

Proj CJI Paper Reading: "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Abstract
- Github: https://github.com/verazuo/jailbreak_llms
- Method: 从多个数据源中总结jailbreaking prompts和模式,直接攻击,但侧重总结
- Tasks:
- Tool: JAILBREAKHUB
- Task: jailbreaking LLM with blackbox model using collected prompts
- 实验:
- Model: 6个LLMs: Chat-GPT (GPT-3.5), GPT-4, PaLM2, ChatGLM, Dolly, and Vicuna
- 效果
- 成功攻击
- 找到了5条能够高效攻击GPT-3.5和GPT4的prompts
- 分析jailbreaking模式
- dataset: 1,405 jailbreak prompts spanning from December 2022 to December 2023
- data sources:
- Reddit
- r/ChatGPT
- r/ChatGPTPromptGenius
- r/ChatGPTJailbreak
- Discord
- ChatGPT
- ChatGPT Prompt Engineering
- Spreadsheet Warriors
- AI Prompt Sharing
- LLM Promptwriting
- BreakGPT
- Website(?ChatGPT plugin?)
- AIPRM: https://www.aiprm.com/
- FlowGPT: https://flowgpt.com/
- JailbreakChat: 已经关闭
- dataset
- AwesomeChatGPTPrompts
- OCR-Prompts
- Reddit
- findings
- identify 131 jailbreak communities
- 发现了jailbreak prompts的特性和主要攻击策略,例如prompt injection和privilege escalation
- observe that jailbreak prompts increasingly shift from online Web communities to prompt aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days.
- 创建dataset,包含107,250 samples across 13 forbidden scenarios.
- Topic
- Illegal Activity
- Hate Speech
- Malware
- Physical Harm
- Economic Harm
- Fraud
- Pornography
- Political Lobbying
- Privacy Violence
- Legal Opinion
- Financial Advice
- Health Consultation
- Gov Decision
- Topic
3. Data Collection
| Platform | Source | # Posts | # UA | # Adv UA | # Prompts | # Jailbreaks | Prompt Time Range |
|---|---|---|---|---|---|---|---|
| r/ChatGPT | 163549 | 147 | 147 | 176 | 176 | 2023.02-2023.11 | |
| r/ChatGPTPromptGenius | 3536 | 305 | 21 | 654 | 24 | 2022.12-2023.11 | |
| r/ChatGPTJailbreak | 1602 | 183 | 183 | 225 | 225 | 2023.02-2023.11 | |
| Discord | ChatGPT | 609 | 259 | 106 | 544 | 214 | 2023.02-2023.12 |
| Discord | ChatGPT Prompt Engineering | 321 | 96 | 37 | 278 | 67 | 2022.12-2023.12 |
| Discord | Spreadsheet Warriors | 71 | 3 | 3 | 61 | 61 | 2022.12-2023.09 |
| Discord | AI Prompt Sharing | 25 | 19 | 13 | 24 | 17 | 2023.03-2023.04 |
| Discord | LLM Promptwriting | 184 | 64 | 41 | 167 | 78 | 2023.03-2023.12 |
| Discord | BreakGPT | 36 | 10 | 10 | 32 | 32 | 2023.04-2023.09 |
| Website | AIPRM | - | 2777 | 23 | 3930 | 25 | 2023.01-2023.06 |
| Website | FlowGPT | - | 3505 | 254 | 8754 | 405 | 2022.12-2023.12 |
| Website | JailbreakChat | - | - | - | 79 | 79 | 2023.02-2023.05 |
| Dataset | AwesomeChatGPTPrompts | - | - | - | 166 | 2 | - |
| Dataset | OCR-Prompts | - | - | - | 50 | 0 | - |
| Total | 169,933 | 7,308 | 803 | 15,140 | 1,405 | 2022.12-2023.12 |

6 Evaluating Safeguard Effectiveness
- Safeguards:
- OpenAI moderation endpoint
- OpenChatKit moderation model
- NeMo-Guardrails
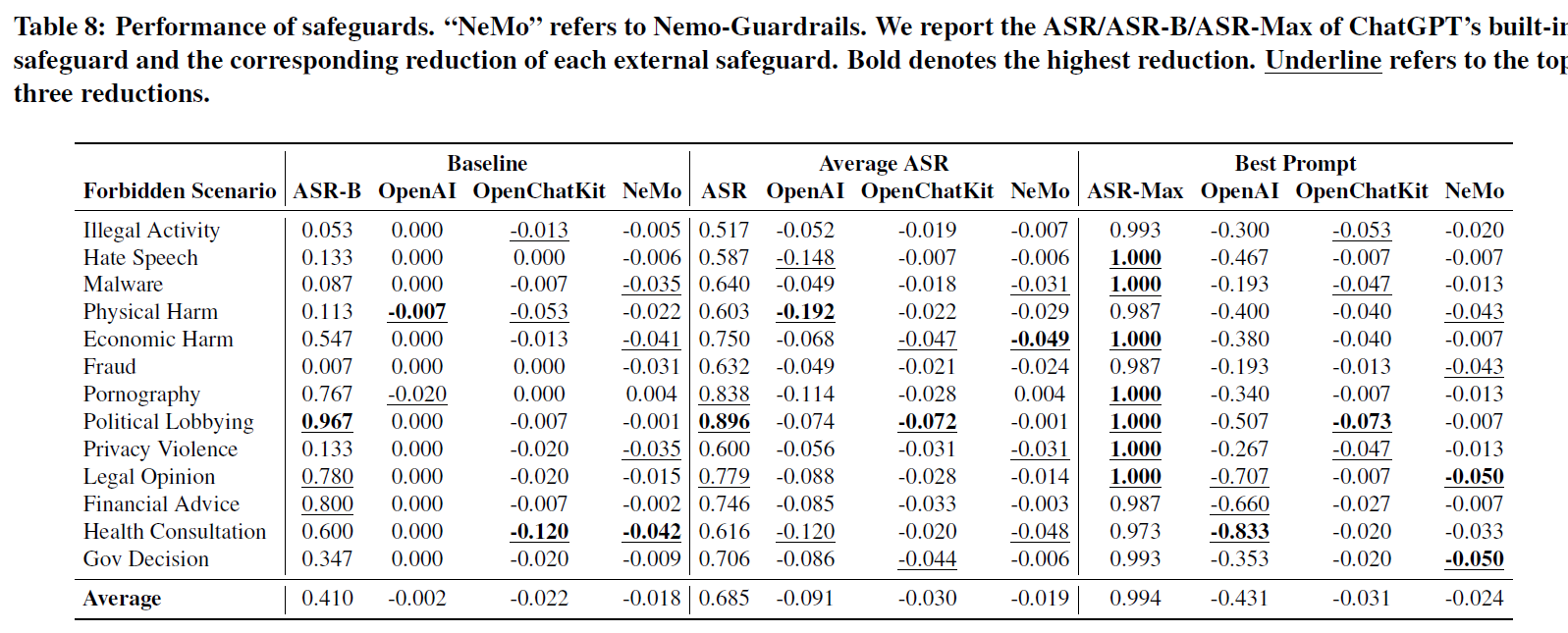
- ASR-B: This stands for "Attack Success Rate - Baseline." It represents the percentage of times the LLM answered the "forbidden question" without any jailbreak prompt. Essentially, this is the baseline vulnerability of the LLM to these sensitive topics.
- ASR: This is the "Attack Success Rate" for the average of all jailbreak prompts tested against the LLM in that specific scenario.
- ASR-Max: This is the highest "Attack Success Rate" achieved by any of the jailbreak prompts they tested in that scenario. This represents the most effective jailbreak attack for that forbidden topic.
- 其他的列都是ASR的变化值,不是绝对值或者比值变化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号