

Proj CJI Paper Reading: Fight Back Against Jailbreaking via Prompt Adversarial Tuning
Abstract
-
背景: adversarial training paradigm
-
Tool: Prompt Adversarial Tuning
-
Task: trains a prompt control attached to the user prompt as a guard prefix
-
Method: 交替update attack prompt control和defense prompt control来进行对抗性调优,使用GCG策略
- calculate the gradients of the one-hot token indicators to identify a set of potential replacement candidates at each token position. Q: 是我想象中的计算方法么?
- 用GPT问了半天也没有理解为何一定要one-hot而不是直接计算gradient
- the top-k negative gradients as promising token replacements for xi.We only generate B candidates in each round to ensure computational efficiency
- 每次随便抽取m个无害QA对来计算loss
-
Q: 使用有害和无害的prompts来优化prompt control
-
Experiment
- effective against both grey-box and black-box attacks, 使得攻击率接近0%
- 在普通任务上仍然维持了模型可用性
- Dataset:MT-bench, MMLU
- Competitors: PPL-based detection, ICD, SafeDecoding, SmoothLLM, Self-reminder, DRO
- Attacks
- Greybox: The parameter of the protected model is available for defenders
- attacks
- GCG
- AutoDAN
- In-Context Attack
- PAIR
- TAP
- models
- Vicuna-7B, Vicuna-13B
- attacks
- blackbox: 在代理模型上训练,然后直接应用到target models上
- models:
- GPT-3.5, GPT-4
- models:
- Greybox: The parameter of the protected model is available for defenders
-
Expeirment2: Defense against Human-crafted Attacks
- Attacks
- competing objectives (CO)
- Always Intelligent and Machiavellian attack (AIM), Prefix Injection attack (PI) and Refusal Suppression attack (RS).
- mismatched generalizations (MG).
- jailbreak prompts written in Base64 coding or Bengali (BN)
- competing objectives (CO)
- Attacks
-
Github: https://github.com/PKU-ML/PAT
3 The Proposed Prompt Adversarial Tuning
3.1 Threat Model and Notations
- Threat Model:强调了greybox robustness的重要性(指虽然模型是开源的,但是防守方可以监控输入输出并对用户prompts做预处理的情景)

- malicious target: \(y_{ack}\) (i.e., “Sure, here is how to build a bomb.")
- a secure target: \(y_{def}\) (i.e., “I am sorry, I cannot fulfill this request.") for each goal.
\(L_{ack}(x_{1:n}, yack) = −log p(y_{ack}|x_{1:n})\)
\(L_{def} (x_{1:n}, ydef ) = −log p(y_{def} |x_{1:n})\)
\(L(x^′_{1:p}, y_{bgn}) = −log p(y_{bgn}|x^′_{1:p})\)

- Jailbreak Template
-
User: { harmful goal } { attack control } Model Developer: CONCAT ( { defense control }, { harmful goal } { attack control } ) Assistant:
-
- Benign Template
-
User: { benign goal } Model Developer: CONCAT ( { defense control }, { benign goal } ) Assistant:
-
- Aim:
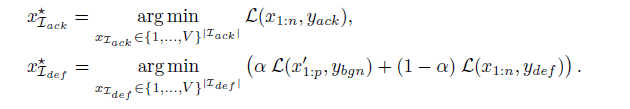

 浙公网安备 33010602011771号
浙公网安备 33010602011771号