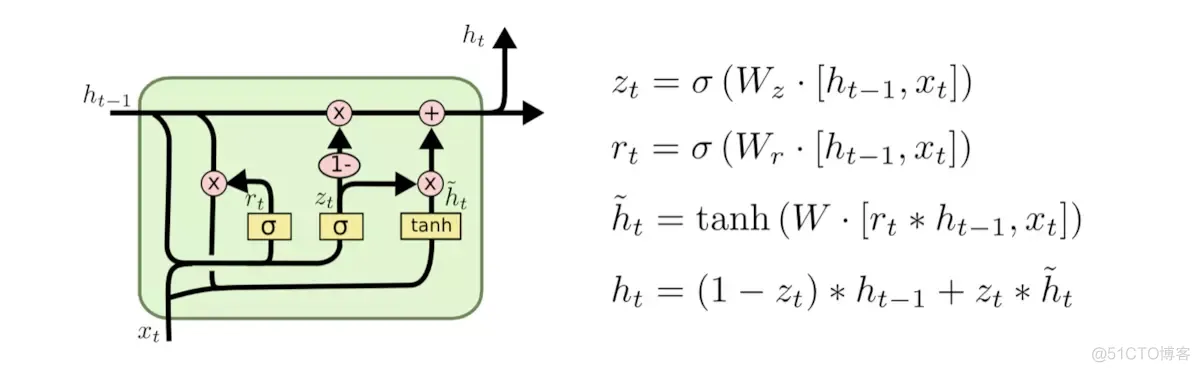
兴趣提取层的基本结构是GRU(Gated Recurrent Unit)网络,如入上图黄色区域所示,即用GRU来对用户行为之间的依赖性进行建模,选用GRU的原因是因为相比传统的序列模型RNN和LSTM,GRU缓解了RNN的梯度消失问题;与LSTM相比,GRU的参数更少,训练收敛速度更快。下图是GRU的结构
兴趣提取层的输入是用户按时间排序的行为序列,建模过程可以用如下公式表示:
\[ \begin{align*} \mathbf{u}_t &= \sigma(\mathbf{W}^u \mathbf{i}_t + \mathbf{U}^u \mathbf{h}_{t - 1} + \mathbf{b}^u),\\ \mathbf{r}_t &= \sigma(\mathbf{W}^r \mathbf{i}_t + \mathbf{U}^r \mathbf{h}_{t - 1} + \mathbf{b}^r),\\ \tilde{\mathbf{h}}_t &= \tanh(\mathbf{W}^h \mathbf{i}_t + \mathbf{r}_t \circ \mathbf{U}^h \mathbf{h}_{t - 1} + \mathbf{b}^h),\\ \mathbf{h}_t &= (1 - \mathbf{u}_t) \circ \mathbf{h}_{t - 1} + \mathbf{u}_t \circ \tilde{\mathbf{h}}_t, \end{align*} \]
其中,$\sigma$ 是sigmoid激活函数,$\circ$ 是逐元素乘积,$\mathbf{W}^u, \mathbf{W}^r, \mathbf{W}^h \in \mathbb{R}^{n_H \times n_I}$,$\mathbf{U}^z, \mathbf{U}^r, \mathbf{U}^h \in \mathbb{R}^{n_H \times n_H}$ ,$n_H$ 是隐藏层大小,$n_I$ 是输入大小。$\mathbf{i}_t$ 是门控循环单元(GRU)的输入,$\mathbf{i}_t = \mathbf{e}_b[t]$ 表示用户在第 $t$ 步的行为,$\mathbf{h}_t$ 是第 $t$ 步的隐藏状态。
辅助loss
为了使GRU能更好的建模用户的兴趣依赖关系,DIEN引入一个辅助损失,具体来讲,就是利用 t 时刻的行为 b(t+1) 作为监督去学习隐含层向量 ht ,负样本是从用户未交互过的商品中随机抽取。辅助loss可以用如下公式表示:
\[ L_{aux} = -\frac{1}{N}(\sum_{i = 1}^{N} \sum_{t} \log \sigma(\mathbf{h}_t^i, \mathbf{e}_b^i[t + 1]) + \log(1 - \sigma(\mathbf{h}_t^i, \hat{\mathbf{e}}_b^i[t + 1]))) \]
最终的损失有ctr损失和辅助损失加权和得到:
\[ L = L_{target} + \alpha * L_{aux}, \]
引入Auxiliary Loss的优势有:
- 帮助GRU的隐状态更好地表示用户兴趣
- 降低优化难度
- 更好的学习embedding
兴趣进化层
兴趣进化层的主要目标是刻画用户兴趣的进化过程,用户兴趣是不断变化的:
- 用户在某一段时间的喜好具有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服
- 每种兴趣都有自己的演变趋势,不同种类的兴趣之间很少相互影响,例如买书和买衣服的兴趣基本互不相关
用户这种变化会直接影响用户的点击决策。建模用户兴趣的进化过程有两方面的好处:
- 兴趣演化模块可以为最终兴趣的表示提供更多的相关历史信息;
- 可以根据interest的变化趋势更好地进行CTR预测
用户兴趣的演化具有如下规律:
- Interest Drift:由于兴趣的多样性,兴趣可能会漂移。用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。
- Interest Individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。我们只关注与目标物品相关的演化过程。
基于以上分析,DIEN结合了注意力机制的局部激活能力和GRU的序列学习能力来对兴趣演化进行建模,attention的计算如下所示:
\[ a_t = \frac{\exp(\mathbf{h}_t \mathbf{W} \mathbf{e}_a)}{\sum_{j = 1}^{T} \exp(\mathbf{h}_j \mathbf{W} \mathbf{e}_a)}, \]
其中,$\mathbf{e}_a$ 是广告属性embedding的拼接,$\mathbf{W} \in \mathbb{R}^{n_H \times n_A}$ ,$n_H$ 是隐藏状态的维度,$n_A$ 是广告嵌入向量的维度。注意力得分能够反映广告 $\mathbf{e}_a$ 与输入 $\mathbf{h}_t$ 之间的关系,相关性越强,注意力得分越高。
如何将attention机制加到GRU中呢?文中尝试了3种方法:
1. GRU with attentional input (AIGRU)
直接把attention分数和兴趣提取层输出的隐藏单元相乘,然后输入到GRU中:
\[ \mathbf{i}'_t = \mathbf{h}_t * a_t \]
即通过attention来减少输入GRU中和target item不相关的item的影响,加强和target item相关的item的影响
2. Attention based GRU(AGRU)
用attention分数替换GRU的更新门:
\[ \mathbf{h}'_t = (1 - a_t) * \mathbf{h}'_{t - 1} + a_t * \tilde{\mathbf{h}}'_t, \]
其中,$\mathbf{h}'_t$、$\mathbf{h}'_{t - 1}$ 和 $\tilde{\mathbf{h}}'_t$ 是注意力门控循环单元(AGRU)的隐藏状态。
AGRU利用注意力得分直接控制隐藏状态的更新,削弱了兴趣演变过程中较少相关兴趣的影响。
3. GRU with attentional update gate (AUGRU)
在GRU的更新门中加入注意力分数:
\[ \begin{align} \tilde{\mathbf{u}}'_t &= a_t * \mathbf{u}'_t, \\ \mathbf{h}'_t &= (1 - \tilde{\mathbf{u}}'_t) \circ \mathbf{h}'_{t - 1} + \tilde{\mathbf{u}}'_t \circ \tilde{\mathbf{h}}'_t, \end{align} \]
其中,$\mathbf{u}'_t$ 是注意力更新门控循环单元(AUGRU)原本的更新门,$\tilde{\mathbf{u}}'_t$ 是我们为AUGRU设计的注意力更新门,$\mathbf{h}'_t$、$\mathbf{h}'_{t - 1}$ 和 $\tilde{\mathbf{h}}'_t$ 是AUGRU的隐藏状态。
在AUGRU中,保留更新门的原始尺寸信息,通过注意力分数来缩放更新门的所有维度,从而导致相关度较小的兴趣对隐藏状态的影响也较小。AUGRU可以更有效地避免兴趣漂移带来的干扰,并推动相对兴趣平稳发展。
作者通过实践发现AUGRU的效果最好
参考资料
论文标题: Deep Interest Evolution Network for Click-Through Rate Prediction
论文地址: https://arxiv.org/pdf/1809.03672.pdf
代码地址: https://github.com/mouna99/dien
https://blog.51cto.com/u_15179348/3242662

 浙公网安备 33010602011771号
浙公网安备 33010602011771号