

Sqoop Mysql导入Hive完整命令参数解析
sqoop是常用的 关系数据库离线同步到数仓的 工具
sqoop导入有两种方式:
1)直接导入到hdfs,然后再load到表中
2)直接导入到hive中
一、直接导入到hdfs,然后再load到表中
1:先将mysql一张表的数据用sqoop导入到hdfs中
将 test 表中的前10条数据导 导出来 只要id name 和 teset 这3个字段
数据存在 hdfs 目录 /user/hdfs 下
bin/sqoop import \ --connect jdbc:mysql://127.0.0.1:3306/dbtest \ --username root \ --password root \ --query 'select id, name,text from test where $CONDITIONS LIMIT 10' \ --target-dir /user/hadoop \ --delete-target-dir \ --num-mappers 1 \ --compress \ --compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--direct \ --fields-terminated-by '\t'
如果导出的数据库是mysql 则可以添加一个 属性 --direct 该属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
2:启动hive 在hive中创建一张表
drop table if exists default.hive_test ; create table default.hive_test( id int, name string, text string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中 (导入后,此时hdfs 中原数据没有了)
load data inpath '/user/hadoop' into table default.hive_test ;
4:查询 hive_test 表
select * from hive_test;
二、直接导入到hive中
1、创建一个文件 vi havetest.sql 编辑文件 vi havetest.sql
use test; drop table if exists test.hive_test ; create table test.hive_test( id int, name string, text string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
2、在 启动hive的时候 执行 sql脚本
hive -f /root/hivetest.sql
[root@cdh01 ~]# hive -f /root/hivetest.sql WARNING: Use "yarn jar" to launch YARN applications. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-common-2.1.1-cdh6.3.2.jar!/hive-log4j2.properties Async: false OK Time taken: 4.816 seconds OK Time taken: 0.19 seconds OK Time taken: 0.725 seconds [root@cdh01 ~]#
3、执行sqoop直接导入hive的功能 IP不能是localhost
sqoop import \ --connect jdbc:mysql://IP:3306/test \ --username root \ --password root \ --table test \ --fields-terminated-by '\t' \ --delete-target-dir \ --num-mappers 1 \ --hive-import \ --hive-database test \ --hive-table hive_test
参数说明 #(必须参数)sqoop 导入,-D 指定参数,当前参数是集群使用队列名称 sqoop import -D mapred.job.queue.name=q \ #(必须参数)链接mysql jdbs参数 xxxx路径/yy库?mysql的参数(多个参数用&隔开) #tinyInt1isBit=false这个参数 主要解决 从Sqoop导入MySQL导入TINYINT(1)类型数据到hive(tinyint),数据为null --connect jdbc:mysql:xxxx/yy?tinyInt1isBit=false \ #(必须参数)用户名、密码、具体的表 --username xx --password xx --table xx \ --delete-target-dir \ #(非必须)系统默认是textfile格式,当然也可以是parquet --as-textfile \ #(非必须)指定想要的列 --columns 'id,title' \ #(必须参数)导入到hive的参数 --hive-import \ #(必须参数)指定分隔符,和hive 的目标表分隔符一致 --fields-terminated-by '\t' \ #(必须参数)hive的库表名 --hive-database xx \ --hive-table xx \ #(必须参数)是不是string 为null的都要变成真正为null --null-string '\\N' --null-non-string '\\N' \ #(非必须)写入到hive的分区信息,hive无分区无需这步 --hive-partition-key dt \ --hive-partition-value $day \ #写入hive的方式 --hive-overwrite \ --num-mappers 1 \ #(必须参数)导入到hive时删除 \n, \r, and \01 -hive-drop-import-delims \ #sqoop完会生成java文件,可以指定文件的路径,方便删除和管理 --outdir xxx
#导入时创建表
--hbase-create-table
hive导入相关参数
--hive-database 库名
--hive-table 表名
--hive-home 重写$HIVE_HOME
--hive-import 插入数据到hive当中,使用hive的默认分隔符
--hive-overwrite 重写插入
--create-hive-table 建表,如果表已经存在,该操作会报错!
--hive-table [table] 设置到hive当中的表名
--hive-drop-import-delims 导入到hive时删除 \n, \r, and \01
--hive-delims-replacement 导入到hive时用自定义的字符替换掉 \n, \r, and \01
--hive-partition-key hive分区的key
--hive-partition-value hive分区的值
--map-column-hive 类型匹配,sql类型对应到hive类型
--query 'select * from test where id >10 and $CONDITIONS' sql语句 $CONDITIONS 必须
执行
[root@cdh01 ~]# sqoop import \ > --connect jdbc:mysql://192.168.230.101:3306/test \ > --username root \ > --password root \ > --table test \ > --fields-terminated-by '\t' \ > --delete-target-dir \ > --num-mappers 5 \ > --hive-import \ > --hive-database test \ > --hive-table hive_test Warning: /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 20/08/14 14:47:43 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7-cdh6.3.2 20/08/14 14:47:43 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 20/08/14 14:47:43 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 20/08/14 14:47:43 INFO tool.CodeGenTool: Beginning code generation Fri Aug 14 14:47:44 CST 2020 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 20/08/14 14:47:45 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 20/08/14 14:47:45 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 20/08/14 14:47:45 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce 20/08/14 14:48:28 INFO mapreduce.Job: Job job_1597287071548_0008 running in uber mode : false 20/08/14 14:48:28 INFO mapreduce.Job: map 0% reduce 0% 20/08/14 14:48:49 INFO mapreduce.Job: map 20% reduce 0% 20/08/14 14:49:08 INFO mapreduce.Job: map 40% reduce 0% 20/08/14 14:49:25 INFO mapreduce.Job: map 60% reduce 0% 20/08/14 14:49:42 INFO mapreduce.Job: map 80% reduce 0% 20/08/14 14:50:00 INFO mapreduce.Job: map 100% reduce 0% 20/08/14 14:50:00 INFO mapreduce.Job: Job job_1597287071548_0008 completed successfully 20/08/14 14:50:00 INFO mapreduce.Job: Counters: 33 20/08/14 14:50:05 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:05 INFO session.SessionState: Created local directory: /tmp/root/d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:05 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/d2cee9ab-0c69-4748-9259-45a1ed4e38b2/_tmp_space.db 20/08/14 14:50:05 INFO conf.HiveConf: Using the default value passed in for log id: d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:05 INFO session.SessionState: Updating thread name to d2cee9ab-0c69-4748-9259-45a1ed4e38b2 main 20/08/14 14:50:05 INFO conf.HiveConf: Using the default value passed in for log id: d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:06 INFO ql.Driver: Compiling command(queryId=root_20200814145005_35ad04c9-8567-4295-b490-96d4b495a085): CREATE TABLE IF NOT EXISTS `test`.`hive_test` ( `id` INT, `name` STRING, `text` STRING) COMMENT 'Imported by sqoop on 2020/08/14 14:50:01' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\011' LINES TERMINATED BY '\012' STORED AS TEXTFILE 20/08/14 14:50:11 INFO hive.metastore: HMS client filtering is enabled. 20/08/14 14:50:11 INFO hive.metastore: Trying to connect to metastore with URI thrift://cdh01:9083 20/08/14 14:50:11 INFO hive.metastore: Opened a connection to metastore, current connections: 1 20/08/14 14:50:11 INFO hive.metastore: Connected to metastore. 20/08/14 14:50:12 INFO parse.SemanticAnalyzer: Starting Semantic Analysis 20/08/14 14:50:12 INFO parse.SemanticAnalyzer: Creating table test.hive_test position=27 20/08/14 14:50:12 INFO ql.Driver: Semantic Analysis Completed 20/08/14 14:50:12 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 20/08/14 14:50:12 INFO ql.Driver: Completed compiling command(queryId=root_20200814145005_35ad04c9-8567-4295-b490-96d4b495a085); Time taken: 6.559 seconds 20/08/14 14:50:12 INFO lockmgr.DummyTxnManager: Creating lock manager of type org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager 20/08/14 14:50:12 INFO imps.CuratorFrameworkImpl: Starting 20/08/14 14:50:12 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-cdh6.3.2--1, built on 11/08/2019 13:15 GMT 20/08/14 14:50:12 INFO zookeeper.ZooKeeper: Client environment:host.name=cdh01 20/08/14 14:50:12 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_202 20/08/14 14:50:12 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation 20/08/14 14:50:12 INFO zookeeper.ZooKeeper: Client environment:java.home=/usr/java/jdk1.8.0_202/jre 20/08/14 14:50:15 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 20/08/14 14:50:15 INFO exec.StatsTask: Executing stats task 20/08/14 14:50:15 INFO hive.metastore: Closed a connection to metastore, current connections: 0 20/08/14 14:50:15 INFO hive.metastore: HMS client filtering is enabled. 20/08/14 14:50:15 INFO hive.metastore: Trying to connect to metastore with URI thrift://cdh01:9083 20/08/14 14:50:15 INFO hive.metastore: Opened a connection to metastore, current connections: 1 20/08/14 14:50:15 INFO hive.metastore: Connected to metastore. 20/08/14 14:50:16 INFO hive.metastore: Closed a connection to metastore, current connections: 0 20/08/14 14:50:16 INFO hive.metastore: HMS client filtering is enabled. 20/08/14 14:50:16 INFO hive.metastore: Trying to connect to metastore with URI thrift://cdh01:9083 20/08/14 14:50:16 INFO hive.metastore: Opened a connection to metastore, current connections: 1 20/08/14 14:50:16 INFO hive.metastore: Connected to metastore. 20/08/14 14:50:16 INFO exec.StatsTask: Table test.hive_test stats: [numFiles=5, numRows=0, totalSize=72, rawDataSize=0, numFilesErasureCoded=0] 20/08/14 14:50:16 INFO ql.Driver: Completed executing command(queryId=root_20200814145013_1557d3d4-f1aa-4813-be67-35f865ce527f); Time taken: 2.771 seconds OK 20/08/14 14:50:16 INFO ql.Driver: OK Time taken: 3.536 seconds 20/08/14 14:50:16 INFO CliDriver: Time taken: 3.536 seconds 20/08/14 14:50:16 INFO conf.HiveConf: Using the default value passed in for log id: d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:16 INFO session.SessionState: Resetting thread name to main 20/08/14 14:50:16 INFO conf.HiveConf: Using the default value passed in for log id: d2cee9ab-0c69-4748-9259-45a1ed4e38b2 20/08/14 14:50:16 INFO session.SessionState: Deleted directory: /tmp/hive/root/d2cee9ab-0c69-4748-9259-45a1ed4e38b2 on fs with scheme hdfs 20/08/14 14:50:16 INFO session.SessionState: Deleted directory: /tmp/root/d2cee9ab-0c69-4748-9259-45a1ed4e38b2 on fs with scheme file 20/08/14 14:50:16 INFO hive.metastore: Closed a connection to metastore, current connections: 0 20/08/14 14:50:16 INFO hive.HiveImport: Hive import complete. 20/08/14 14:50:16 INFO hive.HiveClientCommon: Export directory is contains the _SUCCESS file only, removing the directory. 20/08/14 14:50:16 INFO imps.CuratorFrameworkImpl: backgroundOperationsLoop exiting 20/08/14 14:50:16 INFO zookeeper.ZooKeeper: Session: 0x173e5b94d6d13c0 closed 20/08/14 14:50:16 INFO CuratorFrameworkSingleton: Closing ZooKeeper client. 20/08/14 14:50:16 INFO zookeeper.ClientCnxn: EventThread shut down

4、查看结果
hive> select * from hive_test; OK 1 name1 text1 2 name2 text2 3 name3 text3 4 name4 text4 5 中文 测试 Time taken: 0.668 seconds, Fetched: 5 row(s) hive>
通过sqoop显示mysql数据库列表
sqoop-list-databases --connect jdbc:mysql://127.0.0.1:3306 --username root --password root
sqoop-list-tables --connect jdbc:mysql://127.0.0.1:3306 --username root --password root
[root@cdh01 ~]# sqoop-list-databases --connect jdbc:mysql://127.0.0.1:3306 --username root --password root Warning: /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 20/08/14 14:41:57 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7-cdh6.3.2 20/08/14 14:41:57 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 20/08/14 14:41:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Fri Aug 14 14:41:58 CST 2020 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. information_schema metastore mysql performance_schema scm sys test [root@cdh01 ~]#
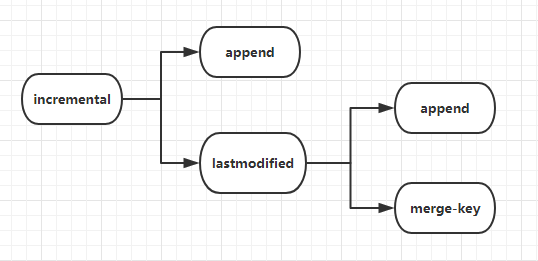
3、导入
1.append方式
2.lastmodified方式,必须要加--append(追加)或者--merge-key(合并,一般填主键)
Mysql创建表、数据
-- ---------------------------- -- Table structure for `data` -- ---------------------------- DROP TABLE IF EXISTS `testdata`; CREATE TABLE `testdata` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` char(20) DEFAULT NULL, `last_mod` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of data -- ---------------------------- INSERT INTO `testdata` VALUES ('1', '1', '2019-08-28 17:34:51'); INSERT INTO `testdata` VALUES ('2', '2', '2019-08-28 17:31:57'); INSERT INTO `testdata` VALUES ('3', '3', '2019-08-28 17:31:58');
导入全部数据到HIVE
sqoop import \ --connect jdbc:mysql://192.168.230.101:3306/test \ --username root \ --password root \ --table testdata \ --fields-terminated-by '\t' \ --delete-target-dir \ --num-mappers 1 \ --hive-import \ --hive-database test \ --hive-table testdata
执行结果
[root@cdh01 ~]# sqoop import --connect jdbc:mysql://192.168.230.101:3306/test --username root --password root --table testdata --fields-terminated-by '\t' --delete-target-dir --num-mappers 1 --hive-import --hive-database test --hive-table testdata hive> select * from testdata; OK 1 1 2019-08-28 17:34:51.0 2 2 2019-08-28 17:31:57.0 3 3 2019-08-28 17:31:58.0 Time taken: 0.192 seconds, Fetched: 3 row(s) hive>
增量导入--append方式导入
Mysql 插入2条记录 INSERT INTO `testdata` VALUES ('4', '4', '2020-08-28 17:31:57'); INSERT INTO `testdata` VALUES ('5', '5', '2020-08-28 17:31:58');
--last-value 3,意味mysql中id为3的数据不会被导入
--targrt-dir的值设置成hive表数据文件存储的路径
sqoop import \ --connect jdbc:mysql://192.168.230.101:3306/test \ --username root \ --password root \ --table testdata \ --fields-terminated-by '\t' \ --num-mappers 1 \ --hive-import \ --hive-database test \ --hive-table testdata \ --target-dir /user/root/test \ --incremental append \ --check-column id \ --last-value 3
执行结果
[root@cdh01 ~]# sqoop import --connect jdbc:mysql://192.168.230.101:3306/test --username root --password root --table testdata --fields-terminated-by '\t' --num-mappers 1 --hive-import --hive-database test --hive-table testdata --target-dir /user/root/test --incremental append --check-column id --last-value 3 hive> select * from testdata; OK 1 1 2019-08-28 17:34:51.0 2 2 2019-08-28 17:31:57.0 3 3 2019-08-28 17:31:58.0 4 4 2020-08-28 17:31:57.0 5 5 2020-08-28 17:31:58.0 Time taken: 0.192 seconds, Fetched: 5 row(s) hive>
注意
sqoop import \ --connect jdbc:mysql://192.168.230.101:3306/test \ --username root \ --password root \ --table testdata \ --fields-terminated-by '\t' \ --num-mappers 1 \ --hive-import \ --hive-database test \ --hive-table testdata \ --target-dir /user/root/test \ --incremental lastmodified \ --merge-key id \ --check-column last_mod \ --last-value '2019-08-30 17:05:49'
参数 说明 –incremental lastmodified 基于时间列的增量导入(将时间列大于等于阈值的所有数据增量导入Hadoop) –check-column 时间列(int) –last-value 阈值(int) –merge-key 合并列(主键,合并键值相同的记录)
以上语句使用 lastmodified 模式进行增量导入,结果报错:
错误信息:--incremental lastmodified option for hive imports is not supported. Please remove the parameter --incremental lastmodified
错误原因:Sqoop 不支持 mysql转hive时使用 lastmodified 模式进行增量导入,但mysql转HDFS时可以支持该方式!
使用 --incremental append
sqoop import \ --connect jdbc:mysql://192.168.230.101:3306/test \ --username root \ --password root \ --table testdata \ --fields-terminated-by '\t' \ --num-mappers 1 \ --hive-import \ --hive-database test \ --hive-table testdata \ --target-dir /user/root/test \ --incremental append \ --merge-key id \ --check-column last_mod \ --last-value '2019-08-30 17:05:49'
可以增量,但是无法合并数据
hive> select * from testdata; OK 1 1 2019-08-28 17:34:51.0 2 2 2019-08-28 17:31:57.0 3 3 2019-08-28 17:31:58.0 4 4 2020-08-28 17:31:57.0 5 5 2020-08-28 17:31:58.0 Time taken: 0.192 seconds, Fetched: 5 row(s) hive> select * from testdata; OK 1 1 2019-08-28 17:34:51.0 2 2 2019-08-28 17:31:57.0 3 3 2019-08-28 17:31:58.0 4 4 2020-08-28 17:31:57.0 5 5 2020-08-28 17:31:58.0 2 222 2020-08-14 19:13:06.0 3 333 2020-08-14 19:13:04.0 4 4 2020-08-28 17:31:57.0 5 5 2020-08-28 17:31:58.0 Time taken: 0.172 seconds, Fetched: 9 row(s) hive>
由于 HDFS 不支持修改文件,sqoop 的 --incremental 和 --hive-import 不能同时使用,分开进行 import 和 merge 这两个步骤。
完

 浙公网安备 33010602011771号
浙公网安备 33010602011771号