flink 任务jar冲突解决
1、背景
Flink流计算任务迁移到B3集群,在代码迁移中出现了各种类型的报错以及jar包冲突
2、问题及解决步骤
1)问题初排与解决
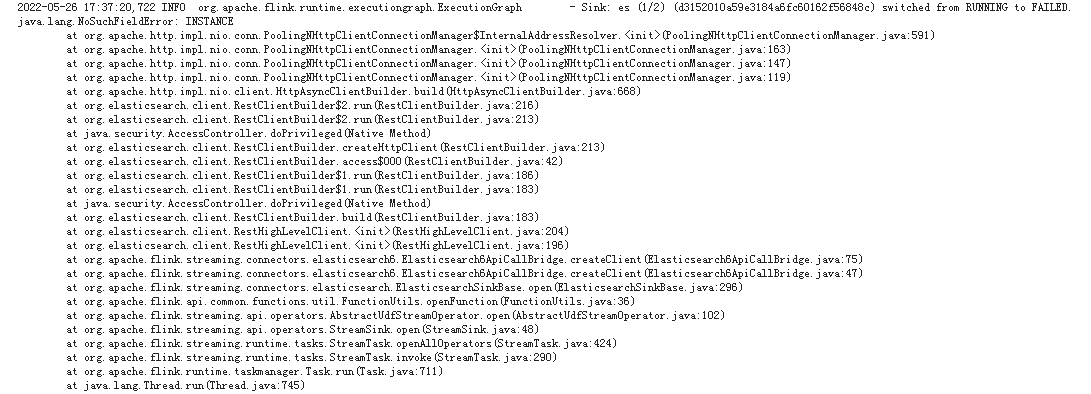
根据以上报错信息,可以报错信息初步怀疑httpClient相关jar冲突。
故在依赖中排除掉可能存在冲突的jar(httpClient,httpCore),运行失败,冲突未解决
2)简化项目代码,精准定位问题
简化项目代码,仅留下从kafka读取数据及打印控制台部分,任务运行正常
加入es相关代码及依赖, NoSuchFieldError: INSTANCE 报错再次出现,可以确定是es相关jar出现问题。
3)项目自带jar包与集群中的jar冲突,这个问题看着很难处理,集群中的jar可能被其他项目可能被其他项目依赖不好乱动,本地的版本加了也白加,都会引用集群上的包,那么怎么解决呢? 通过 maven-shade-plugin 修改http所有包的路径为org/genitus/org/apache/http
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>${maven-shade-plugin.version}</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <relocations> <relocation> <pattern>org.apache.http</pattern> <shadedPattern>genitus.org.apache.http</shadedPattern> </relocation> </relocations> </configuration> </execution> </executions> </plugin>

以上错误提示可以看出 org/elasticsearch/client 下还存在冲突,同上修改org/elasticsearch/client的路径,按理说到这一步,任务运行会直接依赖本地jar,但是很不幸,再一次出现了以下报错。

在flink文档中可以看到这样一个反序列化bug,也就是说采取shade打包改变包依赖路径的方案不可行。
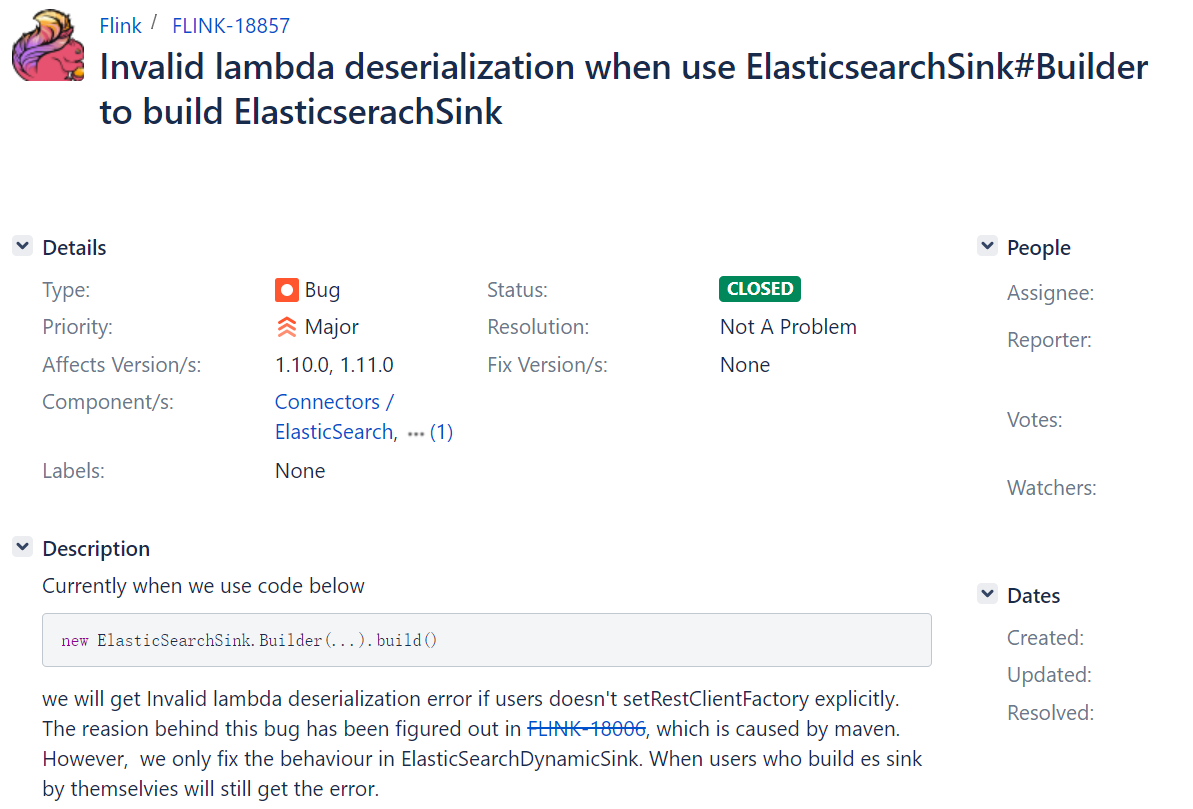
4)转变思路,修改集群类加载机制
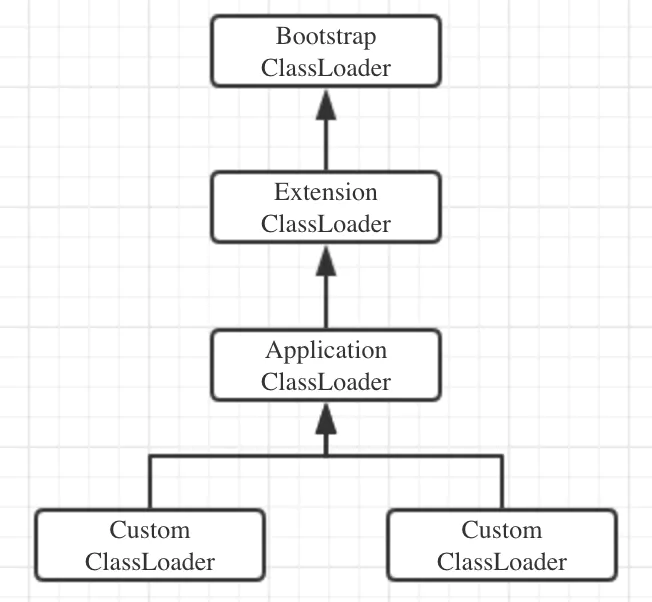
我们知道,在JVM中,一个类加载的过程大致分为加载、链接(验证、准备、解析)、初始化5个阶段。而我们通常提到类的加载,就是指利用类加载器(ClassLoader)通过类的全限定名来获取定义此类的二进制字节码流,进而构造出类的定义。Flink作为基于JVM的框架,在flink-conf.yaml中提供了控制类加载策略的参数classloader.resolve-order,可选项有child-first 和 parent-first。
Flink的parent-first类加载策略就是照搬双亲委派模型的。也就是说,用户代码的类加载器是Custom ClassLoader,Flink框架本身的类加载器是Application ClassLoader。用户代码中的类先由Flink框架的类加载器加载,再由用户代码的类加载器加载。
双亲委派模型的好处就是随着类加载器的层次关系保证了被加载类的层次关系,从而保证了Java运行环境的安全性。但是在Flink App这种依赖纷繁复杂的环境中,双亲委派模型可能并不适用。例如,程序中引入的Flink-Cassandra Connector总是依赖于固定的Cassandra版本,用户代码中为了兼容实际使用的Cassandra版本,会引入一个更低或更高的依赖。而同一个组件不同版本的类定义有可能会不同(即使类的全限定名是相同的),如果仍然用双亲委派模型,就会因为Flink框架指定版本的类先加载,而出现莫名其妙的兼容性问题,如NoSuchMethodError、IllegalAccessError等。
查看运行日志,可以看到flink类加载机制是 parent-first
2022-05-26 19:43:05,195 INFO org.apache.flink.configuration.GlobalConfiguration
- Loading configuration property: classloader.resolve-order, parent-first
修改 classloader.resolve-order 为 child-first ,设置任务启动时首先加载用户空间的jar。
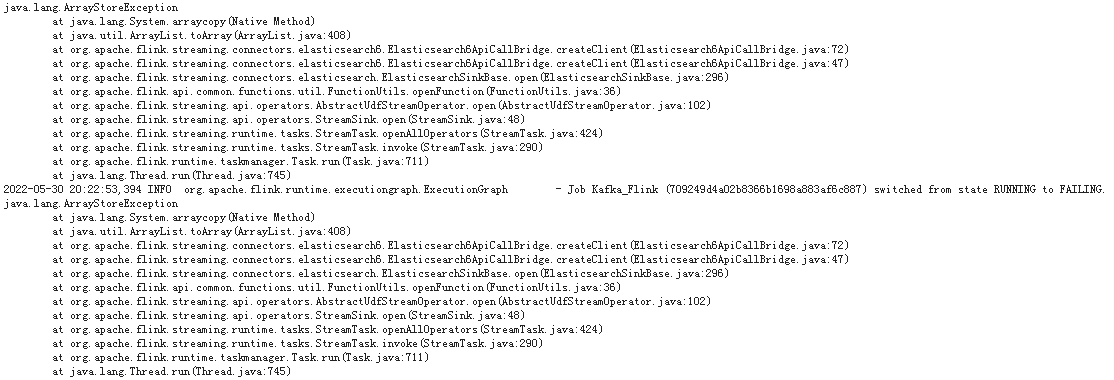
似乎child-first配置并未生效,程序依旧加载的是集群jar。问题出在哪里呢?
5)查看作业提交命令

逐步检查作业提交时的各种配置,发现疑点 flink -C 后面的 jar包会提交到用户空间,让我们来看一下官方解释
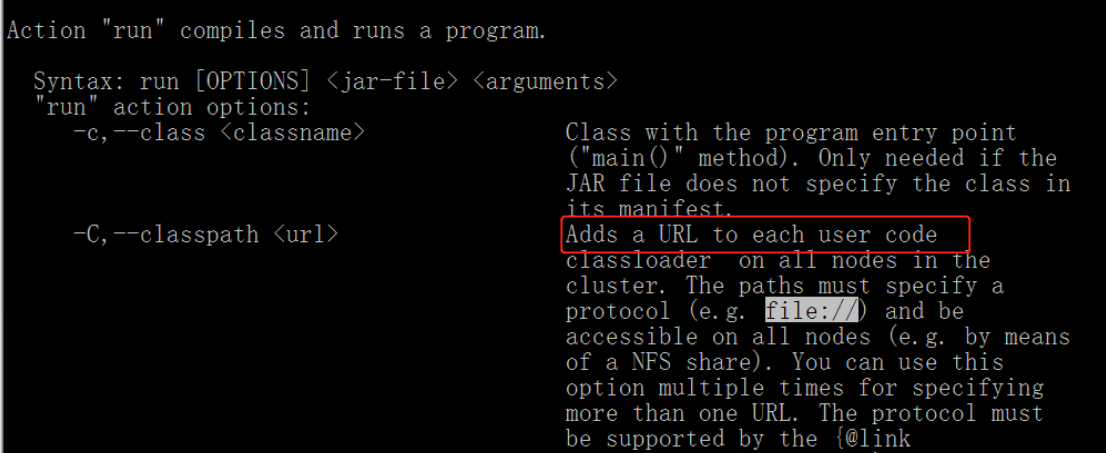
最终解决方案,删除集群中flink-connectors-1.6.4.jar中冲突的依赖。
3、Flink 作业2冲突解决
第一个作业问题解决起来耗费了较多精力,作业2的问题解决就变得更加得心应手
java.lang.VerifyError: class com.fasterxml.jackson.module.scala.ser.ScalaIteratorSerializer
overrides final method withResolved.(Lcom/fasterxml/jackson/databind/BeanProperty;
Lcom/fasterxml/jackson/databind/jsontype/TypeSerializer;Lcom/fasterxml/jackson/databind/JsonSerializer;)
Lcom/fasterxml/jackson/databind/ser/std/AsArraySerializerBase;
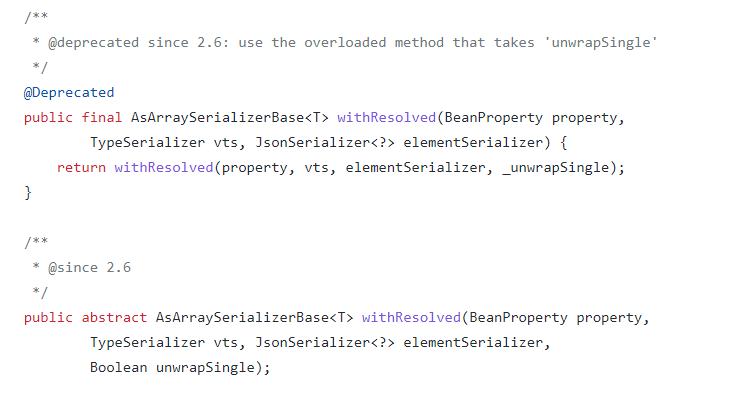
深入源码可以看到 IterableSerializer中的类要重写withResolved方法
com.fasterxml.jackson.module.scala.ser.IterableSerializer extends AsArraySerializerBase
override def withResolved(newProperty: BeanProperty, newVts: TypeSerializer, elementSerializer: JsonSerializer[_]) = new IterableSerializer(seqType, elemType, anyRefType, staticTyping, Option(newVts), newProperty, Option(elementSerializer.asInstanceOf[JsonSerializer[AnyRef]]))
2.4.6

2.6.7
可以确定jackson-databind版本冲突
修改jackson-module-scala版本,冲突未解决,仔细检查本地jackson的版本,并无异常
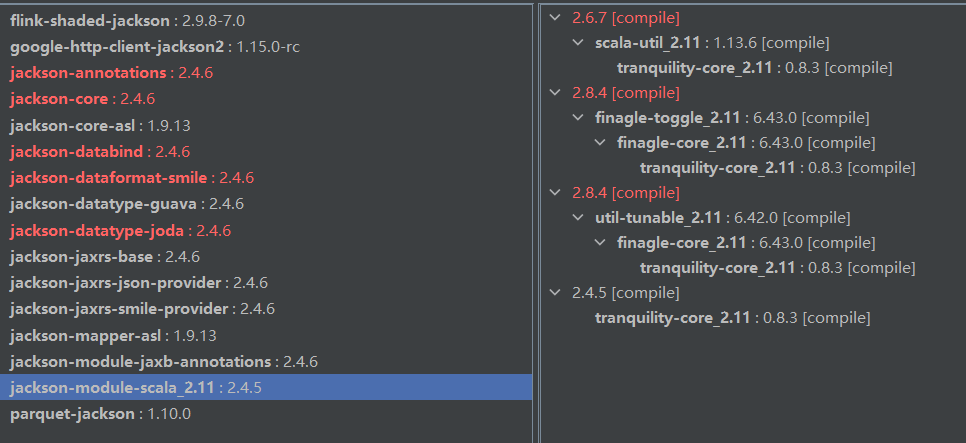
怀疑集群存在冲突jar
补充:
谁控制jar包的加载顺序的?
查了很多资料,比较靠谱的说法是,操作系统本身,控制了jar包的默认加载顺序。
包路径越靠前,越先被加载。换句话说,如果靠前的jar包里的类被加载了,后面jar包里有同名同路径的类,就会被忽略掉,不会被加载。
Classpath: lib/flink-metrics-graphite-1.9.3.jar
:lib/flink-shaded-hadoop-2-uber-2.6.0-cdh5.5.0-11.0.jar
:lib/flink-table-blink_2.11-1.9.3.jar:lib/flink-table_2.11-1.9.3.jar
:lib/log4j-1.2.17.jar:lib/sentry-hdfs-1.8.0.jar
:lib/slf4j-log4j12-1.7.15.jar:log4j.properties:logback.xml
:maddons/flink-connectors-1.9.3.jar:flink.jar
:flink-conf.yaml:genitus-gungnir-streaming-0.2.0.jar
反编译 flink-connectors-1.9.3.jar:flink.jar 后,发现端倪。已经存在jackson-databind较高版本。
下一个问题,升级集群中hadoop版本为2.8.4

升级完以后 NoSuchMethodError再次出现,此时,经验已经很丰富了,直接查看源代码,找出报错的原因。
com.iflytek.odeon.jobtracker.common.api.exception.TrackerException: Tracker-003,作业提交失败,java.lang.NoSuchMethodError:
org.apache.commons.cli.Options.hasShortOption(Ljava/lang/String;)Z at org.apache.commons.cli.DefaultParser.handleShortAndLongOption(DefaultParser.java:478) at org.apache.commons.cli.DefaultParser.handleToken(DefaultParser.java:243) at org.apache.commons.cli.DefaultParser.parse(DefaultParser.java:120) at org.apache.commons.cli.DefaultParser.parse(DefaultParser.java:81) at org.apache.flink.client.cli.CliFrontendParser.parse(CliFrontendParser.java:463) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:176) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1008) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1081) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1840) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1081) at com.iflytek.odeon.jobtracker.common.api.exception.TrackerException.asTrackerException(TrackerException.java:51) at com.iflytek.odeon.jobtracker.avatar.job.FlinkJarAvatar193.submit(FlinkJarAvatar193.java:183) at com.iflytek.odeon.jobtracker.tracker.job.JobTracker.submit(JobTracker.java:111) at com.iflytek.odeon.jobtracker.tracker.job.JobTracker.startFromBeginning(JobTracker.java:48) at com.iflytek.odeon.jobtracker.tracker.TrackerExecutor$1.run(TrackerExecutor.java:21) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
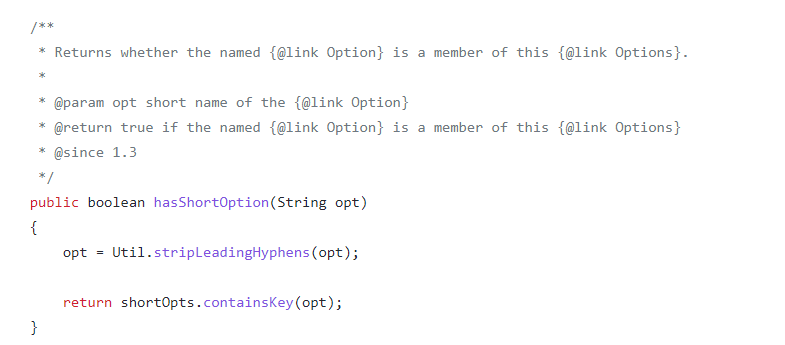
解决完jar冲突后,还出现了以下内存溢出的问题,这就是小意思了。
java.lang.OutOfMemoryError: GC overhead limit exceeded at java.lang.StringCoding$StringDecoder.decode(StringCoding.java:149) at java.lang.StringCoding.decode(StringCoding.java:193) at java.lang.StringCoding.decode(StringCoding.java:254) at java.lang.String.<init>(String.java:546) at java.lang.String.<init>(String.java:566) at org.genitus.gungnir.streaming.util.SessionCodec$$anonfun$decode$1.apply(Codec.scala:66) at org.genitus.gungnir.streaming.util.SessionCodec$$anonfun$decode$1.apply(Codec.scala:65) at scala.util.Try$.apply(Try.scala:192) at org.genitus.gungnir.streaming.util.SessionCodec.decode(Codec.scala:65) at org.genitus.gungnir.streaming.serialization.SessionDeserializationSchema.deserialize(Deserializer.scala:54) at org.genitus.gungnir.streaming.serialization.SessionDeserializationSchema.deserialize(Deserializer.scala:37) at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:146) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:715) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63)
3、总结
解决jar包冲突的常见手段
1)exclude ,排除掉冲突的jar
2)relocation ,修改依赖的包路径
3)修改类加载机制
4)结合源码,真正地定位问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号