

此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
该作业采用的编程语言为Python,其代码的地址为:https://e.coding.net/xucancan1/words_count/words_count.git
我用的是git和tortoisgit将文件传入到coding.net上的
功能1 小文件输入
功能2 支持命令行输入英文作品的文件名
功能3 支持命令行输入存储有英文作品文件的目录名
功能4 从控制台读入英文单篇作品
一. 功能1
重难点:
(1)对于第一个题,如何把文件名输入到命令行参数上,让命令行的参数来进行处理问题?注意这里要与input()函数的输入区分开来
如果我们使用input()函数获得输入数据而进行处理,这种在命令行上运行时,会要求敲两次回车键才能执行,第一行输入的数据都输入到了sys.argv中,而第二行输入的数据,才是被输入到了input()了,然后通过input()来处理,虽然结果相同,但显然不符合题意。
正确做法:引入sys包,通过sys,argv数组来接收输入的文件名以及其他参数 (ps:不是用input来接受文件名进行处理)
(2)如何通过命令行输入的文件名来读取对应的文件?
通过使用sys.argv[0],sys.argv[1],sys.argv[2],来进行操作,一般sys.argv[0]指的是pthon文件名的路径,sys.argv[1],sys.argv[2],才是接下来的要处理的参数
对于打开文件用open()函数:f=open("sys.argv[0]",''r",encoding="UTF-8"),这里有一个很容易错的问题,那就是这个需要加一个utf-8,当时在这个问题卡了很久,不明白问题所在,通过百度才明白。
由于.py文件默认ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时会报错,所以在open()函数里加‘encoding='utf-8’,意为以字节为单位对Unicode进行编码保存,这样遇到中文也不会出错。
(3)如何将文件的内容分割成单词,然后存储到列表中?
我用的是split()函数按照一定的规则进行分割;首先将文件统一转换成小写(大写也行)进行预处理,避免重复计算,然后用list()函数将每个单词列表化和filter()函数消除列表中的空格
(4)如何统计总单词数和统计各个单词出现的次数?
对于这个问题,我本来想着用一个for循环来遍历列表。将每个单词出现的个数用字典来统计的,但是后来想了一下这个有点浪费体力,然后刚好有一个collection包里有一个counter()函数,直接统计列表中的单词,返回的结果是一个元组的列表,刚好符合我要的功能。接着就是遍历这个字典统计各个单词的出现的个数以及进行打印。
(5)如何统计单词数出现最多的前n个单词的列表?
这里其实可以使用sort函数对字典的键值进行排序,然后选择只打印前10个单词以及出现的个数,但是这样多了一个for循环判断,我果断放弃了,又选择一个一个内置函数most_common(10),这个函数好处作用是统计了前10的单词,返回是一个字典,然后只需打印遍历这个字典就行。
重要代码:
#功能1:小文件输入。 def count_words(filename): #print("c") s=".txt" if s in filename: path=filename else: path=filename+s try: with open(path,"r",encoding="UTF-8") as f_obj: content = f_obj.read().lower() except FileNotFoundError: msg = "sorry,the file " + filename + " does not exist." print(msg) else: #为避免重复计算大小写单词,所以将所有单词全部转换为小写 lists= re.split(r'[",", ".", "!", "?", ";", ""","--","\n"]', content) #通过正则表达式和split()函数生成文件内容的列表 lists= list(filter(None, lists)) #消除列表中的空格 words=Counter(lists) #遍历字典,统计键值对数 num=0 for key,value in words.items(): num+=1 #功能1不输出words,功能2输出words if sys.argv[1]=="-s": print("total"+" "+str(num)) else: print("total"+" "+str(num)+" words") #most_common(n)返回统计单词数出现最多的前n个单词列表 maxwords=words.most_common(10) for i in maxwords: print("%-10s%5d"%(i[0],i[1]))
执行效果截图:
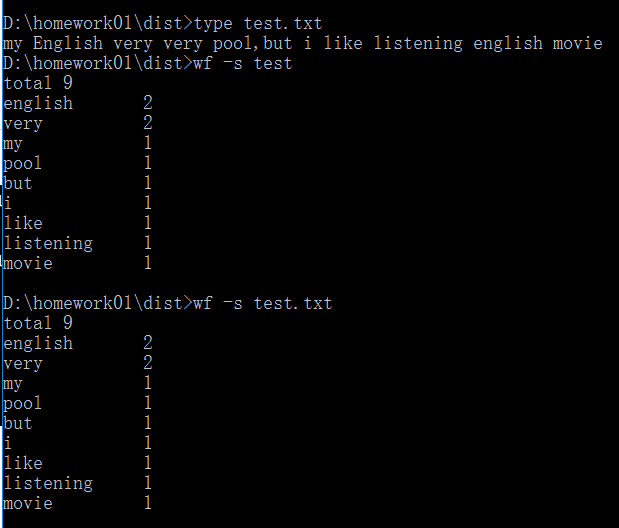
二. 功能2
重难点:
(1)如何支持直接输入文件名,而不需要加后缀名.txt和-s就可以统计文件的各个单词次数呢?
对于这个问题,要与第一题区分,第一题是加-s就运行执行这个文件,我们只要判断一下sys,argv[1]是否是-s,如果有,就执行第一个功能,如果没有就执行第二个功能,接着然后在输入的文件后面添加一个.txt后缀。
(2)如何处理这个文件的大小写单词和非字母对单词词统计的影响?
对于这两个问题,当统计次数时,首先解决大小写的影响,我用的是.lower()函数将全部单词转化为小写,(这里也可以用.upper()函数转换成大写),这样做可以避免重复计算单词。其次是解决非字母的字符,我使用的是findall(r"[a-z0-9^-]+",f.read().lower())函数来处理的,它的作用是通过正则表达式和findall()函数排除不符合的字符,从而生成文件内容的列表,其实我后来想了一下,其实也可以用replace()函数把那些不符合单词的字符替换掉。
(3)有关功能1和功能2的区别?
功能1和功能2除了上述的输入有区别外,还有输出的区别:功能2是要输出“words”这个单词的,功能1不输出该单词。
重要代码:
#功能2:支持命令行输入英文作品的文件名 def count_words02(name): # 判断传入的命令行参数后缀部分是否含有.txt d=".txt" if d in name: path=name else: #若没有,要加上,再作为打开路径 path=name+d f=open(path,"r",encoding="utf-8") lists=findall(r"[a-z0-9^-]+",f.read().lower())#通过正则表达式和findall()函数生成文件内容的列表 words=Counter(lists) #遍历字典,统计键值对数 num=0 for key,value in words.items(): num+=1 #功能1不输出words,功能2输出words if sys.argv[1]=="-s": print("total"+" "+str(num)) else: print("total"+" "+str(num)+" words") #most_common(n)返回计数值最大的n个元素的元素列表 maxwords=words.most_common(10) for i in maxwords: print("%-10s%5d"%(i[0],i[1]))
执行效果截图:
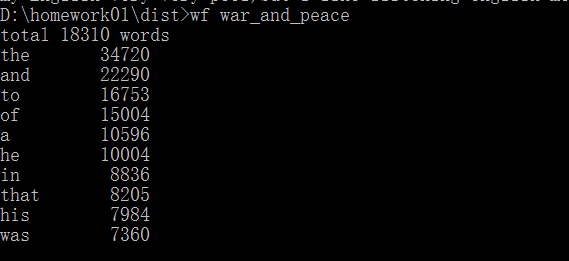
三.功能3
重难点:
(1)如何判断你输入的参数是文件还是文件夹?
对于这个问题,我百度了一下,首先需要os这个包,这个包里面带了一个os.path.isdir()函数,它的作用是用于判断某一对象(需提供绝对路径)是否为目录,这个要与os.path.isfile()函数区分开来他的作用是判断对象是否为一个文件,具体用法区别详见:https://blog.csdn.net/m0_37443131/article/details/81231763
(2)如何获取当前.txt文件的绝对路径?
这个问题困扰了很久,我当时想取指定文件或目录的绝对路径(完整路径),想起OS模块不是有个取文件绝对路径的方法os.path.abspath(),结果出现了很大的问题。
例如:获取文件‘test.py’的完整路径
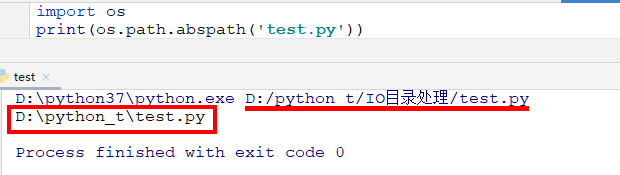
test.py的完整路径是:D:\python_t\IO目录处理\test.py,而不是D:\python_t\test.py,看到这个结果我就泪奔了,不是取绝对路径么?怎么不是真实的完整路径?上级目录不见了?很多疑惑?
其实通过这个例子,我们可以看出os.path.abspath()函数无法获取指定文件的绝对路径,而是需要加文件路径os.path.abspath(path),所以我为了获得绝对路径,分为了两个部分,第一部分是获得该文件夹的上级目录 domain = os.path.abspath("."), domain获取的是当前文件的上一级目录文件夹,然后加上当前文件夹;第二部分是获得需要访问的.txt文件,两个部分加起来,就是.txt文件的绝对路径。
详细用法:https://blog.csdn.net/funnypython/article/details/78733115
(3)在获得文件夹路径时,需要把所有的\\更改为/
因为python返回路径时目录级别都是\\这个形态的,需要将他转换成 / 这个形态,用了replace()函数替换
(4)如何统计文件夹下的.txt文件的单词出现次数?
由于获得了该文件夹的绝对路径,再加上需要访问的.txt文件,两部分加起来就是该.txt文件的绝对路径,然后用open()函数,对这个文件进行读取,去除一些不符合单词的字符,然后用counter()函数统计单词出现的个数。
重要代码:
#功能3 elif os.path.isdir(sys.argv[1]): #print(sys.argv[1]) filecount(sys.argv[1])
#功能3:传入文件夹,批量统计文件夹下各文件的单词的个数 def filecount(filename): files=os.listdir(filename)#将文件夹下的文件列表化 # print(files) #输出该文件下所有的文件 print("\n") domain = os.path.abspath(".") #获取文件的上一级目录文件夹,输出的是D:/homework01/ domain = domain.replace('\\', '/') + '/' + filename + '/' #将所有的\\变成“/”,且加上当前文件,返回相当于D:/homework01/book/ for file in files: #遍历文件下的所有文件 path=domain+file #这才是该文件的真实路径,path=D:/homework01/book/file.txt (filename1, extension) = os.path.splitext(file)#将文件名与后缀分开,将文件名单列出来 print(filename1) f=open(path,"r",encoding="utf-8") lists=findall(r"[a-z0-9^-]+",f.read().lower())#通过正则表达式和findall()函数生成文件内容的列表 words=Counter(lists) #Counter函数是用来跟踪值出现的次数,以字典的键值对形式存储,其中元素为key,其计数为value #遍历字典,统计键值对数 num=0 for key,value in words.items(): num+=1 print("total"+" "+str(num)+" words") #most_common(n)返回计数值最大的n个元素的元素列表 maxwords=words.most_common(10) for i in maxwords: print("%-10s%5d"%(i[0],i[1])) print('------------------')
执行效果截图:
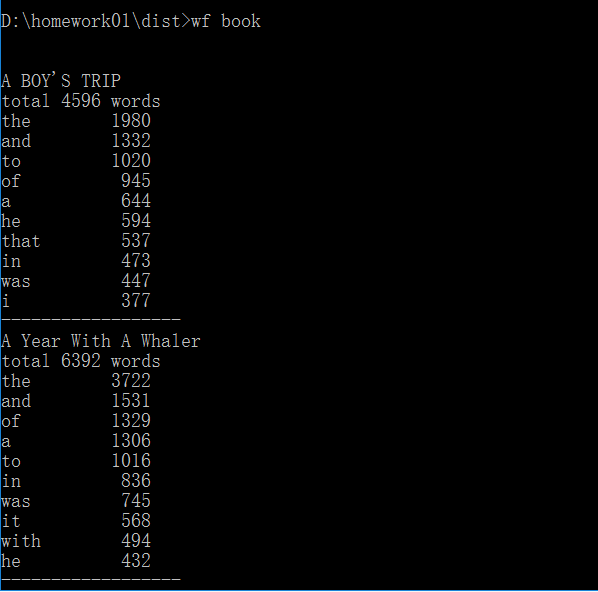
四.功能4
重点难点:
(1)如何对功能4的理解?
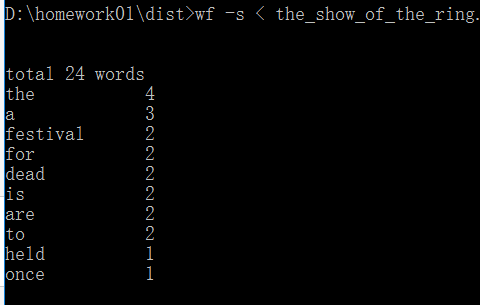
其实开始看这个功能4时,我还蒙,但是看了一下测试用例,我慢慢明白了,首先确定 the_show_of_the_ring是一个文件,其次哪个>wf -s < the_show_of_the_ring,这个<符号是一个重定向符,-s是添加的区别于其他功能的标志,所以题意是统计重定向的文件的单词个数。
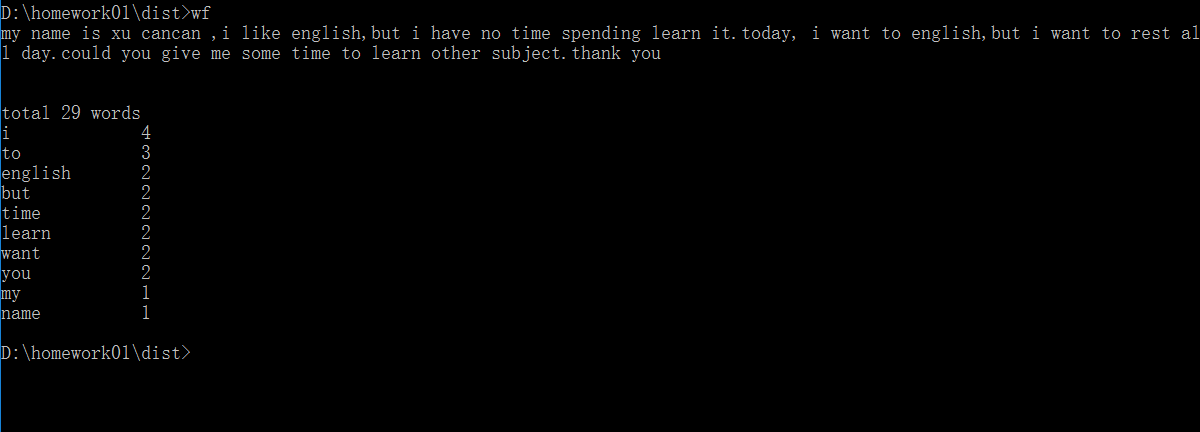
(2)如何在cmd命令台接收一大段英文文章?
首先确定sys.argv数组是不能接受这么大段英文文章的,所以我引用了input()函数,sys.argv用来存储这个.py文件路径,我先判断一下输入,sys.argv数组的里面内容的个数为1,就表明它接下来要输入一段英文文章;接着我用input()函数来接收这段英文。然后通过input()函数接收的英文进行分割处理成单词列表,接下来就是统计单词个数了
重要代码:
#功能4:输入一篇文章统计单词字数 if(len(argv)==1): str = input() str = re.sub('[^a-zA-Z]',' ',str) #sub()函数将不为字母的替换空格 count_words03(str)
(3)如何统计重定向文件的单词,即< the_show_of_the_ring?
对于这个问题,我完全没有头绪,后来通过伟大的百度,查阅了一下windows下文件重定向的相关问题,大概总算明白了是什么回事。然后看到了一个sys.stdin.readline() 函数,这个函数功能是存储重定向的文件名接着去读这个文件的内容,返回这个文件的内容。刚好返回的内容是我们需要的,我们可以通过相关处理变成单词列表,继续统计该列表的单词。
sys.stdin.readline()函数用法详见:https://www.jb51.net/article/169914.htm
(4)如何判别wf.py -s是执行功能4的重定向呢?
这个功能区别于功能1,功能1中的sys.argv数组里面的len(sys.argv)是3,而功能4中的len(sys.argv)数组里面的是2,接下来用sys.stdin.readline() 函数接收重定向的文件,并返回该文件的内容。
重要代码:
#功能1和功能4 elif sys.argv[1]=='-s': if(len(argv) == 3): #执行功能1 #print(sys.argv[2]) count_words(sys.argv[2]) elif(len(argv)==2): #执行功能4:重新定向文件 redirect_words = sys.stdin.readline() # 存储重定向的文件名接着去读这个文件的内容,返回这个文件
重要代码:
#功能4:重定向 def count_words03(string): print("\n") lists = string.replace('\n', ' ').lower().split() # 用空格去掉所有的\n,且转换成小写,进行分割单词 words=Counter(lists) #Counter函数是用来跟踪值出现的次数,以字典的键值对形式存储,其中元素为key,其计数为value #遍历字典,统计键值对数 num=0 for key,value in words.items(): num+=1 print("total"+" "+str(num)+" words") #most_common(n)返回计数值最大的n个元素的元素列表 maxwords=words.most_common(10) for i in maxwords: print("%-10s%5d"%(i[0],i[1])) #定义main函数 def main(argv): #功能4:输入一篇文章统计单词字数 if(len(argv)==1): str = input() str = re.sub('[^a-zA-Z]',' ',str) #sub()函数将不为字母的替换空格 count_words03(str) #功能1和功能4 elif sys.argv[1]=='-s': if(len(argv) == 3): #执行功能1 #print(sys.argv[2]) count_words(sys.argv[2]) elif(len(argv)==2): #执行功能4:重新定向文件 redirect_words = sys.stdin.readline() # 存储重定向的文件名接着去读这个文件的内容,返回这个文件的内容 redirect_words= re.sub('[^a-zA-Z]',' ',redirect_words) count_words03(redirect_words)
执行效果图:
五 功能5
在文件中统计给定的单词长度为m的次数前n个的单词
重难点:
(1)如何解析题目的需求?
我为了把这个功能模块整合到原先设计好的程序框架中,特定对功能5做了标记,这是为了与其他功能的执行区分,用了-h这个标记来执行功能5,剩下的就是功能5的需求进行设计。
(2)如何将两个变量参数输入进去,并且让它们执行相应的功能?
对于这个问题我是用input()函数来接收它们,由于input()函数返回的是字符串类型,所以我用了int()函数将他们强制转换成整形,然后把它们输入到功能5模块中进行处理,接着就是读取文件,将文件内容按照正则表达式分割成单词列表。
#功能5: 在文件中统计给定的单词长度为m的次数前n个的单词 if(sys.argv[1]=="-h"): str1=input() a=int((str1.strip())) str2=input() b=int((str2.strip()))) count_words04(sys.argv[2],a,b)
(3)注意input()函数,这个函数它也接收空格,回车换行等字符,在将它强制转换时,需要用striip()将这些过滤掉,然后才能用int()函数转成整数
(4)如何获得文件中单词长度为m的单词次数前n的单词列表呢?
首先,解决这个问题分为两步,第一步在文件中获取所有单词长度为m的单词;我先用counter()函数统计各个单词的出现的次数,由于counter()函数返回的是单词元组的列表,在这个问题,我开始以为counter()函数返回的是字典,后面造成了一定隐形错误,然后我遍历这个列表,找出所有单词长度为m的单词,接着将它们逐个添加到一个空字典中;第二步在第一步的基础上,统计单词次数前n的单词;由于获得了所有单词长度为m的单词的字典,接着对这些字典的键值进行排序,我本来是想用一个冒泡排序进行排序的,后来想着这样太麻烦了,所以直接用most_common()函数统计出前n的单词 以及次数。
words=Counter(lists) #遍历元组,统计键值对数 num=0 words_dic = {} for key,value in words.items(): d={} if(len(key)==lent): #统计长度为lent的单词 d[key]=value words_dic.update(d) num+=1 print("\n") print("total"+" "+str(num)+" words") print("你选择了长度为"+str(lent)+"的单词") print("统计单词数出现最多的前"+str(n)+"个单词的列表") words_list=Counter(words_dic)
(5)关于most_common()函数的错误用法的血泪史。
错误1:调用most_common()函数有限制,我一直以为可以通过字典来调用它,然后我一直运行,不停的报错,(ps:我英语差,当时看不懂错误提示)然后我将错误提示提交给百度,搜查相关的问题,然后知道了问题关键所在,原来是most_commom()函数的用法出现问题,接着我查了一下most_commom()函数的用法,字典不能调用它,列表可以调用它。然后我就再次使用counter()函数,将字典转成带有元组的列表,这样就可以使用most_commom()函数了。
错误2:most_common()函数只返回前n个单词,它不管第n+1个单词是否与第n个单词相等,这样造成的后果会丢掉那些原本第n+1个单词和第n个单词相等的单词。
错误运行结果截图:
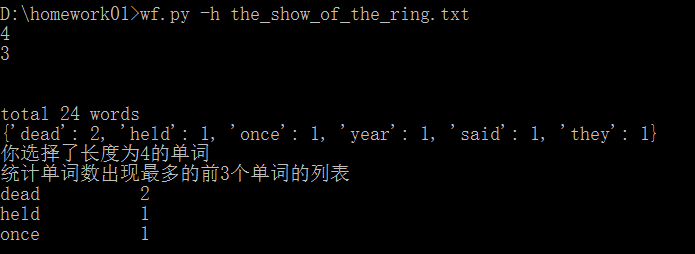
从上图可以看出,长度为4的单词排序,取单词数出现前3的单词,第4,第5,第6的单词个数与第3的单词个数相等,但是它们被舍弃了,没有被显示,这种返回结果非常不好。
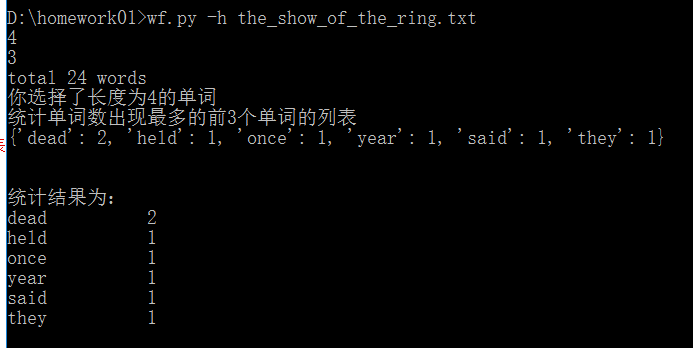
针对上面的出现的问题,我重新定义了一个get_count(dct, n)函数来解决,当相等的情况下,相等的需要全部被显示出来。
#返回统计单词数出现最多的前n个单词列表 def get_count(dct, n): data = dct.most_common() val = data[n-1][1] return list(takewhile(lambda x: x[1] >= val, data))
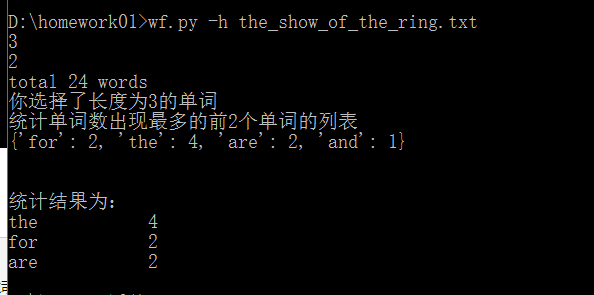
正确运行结果截图:
重要代码:
def main(argv): #功能5: 在文件中统计给定的单词长度为m的次数前n个的单词 if(sys.argv[1]=="-h"): str1=input() a=int((str1.strip())) str2=input() b=int((str2.strip())) count_words04(sys.argv[2],a,b)
#功能5:查找特定长度单词的个数 def count_words04(filename,lent,n): s=".txt" if s in filename: path=filename else: path=filename+s try: with open(path,"r",encoding="UTF-8") as f_obj: content = f_obj.read().lower() except FileNotFoundError: msg = "sorry,the file " + filename + " does not exist." print(msg) else: #为避免重复计算大小写单词,所以将所有单词全部转换为小写 lists= re.split(r'[",", ".", "!", "?", ";", ""","--","\n"]', content) #通过正则表达式和split()函数生成文件内容的列表 lists= list(filter(None, lists)) #消除列表中的空格 words=Counter(lists) #遍历元组,统计键值对数 num=0 words_dic = {} for key,value in words.items(): d={} if(len(key)==lent): #统计长度为lent的单词 d[key]=value words_dic.update(d) num+=1 print("total"+" "+str(num)+" words") print("你选择了长度为"+str(lent)+"的单词") print("统计单词数出现最多的前"+str(n)+"个单词的列表") print(words_dic) words_list=Counter(words_dic) # 本来想用most_common(n)返回统计单词数出现最多的前n个单词列表,后来当有多个单词相等的时候,这个函数只取前n个,其实第n+1个也是跟第n值相等,但是这个函数不能实现 maxwords=get_count(words_list,n) #maxwords=words_list.most_common(n) print("\n") print("统计结果为:") for i in maxwords: print("%-10s%5d"%(i[0],i[1]))
执行结果截图:
6.psp
| 功能 | 预计花费时间 | 实际花费时间 | 时间差 | 原因 |
| 功能1 | 80min | 123min | 43min | 对python命令台输入输出不太熟悉 |
| 功能2 | 60min | 105min | 45min | 对参数输入没把握好,且处理后缀名花了一段时间 |
| 功能3 | 90min | 146min | 76min | 对于获取绝对路径不理解,花了很久解决这个问题 |
| 功能4 | 100min | 152min | 52min | 首先对题目的解析花了一段时间,且设计相关功能也花了很多时间 |
| 功能5 | 40min | 60min | 20min | 功能测试,以及功能设计需求超出了时间 |
| 测试 | 20min | 123min | 103min | 对于python文件需要转换成.exe文件,安装pyinstaller严重超出了时间 |
7.总结
完成这个部分作业,我大概分为了三个阶段:
第一阶段熟悉安装使用git和totorisgit,熟练将文件从coding.net或github中pull下来或者push到云端。
第二阶段1-5功能代码设计的实现
第三阶段将.py文件转换成.exe文件
对于第一阶段,说句实话,花了很久时间才把totorisegit这个工具学会(当然也可以用git命令行),用它可以直接push&pull代码,而且可以将代码push到云端存储着,真的很方便,虽然在学习使用工具这个过程中摸索地很痛苦,但是学会了后,我感觉totorisgit工具和云端仓库真的太nice了!
对于第二个阶段功能代码设计,python很多方法的实现完全可以调用相关函数来执行,我在这个问题上由于python知识储备不是很足,所以花了很多时间研究其中的函数,最终才将相关的函数运用到实际操作中。
对于第三阶段下载安装pyinstaller,将.py文件转换成.exe文件,这个我也摸索了很久,主要是在.exe文件的查询上,一开始不知道它转化到哪里了,后来查询百度,发现它存到了dist文件中
通过这次的编程实践,让我学习到了很多以前没有学到的知识,同时也让我知道了自己的不足,我还需要不停地努力!
关于totoisgit和git安装是相关问题:
1.Git将本地代码推到远程仓库的步骤:[https://blog.csdn.net/weixin_39910711/article/details/89955544]
2.利用totorisgit在github上下载代码:https://blog.csdn.net/zdp072/article/details/51966586
3.远程仓库连接错误时,如何清除连接[https://www.cnblogs.com/wollow/p/10840016.html]
4.认证失败时,怎么办[https://www.jianshu.com/p/c095300d569e]
5.使用Git客户端下载代码的流程[https://blog.csdn.net/wyqwilliam/article/details/82881609]
6.Git clone和Git pull的简要区别[https://www.jianshu.com/p/c6a0397ec6f5]
7.如何将.py文件转化为可执行的.exe文件:https://blog.csdn.net/qq_36604847/article/details/81509113

 浙公网安备 33010602011771号
浙公网安备 33010602011771号