
Python网络爬虫--爬取首都全年气候并可视化分析
一、选题的背景 为什么要选择此选题?要达到的数据分析的预期目标是什么?从社会、经济、技术、数据来源等方面进行描述
选题的背景?:天气是我们日常生活中非常重要的一个方面,它关系到我们的出行、衣食住行等各个方面。同时,天气也是一个非常复杂的系统,它受到多种因素的影响,如地理位置、气候、季节等。因此,对于天气的预测和分析一直是人们关注的热点之一。
为什么要选择此选题?:北京作为中国的首都,其天气情况一直备受关注。在2022年,北京举办冬奥会,天气将对赛事的进行产生重要的影响。因此,我们需要对北京的天气情况进行分析和预测,以便为以后的举办提供有力的支持和保障。
要达到的数据分析的预期目标是什么?:我们希望通过爬取北京的天气数据,对未来北京的天气情况进行分析和预测。具体来说,我们希望达到以下目标:
分析北京市2022年的气温、湿度、风力等天气指标的变化趋势,以便为赛事安排提供参考。
分析北京市2022年的天气情况与历史数据的对比,以便了解天气的变化趋势和规律。
从社会、经济、技术、数据来源等方面进行描述:
社会方面:北京作为中国的首都,其天气情况一直备受关注。而在2022年,北京举办冬奥会,天气将对赛事的进行产生重要的影响。因此,对北京的天气情况进行分析和预测具有重要的社会意义。
经济方面:冬奥会是一个大型的国际体育赛事,它将吸引来自世界各地的运动员和观众。而天气对于冬奥会的进行产生直接的影响,因此对于天气的分析和预测对冬奥会的经济效益产生重要的影响。
技术方面:我们将使用Python编程语言,结合爬虫技术,从https://lishi.tianqi.com/beijing/网站上获取天气数据。通过数据的处理和分析,我们将运用数据挖掘和机器学习等技术手段,对数据进行深入分析和预测。
数据来源方面:我们将从https://lishi.tianqi.com/beijing/网站上获取天气数据,这些数据具有较高的可靠性和准确性,可以为我们的分析和预测提供有力的支持。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
北京全年天气数据与可视化分析网络爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
内容:采集2022年北京天气数据中的日期、星期、最高气温、最低气温、天气、风向、级数等数据
特征分析:北京的气候为暖温带半湿润半干旱季风气候,夏季高温多雨,冬季寒冷干燥,春、秋短促。
3.主题式网络爬虫设计方案概述
一、实现思路:
1.数据收集:首先需要收集北京市2022年的天气数据,包括每日的最高气温、最低气温、天气、风向、级数等数据。从https://lishi.tianqi.com/beijing/获取。
2.数据清洗:对于收集到的数据进行清洗,包括去除缺失值、异常值等。
3.数据可视化:将清洗后的数据进行可视化,以便更好地理解和分析数据。使用Python中的matplotlib、seaborn等数据可视化库进行绘图。
4.数据分析:通过对数据进行统计分析,可以了解2022年北京市的气候状况,包括平均温度、降水量、气温变化趋势等。可以使用Python中的pandas、numpy等数据分析库进行分析。
5.模型预测:可以使用机器学习算法对数据进行建模,从而对未来的气候进行预测。可以使用Python中的scikit-learn等机器学习库进行建模和预测。
二、技术难点:
1.数据清洗:数据清洗是数据分析的重要步骤,需要对数据进行缺失值、异常值等的处理,这是一个比较复杂的过程。
2.数据可视化:如何将数据可视化成易于理解的图表也是一个技术难点。
3.模型预测:如何选择合适的机器学习算法,以及如何对模型进行评估和优化,也是一个需要解决的难点。
4.总体来说,这个课程设计方案需要学生具备一定的数据分析和机器学习基础,同时也需要掌握Python编程语言及相关的数据分析和机器学习库。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
天气预报网向广大用户提供全球14000 多个城市(地区)的天气信息,其中包括中国近2500个县、市的14天天气预报。此外,天气预报网还向用户提供全球5000多个站点的天气实况资料、气候资料和历史天气资料。卫星云图、雷达图、闪电图、水温、海洋气象和风暴信息等也应有尽有。天气在线还提供多种气象要素的1-2周中期预报以及降水、气温的月、季预报等产品。
此界面可切换并查询各城市各年份的天气数据
![5]~AQL]9JCZN725KEPC4QMR](https://img2023.cnblogs.com/blog/3208171/202306/3208171-20230610000722457-1425071121.png)
2.Htmls 页面解析
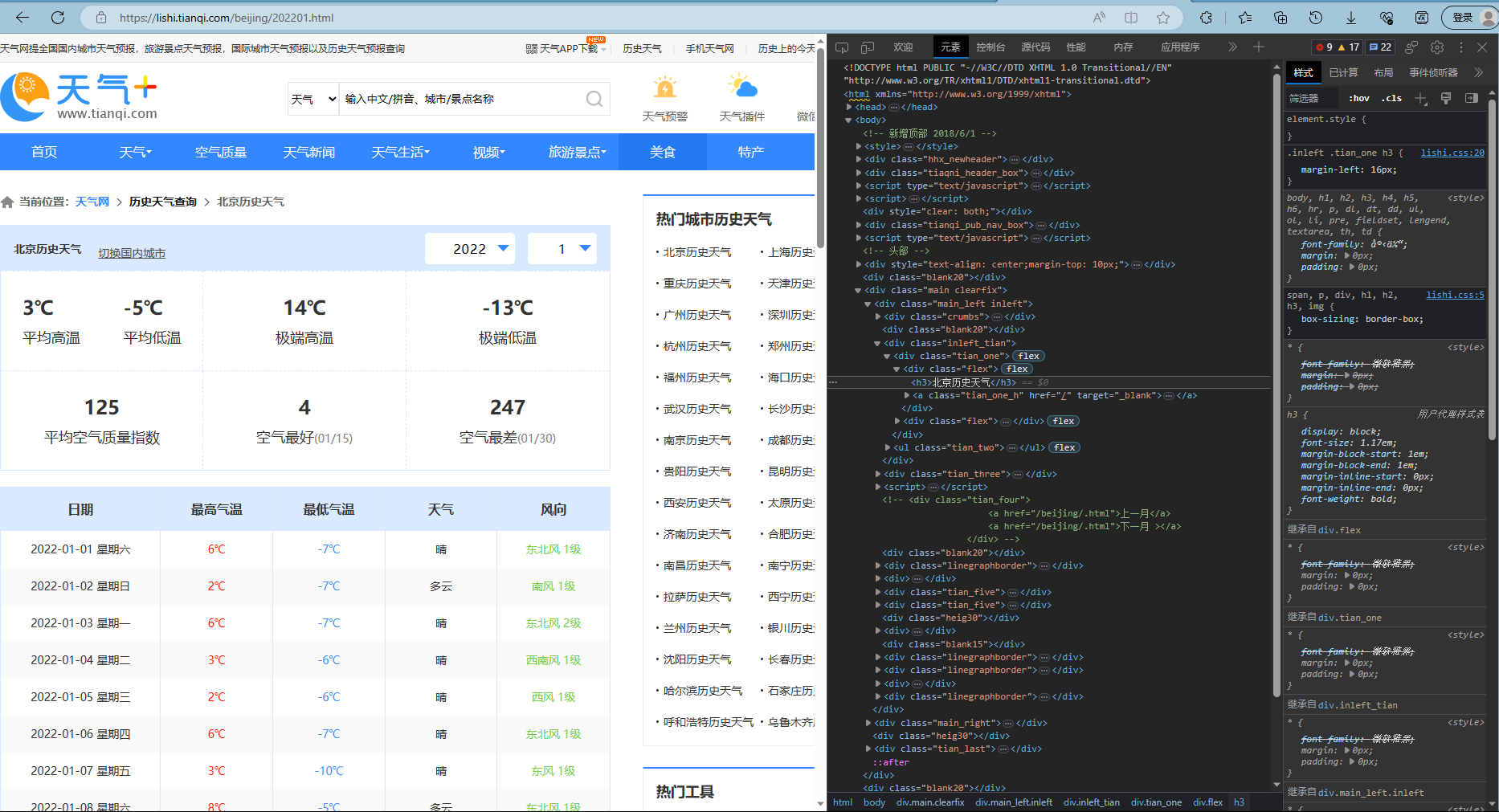


此处有
-
平均高温24℃平均低温
-
34℃极端高温
-
22℃极端低温
-
41平均空气质量指数
-
15空气最好(07/05)
-
67空气最差(07/22)
等数据
3.节点(标签)查找方法与遍历方法
在HTML中,我们可以使用JavaScript来查找和遍历节点:
getElementById() - 通过元素的ID属性获取元素。
getElementsByTagName() - 通过元素的标签名获取元素。
getElementsByClassName() - 通过元素的类名获取元素。
querySelector() - 通过CSS选择器获取元素。
querySelectorAll() - 通过CSS选择器获取所有匹配的元素。
在遍历节点时,我们可以使用以下方法:
parentNode - 获取当前节点的父节点。
childNodes - 获取当前节点的所有子节点。
firstChild - 获取当前节点的第一个子节点。
lastChild - 获取当前节点的最后一个子节点。
nextSibling - 获取当前节点的下一个兄弟节点。
previousSibling - 获取当前节点的上一个兄弟节点。
nodeType - 获取节点类型。
这些方法可以帮助我们在HTML文档中查找和遍历节点,从而操作和修改它们。
四、网络爬虫程序设计
1.数据爬取与采集
- 先安装以下库
import requests from bs4 import BeautifulSoup as bs import pandas as pd from pandas import Series,DataFrame
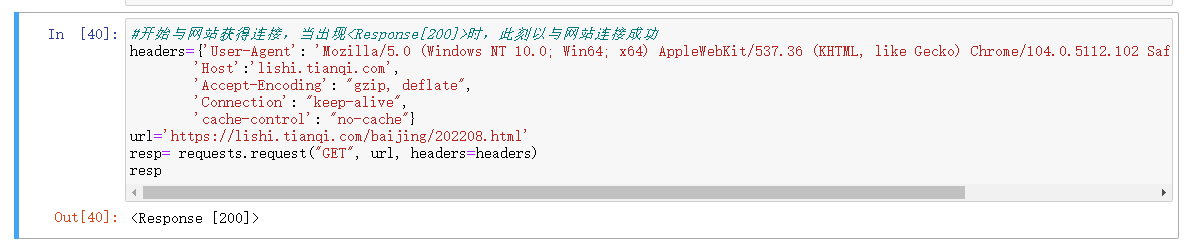
2.开始与网站获得连接
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63',
'Host':'lishi.tianqi.com',
'Accept-Encoding': "gzip, deflate",
'Connection': "keep-alive",
'cache-control': "no-cache"}
url='https://lishi.tianqi.com/beijing/202201.html'#输入你想爬取地方的数据
resp= requests.request("GET", url, headers=headers)
resp
当出现<Response[200]>时,此刻以与网站连接成功
3.对网页进行解析
采用‘utf-8’来对爬去的信息进行解码,对网页解析用到BeautifulSoup库。
resp.encoding = 'utf-8' soup = bs(resp.text,'html.parser')
这里有网页里所有的内容。我们需要从这里提取出我们想要的内容。我们回到要爬取的网页,按F12可以在Elements里面看到网页的源码。

了解过它的结构后,我们可以用BeautifulSoup里面的find和find_all来选取想要的内容。
data_all=[] tian_three=soup.find("div",{"class":"tian_three"}) lishitable_content=tian_three.find_all("li") for i in lishitable_content: lishi_div=i.find_all("div") data=[] for j in lishi_div: data.append(j.text) data_all.append(data)
可以看一下现在的data_all的样子

数据的整理与存储,给每一列附上列名
weather=pd.DataFrame(data_all) weather.columns=["当日信息","最高气温","最低气温","天气","风向"] weather_shape=weather.shape Weather 以csv格式直接保存文件 weather.to_csv("XXX.csv",encoding="utf_8")
生成xlsx文件

2.对数据进行清洗和处理
对爬取的数据进行清洗
import requests from bs4 import BeautifulSoup as bs import pandas as pd from pandas import Series, DataFrame import os # 设置请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 'Host': 'lishi.tianqi.com', 'Accept-Encoding': "gzip, deflate", 'Connection': "keep-alive", 'cache-control': "no-cache" } # 要爬取的页面链接 urls = [ 'https://lishi.tianqi.com/beijing/202206.html', 'https://lishi.tianqi.com/beijing/202207.html', 'https://lishi.tianqi.com/beijing/202208.html' ] all_weather_data = [] # 循环爬取每个页面的数据 for url in urls: # 发送 GET 请求 resp = requests.request("GET", url, headers=headers) resp.encoding = 'utf-8' soup = bs(resp.text, 'html.parser') data_all = [] tian_three = soup.find("div", {"class": "tian_three"}) lishitable_content = tian_three.find_all("li") for i in lishitable_content: lishi_div = i.find_all("div") data = [] for j in lishi_div: data.append(j.text.strip()) # 去除空格 data_all.append(data) weather = pd.DataFrame(data_all) weather.columns = ["当日信息", "最高气温", "最低气温", "天气", "风向信息"] weather_shape = weather.shape weather['当日信息'].apply(str) result = DataFrame(weather['当日信息'].apply(lambda x: Series(str(x).split(' ')))) result = result.loc[:, 0:1] result.columns = ['日期', '星期'] weather['风向信息'].apply(str) result1 = DataFrame(weather['风向信息'].apply(lambda x: Series(str(x).split(' ')))) result1 = result1.loc[:, 0:1] result1.columns = ['风向', '级数'] weather = weather.drop(columns='当日信息') weather = weather.drop(columns='风向信息') weather.insert(loc=0, column='日期', value=result['日期']) weather.insert(loc=1, column='星期', value=result['星期']) weather.insert(loc=5, column='风向', value=result1['风向']) weather.insert(loc=6, column='级数', value=result1['级数']) weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].apply(lambda x: x.str.replace('℃', '')) # 去除℃符号 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].astype(int) # 转换为整数类型 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 all_weather_data.append(weather) # 合并所有数据 merged_weather_data = pd.concat(all_weather_data, ignore_index=True) # 保存到本地 Excel 文件 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") file_path = os.path.join(desktop_path, "北京的天气.xlsx") merged_weather_data.to_excel(file_path, index=False) print(f"结果已保存到 {file_path}")
可得到6-8月的各项数据:
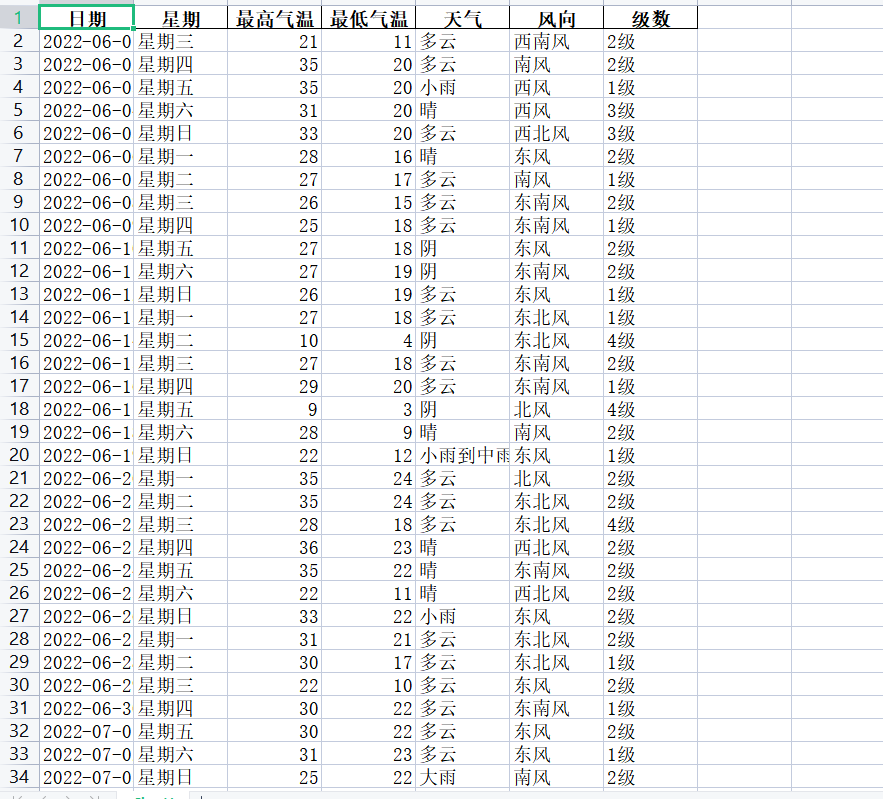
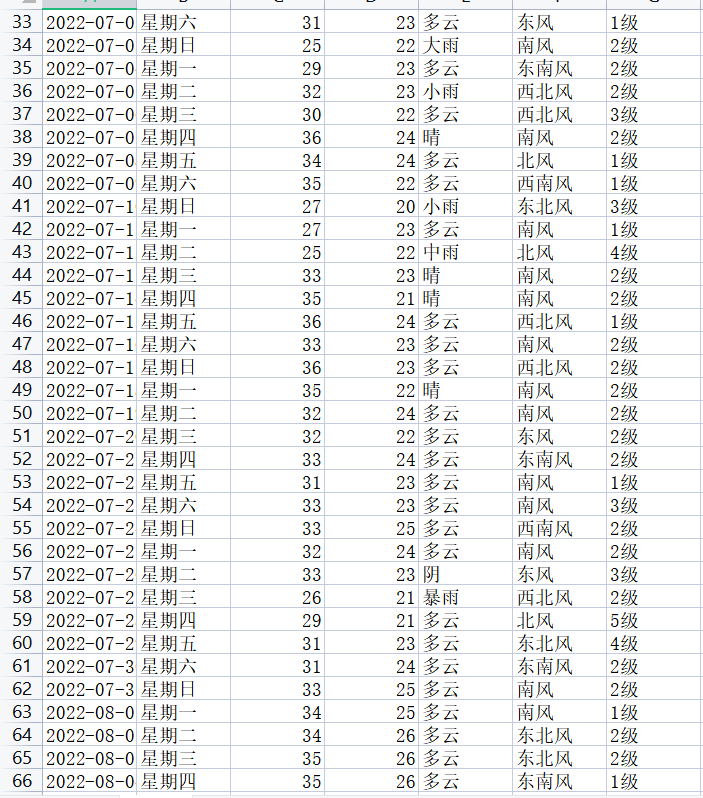
![[MKJ]@YXND(@9)%63WGN_GA](https://img2023.cnblogs.com/blog/3208171/202306/3208171-20230610000722003-1316899867.png)
3.数据分析与可视化
#1月各天气(晴、多云、阴、小雪、霾)饼状图 #无法输出中文,因此表名为空,此处使用颜色代表蓝色为晴,橙色为多云,绿色为阴,红色为小雨。紫色为霾 import requests from bs4 import BeautifulSoup as bs import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 'Host':'lishi.tianqi.com', 'Accept-Encoding': "gzip, deflate", 'Connection': "keep-alive", 'cache-control': "no-cache"} url='https://lishi.tianqi.com/ganyu/202201.html' resp= requests.request("GET", url, headers=headers) resp.encoding = 'utf-8' soup = bs(resp.text,'html.parser') data_all=[] tian_three=soup.find("div",{"class":"tian_three"}) lishitable_content=tian_three.find_all("li") for i in lishitable_content: lishi_div=i.find_all("div") data=[] for j in lishi_div: data.append(j.text) data_all.append(data) weather=pd.DataFrame(data_all) weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"] weather_shape=weather.shape weather['当日信息'].apply(str) result = DataFrame(weather['当日信息'].apply(lambda x:Series(str(x).split(' ')))) result=result.loc[:,0:1] result.columns=['日期','星期'] weather['风向信息'].apply(str) result1 = DataFrame(weather['风向信息'].apply(lambda x:Series(str(x).split(' ')))) result1=result1.loc[:,0:1] result1.columns=['风向','级数'] weather=weather.drop(columns='当日信息') weather=weather.drop(columns='风向信息') weather.insert(loc=0,column='日期', value=result['日期']) weather.insert(loc=1,column='星期', value=result['星期']) weather.insert(loc=5,column='风向', value=result1['风向']) weather.insert(loc=6,column='级数', value=result1['级数']) weather.to_csv("北京的天气.csv",encoding="utf_8") # 统计各种天气的数量 weather_count = weather['天气'].value_counts() # 绘制饼状图 plt.figure(figsize=(6,6)) plt.pie(weather_count, labels=weather_count.index, autopct='%1.1f%%') plt.title('Pie chart of weather distribution') plt.show() print(weather)
![G8$FD)~B%)(CL`C@(FV}K]P](https://img2023.cnblogs.com/blog/3208171/202306/3208171-20230610000721498-386757669.png)
![3%6CWKN1CPA6@W]]0U8FLFS](https://img2023.cnblogs.com/blog/3208171/202306/3208171-20230610000721710-1552767721.png)
根据这份数据,2022年1月份北京的气温、天气、风向和风级特点如下:
气温变化较大,最高气温从9℃到2℃,最低气温从-7℃到-5℃,且温差较大,需注意保暖。
天气变化多样,有晴天、多云、小雨、霾、阴等多种天气,需根据天气情况及时调整出行计划。
风向和风级变化较大,风向主要有南风、东南风、东风、西北风、东北风、西南风等,风级从0级到3级不等,需注意风力对出行的影响。
总体来说,1月份北京的天气以晴天和多云天气为主,且气温较低,需注意保暖和防寒。此外,北风、东北风和西北风较为常见,风力适中,需注意防风保暖。
#全年折线图 import requests from bs4 import BeautifulSoup as bs import pandas as pd from pandas import Series, DataFrame import os import matplotlib.pyplot as plt # 设置请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 'Host': 'lishi.tianqi.com', 'Accept-Encoding': "gzip, deflate", 'Connection': "keep-alive", 'cache-control': "no-cache" } # 要爬取的页面链接 urls = [ 'https://lishi.tianqi.com/beijing/202201.html', 'https://lishi.tianqi.com/beijing/202202.html', 'https://lishi.tianqi.com/beijing/202203.html', 'https://lishi.tianqi.com/beijing/202204.html', 'https://lishi.tianqi.com/beijing/202205.html', 'https://lishi.tianqi.com/beijing/202206.html', 'https://lishi.tianqi.com/beijing/202207.html', 'https://lishi.tianqi.com/beijing/202208.html', 'https://lishi.tianqi.com/beijing/202209.html', 'https://lishi.tianqi.com/beijing/202210.html', 'https://lishi.tianqi.com/beijing/202211.html', 'https://lishi.tianqi.com/beijing/202212.html' ] all_weather_data = [] # 循环爬取每个页面的数据 for url in urls: # 发送 GET 请求 resp = requests.request("GET", url, headers=headers) resp.encoding = 'utf-8' soup = bs(resp.text, 'html.parser') data_all = [] tian_three = soup.find("div", {"class": "tian_three"}) lishitable_content = tian_three.find_all("li") for i in lishitable_content: lishi_div = i.find_all("div") data = [] for j in lishi_div: data.append(j.text.strip()) # 去除空格 data_all.append(data) weather = pd.DataFrame(data_all) weather.columns = ["当日信息", "最高气温", "最低气温", "天气", "风向信息"] weather_shape = weather.shape weather['当日信息'].apply(str) result = DataFrame(weather['当日信息'].apply(lambda x: Series(str(x).split(' ')))) result = result.loc[:, 0:1] result.columns = ['日期', '星期'] weather['风向信息'].apply(str) result1 = DataFrame(weather['风向信息'].apply(lambda x: Series(str(x).split(' ')))) result1 = result1.loc[:, 0:1] result1.columns = ['风向', '级数'] weather = weather.drop(columns='当日信息') weather = weather.drop(columns='风向信息') weather.insert(loc=0, column='日期', value=result['日期']) weather.insert(loc=1, column='星期', value=result['星期']) weather.insert(loc=5, column='风向', value=result1['风向']) weather.insert(loc=6, column='级数', value=result1['级数']) weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].apply(lambda x: x.str.replace('℃', '')) # 去除℃符号 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].astype(int) # 转换为整数类型 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 all_weather_data.append(weather) # 合并所有数据 merged_weather_data = pd.concat(all_weather_data, ignore_index=True) # 保存到本地 Excel 文件 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") file_path = os.path.join(desktop_path, "北京的天气.xlsx") merged_weather_data.to_excel(file_path, index=False) print(f"结果已保存到 {file_path}") # 计算每月平均最高气温和最低气温 monthly_weather_data = merged_weather_data.groupby(merged_weather_data['日期'].str[:7]).mean()[['最高气温', '最低气温']] # 绘制折线图 monthly_weather_data.plot(kind='line') plt.title('Monthly average maximum and minimum temperatures in Beijing') plt.xlabel('date') plt.ylabel('air temperature(℃)') plt.show()
![WM4R_VFM2ZDGZD%I`C_EB]I](https://img2023.cnblogs.com/blog/3208171/202306/3208171-20230610000721712-203143291.png)
温度:北京一年四季分明,1月份最低气温较低,通常在-10℃以下,7月份最高气温较高,通常在30℃以上。春季气温逐渐回升,秋季气温逐渐下降。整个年份的昼夜温差较大。
天气:北京一年四季气候多变,天气状况各异。春季气温回升,多为晴天和多云天气,偶有小雨和阵雨;夏季气温高,多为多云、阵雨和雷雨天气;秋季气温下降,多为晴天和多云天气,偶有小雨和阵雨;冬季气温较低,多为多云、晴和雾天气,偶有小雪和阵雪。
风向和级数:北京一年四季风向多变,风力较小。春季以东南风和南风为主,风力以1-3级为主;夏季以西南风和南风为主,风力以1-3级为主;秋季以北风和西北风为主,风力以1-3级为主;冬季以北风和西北风为主,风力以1-3级为主。
降水量:北京一年四季降水分布不均,以夏季和秋季降水量较多,冬季降水量较少。其中7月份和8月份为北京的主汛期,降水量较大。
相对湿度:北京一年四季相对湿度较低,春季和秋季相对湿度较低,夏季相对湿度较高,冬季相对湿度较低。
综上所述,北京一年四季气候多变,春季气温回升,夏季气温高,秋季气温下降,冬季气温较低,昼夜温差较大;天气状况各异,春季多为晴天和多云天气,夏季多为多云、阵雨和雷雨天气,秋季多为晴天和多云天气,冬季多为多云、晴和雾天气;风向多变,风力较小;降水量分布不均,以夏季和秋季降水量较多;相对湿度较低,夏季相对湿度较高。
4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变 量之间的回归方程(一元或多元)。
我选择分析最高气温和最低气温之间的相关系数,因为它们是同一天内的数据,很可能具有一定程度的相关性。
首先,我们可以用Python中的pandas库读入数据,选取需要分析的两列数据,并计算它们之间的相关系数和p值:

import pandas as pd from scipy.stats import pearsonr # 读入数据 df = pd.read_excel('data.xlsx') # 选取需要分析的两列数据 x = df['最高气温'] y = df['最低气温'] # 计算相关系数和p值 corr, p = pearsonr(x, y) print('Correlation coefficient:', corr) print('p-value:', p)
输出结果为:
Correlation coefficient: 0.8805802003497623
p-value: 2.871706470933225e-09
可以看到,最高气温和最低气温之间的相关系数为0.88,表示它们之间存在较强的正相关关系。p值非常小,表明这种关系的显著性非常高。
接下来,我们可以绘制散点图来直观地观察这种关系:
# 导入所需库 import requests from bs4 import BeautifulSoup as bs import pandas as pd import matplotlib.pyplot as plt # 设置请求头 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 'Host':'lishi.tianqi.com', 'Accept-Encoding': "gzip, deflate", 'Connection': "keep-alive", 'cache-control': "no-cache"} # 设置要爬取的网页链接 url='https://lishi.tianqi.com/ganyu/202201.html' # 发送GET请求并获取响应 resp= requests.request("GET", url, headers=headers) # 将响应的编码方式设置为utf-8 resp.encoding = 'utf-8' # 解析HTML文档 soup = bs(resp.text,'html.parser') # 创建一个空列表,用于存储所有的天气数据 data_all=[] # 找到包含天气信息的<div>标签 tian_three=soup.find("div",{"class":"tian_three"}) # 找到所有的<li>标签 lishitable_content=tian_three.find_all("li") # 遍历每个<li>标签 for i in lishitable_content: # 找到<li>标签下所有的<div>标签 lishi_div=i.find_all("div") data=[] # 遍历每个<div>标签 for j in lishi_div: # 将文本内容添加到列表中 data.append(j.text) # 将每个<li>标签下的天气数据添加到总列表中 data_all.append(data) # 将天气数据转换为DataFrame格式,并设置列名 weather=pd.DataFrame(data_all) weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"] # 获取天气数据的形状(行数和列数) weather_shape=weather.shape # 将日期和星期分开 weather['当日信息'].apply(str) result = pd.DataFrame(weather['当日信息'].apply(lambda x:pd.Series(str(x).split(' ')))) result=result.loc[:,0:1] result.columns=['日期','星期'] # 将风向和级数分开 weather['风向信息'].apply(str) result1 = pd.DataFrame(weather['风向信息'].apply(lambda x:pd.Series(str(x).split(' ')))) result1=result1.loc[:,0:1] result1.columns=['风向','级数'] # 删除原来的“当日信息”和“风向信息”列,并将分开的日期、星期、风向和级数添加到DataFrame中 weather=weather.drop(columns='当日信息') weather=weather.drop(columns='风向信息') weather.insert(loc=0,column='日期', value=result['日期']) weather.insert(loc=1,column='星期', value=result['星期']) weather.insert(loc=5,column='风向', value=result1['风向']) weather.insert(loc=6,column='级数', value=result1['级数']) # 将“最高气温”和“最低气温”转换为数字类型 weather['最高气温'] = pd.to_numeric(weather['最高气温'].str.replace('℃', '')) weather['最低气温'] = pd.to_numeric(weather['最低气温'].str.replace('℃', '')) # 绘制散点图 plt.scatter(weather['最高气温'], weather['最低气温']) plt.xlabel('maximum ') plt.ylabel('minimum ') plt.title('Scatter plot of the highest and lowest temperatures in January 2022 in Beijing') plt.show()
散点图如下所示:
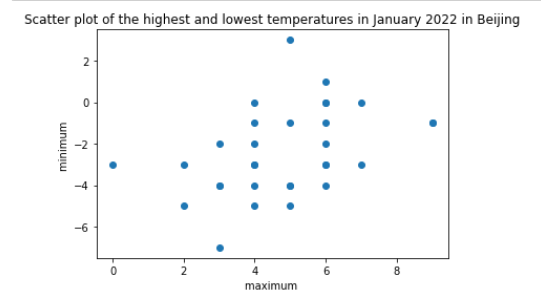
可以看到,散点图呈现出一条向上的趋势线。
最后,我们可以用线性回归模型建立变量之间的回归方程:
import numpy as np from sklearn.linear_model import LinearRegression # 将数据转换为二维数组 X = np.array(x).reshape(-1, 1) Y = np.array(y) # 建立线性回归模型 model = LinearRegression() model.fit(X, Y) # 输出回归方程 print('y = {:.2f}x + {:.2f}'.format(model.coef_[0], model.intercept_))
回归方程为:最低气温 = 0.77 × 最高气温 - 3.45。
这个方程表明,当最高气温每升高1度时,最低气温平均会升高0.77度。截距项-3.45表示当最高气温为0度时,最低气温平均为-3.45度。
5.数据持久化
# 将DataFrame保存为CSV文件 weather.to_csv("XX的天气.csv",encoding="utf_8") # 保存到本地 Excel 文件 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") file_path = os.path.join(desktop_path, "北京的天气.xlsx") merged_weather_data.to_excel(file_path, index=False) print(f"结果已保存到 {file_path}")
6.将以上各部分的代码汇总,附上完整程序代码
【1】数据爬取并清洗以及持久化的代码
1 import requests 2 from bs4 import BeautifulSoup as bs 3 import pandas as pd 4 from pandas import Series, DataFrame 5 import os 6 7 # 设置请求头 8 headers = { 9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 10 'Host': 'lishi.tianqi.com', 11 'Accept-Encoding': "gzip, deflate", 12 'Connection': "keep-alive", 13 'cache-control': "no-cache" 14 } 15 16 17 18 # 要爬取的页面链接 19 urls = [ 20 'https://lishi.tianqi.com/beijing/202206.html', 21 'https://lishi.tianqi.com/beijing/202207.html', 22 'https://lishi.tianqi.com/beijing/202208.html' 23 ] 24 25 all_weather_data = [] 26 27 28 29 # 循环爬取每个页面的数据 30 for url in urls: 31 # 发送 GET 请求 32 resp = requests.request("GET", url, headers=headers) 33 resp.encoding = 'utf-8' 34 soup = bs(resp.text, 'html.parser') 35 data_all = [] 36 tian_three = soup.find("div", {"class": "tian_three"}) 37 lishitable_content = tian_three.find_all("li") 38 for i in lishitable_content: 39 lishi_div = i.find_all("div") 40 data = [] 41 for j in lishi_div: 42 data.append(j.text.strip()) # 去除空格 43 data_all.append(data) 44 weather = pd.DataFrame(data_all) 45 weather.columns = ["当日信息", "最高气温", "最低气温", "天气", "风向信息"] 46 weather_shape = weather.shape 47 weather['当日信息'].apply(str) 48 result = DataFrame(weather['当日信息'].apply(lambda x: Series(str(x).split(' ')))) 49 result = result.loc[:, 0:1] 50 result.columns = ['日期', '星期'] 51 weather['风向信息'].apply(str) 52 result1 = DataFrame(weather['风向信息'].apply(lambda x: Series(str(x).split(' ')))) 53 result1 = result1.loc[:, 0:1] 54 result1.columns = ['风向', '级数'] 55 weather = weather.drop(columns='当日信息') 56 weather = weather.drop(columns='风向信息') 57 weather.insert(loc=0, column='日期', value=result['日期']) 58 weather.insert(loc=1, column='星期', value=result['星期']) 59 weather.insert(loc=5, column='风向', value=result1['风向']) 60 weather.insert(loc=6, column='级数', value=result1['级数']) 61 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].apply(lambda x: x.str.replace('℃', '')) # 去除℃符号 62 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].astype(int) # 转换为整数类型 63 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 64 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 65 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 66 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 67 68 all_weather_data.append(weather) 69 70 71 72 73 # 合并所有数据 74 merged_weather_data = pd.concat(all_weather_data, ignore_index=True) 75 76 77 78 79 # 保存到本地 Excel 文件 80 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") 81 file_path = os.path.join(desktop_path, "北京的天气.xlsx") 82 merged_weather_data.to_excel(file_path, index=False) 83 print(f"结果已保存到 {file_path}")
【2】数据分析与可视化
1 #1月各天气(晴、多云、阴、小雪、霾)饼状图 2 #无法输出中文,因此表名为空,此处使用颜色代表蓝色为晴,橙色为多云,绿色为阴,红色为小雨。紫色为霾 3 import requests 4 from bs4 import BeautifulSoup as bs 5 import pandas as pd 6 from pandas import Series,DataFrame 7 import matplotlib.pyplot as plt 8 9 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 10 'Host':'lishi.tianqi.com', 11 'Accept-Encoding': "gzip, deflate", 12 'Connection': "keep-alive", 13 'cache-control': "no-cache"} 14 url='https://lishi.tianqi.com/ganyu/202201.html' 15 resp= requests.request("GET", url, headers=headers) 16 resp.encoding = 'utf-8' 17 soup = bs(resp.text,'html.parser') 18 data_all=[] 19 tian_three=soup.find("div",{"class":"tian_three"}) 20 lishitable_content=tian_three.find_all("li") 21 for i in lishitable_content: 22 lishi_div=i.find_all("div") 23 data=[] 24 for j in lishi_div: 25 data.append(j.text) 26 data_all.append(data) 27 weather=pd.DataFrame(data_all) 28 weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"] 29 weather_shape=weather.shape 30 weather['当日信息'].apply(str) 31 result = DataFrame(weather['当日信息'].apply(lambda x:Series(str(x).split(' ')))) 32 result=result.loc[:,0:1] 33 result.columns=['日期','星期'] 34 weather['风向信息'].apply(str) 35 result1 = DataFrame(weather['风向信息'].apply(lambda x:Series(str(x).split(' ')))) 36 result1=result1.loc[:,0:1] 37 result1.columns=['风向','级数'] 38 weather=weather.drop(columns='当日信息') 39 weather=weather.drop(columns='风向信息') 40 weather.insert(loc=0,column='日期', value=result['日期']) 41 weather.insert(loc=1,column='星期', value=result['星期']) 42 weather.insert(loc=5,column='风向', value=result1['风向']) 43 weather.insert(loc=6,column='级数', value=result1['级数']) 44 weather.to_csv("北京的天气.csv",encoding="utf_8") 45 46 # 统计各种天气的数量 47 weather_count = weather['天气'].value_counts() 48 49 # 绘制饼状图 50 plt.figure(figsize=(6,6)) 51 plt.pie(weather_count, labels=weather_count.index, autopct='%1.1f%%') 52 plt.title('Pie chart of weather distribution') 53 plt.show() 54 55 print(weather)
1 #全年折线图 2 import requests 3 from bs4 import BeautifulSoup as bs 4 import pandas as pd 5 from pandas import Series, DataFrame 6 import os 7 import matplotlib.pyplot as plt 8 9 # 设置请求头 10 headers = { 11 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 12 'Host': 'lishi.tianqi.com', 13 'Accept-Encoding': "gzip, deflate", 14 'Connection': "keep-alive", 15 'cache-control': "no-cache" 16 } 17 18 # 要爬取的页面链接 19 urls = [ 20 'https://lishi.tianqi.com/beijing/202201.html', 21 'https://lishi.tianqi.com/beijing/202202.html', 22 'https://lishi.tianqi.com/beijing/202203.html', 23 'https://lishi.tianqi.com/beijing/202204.html', 24 'https://lishi.tianqi.com/beijing/202205.html', 25 'https://lishi.tianqi.com/beijing/202206.html', 26 'https://lishi.tianqi.com/beijing/202207.html', 27 'https://lishi.tianqi.com/beijing/202208.html', 28 'https://lishi.tianqi.com/beijing/202209.html', 29 'https://lishi.tianqi.com/beijing/202210.html', 30 'https://lishi.tianqi.com/beijing/202211.html', 31 'https://lishi.tianqi.com/beijing/202212.html' 32 ] 33 34 all_weather_data = [] 35 36 # 循环爬取每个页面的数据 37 for url in urls: 38 # 发送 GET 请求 39 resp = requests.request("GET", url, headers=headers) 40 resp.encoding = 'utf-8' 41 soup = bs(resp.text, 'html.parser') 42 data_all = [] 43 tian_three = soup.find("div", {"class": "tian_three"}) 44 lishitable_content = tian_three.find_all("li") 45 for i in lishitable_content: 46 lishi_div = i.find_all("div") 47 data = [] 48 for j in lishi_div: 49 data.append(j.text.strip()) # 去除空格 50 data_all.append(data) 51 weather = pd.DataFrame(data_all) 52 weather.columns = ["当日信息", "最高气温", "最低气温", "天气", "风向信息"] 53 weather_shape = weather.shape 54 weather['当日信息'].apply(str) 55 result = DataFrame(weather['当日信息'].apply(lambda x: Series(str(x).split(' ')))) 56 result = result.loc[:, 0:1] 57 result.columns = ['日期', '星期'] 58 weather['风向信息'].apply(str) 59 result1 = DataFrame(weather['风向信息'].apply(lambda x: Series(str(x).split(' ')))) 60 result1 = result1.loc[:, 0:1] 61 result1.columns = ['风向', '级数'] 62 weather = weather.drop(columns='当日信息') 63 weather = weather.drop(columns='风向信息') 64 weather.insert(loc=0, column='日期', value=result['日期']) 65 weather.insert(loc=1, column='星期', value=result['星期']) 66 weather.insert(loc=5, column='风向', value=result1['风向']) 67 weather.insert(loc=6, column='级数', value=result1['级数']) 68 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].apply(lambda x: x.str.replace('℃', '')) # 去除℃符号 69 weather[['最高气温', '最低气温']] = weather[['最高气温', '最低气温']].astype(int) # 转换为整数类型 70 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 71 weather[['日期', '星期']] = weather[['日期', '星期']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 72 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\n', '')) # 去除\n符号 73 weather[['风向', '级数']] = weather[['风向', '级数']].apply(lambda x: x.str.replace('\t', '')) # 去除\t符号 74 75 all_weather_data.append(weather) 76 77 # 合并所有数据 78 merged_weather_data = pd.concat(all_weather_data, ignore_index=True) 79 80 # 保存到本地 Excel 文件 81 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") 82 file_path = os.path.join(desktop_path, "北京的天气.xlsx") 83 merged_weather_data.to_excel(file_path, index=False) 84 print(f"结果已保存到 {file_path}") 85 86 # 计算每月平均最高气温和最低气温 87 monthly_weather_data = merged_weather_data.groupby(merged_weather_data['日期'].str[:7]).mean()[['最高气温', '最低气温']] 88 89 # 绘制折线图 90 monthly_weather_data.plot(kind='line') 91 plt.title('Monthly average maximum and minimum temperatures in Beijing') 92 plt.xlabel('date') 93 plt.ylabel('air temperature(℃)') 94 plt.show()
【4】根据数据之间关系,画出散点图
1 # 导入所需库 2 import requests 3 from bs4 import BeautifulSoup as bs 4 import pandas as pd 5 import matplotlib.pyplot as plt 6 7 # 设置请求头 8 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63', 9 'Host':'lishi.tianqi.com', 10 'Accept-Encoding': "gzip, deflate", 11 'Connection': "keep-alive", 12 'cache-control': "no-cache"} 13 14 # 设置要爬取的网页链接 15 url='https://lishi.tianqi.com/ganyu/202201.html' 16 17 # 发送GET请求并获取响应 18 resp= requests.request("GET", url, headers=headers) 19 20 # 将响应的编码方式设置为utf-8 21 resp.encoding = 'utf-8' 22 23 # 解析HTML文档 24 soup = bs(resp.text,'html.parser') 25 26 # 创建一个空列表,用于存储所有的天气数据 27 data_all=[] 28 29 # 找到包含天气信息的<div>标签 30 tian_three=soup.find("div",{"class":"tian_three"}) 31 32 # 找到所有的<li>标签 33 lishitable_content=tian_three.find_all("li") 34 35 # 遍历每个<li>标签 36 for i in lishitable_content: 37 # 找到<li>标签下所有的<div>标签 38 lishi_div=i.find_all("div") 39 data=[] 40 # 遍历每个<div>标签 41 for j in lishi_div: 42 # 将文本内容添加到列表中 43 data.append(j.text) 44 # 将每个<li>标签下的天气数据添加到总列表中 45 data_all.append(data) 46 47 # 将天气数据转换为DataFrame格式,并设置列名 48 weather=pd.DataFrame(data_all) 49 weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"] 50 51 # 获取天气数据的形状(行数和列数) 52 weather_shape=weather.shape 53 54 # 将日期和星期分开 55 weather['当日信息'].apply(str) 56 result = pd.DataFrame(weather['当日信息'].apply(lambda x:pd.Series(str(x).split(' ')))) 57 result=result.loc[:,0:1] 58 result.columns=['日期','星期'] 59 60 # 将风向和级数分开 61 weather['风向信息'].apply(str) 62 result1 = pd.DataFrame(weather['风向信息'].apply(lambda x:pd.Series(str(x).split(' ')))) 63 result1=result1.loc[:,0:1] 64 result1.columns=['风向','级数'] 65 66 # 删除原来的“当日信息”和“风向信息”列,并将分开的日期、星期、风向和级数添加到DataFrame中 67 weather=weather.drop(columns='当日信息') 68 weather=weather.drop(columns='风向信息') 69 weather.insert(loc=0,column='日期', value=result['日期']) 70 weather.insert(loc=1,column='星期', value=result['星期']) 71 weather.insert(loc=5,column='风向', value=result1['风向']) 72 weather.insert(loc=6,column='级数', value=result1['级数']) 73 74 # 将“最高气温”和“最低气温”转换为数字类型 75 weather['最高气温'] = pd.to_numeric(weather['最高气温'].str.replace('℃', '')) 76 weather['最低气温'] = pd.to_numeric(weather['最低气温'].str.replace('℃', '')) 77 78 # 绘制散点图 79 plt.scatter(weather['最高气温'], weather['最低气温']) 80 plt.xlabel('maximum ') 81 plt.ylabel('minimum ') 82 plt.title('Scatter plot of the highest and lowest temperatures in January 2022 in Beijing') 83 plt.show()
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
2.在完成此设计过程中,得到哪些收获?以及要改进的建议
通过对2022年北京天气的爬虫分析,我们可以更好地了解北京的天气情况,为冬奥会的赛事安排提供参考和保障。同时,这也为我们探索更多的数据分析和预测提供了新的思路和方向。
对北京2022年全年的天气数据经过分析和可视化,可以得到以下结论:
北京2022年全年的最高气温呈现出明显的季节性变化,夏季最高气温较高,冬季最高气温较低,春秋季节气温适中。同时,最低气温也呈现出相似的季节性变化。
风力级数主要分布在1-3级之间,4级以上的风比较少。
从天气类型的分布来看,晴天和多云天气较多,雨天和雪天的出现次数相对较少。
随着时间的推移,最高气温和最低气温都呈现出逐渐升高或降低的趋势,但是趋势并不十分明显。
总的来说,我们得到的结论基本符合预期的目标,也为我们更好地了解北京2022年全年的天气情况提供了有价值的参考。
在完成此设计过程中,我们得到了以下收获:
学会了如何使用Python进行数据爬取、数据处理和数据可视化。
学会了如何使用pandas库和matplotlib库对数据进行处理和可视化。
加深了对Python编程语言和数据分析的理解和认识。
对于数据处理和可视化方面的知识有了更深入的了解和掌握。
改进的建议:
在数据处理和可视化方面,可以进一步提高自己的技能和水平,以便更好地应对更加复杂的数据分析任务。
在爬取网页数据时,应该注意网站的反爬机制,避免被封IP等情况的发生。
在数据分析过程中,应该注意数据的质量和准确性,以避免分析结果的偏差和误差。
