机器学习第三周
应用机器学习的时候,会遇到很多问题。比如模型的选择,数据的拟合程度,新样本的泛化程度。这里记录 一些相关概念和应对方法。
1. 将 数据集分成 训练集,验证集,测试集。最好是采用随机方法来取,一般是 60% ,20%,20%。
要考虑假设函数的拟合程度(也就是模型选择)以及 新情况的泛化程度,验证集作用是挑出拟合合适的假设函数,测试集的作用是看新样本的泛化程度
这里以单变量线性回归为例子来看以下具体处理
-
使用训练集训练出10个模型
-
用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
-
选取代价函数值最小的模型
-
用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
用训练集得到的模型参数,也就是thera向量组,带入到预先设定的多个假设函数中,得到初步模型。
然后将这几个假设函数对应的代价函数计算对比,得到最小的代价,也就是选定了模型。(这是验证集的作用)
然后对这个选出来的假设函数应用测试集来查看一下拟合程度,考察拟合程度主要就是看欠拟合还是过拟合,运用的指标有方差和偏差。
下图是假设函数组合。
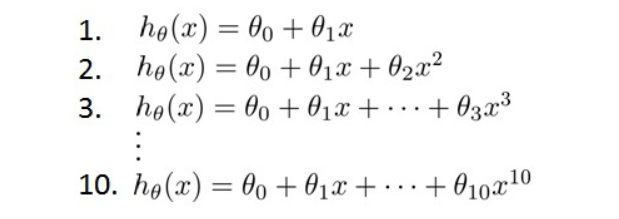
高偏差和高方差的问题基本上来说是欠拟合和过拟合的问题
下图就是典型的 欠拟合 拟合的不错 过拟合
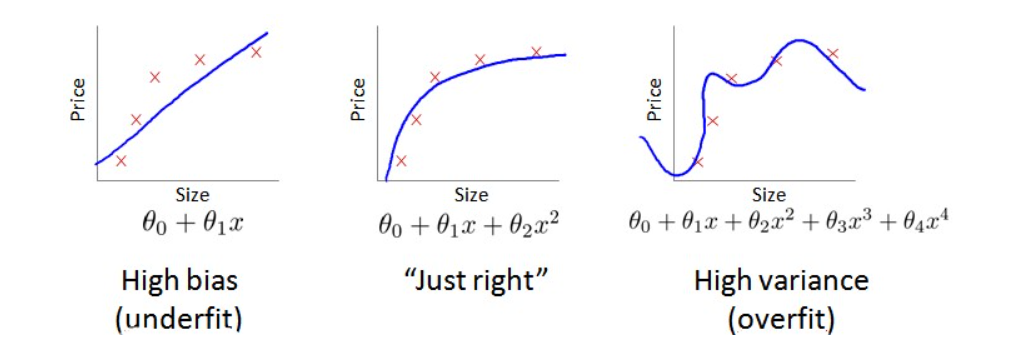
将验证集和训练集的代价函数放到一张图上,对于训练集,当 较小时,模型拟合程度更低,误差较大;随着 的增长,拟合程度提高,误差减小。 对于交叉验证集,当 较小时,模型拟合程度低,误差较大;但是随着 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
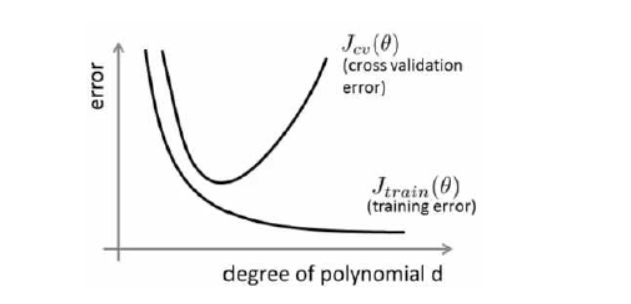
所以有结论
训练集误差和交叉验证集误差近似时:偏差/欠拟合 交叉验证集误差远大于训练集误差时:方差/过拟合。
上面的都是没有加入正则项的,一般模型都会匹配上正则项,正则项的选择和上面的方程次数的选择其实是一个意思, 选择恰当的正则项就是选择恰当的次数来比较好的拟合数据。
依然是模型的多个参数选择,选择较小代价的那一个,在加入测试集看泛化

选择的方法为:
- 使用训练集训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
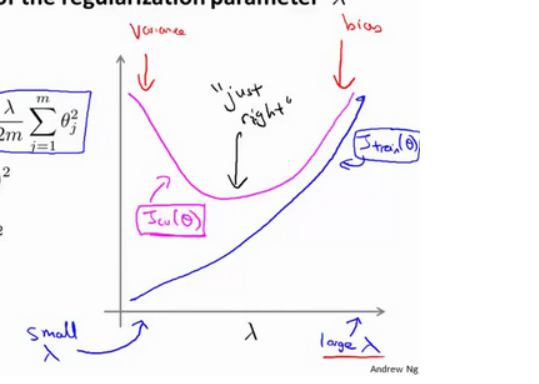
当 theta 较小时,训练集误差较小(过拟合)而交叉验证集误差较大 • 随着 theta 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加.
这里的图像和上述的次数的图形从形状来看 正好反过来,其实是一个意思,毕竟次数越大越拟合(过拟合)。正则越小,等同于失去惩罚能力,越拟合(过拟合)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号