实验6
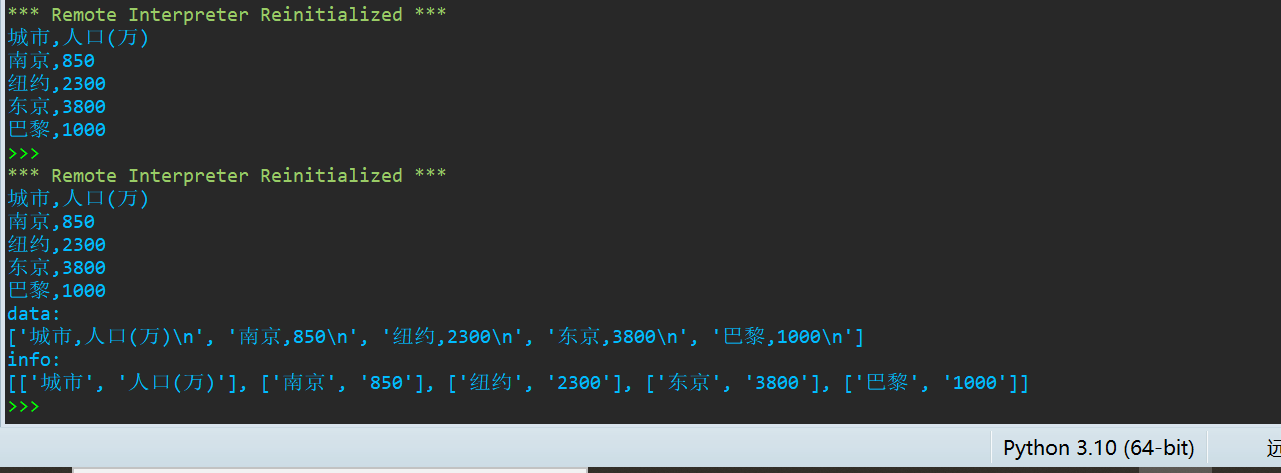
title = ['城市', '人口(万)'] info = [ ['南京', '850'], ['纽约', '2300'], ['东京', '3800'], ['巴黎', '1000'] ] with open('city1.csv', 'w', encoding='utf-8') as f: f.write(','.join(title) + '\n') for item in info: f.write(','.join(item) + '\n') with open('city1.csv', 'r', encoding='utf-8') as f: print(f.read().rstrip('\n')) with open('city1.csv', 'r', encoding='utf-8') as f: data = f.readlines() print('data: ') print(data) info = [line.rstrip('\n').split(',') for line in data] print('info: ') print(info)
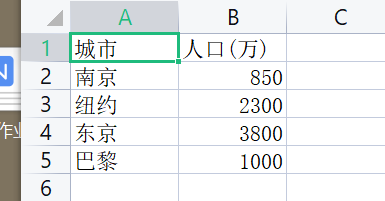
import csv title = ['城市', '人口(万)'] info = [ ['南京', '850'], ['纽约', '2300'], ['东京', '3800'], ['巴黎', '1000'] ] with open('city2.csv', 'w', encoding='utf-8', newline='') as f: f_writer = csv.writer(f) # 为文件对象f创建一个writer对象 f_writer.writerow(title) # 通过writer对象的writerrow方法写入一行(标题行) f_writer.writerows(info) # 通过writer对象的writerrows方法写入多行
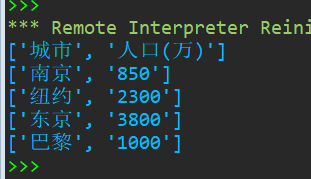
with open('city2.csv', 'r', encoding='utf-8') as f: f_reader = csv.reader(f) # 为文件对象f创建一个reader对象 for line in f_reader: print(line)
import csv with open('city3.csv', 'w', encoding='utf-8', newline='') as f: title = ['城市', '人口'] f_writer = csv.DictWriter(f, fieldnames = title) # 为文件对象f创建一个 DictWriter对象,并指定字段名称 f_writer.writeheader() f_writer.writerow({'城市':'南京', '人口': '850万'}) f_writer.writerow({'城市':'纽约', '人口': '2300万'}) f_writer.writerow({'城市':'东京', '人口': '3800万'}) f_writer.writerow({'城市':'巴黎', '人口': '1000万'})
def is_valid(x): if len(x) != 18: return False for i in x: if not (i.isdigit() or i == 'X'): return False else: return True import csv l=[] with open('data3_id.txt', 'r', encoding='utf-8') as f: f_reader = csv.DictReader(f) for line in f_reader: n=line.get('身份证号码') name=line.get('姓名') if is_valid(n) is True: x=(f'{name},{n[6:10]}-{n[10:12]}-{n[12:14]}') l.append(x) l1=sorted(l,key=(lambda x : x[3:8]),reverse=False) for i in l1: print(i)

import random import datetime data1=[] with open('data5.txt', 'r', encoding='utf-8') as f: data=f.readlines() for i in data: a=i.strip('\n') data1.append(a) n=eval(input('输入随机抽取人数')) R=random.sample(data1,n) for i in R: print(i) t=datetime.datetime.now() T=t.strftime('%Y%m%d') filename=T+'.txt' with open (filename,'w',encoding='utf-8')as f: for i in R: f.write(i+'\n')


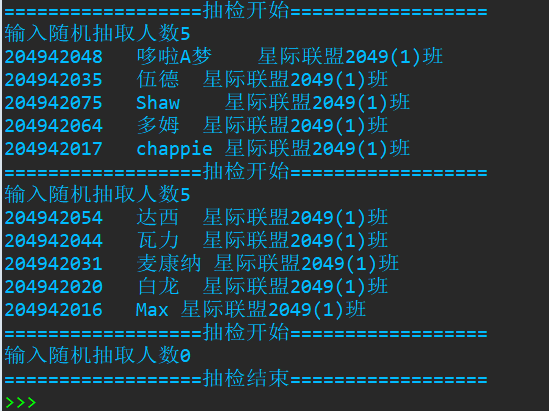
import random import datetime data1=[] with open('data5.txt', 'r', encoding='utf-8') as f: data=f.readlines() for i in data: a=i.strip('\n') data1.append(a) t=datetime.datetime.now() T=t.strftime('%Y%m%d') filename=T+'.txt' S=set() while True: print('{:=^40}'.format('抽检开始')) n=eval(input('输入随机抽取人数')) if n == 0 : print('{:=^40}'.format('抽检结束')) break R=random.sample(data1,n) for i in R: data1.remove(i) for i in R: print(i) t=datetime.datetime.now() T=t.strftime('%Y%m%d') filename=T+'.txt' with open (filename,'a',encoding='utf-8')as f: for i in R: f.write(i+'\n')