


一、安装Spark
-
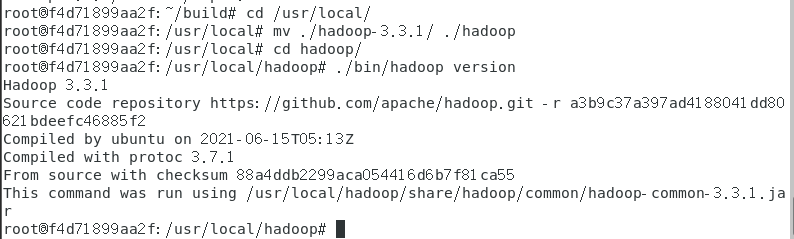
检查基础环境hadoop,jdk
查看 jdk 环境 ( java -version )

查看 hadoop环境 ( hadoop version )
2.下载spark

3.解压,文件夹重命名、权限
解压

重命名
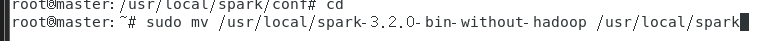
赋权(可以不用)

4. 配置 Spark 环境变量

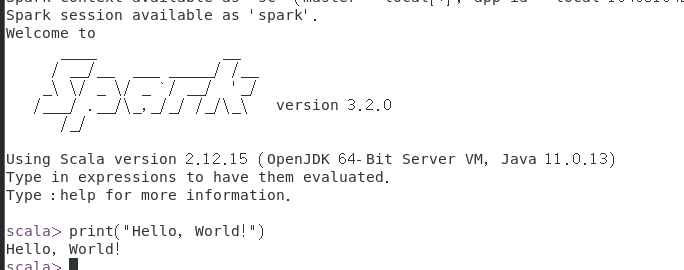
6. 试运行Python代码 ( 打印HelloWorld )
二、Python编程练习:英文文本的词频统计
-
准备文本文件

2.读文件
text = open("word.txt", "r").read()
3. 预处理:大小写,标点符号,停用词
# 将文本中的所有大写字母转换为小写字母( 大写也可 )
text = text.lower()
# 替换文本中的所有特殊符号为空格
for c in '!"#$%^&*()_+-=@[]{}|\?/<>,.:;~·`、“”‘’':
text = text.replace(c, " ")
4. 分词
# 将处理好的文本切分成列表
words = text.split()
5. 统计每个单词出现的次数
# 遍历列表,统计词出现的次数
for word in words:
count[word] = count.get(word, 0) + 1
6. 按词频大小排序
# 定义空字典
count = {}
# 遍历列表,统计词出现的次数
for word in words:
count[word] = count.get(word, 0) + 1
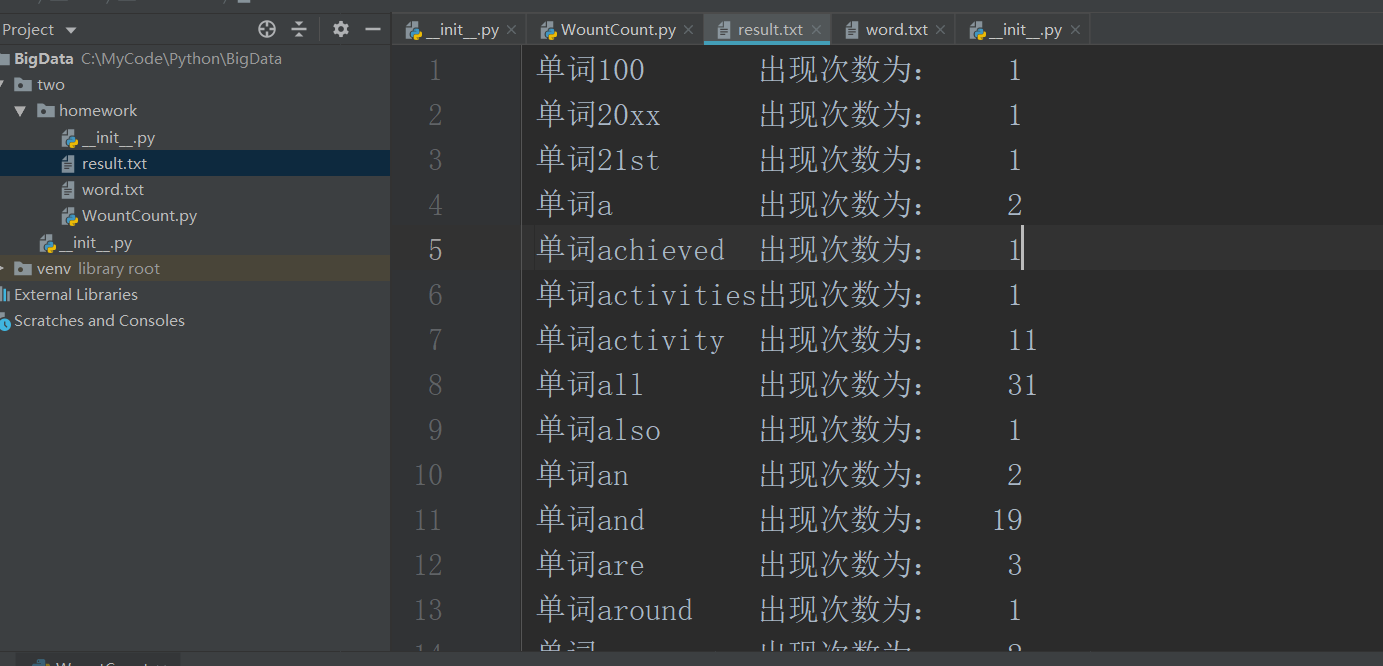
7. 结果写文件
file = open("result.txt", "w")
for i in range(len(items)):
# 从items[i]中一次返回单词和单词的词频
word, count = items[i]
str ="单词{0:<10}出现次数为:{1:>5}\n".format(word, count)
file.write(str)
最终结果
3. 使用Jupyter Notebook调试PySpark程序
1 安装Anaconda
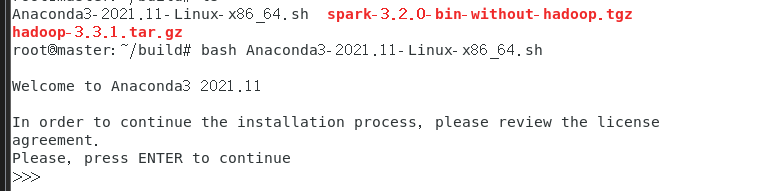
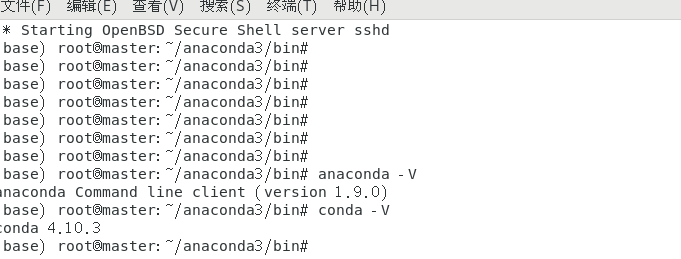
2. 查看Anaconda的版本信息
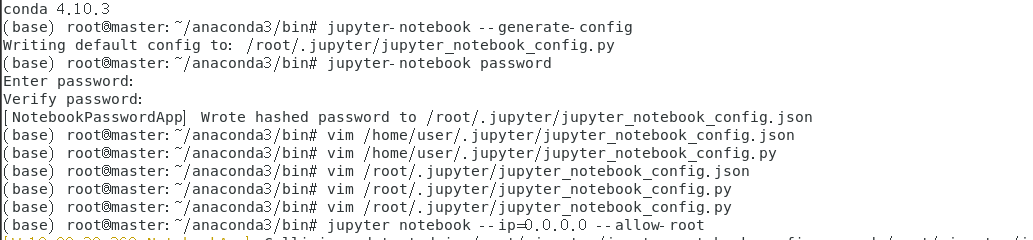
3. 配置Jupyter Notebook( 过程与 http://dblab.xmu.edu.cn/blog/2575-2/ 一样 )
4. 运行Jupyter Notebook
jupyter notebook --ip=0.0.0.0 --allow-root
打印HelloWorld
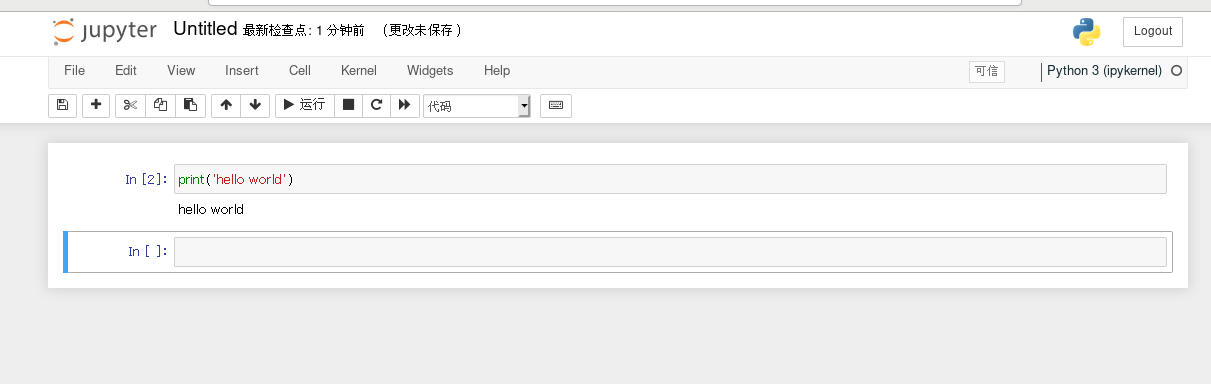
保存

4. 配置Jupyter Notebook实现和PySpark交互
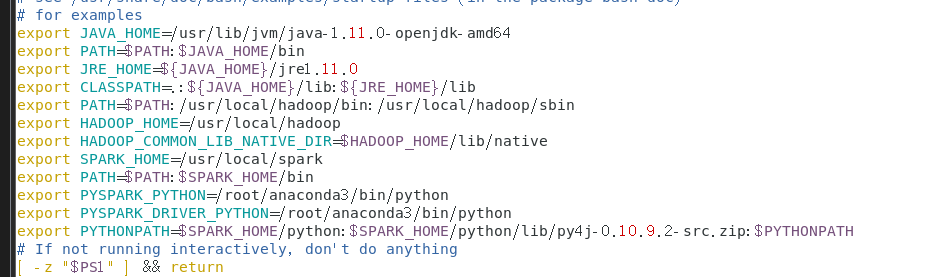
1. 配置环境变量
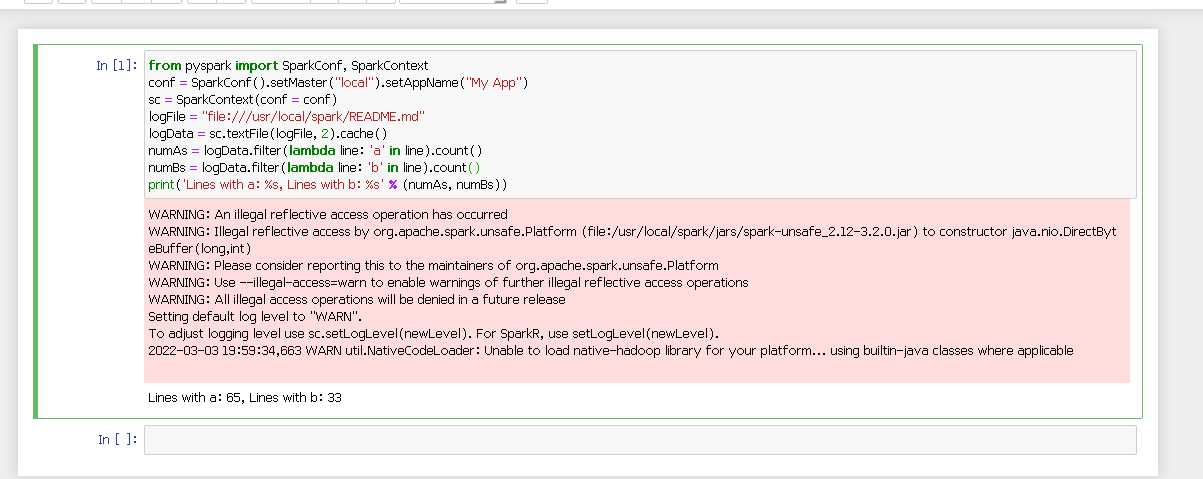
2. 运行程序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号