通俗易懂之flink的窗口、时间和水印
1,经常说的窗口是个啥?
大家平时开发经常会做一些聚合操作,比如count,sum等。在离线跑批的情况下,这些数据都是恒定的,所以不会有什么问题。但是到了实时流的场景,似乎就不太行了。比如小伙伴陆续排队来游乐园玩耍,售票员如果需要做统计,是怎么样的呢?

3个,4个,5个。。。。。。可以知道,在流的世界里,数据是源源不断的过来的,我们是无法进行聚合统计的,因为流是无界的,而在离线情况,这些数据是一个有界的。为了方便对流的数据进行聚合操作,有了窗口的概念。售票员通常的做法是,比如每隔10分钟统计下进去了多少个小伙伴,又或者每进去100个小伙伴就把通道门关闭,等这100个小伙伴玩好了再打开通道门,再进去100个小伙伴。可以看到,window(窗口)是一种可以把无限数据切割为有限数据块的手段。窗口可以是时间驱动的(比如这里的每隔10分钟),也可以是数据驱动的(比如100个小伙伴);
2,窗口的分类
Flink的窗口可以分为三种类型:
滚动窗口:
对应的语义:每隔10分钟统计一次人数
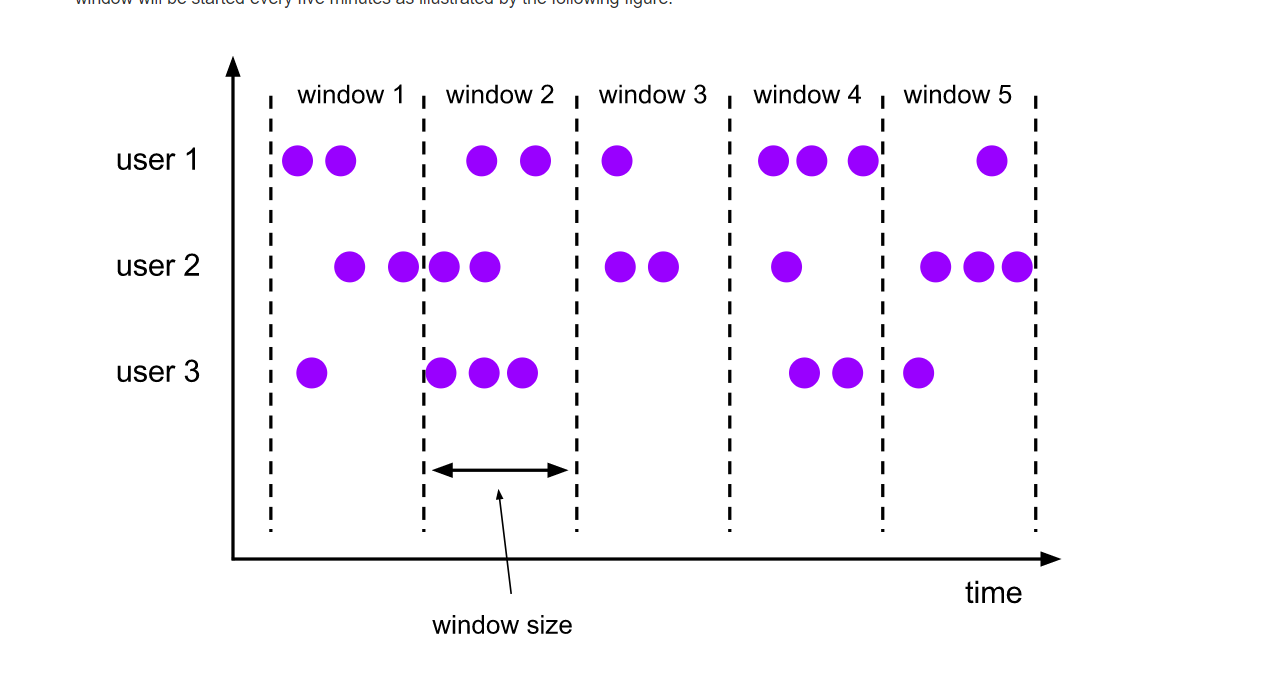
一眼看出来这里的window size就是10分钟,可以看出来数据是不会又重叠的。
滑动窗口:
对应的语义:每隔5分钟统计下前10分钟的人数
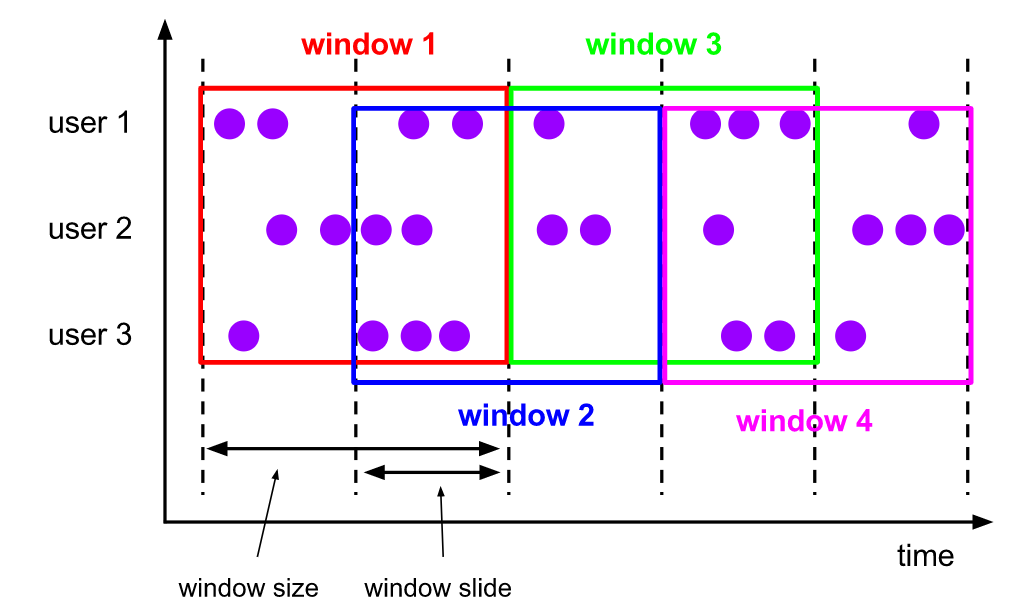
这里每5分钟作为一个滑动,得到一个10分钟的窗口,可以看出来数据是有重叠的。
会话窗口:
这种窗口使用的不多,略过。
3,flink时间的分类
Flink的时间可以分为三类:
事件时间(Event Time)
事件时间是外部原始数据自带的时间,比如{"name":"zhangsan","opreator":"visit","time":"2020-08-31 17:10:15"},这里的time就是事件时间。
处理时间(Processing Time)
事件被处理时系统的当前时间。
摄入时间(Ingestion Time)
事件进入flink的时间。

4,从没听说过的水印又是个什么东东,是为了解决什么问题产生的?
场景:
首先大家都知道kafka是能做到每个分区有序,但是不能做到全局有序的。(当然也可以,就是一个分区,但是这样完全没了分布式的意义了。)那么这种情况下,如何做到数据不乱序呢,水印的出现就是为了解决数据乱序的问题。
水印的本质来说其实就是一个时间戳。如果flink系统出现来了一个WaterMark T,这就意味着时间小于T的事件都已经到达,窗口结束时间和T相同的那个窗口被触发计算。简单的说,水印就是判断是否迟到的标准,同时它也是窗口是否被触发的一个标记。
5,一个案例解决你的困惑。
下面通过一个例子来加深大家对这些概念的理解,前面说了,水印的出现主要是为了解决数据乱序的问题,所以我们看看是如何解决乱序的。比如lisi不停的打卡,假设原始message为”lisi,时间戳”这样的字符串。设置窗口大小为5秒。首先flink会根据系统时间划分出来窗口,这个划分的目的后面解释。只要知道这时的窗口划分是flink系统定义好的,和消息所带的时间无关。划分的结构如下:

现在假设我们允许消息是可以延迟10秒的。这里是为了计算出来水印,水印的计算:
消息的时间-最大的延迟;
下面我们构造一批测试数据:
* lisi,1598839882000 2020-08-31 10:11:22
* lisi,1598839886000 2020-08-31 10:11:26
* lisi,1598839892000 2020-08-31 10:11:32
* lisi,1598839893000 2020-08-31 10:11:33
* lisi,1598839894000 2020-08-31 10:11:34
* lisi,1598839895000 2020-08-31 10:11:35
* lisi,1598839900000 2020-08-31 10:11:40
这里我写了相应的代码,核心的代码为:
//抽取timestamp和生成watermark DataStream<Tuple2<String, Long>> waterMarkStream = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple2<String, Long>>() { Long currentMaxTimestamp = 0L; final Long maxOutOfOrderness = 10000L;// 最大允许的乱序时间是10s SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); /** * 定义生成watermark的逻辑 * 默认100ms被调用一次 */ @Nullable @Override public Watermark getCurrentWatermark() { return new Watermark(currentMaxTimestamp - maxOutOfOrderness); } //定义如何提取timestamp @Override public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) { long timestamp = element.f1; currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp); // System.out.println("key:" + element.f0 + ",eventtime:[" + element.f1 + "|" + sdf.format(element.f1) + "],currentMaxTimestamp:[" + currentMaxTimestamp + "|" + // sdf.format(currentMaxTimestamp) + "],watermark:[" + getCurrentWatermark().getTimestamp() + "|" + sdf.format(getCurrentWatermark().getTimestamp()) + "]"); System.out.println("传入数据:" + element.f1 + "|" + sdf.format(element.f1) + ",此时的水印为:" + getCurrentWatermark().getTimestamp() + "|" + sdf.format(getCurrentWatermark().getTimestamp())); return timestamp; } });
这里主要是定义了水印的计算,下面我们依次看一下每条数据输入进去以后的结果。
在数据源头输入:lisi,1598839882000,此时打印出来:

这里验证了水印的计算就是消息的时间-延迟的时间(用户自己指定),我们是10s,所以水印是2020-08-31 10:11:12.000;
继续输入:lisi,1598839886000,此时打印出来:

水印变为:2020-08-31 10:11:16;
继续输入:lisi,1598839892000,此时打印出来:

水印变为:2020-08-31 10:11:2
注意:这里我们的水印已经和我们第一条输入数据的时间相同了;
继续输入:lisi,1598839893000,此时打印出来:

水印变为:2020-08-31 10:11:23
说明一点,我们的代码在满足水印和窗口的条件是做了排序,然后打印出原始消息的。但是这里迟迟没有打印,而且我们的第一条原始数据都比水印小了。
继续输入:lisi,1598839894000,此时打印出来:

水印变为:2020-08-31 10:11:24。
最开始的数据依旧没有触发,此时已经比最新的数据小了12秒。
那我们再输入会怎样呢:
继续输入:lisi,1598839895000,此时打印出来:

这里发现当我们输入1598839895000这个时间以后,就会触发窗口数据的执行了。此时的水印为:2020-08-31 10:11:25。那么是什么原因触发了这个窗口的执行呢?我们本章节最开始把flink系统时间做了划分的目的是什么呢?

谜底就在这里了!首先我们第一条数据的时间是1598839882000(2020-08-31 10:11:22),在区间为[00:00:20,00:00:25)这个范围,然后当我们的水印时间达到该窗口的最大时间,就会触发这个窗口的执行了。这里当我们的水印达到了2020-08-31 10:11:25,也就是第一条数据所在的窗口的最大值时,那么该窗口的数据就会依次被执行了。该窗口只有一条数据,也就是lisi,1598839882000(2020-08-31 10:11:22)。
同理,第二条数据lisi,1598839886000(2020-08-31 10:11:26)在区间[00:00:25,00:00:30)上,
继续输入:lisi,1598839900000(2020-08-31 10:11:40),此时打印出来:

这时候的水印为2020-08-31 10:11:30,和第二条数据所在的窗口最大值一样大,所以也会触发这个窗口数据的打印;
我们输入的第3~第5条数据在区间[00:00:30,00:00:35)这个范围,此时只要我们把水印提高到2020-08-31 10:11:35,理论上就算触发该窗口的执行,且该窗口size=3;
继续输入lisi,1598839905000(2020-08-31 10:11:45),此时打印出来:

结果如我们的所料,然后我们的代码在窗口对时间做了排序,所以3条数据依次为:
* lisi,1598839892000 2020-08-31 10:11:32
* lisi,1598839893000 2020-08-31 10:11:33
* lisi,1598839894000 2020-08-31 10:11:34
最后再来梳理下这个例子;
第一步,我们会根据窗口的大小,按照系统时间划分,这个时间是系统时间,而不是我们的事件时间,这样会把后面的每个事件时间依次划分到某个窗口去,这样就有了窗口的边界,最小值和最大值;

第二步,根据水印的计算规则(一般和我们的事件时间绑定),计算出水印超过了(或者等于)窗口的最大值,这时候就可以触发该窗口所有的值的计算了。。
通过这种方式,随着数据的进入,flink的水印一步步提高,然后一步步触发窗口数据的执行,同时窗口的数据汇聚到一起,开发者可以保证数据的有序性,从而解决数据乱序的问题。
6,总结
Flink的水印,时间,窗口是一个比较难理解的概念,本文只是讲了其中的一部分,许多细节还要读者慢慢体会。这里我用了单线程来模拟,如果是多线程的情况下水印又将是如何的?迟到的数据会怎样呢?还有诸多细节,有机会继续分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号