

一阶优化方法比较


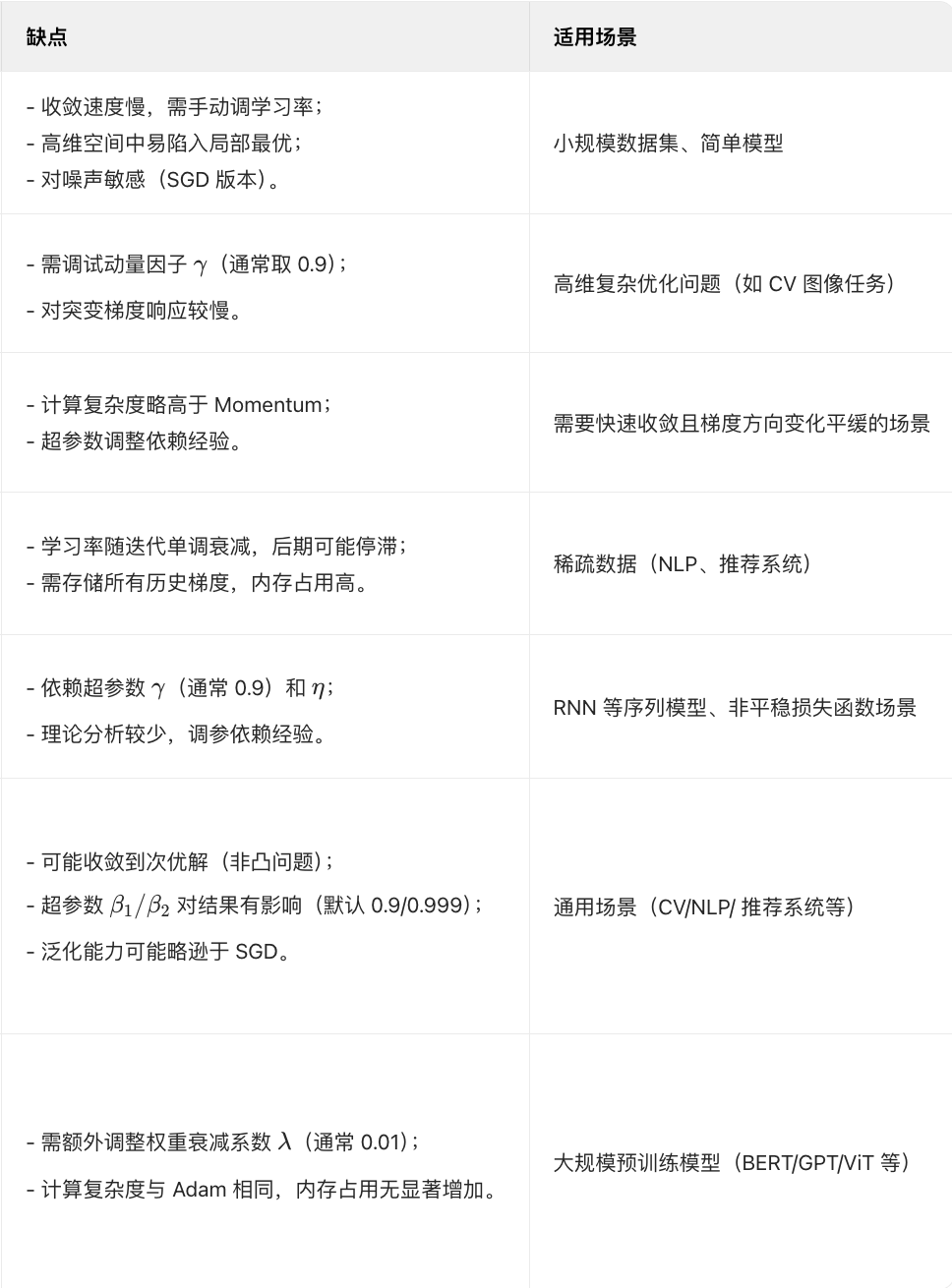
SGD
权重更新公式
\[W \leftarrow W - \eta \frac{{\partial L}}{W}\]

SGD的缺点
- 学习率的设置非常需要技巧,学习率设置的过大,容易跳过最优点,学习率设的过小,又容易困于局部最优或鞍点,所以一般要设置一个随着训练批次衰减的学习率
- 所有特征的学习率都一样,那对于稀疏特征,更新的可能会非常少
由于SGD不同的参数都用了相同的学习率,在许多情况SGD的梯度都没有指向最小值方向,使SGD的学习变得低效,SGD想要很好的收敛需要在调节学习率上下很大的功夫。。

python代码
class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key]
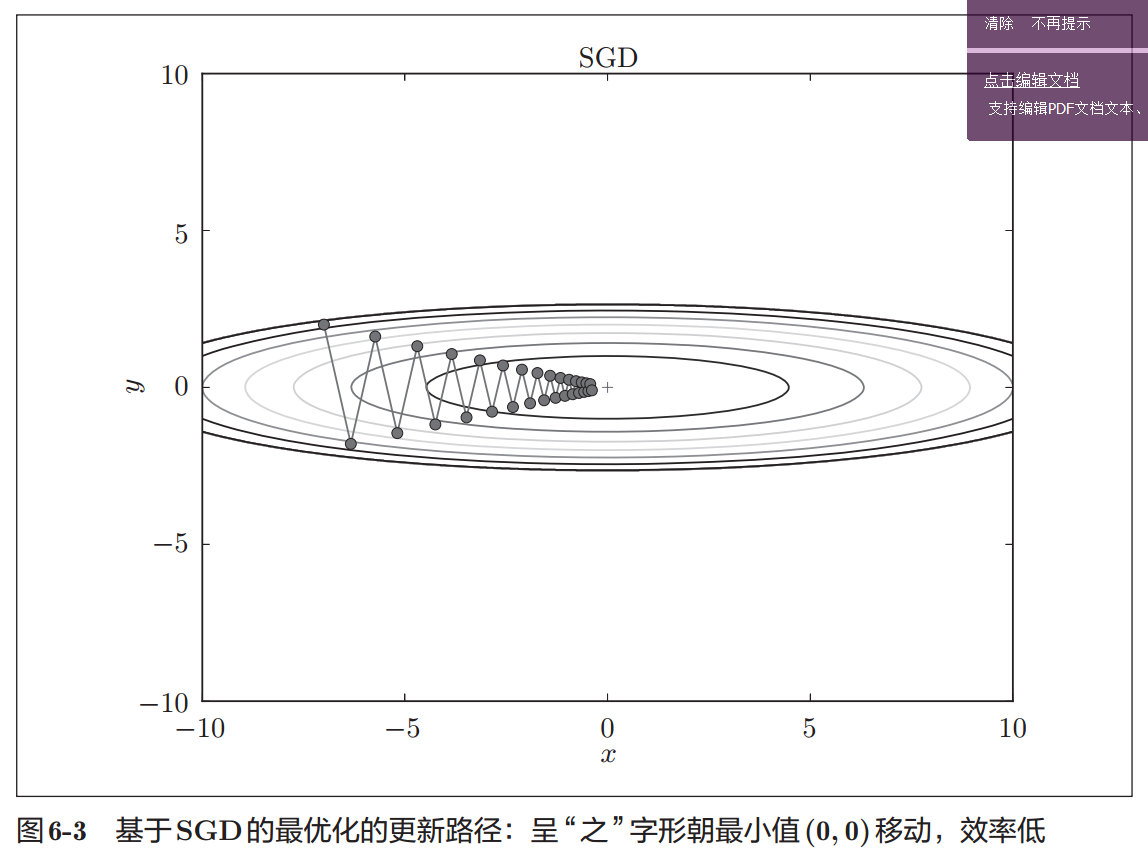
Momentum
权重更新公式

或:
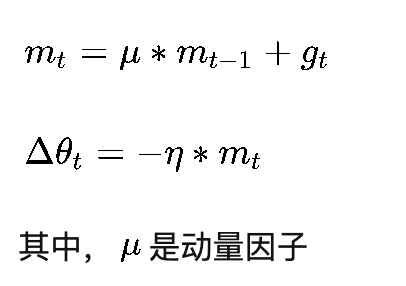
优点
在下降初期,由于这个时候的梯度方向是一致的,梯度的累加和可以让其更快速的收敛到最优值附近,当到达最优值附近之后,由于最优值左右的梯度方向是相反的,累计梯度会互相抵消,减少在最优值附近的震荡。
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。更新路径就像小球在碗中滚动一样。和SGD相比,我们发现“之”字形的“程度”减轻了。这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。

tensorflow中的类
class tf.train.MomentumOptimizer
Optimizer that implements the Momentum algorithm.
tf.train.MomentumOptimizer.__init__(learning_rate, momentum, use_locking=False, name=’Momentum’, use_nesterov=False)
Construct a new Momentum optimizer.
Args:
learning_rate: A Tensor or a floating point value. The learning rate.
momentum: A Tensor or a floating point value. The momentum.
use_locking: If True use locks for update operations.
name: Optional name prefix for the operations created when applying gradients. Defaults to “Momentum”.
python代码实现
class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum * self.v[key] - self.lr * grads[key] params[key] += self.v[key]
Nesterov
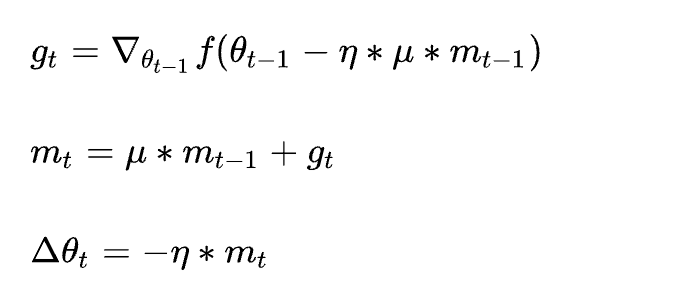
nesterov和前面momentum唯一的区别就是nesterov加的是累计动量会到达的位置的梯度,相当于提前看到了未来位置的梯度,这样,如果未来位置梯度和现在的累计梯度位置相反,那么很可能已经到最优点了,会减少学习率,减少震荡;如果相同,就可以增大学习率,加快收敛。
AdaGrad
权重更新公式


优点
- 对每个权重的特征的学习率都除了该权重下的累计梯度平方和的开放,对于学习率比较小的权重(如比较稀疏的特征)能获得更大的学习率,适用于稀疏特征。
- 在训练初期,梯度累加和比较小,可以获得更快的更新
缺点
- 初始化W影响初始化梯度,初始化W过大,会导致初始梯度被惩罚得很小
- 训练到中后期,递推路径上累加的梯度平方和越打越多,迅速使得梯度被惩罚逼近0,提前结束训练
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。在关于学习率的有效技巧中,有一种被称为学习率衰减(learning ratedecay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。而AdaGrad进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。AdaGrad会为参数的每个元素适当地调整学习率 。

tensorflow中的类
class tf.train.AdagradOptimizer
Optimizer that implements the Adagrad algorithm.
See this paper.
tf.train.AdagradOptimizer.__init__(learning_rate, initial_accumulator_value=0.1, use_locking=False, name=’Adagrad’)
Construct a new Adagrad optimizer.
Args:
learning_rate: A Tensor or a floating point value. The learning rate.
initial_accumulator_value: A floating point value. Starting value for the accumulators, must be positive.
use_locking: If True use locks for update operations.
name: Optional name prefix for the operations created when applying gradients. Defaults to "Adagrad".
python代码
class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
RMSProp
AdaGrad的一个限制是,它可能会在搜索结束时导致每个参数的步长(学习率)非常小,这可能会大大减慢搜索进度,并且可能意味着无法找到最优值。RMSProp和Adadelta都是在同一时间独立开发的,可认为是AdaGrad的扩展,都是为了解决AdaGrad急剧下降的学习率问题。
RMSProp采用了指数加权移动平均来累计梯度平方和, RMSProp比AdaGrad只多了一个超参数,其作用类似于动量(momentum),其值通常置为0.9
https://arxiv.org/pdf/1609.04747.pdf
RMSPropV2
AdaDelta

![]()
优点
- 分子作为一个加速项,作为动量在时间窗口w ww上积累先前的梯度
- 分母可以起到不同参数调整不同学习率的作为,而且用均值代替求和,可以防止更新梯度快速收敛到0
https://blog.csdn.net/XiangJiaoJun_/article/details/83960136
Adam
权重更新公式



优点:
1. 模型收敛速度非常快,且自带权重衰减
缺点:
在稀疏场景下的表现可能不如adagrad,可能是因为adam里的梯度更新的时候使用是关于当前参数历史梯度的一阶段矩估计的滑动平均与梯度二阶矩估计平方根的商。这导致了在稀疏任务场景下,每次batch更新的时候,除了batch里出现过的样本对应的参数,其他没有出现在batch.里的参数也都被更新了,很容易导致embedding参数过拟合。整个模型很快的收敛到了一个局部最优的状态,后面继续训练就很难获得效果的提升了。
LazyAdam适合处理稀疏数据下的参数更新。
https://wx.zsxq.com/dweb2/index/columns/48415285421248
tensorflow中的类
class tf.train.AdamOptimizer
实现了Adam算法的优化器
构造函数:
tf.train.AdamOptimizer.__init__(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name=’Adam’)
Construct a new Adam optimizer.
Initialization:
m_0 <- 0 (Initialize initial 1st moment vector)
v_0 <- 0 (Initialize initial 2nd moment vector)
t <- 0 (Initialize timestep)
The update rule for variable with gradient g uses an optimization described at the end of section2 of the paper:
t <- t + 1
lr_t <- learning_rate * sqrt(1 - beta2^t) / (1 - beta1^t)
m_t <- beta1 * m_{t-1} + (1 - beta1) * g
v_t <- beta2 * v_{t-1} + (1 - beta2) * g * g
variable <- variable - lr_t * m_t / (sqrt(v_t) + epsilon)
The default value of 1e-8 for epsilon might not be a good default in general. For example, when training an Inception network on ImageNet a current good choice is 1.0 or 0.1.
Note that in dense implement of this algorithm, m_t, v_t and variable will update even if g is zero, but in sparse implement, m_t, v_t and variable will not update in iterations g is zero.
Args:
learning_rate: A Tensor or a floating point value. The learning rate.
beta1: A float value or a constant float tensor. The exponential decay rate for the 1st moment estimates.
beta2: A float value or a constant float tensor. The exponential decay rate for the 2nd moment estimates.
epsilon: A small constant for numerical stability.
use_locking: If True use locks for update operations.
name: Optional name for the operations created when applying gradients. Defaults to “Adam”.
python代码实现
class Adam: """Adam (http://arxiv.org/abs/1412.6980v8)""" def __init__(self, lr=0.001, beta1=0.9, beta2=0.999): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.iter = 0 self.m = None self.v = None def update(self, params, grads): if self.m is None: self.m, self.v = {}, {} for key, val in params.items(): self.m[key] = np.zeros_like(val) self.v[key] = np.zeros_like(val) self.iter += 1 lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys(): #self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key] #self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2) self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key]) params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7) #unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias #unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias #params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
问题
1. 深度学习算法是怎么越过局部最优解,找到全局最优解的?
可以通过观察训练loss判断是不是陷入局部最优,如果陷入局部最优可以通过调大学习率来跳过局部最优点。
实际上,什么学习一般求解的都是高维空间中的解,在高维空间中,基本上都是鞍点,很少会有局部最优点
2. 深度学习为什么只用一阶优化算法,不用二阶优化算法?
主要是因为二阶优化方法时间复杂度太高了(一般为O(n^2))
https://www.zhihu.com/question/53218358
参考资料·:
https://zhuanlan.zhihu.com/p/22252270
https://zhuanlan.zhihu.com/p/32230623
https://blog.csdn.net/leadai/article/details/79178787
https://ruder.io/optimizing-gradient-descent/index.html#momentum

 浙公网安备 33010602011771号
浙公网安备 33010602011771号