关系型数据库范式
设计关系数据库时,为了设计出合理的数据库表结构,需要遵从不同的规范要求,这些规范性要求被称为范式。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
各种范式呈递次规范,越高的范式数据库冗余越小。满足高层次范式的必定满足低层次范式,如一个数据库设计如果符合第二范式,一定也符合第一范式。
一、基本概念
1、实体:现实世界中客观存在的并可以相互区分的对象或事物。如"公司"、"项目"、"员工"等。
2、属性:实体所具有的某一特性。比如"公司名称"、"公司地址"都是实体"公司"的属性。
3、码:表中可以唯一确定一行数据的某个属性[或者属性组]。如[员工号]、[员工号,绩效评定月份]。不同的表结构,对应的码不同。下文表(二)中,[员工号,绩效评定月份]属性组就是码。
4、主属性:包含在任何一个码中的属性称为主属性。下文表(二)中,员工号和绩效评定月份就是主属性。
5、非主属性:与主属性相反,没有在任何候选码中出现过,这个属性就是非主属性。下文表二中,员工姓名、部门、部门人数、绩效就是非主属性。
二、第一范式
1、概述
第一范式指的是符合第一范式的关系中的每个属性都不可再分。
2、实例分析
下表(一)中,由于部门信息这个属性可以再分为部门和部门人数这两个属性,所以不符合第一范式。
| 员工号 | 员工姓名 | 部门 | 绩效评定月份 | 绩效 | |
| 部门 | 部门人数 | ||||
| 10001 | 张三 | 开发部 | 30 | 201801 | 90 |
| 10001 | 张三 | 开发部 | 30 | 201802 | 85 |
| 10002 | 李四 | 集成部 | 30 | 201801 | 88 |
| 10002 | 李四 | 集成部 | 30 | 201802 | 87 |
| 10003 | 王五 | 综合部 | 5 | 201802 | 89 |
| 10004 | 马六 | 综合部 | 5 | 201802 | 85 |
表(一)
将上表修改成如下表,就满足第一范式。
| 员工号 | 员工姓名 | 部门 | 部门人数 | 绩效评定月份 | 绩效 |
| 10001 | 张三 | 开发部 | 30 | 201801 | 90 |
| 10001 | 张三 | 开发部 | 30 | 201802 | 85 |
| 10002 | 李四 | 集成部 | 30 | 201801 | 88 |
| 10002 | 李四 | 集成部 | 30 | 201802 | 87 |
| 10003 | 王五 | 综合部 | 5 | 201802 | 89 |
| 10004 | 马六 | 综合部 | 5 | 201802 | 85 |
表(二)
第一范式是所有关系型数据库的最基本要求,只要在关系型数据库管理系统(RDBMS)中已经存在的数据表,一定是符合第一范式。
3、不足
A、数据冗余:如上表中,员工号、员工姓名、部门、部门人数数据重复出现多次。
B、插入异常:根据三种关系完整性约束中实体完整性的要求,关系中的码所包含的任意一个属性都不能为空,所有属性的组合也不能重复(可以简单的理解为表的主键)。上表中,为了唯一区分每一条记录,需要将(员工号,绩效评定月份)作为码。如果一个新建的部门还没有员工的话,那么就无法将部门和部门人数的信息插入到表中,导致插入异常,无法有效记录部门的信息。
C、删除异常:如果将员工相关的记录都删除,那么部门相关的信息也会删除,导致了删除异常。
D、修改异常:假如张三转到集成部,为了保证数据库中数据的一致性,需要修改两条条记录中部门与部门人数的数据,导致修改异常。
三、第二范式
1、概述
第二范式是为了解决第一范式所带来的问题而设定的规则,它是在第一范式的基础之上,消除了非主属性对于码的部分函数依赖。简单地说,第二范式要求每个非主属性完全依赖于主键,而不是仅依赖于主键其中的一部分属性。
2、相关概念
A、函数依赖
在一张表中,如果在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。
在上表(二)中,存在着以下的函数依赖:
★ 员工号 → 员工姓名
★ 部门 → 部门人数
★ (员工号,绩效评定月份) → 绩效
以下的函数依赖则不成立:
★ 员工号 → 绩效评定月份
★ 员工号 → 绩效
B、完全函数依赖
如果X → Y是一个函数依赖,且对X的任何一个真子集X',都不存在X' → Y,则称X → Y是一个完全函数依赖。为了方便表述,写作X>>Y(非正式方式)。
在上表中,存在着以下的完全函数依赖:
★ 员工号>>员工姓名
★ (员工号,绩效评定月份)>>绩效(员工号对应的绩效不确定,绩效评定月份对应的绩效也不确定)
C、部分函数依赖
如果X → Y是一个函数依赖,并且存在X的一个真子集X',使得X' → Y,则称X → Y是一个部分函数依赖。为了方便表述,写作X>Y(非正式方式)。
在上表中,存在着以下的部分函数依赖:
★ (员工号,绩效评定月份)>员工姓名
D、传递函数依赖
如果X→Y,Y→Z,且Y不属于X,Y → X不成立,则称Z传递函数依赖于X。为了方便表述,写作X>>>Z(非正式方式)。(限定Y不属于X,Y→X不成立,是因为如果Y属于X,那么Z部分函数依赖于X,此时X中存在多余属性;若Y → X成立,则有X和Y等价,则关系中没有必要同时存在X和Y)
在上表中,存在着以下的传递函数依赖:
★ 员工号>>>部门人数(员工号 → 部门,部门 → 部门人数)
3、实例分析
根据定义,我们可以知道:第二范式就是判断是否存在非主属性对于码的部分函数依赖,如果存在,则不满足第二范式。
判断一个表是否符合第二范式,可以通过以下步骤进行判断:
★ 找出表中所有的码;
★ 根据第一步找出的码,找出所有的主属性;
★ 根据主属性,找出所有的非主属性;
★ 判断是否存在非主属性对于码的部分函数依赖,由此判定是否符合第二范式;
我们根据以上步骤来分析一下上表(二):
★ 该表的码为:(员工号,绩效评定月份)
★ 该表的主属性为:员工号、绩效评定月份
★ 该表的非主属性为:员工姓名、部门、部门人数、绩效
★ 该表的非主属性对于码的函数依赖关系如下:
[员工号,绩效评定月份] → 绩效,完全函数依赖;
[员工号,绩效评定月份]→ 员工姓名,部分函数依赖;因为存在:员工号 → 员工姓名
[员工号,绩效评定月份]→ 部门,部分函数依赖;因为存在:员工号 → 部门
[员工号,绩效评定月份]→ 部门人数,传递函数依赖;因为存在:员工号 → 部门,部门 → 部门人数
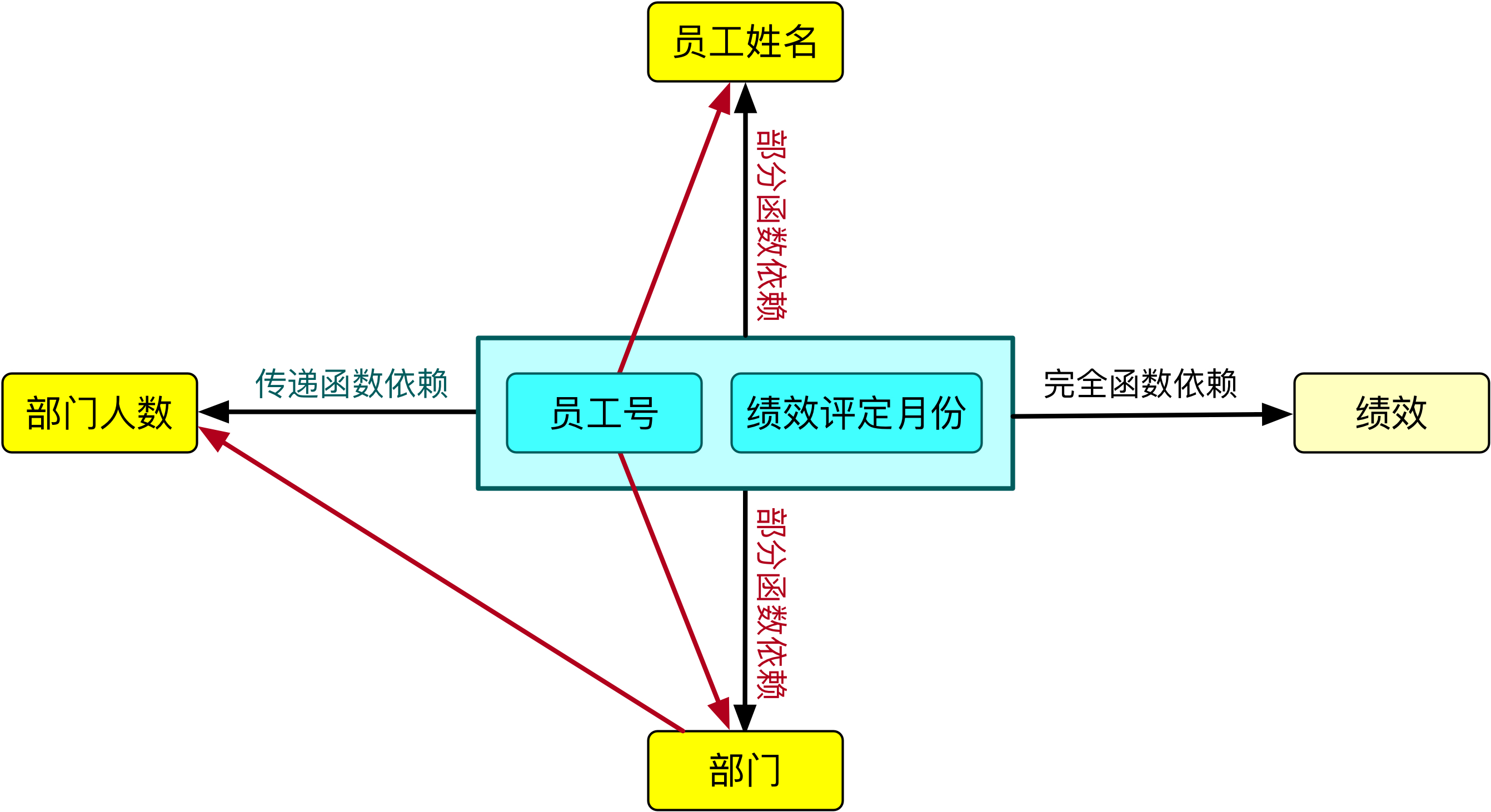
由于存在非主属性对于码的部分函数依赖,所以上表不符合第二范式。
为了符合第二范式的要求,我们必须消除这些部分函数依赖,将大表拆分成更多个更小的表。
我们将上表拆分成如下的两个表:
| 员工号 | 绩效评定月份 | 绩效 |
| 10001 | 201801 | 90 |
| 10001 | 201802 | 85 |
| 10002 | 201801 | 88 |
| 10002 | 201802 | 87 |
| 10003 | 201802 | 89 |
| 10004 | 201802 | 85 |
表(三)
| 员工号 | 员工姓名 | 部门 | 部门人数 |
| 10001 | 张三 | 开发部 | 30 |
| 10002 | 李四 | 集成部 | 30 |
| 10003 | 王五 | 综合部 | 5 |
| 10004 | 马六 | 综合部 | 5 |
表(四)
两个表的非主属性对于码的函数依赖关系如下:
★ [员工号,绩效评定月份]→ 绩效,完全函数依赖;
★ 员工号 → 员工姓名,完全函数依赖;
★ 员工号 → 部门,完全函数依赖;
★ 员工号 → 部门人数,完全函数依赖和传递函数依赖;因为存在:员工号 → 部门,部门 → 部门人数
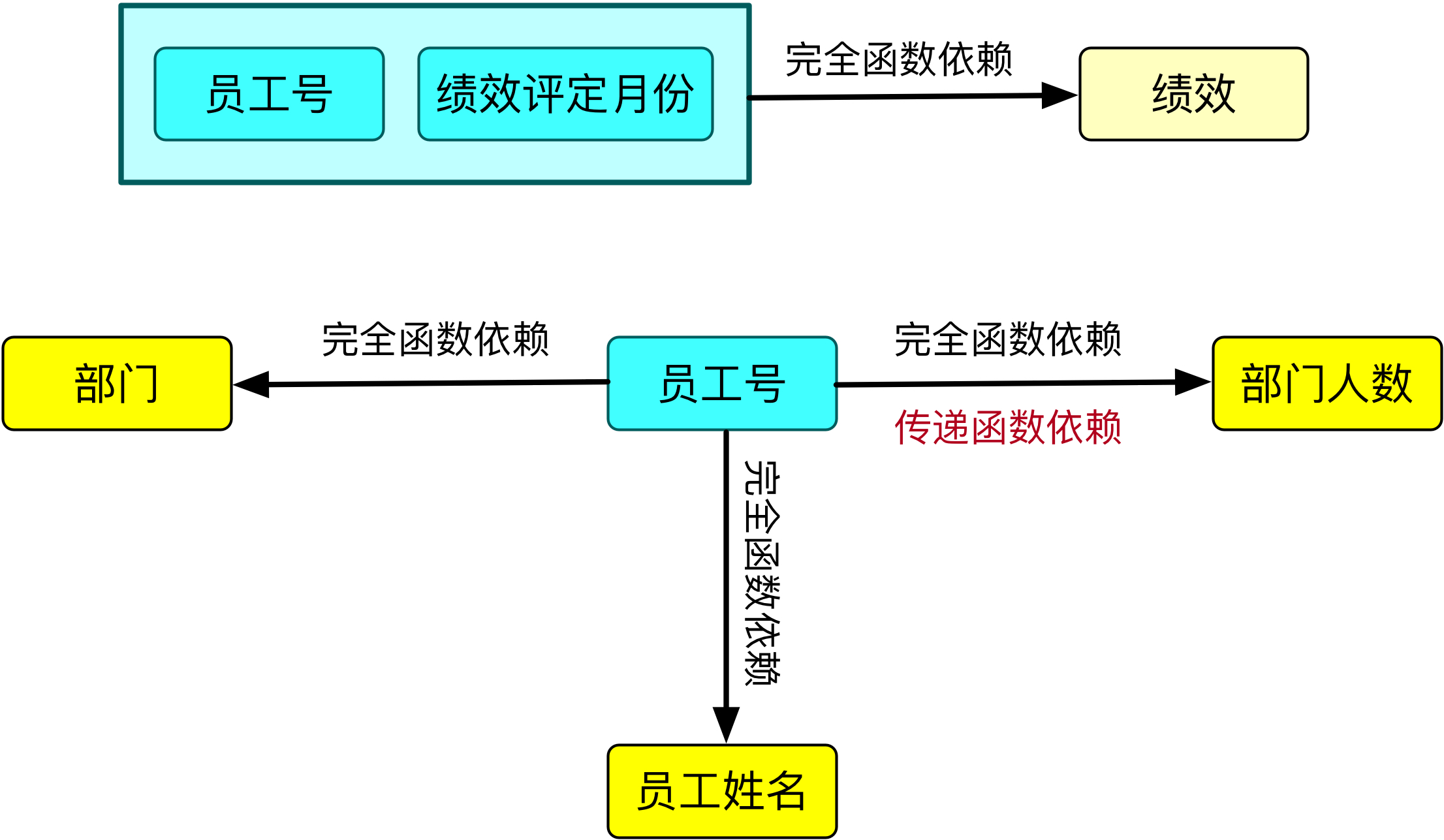
由于两个表都符合完全函数依赖,所以两个表都符合第二范式。
那么第二范式是否解决了第一范式的不足呢?
A、数据冗余:除部门人数数据重复外,其余无冗余。有改进。
B、插入异常:根据三种关系完整性约束中实体完整性的要求,关系中的码所包含的任意一个属性都不能为空,所有属性的组合也不能重复(可以简单的理解为表的主键)。员工-部门表中,为了唯一区分每一条记录,需要将员工号作为码。如果一个新建的部门还没有员工的话,那么就无法将部门和部门人数的信息插入到表中,导致插入异常,无法记录部门的信息。无改进。
C、删除异常:表(四)中,如果将员工相关的记录都删除,那么部门相关的信息也会删除,导致了删除异常。无改进。
D、修改异常:假如张三转到集成部,只需要改动对应的部门即可。有改进。
所以,仅仅符合第二范式的要求,很多情况下还是不够的,为了能进一步解决这些问题,我们还需要将符合第二范式要求的表改进为符合第三范式的要求。而导致这些的原因是传递函数依赖。
三、第三范式
1、概述
第三范式是在第二范式的基础之上,消除非主属性对于码的传递函数依赖。
2、实例分析
在上述例子中,由于存在员工号与部门人数的传递函数依赖,所以需要将表(四)进行再次拆分,拆分后所有表如下:
| 员工号 | 绩效评定月份 | 绩效 |
| 10001 | 201801 | 90 |
| 10001 | 201802 | 85 |
| 10002 | 201801 | 88 |
| 10002 | 201802 | 87 |
| 10003 | 201802 | 89 |
| 10004 | 201802 | 85 |
表(五)
| 员工号 | 员工姓名 | 部门 |
| 10001 | 张三 | 开发部 |
| 10002 | 李四 | 集成部 |
| 10003 | 王五 | 综合部 |
| 10004 | 马六 | 综合部 |
表(六)
| 部门 | 部门人数 |
| 开发部 | 30 |
| 集成部 | 30 |
| 综合部 | 5 |
表(七)
以上三个表均满足第三范式,那么第三范式是否解决了第二范式的不足呢?
A、数据冗余:无冗余。有改进。
B、插入异常:可以插入部门信息。有改进。
C、删除异常:删除员工信息,部门信息不会删除。有改进
D、修改异常:假如张三转到集成部,只需要改动对应的部门即可。有改进。
所以第三范式基本解决了数据冗余、插入异常、删除异常、修改异常等问题。
四、其它范式(待补充细化)
A、BCNF范式
1、所有非主属性都完全函数依赖于每个候选键
2、所有主属性都完全函数依赖于每个不包含它的候选键
3、没有任何属性完全函数依赖于非候选键的任何一组属性
B、第四范式
解决多值依赖问题,要求把同一表内的多对多关系删除。表示在多对多关系中,实体本身并不存储关系,而关系都记录在另一个中间关系表中,要选择俩个多对多实体间的数据,必须通过中间关系表来得到,实体本身没有存储任何与另外一个实体的关系的记录。
C、第五范式
也称投影-连接范式,是数据库规范化的一个级别,以去除多个关系之间的语义相关。一张表满足第五范式当且仅当它的每个连接依赖可由候选键推出。
五、总结
范式就是在数据库表设计时移除数据冗余的过程。随着范式级别的提升,数据冗余越来越少,但数据库的效率也越来越低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号