
protobuf逆向解析 Python 或者 C# application/grpc-web+proto
先说解决方案吧,总共有两个解决方法
一:Python 用 blackboxprotobuf 这个模块 它像个万能解析proto的程序,这个很简单 但有个问题 时不时的会遇到解析一个文件需要一个小时以后才解析完 太费时间
先放干货,再去解释,这个代码直接运行即可
import blackboxprotobuf
import requests
import os
import datetime
# 用 blackboxprotobuf 直接解码
os.environ["NO_PROXY"]='s.wanfangdata.com.cn'
#headers={"User-Agent":UserAgent().chrome}
headers={
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Content-Type":"application/grpc-web+proto",
"Origin":"https://s..com.cn",
"host":"s.wanfangdata.com.cn",
"Referer": "https://s..com.cn/paper?q=%E4%BD%9C%E8%80%85%E5%8D%95%E4%BD%8D%3A%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%A6&p=4",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
deserialize_data={
"1": {
"1": "paper",
"2": "作者单位:北京大学",
"5": 1,
"6": 20,
"8": "\u0000"
},
"2": 1
}
message_type={'1': {'type': 'message', 'message_typedef': {
'1': {'type': 'bytes', 'name': ''},
'2': {'type': 'bytes', 'name': ''},
'5': {'type': 'int', 'name': ''},
'6': {'type': 'int', 'name': ''},
'8': {'type': 'bytes', 'name': ''}}, 'name': ''},
'2': {'type': 'int', 'name': ''}}
form_data = bytes(blackboxprotobuf.encode_message(deserialize_data, message_type))
f_data = bytes([0,0,0,0,len(form_data)])+form_data
url='https://s..com.cn/SearchService.SearchService/search'
res = requests.post(url,data=f_data,headers=headers,timeout=10)
response_data,message_type=blackboxprotobuf.protobuf_to_json(res.content[5:-20])
print(response_data)
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
print(message_type)
1.首先编写它
图1
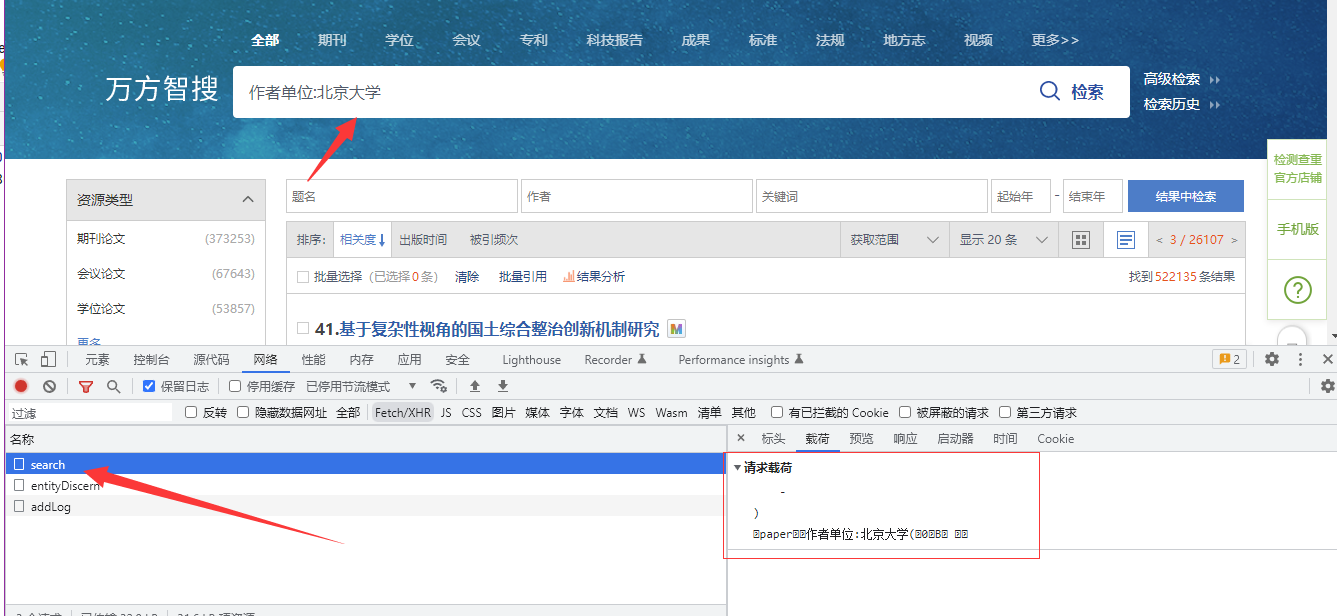
因为看不懂,所以才要用到接下来的宝贝软件: Fiddler
图2

选中的这些右键保存为a.bin 文件,记住 前五位不要,后面再讲为什么
import blackboxprotobuf with open('d://a.bin',mode="rb") as f: proto_info = f.read() print(proto_info) response_data2, message_type2 = blackboxprotobuf.protobuf_to_json(proto_info) print(response_data2) print(message_type2)
图3
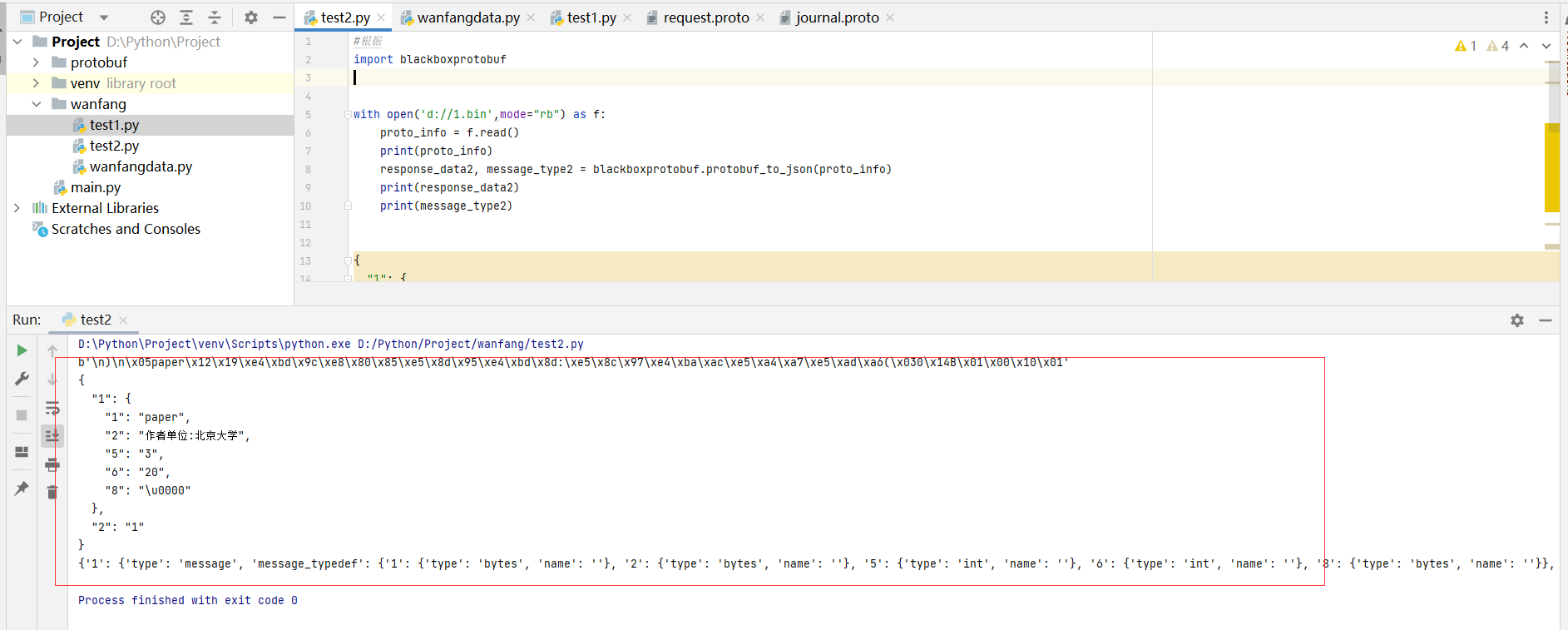
看到这懂了吧
二:安装Proto,写一个检索类A,A里赋值 当成参数 post过去 得到返回数据流, 自己编写解析的一个类B,拿到传回来的bytes[] 后 用这个类B解一下;A与B怎么写下面讲
1. 创建文件夹,request.proto 文件
创建文件夹,request.proto 文件
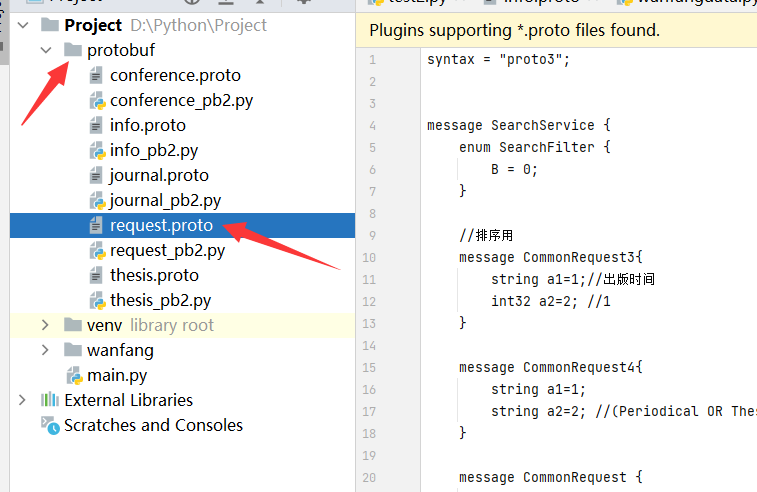
里面是这个
syntax = "proto3"; message SearchService { enum SearchFilter { B = 0; } //排序用 message CommonRequest3{ string a1=1;//出版时间 int32 a2=2; //1 } message CommonRequest4{ string a1=1; string a2=2; //(Periodical OR Thesis OR Conference) } message CommonRequest { string searchType = 1; string searchWord = 2; CommonRequest3 a3=3; CommonRequest4 a4=4; int32 currentPage = 5; int32 pageSize = 6; repeated SearchFilter searchFilter = 8; } enum InterfaceType { // 定义了什么不知道,但是enum必须有一个值就是0 DEFAUTL = 0; } message SearchRequest { CommonRequest commonrequest = 1; // 任意变量名 int32 interfaceType = 2; // 任意变量名 } }
此处写入CMD回车

2. 创建 info.proto
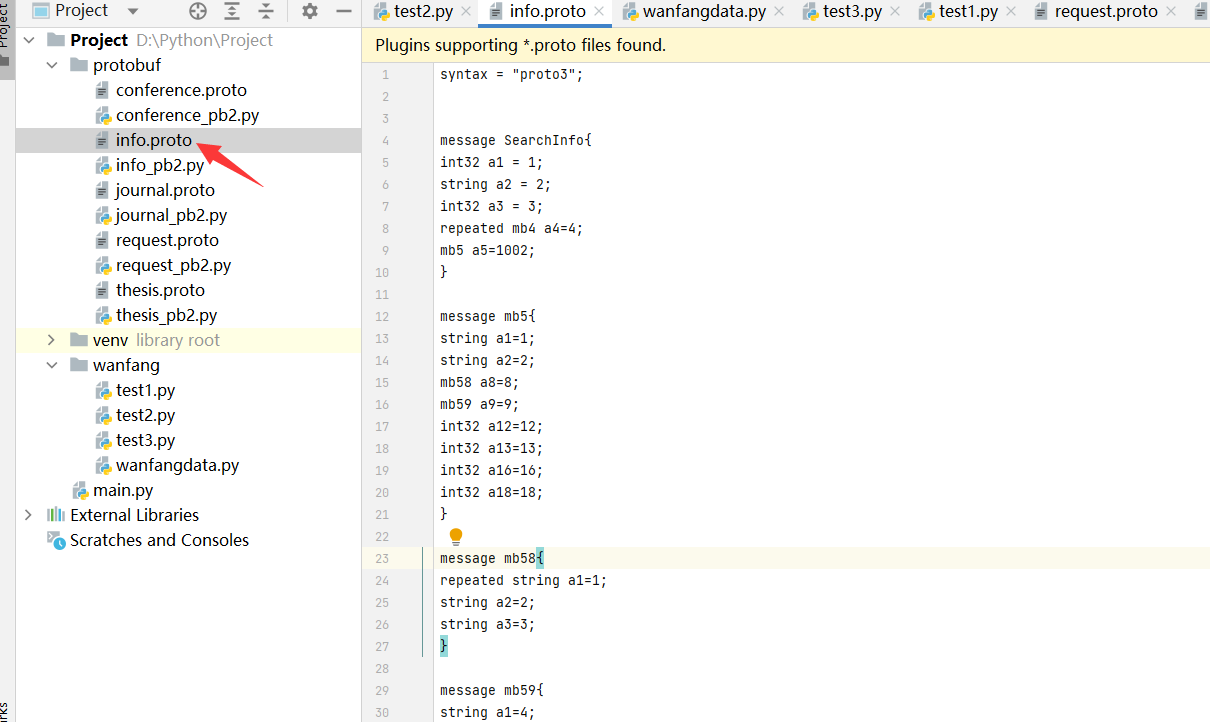
syntax = "proto3"; message SearchInfo{ int32 a1 = 1; string a2 = 2; int32 a3 = 3; repeated mb4 a4=4; mb5 a5=1002; } message mb5{ string a1=1; string a2=2; mb58 a8=8; mb59 a9=9; int32 a12=12; int32 a13=13; int32 a16=16; int32 a18=18; } message mb58{ repeated string a1=1; string a2=2; string a3=3; } message mb59{ string a1=4; } message mb4{ string a1=1; repeated mb42 a2=2; string a3=3; bytes a4=101;//期刊 bytes a5=104;//会议 bytes a6=102;//学位--暂时不查 } message mb4101{ string a1=1; string a2=2; repeated string a3=3; string a4=4; repeated string a5=5; repeated string a6=6; string a8=8; string a9=9; string a10=10; string a12=12; repeated string a13=13; repeated string a16=16; repeated string a18=18; string a20=20; string a22=22; repeated string a24=24; string a25=25; repeated string a27=27; string a28=28; string a29=29; string a30=30; int32 a31=31; int32 a32=32; int32 a33=33; string a34=34; string a35=35; string a36=36; string a37=37; string a38=38; repeated string a39=39; string a40=40; string a41=41; repeated string a42=42; string a43=43; string a44=44; string a45=45; string a46=46; int32 a47=47; int32 a48=48; int32 a49=49; int32 a50=50; string a53=53; string a54=54; string a55=55; int32 a56=56; string a57=57; repeated string a58=58; fixed32 a61=61; int32 a62=62; bytes a66=66; string a67=67; fixed32 a68=68; fixed32 a69=69; } message mb42{ int32 a1=1; int32 a2=2; }
生成py文件,此处CMD
代码:test3.py 运行就可以了
import protobuf.info_pb2 as pbinfo #import protobuf.journal_pb2 as pbjournal # 导包 import protobuf.request_pb2 as pb # 导包 import requests search_request = pb.SearchService.SearchRequest() search_request.commonrequest.searchType = "paper" search_request.commonrequest.searchWord = '作者单位:(北京大学) or 作者单位:(湖北大学)' search_request.commonrequest.pageSize = 20 search_request.commonrequest.currentPage = 1 search_request.commonrequest.a4.a1 = "Type" search_request.commonrequest.a4.a2 = "(Periodical OR Thesis OR Conference)" search_request.commonrequest.a3.a1="出版时间" search_request.commonrequest.a3.a2=1 search_request.commonrequest.searchFilter.append(0) search_request.interfaceType = 1 headers = { 'Referer': 'xxxx', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36', 'Content-Type': 'application/grpc-web+proto', } bytes_body = search_request.SerializeToString() # 构造字节序列的头部 bytes_head = bytes([0, 0, 0, 0, len(bytes_body)]) resp = requests.post(url="https://s..com.cn/SearchService.SearchService/search", data=bytes_head+bytes_body, headers=headers) proto_info = resp.content print('---------------3------------------- PB4 解析的内容和格式') first_parsed2 = pbinfo.SearchInfo() first_parsed2.ParseFromString(proto_info[5:-20]) print(first_parsed2) #print(first_parsed2.a4[0].a5) print(len(first_parsed2.a4)) print('---------------4.2------------------- pbjournal 解析的内容和格式') #first_parsedj2 = pbjournal.JournalInfo() #first_parsedj2.ParseFromString(first_parsed2.a4[1].a4) #print(first_parsedj2)
三 C#解析
运行这两句 编译成cs文件
protoc -I=./ --csharp_out=./ request.proto
protoc -I=./ --csharp_out=./ info.proto
public class bll {#region 根据单位和年下载数据 /// <summary> /// 根据单位和年下载数据 /// </summary> /// <param name="stype">检索类型:issn,org,term 检索式检索</param> /// <param name="stxt">北京大学/1111-1111</param> /// <param name="year">空或者2018</param> public static void CatchInfo(string stype,string stxt, string year = "") {
Console.Write($"{stxt}====开始下载 获取总条数:"); int pageSize = 50; int rowCount = GetRowCount(stype,stxt, year, year); Console.WriteLine($"{rowCount}"); Console.WriteLine(); --后面的我给删了,不能写太全了 } /// <summary> /// 返回总条数 /// </summary> /// <param name="stype">检索类型:issn,org,term 检索式检索</param> /// <param name="stxt">北京大学/1111-1111</param> /// <param name="year">空或者2018</param> /// <returns></returns> static int GetRowCount(string stype, string stxt, string syear, string eyear) { SearchInfo info = GetInfo(stype, stxt, syear, eyear, 1); int count = info.A3; return count; } /// <summary> /// 编辑检索式去检索得到返回数据 /// </summary> /// <param name="stype">检索类型:issn,org,term 检索式检索</param> /// <param name="stxt">北京大学/1111-1111</param> /// <param name="syear"></param> /// <param name="eyear"></param> /// <param name="page"></param> /// <returns></returns> static SearchInfo GetInfo(string stype,string seartxt, string syear, string eyear, int page) { //1.参数 SearchRequest sr = new SearchRequest(); CommonRequest common = new CommonRequest(); common.SearchType = "paper"; string stypr2 = ""; stypr2 = $"作者单位:(\"{seartxt}\")"; common.SearchWord = term; common.CurrentPage = page; common.PageSize = 50; common.SearchFilter.Add(0); CommonRequest4 a4 = new CommonRequest4(); a4.A1 = "Type"; a4.A2 = "(Periodical OR Thesis OR Conference)";//(Periodical OR Thesis OR Conference) common.A4 = a4; CommonRequest3 a3 = new CommonRequest3(); a3.A1 = "出版时间"; a3.A2 = 1; common.A3 = a3; sr.InterfaceType = 1; sr.Commonrequest = common; byte[] byteData = sr.ToByteArray(); //2.参数前加5个0 int d = byteData.Length; byte[] b1 = new byte[] { 0, 0, 0, 0, Convert.ToByte(d) }; byte[] b2 = byteData; byte[] b3 = new byte[b1.Length + b2.Length]; b1.CopyTo(b3, 0); b2.CopyTo(b3, b1.Length); string byteDataStr = Encoding.UTF8.GetString(b3); string url = "https://s..com.cn/SearchService.SearchService/search"; Stream stream = GetHtmlByPostUrl3(url, b3); MemoryStream ms2 = StreamToMemoryStream(stream); //掐头去尾 前5和后20 byte[] btt1 = StreamToBytes(ms2); byte[] btt2 = btt1.Skip(5).Take(btt1.Length - 25).ToArray(); //byte[] btt3 = btt2.Take(btt1.Length - 25).ToArray(); SearchInfo dat2 = SearchInfo.Parser.ParseFrom(btt2);//反序列化 return dat2; } #endregion #region 工具 static Stream GetHtmlByPostUrl3(string url, byte[] byteData, int err = 1) { try { //实例化编码方式 //UTF8Encoding encoding = new UTF8Encoding(); Encoding encoding = Encoding.GetEncoding("utf-8"); //根据请求链接参数需求对参数字符串转为二进制字符组 //byte[] byteData = encoding.GetBytes(postData); //创建请求对象 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Host = "s.wanfangdata.com.cn"; //请求用户代理 request.UserAgent = " Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"; //请求头协议方式 request.Accept = "*/*"; //请求头语言 request.Headers.Add("Accept-Language", "zh-CN,zh;q=0.9"); //请求类型 request.ContentType = "application/grpc-web+proto"; //设置请求数据长度 request.ContentLength = byteData.Length; request.Method = "POST"; request.Referer = "https://s.wanfangdata.com.cn/advanced-search/paper"; request.CookieContainer = new CookieContainer(); //设置请求等待时间 request.Timeout = 100000; request.ReadWriteTimeout = 100000; //将请求到数据放入到流中 Stream reqStream = request.GetRequestStream(); //输出流 reqStream.Write(byteData, 0, byteData.Length); //返回对象 HttpWebResponse objResponse = (HttpWebResponse)request.GetResponse(); Stream streamResponse = objResponse.GetResponseStream(); //关闭流 reqStream.Close(); return streamResponse; } catch (Exception e) { } return null; } static MemoryStream StreamToMemoryStream(Stream stream) { MemoryStream memoryStream = new MemoryStream(); //将基础流写入内存流 const int bufferLength = 1024; byte[] buffer = new byte[bufferLength]; int actual = stream.Read(buffer, 0, bufferLength); while (actual > 0) { // 读、写过程中,流的位置会自动走。 memoryStream.Write(buffer, 0, actual); actual = stream.Read(buffer, 0, bufferLength); } memoryStream.Position = 0; return memoryStream; } static byte[] StreamToBytes(Stream stream) { byte[] bytes = new byte[stream.Length]; stream.Read(bytes, 0, bytes.Length); stream.Seek(0, SeekOrigin.Begin); return bytes; } #endregion }
我是遇到响应类型 application/grpc-web+proto 这个后没见过,才研究的
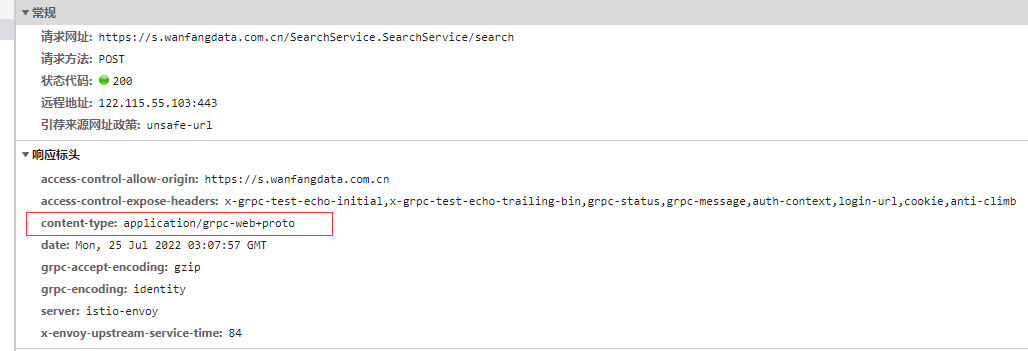
上面有个BUG,
byte[] b1 = new byte[] { 0, 0, 0, 0, Convert.ToByte(d) };
d当d>256的时候就报错了,也就是检索条件长的话就不能检索了,现在补充一下
取余数,并且位移8


 浙公网安备 33010602011771号
浙公网安备 33010602011771号