


爬取抽屉网全文实战(基于scrapy模块)
一、先安装scrapy


1. pip3 install wheel 2. pip3 install lxml 3. pip3 install pyopenssl 4. pip3 install -i https://mirrors.aliyun.com/pypi/simple/ pypiwin32 5. 下载文件(twisted): https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 install 文件路径\Twisted-19.2.0-cp36-cp36m-win_amd64.whl 6.pip3 install scrapy 7.scrapy 测试安装是否成功 Scrapy 1.6.0 - no active project
二、下载MongoDB
网址:https://www.mongodb.com/
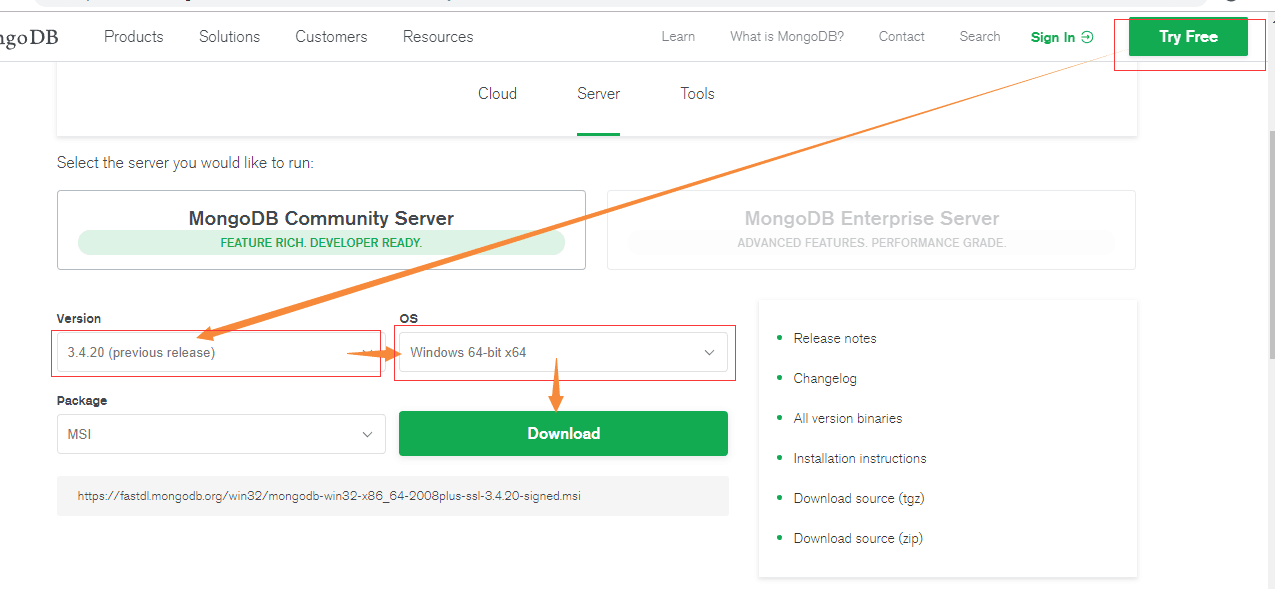
如果下载不成功就下载µTorrent
链接:https://pan.baidu.com/s/1TXMRmLS2YFBocdo4hpZMpg
提取码:3wmu
复制这段内容后打开百度网盘手机App,操作更方便哦
链接:https://pan.baidu.com/s/1swReUlQsSf4ohWrDDy_Jzg
提取码:4bkp
复制这段内容后打开百度网盘手机App,操作更方便哦
下载完成后找到下载的路径
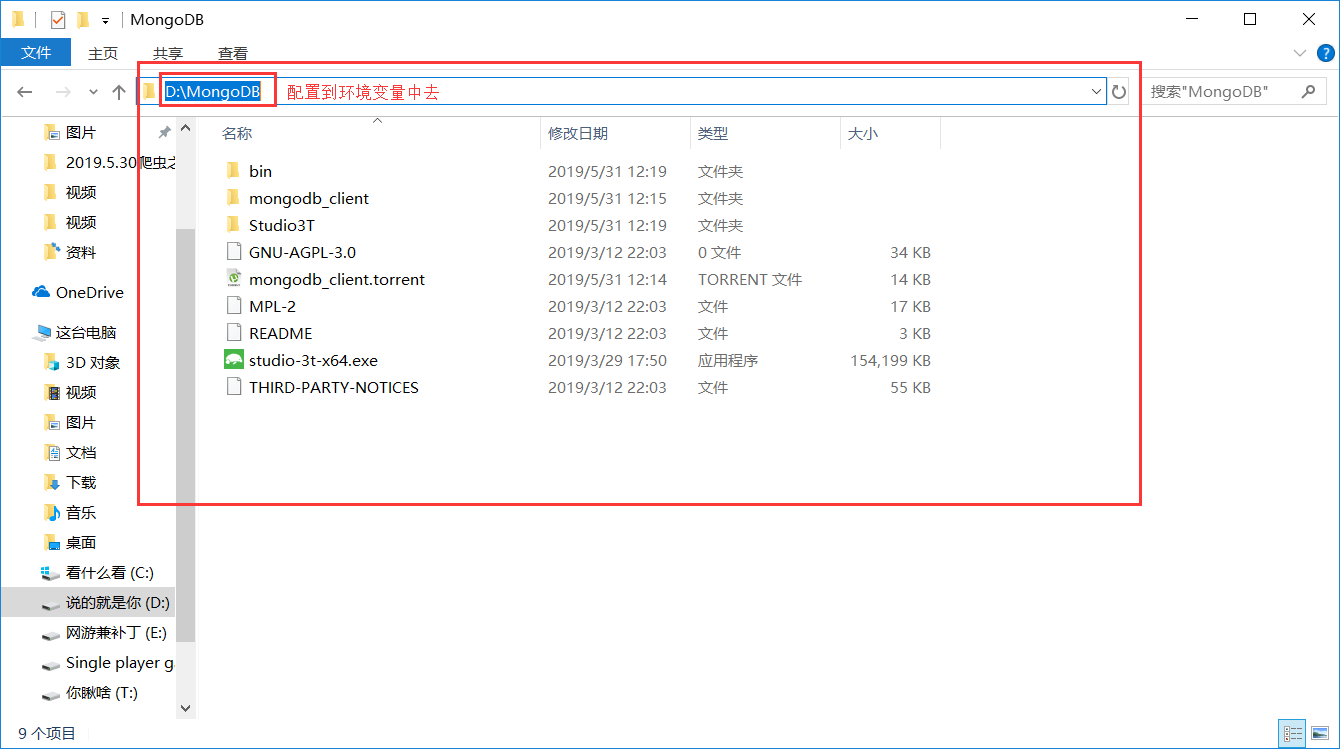
配置到环境变量中
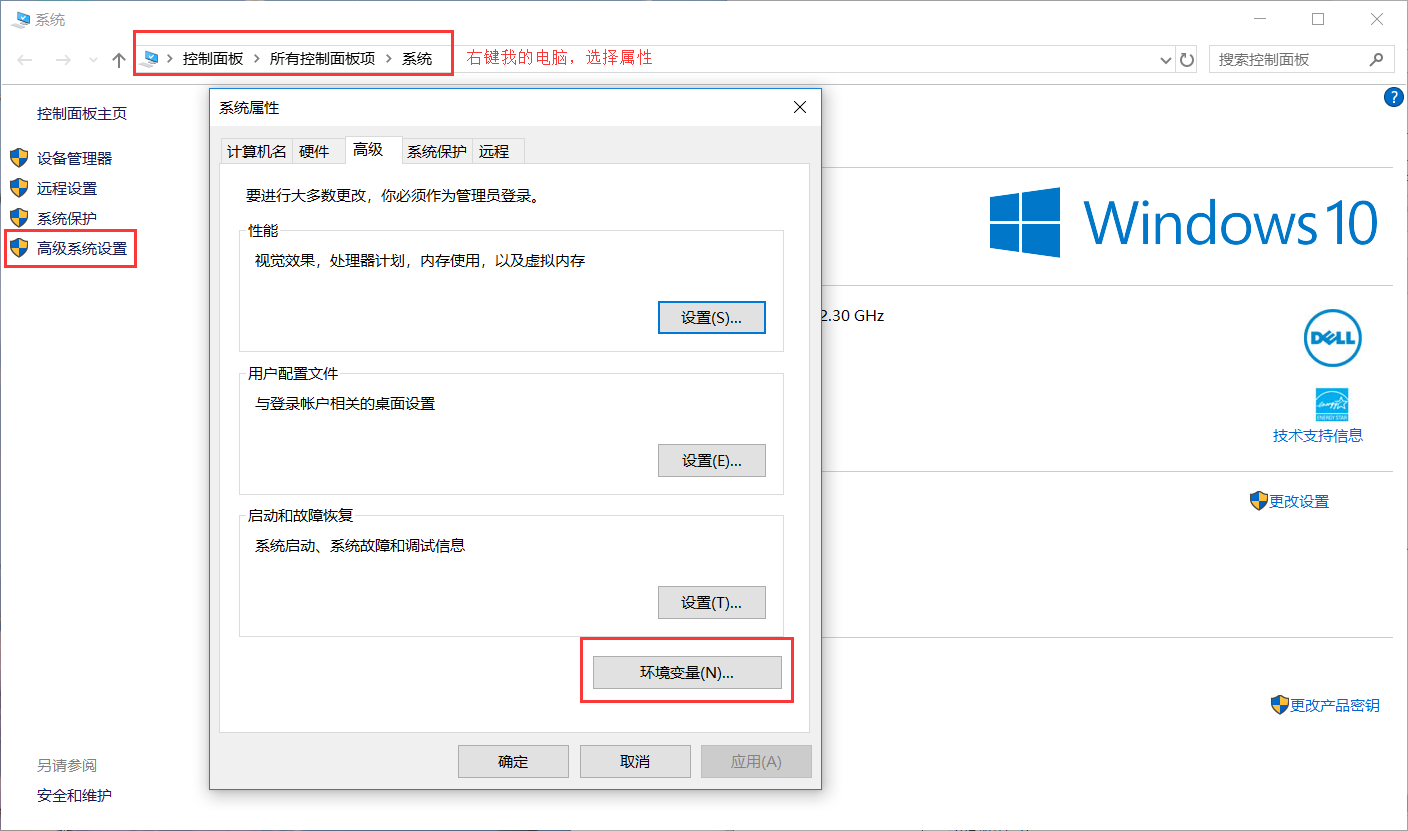
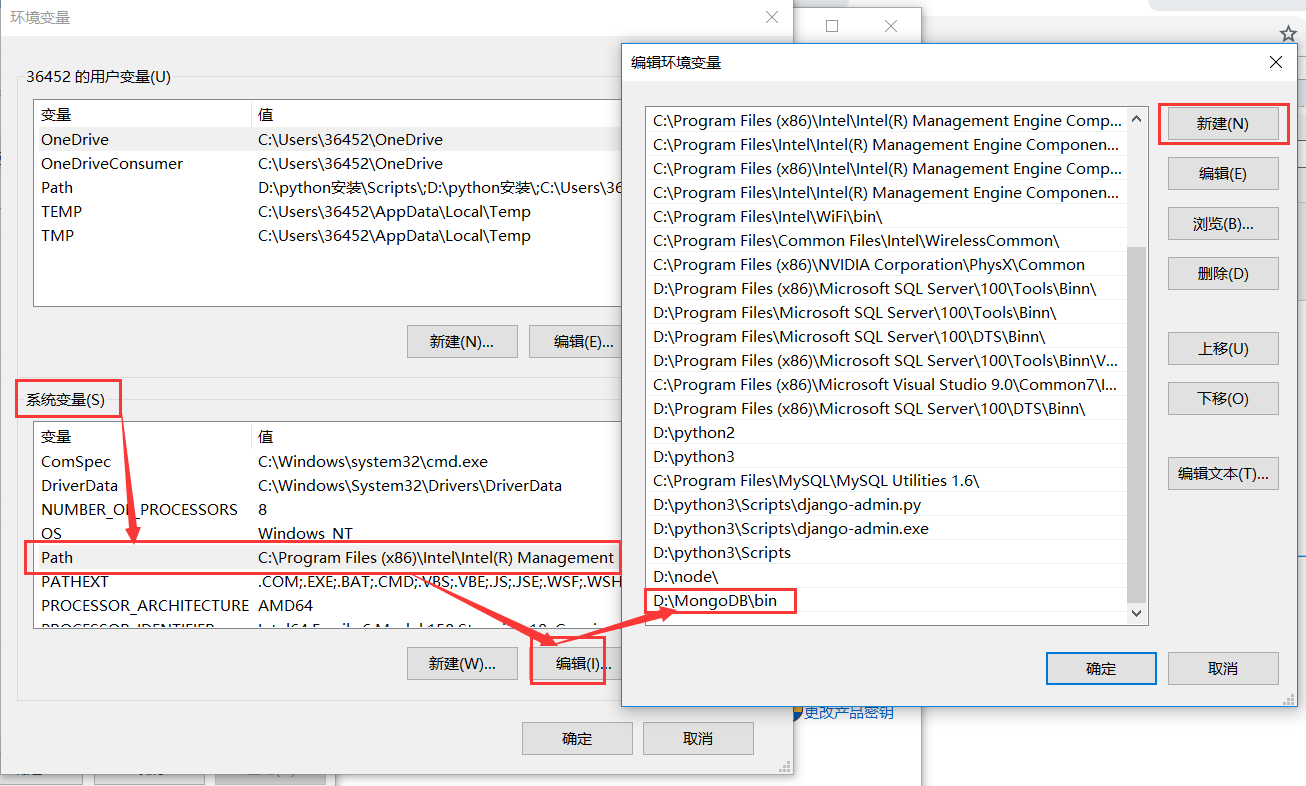
注意:在C盘下如果没有data需要手动创建并且在data里面创建一个db文件夹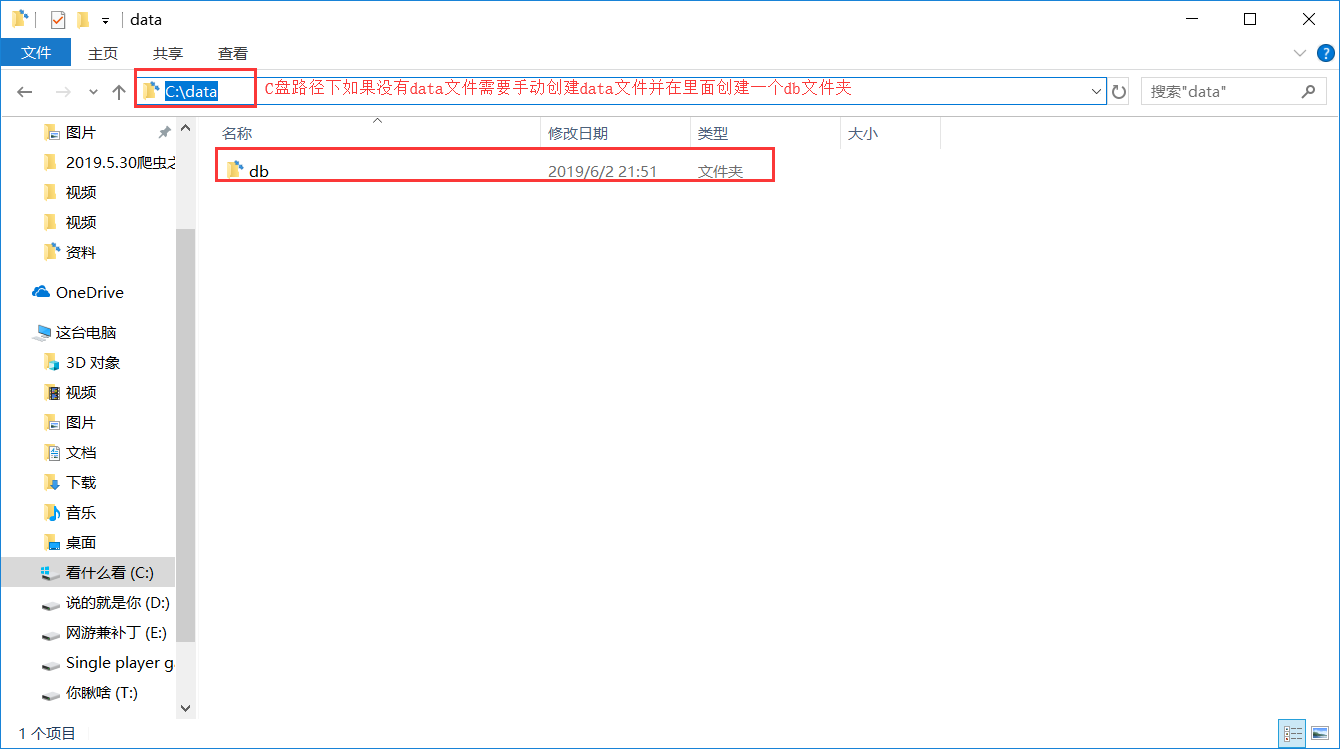
以上步骤做完后分别打开两个CMD
***服务器***
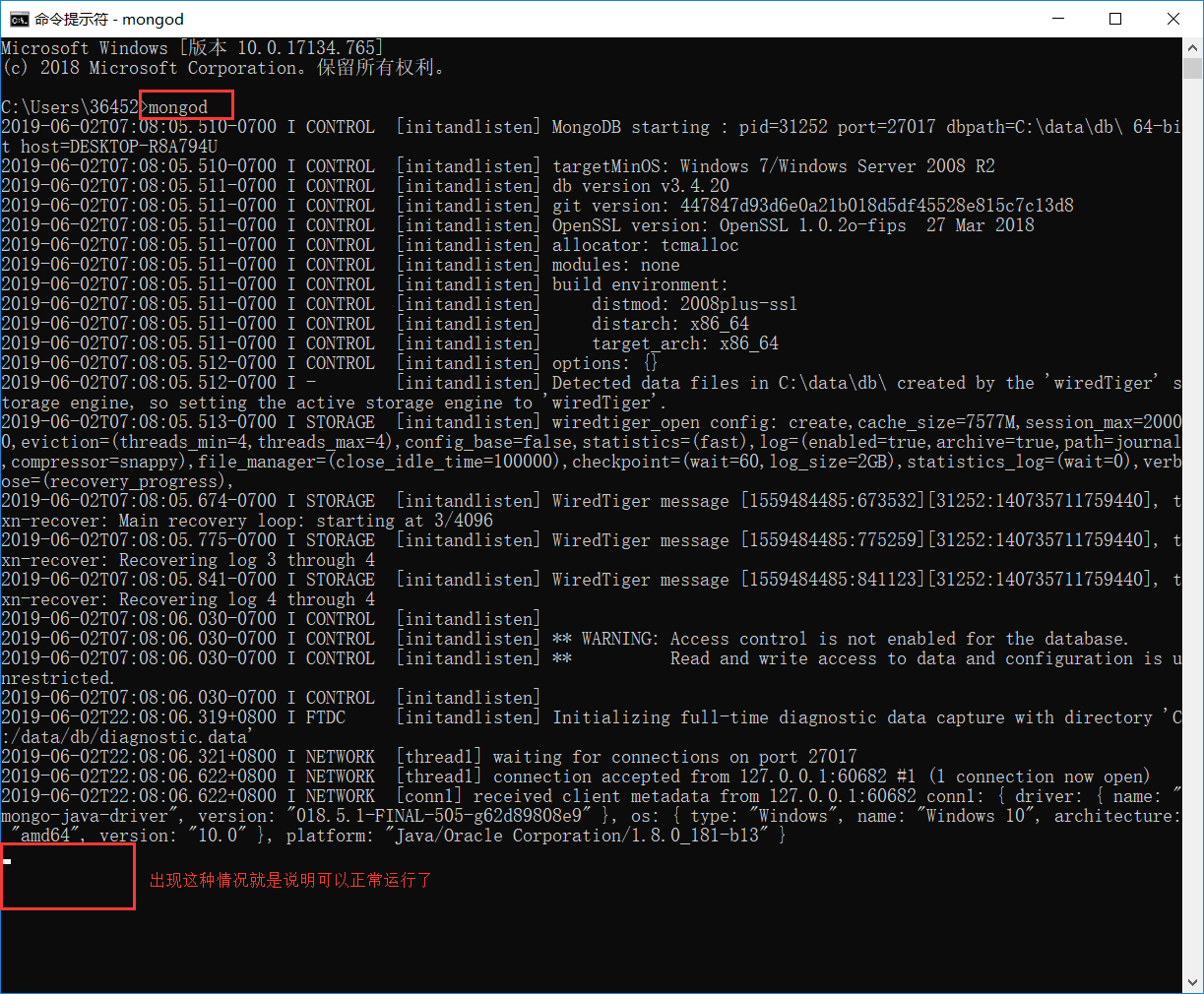
***客户端***

MangoDB创建数据库

以上全部成功后就可以开始代码之旅了
首先在客户端中创建爬虫py文件
# 创建项目 scrapy startproject spider_project # 定位到spider_project文件下 cd spider_project # 创建chouti.py文件 scrapy genspider chouti chouti.com
下面就是具体的代码
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy # class SpiderProjectItem(scrapy.Item): # # define the fields for your item here like: # name = scrapy.Field() # 新闻items类 class SpiderNewListItem(scrapy.Item): # define the fields for your item here like: # 新闻链接 new_url = scrapy.Field() # 新闻文本 new_text = scrapy.Field() # 点赞数 nice_num = scrapy.Field() # 新闻ID new_id = scrapy.Field() # 评论数 commit_num = scrapy.Field() # 新闻详情 new_content = scrapy.Field() # 发表新闻用户的主页 user_link = scrapy.Field() # 新闻items类 class SpiderUserListItem(scrapy.Item): # define the fields for your item here like: # 新闻链接 new_url = scrapy.Field() # 新闻文本 new_text = scrapy.Field() # 点赞数 nice_num = scrapy.Field() # 新闻ID new_id = scrapy.Field() # 评论数 commit_num = scrapy.Field() # 新闻详情 new_content = scrapy.Field() # 用户名 user_name = scrapy.Field()
pipelines.py文件
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # class SpiderProjectPipeline(object): # def process_item(self, item, spider): # return item import scrapy from pymongo import MongoClient # 新闻详情 class SpiderNewListPipeline(object): def __init__(self, ip, port, mongo_db): self.ip = ip self.port = port self.mongo_db = mongo_db # 一 启动scrapy项目会先执行此方法加载settings里面的配置文件 @classmethod def from_crawler(cls, crawler): ip = crawler.settings.get('IP') port = crawler.settings.get('PORT') mongo_db = crawler.settings.get('DB') return cls(ip, port, mongo_db) # 二 执行爬虫程序会先执行此方法 def open_spider(self, spider): self.client = MongoClient(self.ip, self.port) def process_item(self, item, spider): new_url = item.get('new_url') new_text = item.get('new_text') nice_num = item.get('nice_num') new_id = item.get('new_id') commit_num = item.get('commit_num') new_content = item.get('new_content') user_link = item.get('user_link') new_data = { 'new_url': new_url, 'new_text': new_text, 'nice_num': nice_num, 'new_id': new_id, 'commit_num': commit_num, 'new_content': new_content, 'user_link': user_link } self.client[self.mongo_db]['new_list'].insert_one(new_data) return item def close_spider(self, spider): self.client.close() # 用户主页新闻详情 class SpiderUserListPipeline(object): def __init__(self, ip, port, mongo_db): self.ip = ip self.port = port self.mongo_db = mongo_db # 一 启动scrapy项目会先执行此方法加载settings里面的配置文件 @classmethod def from_crawler(cls, crawler): ip = crawler.settings.get('IP') port = crawler.settings.get('PORT') mongo_db = crawler.settings.get('DB') return cls(ip, port, mongo_db) # 二 执行爬虫程序会先执行此方法 def open_spider(self, spider): self.client = MongoClient(self.ip, self.port) def process_item(self, item, spider): new_url = item.get('new_url') new_text = item.get('new_text') nice_num = item.get('nice_num') new_id = item.get('new_id') commit_num = item.get('commit_num') new_content = item.get('new_content') user_name = item.get('user_name') new_data = { 'new_url': new_url, 'new_text': new_text, 'nice_num': nice_num, 'new_id': new_id, 'commit_num': commit_num, 'new_content': new_content, } self.client[self.mongo_db][user_name].insert_one(new_data) return item def close_spider(self, spider): self.client.close() # class MysqlSpiderNewListPipeline(object): # # def __init__(self, ip, port, mongo_db): # self.ip = ip # self.port = port # self.mongo_db = mongo_db # # # 一 启动scrapy项目会先执行此方法加载settings里面的配置文件 # @classmethod # def from_crawler(cls, crawler): # ip = crawler.settings.get('IP') # port = crawler.settings.get('PORT') # mongo_db = crawler.settings.get('DB') # # return cls(ip, port, mongo_db) # # # 二 执行爬虫程序会先执行此方法 # def open_spider(self, spider): # self.client = MongoClient(self.ip, self.port) # # def process_item(self, item, spider): # new_url = item.get('new_url') # new_text = item.get('new_text') # nice_num = item.get('nice_num') # new_id = item.get('new_id') # commit_num = item.get('commit_num') # new_content = item.get('new_content') # user_link = item.get('user_link') # # new_data = { # 'new_url': new_url, # 'new_text': new_text, # 'nice_num': nice_num, # 'new_id': new_id, # 'commit_num': commit_num, # 'new_content': new_content, # 'user_link': user_link # } # # self.client[self.mongo_db]['new_list'].insert_one(new_data) # # return item # # # # def close_spider(self, spider): # self.client.close()
settings.py
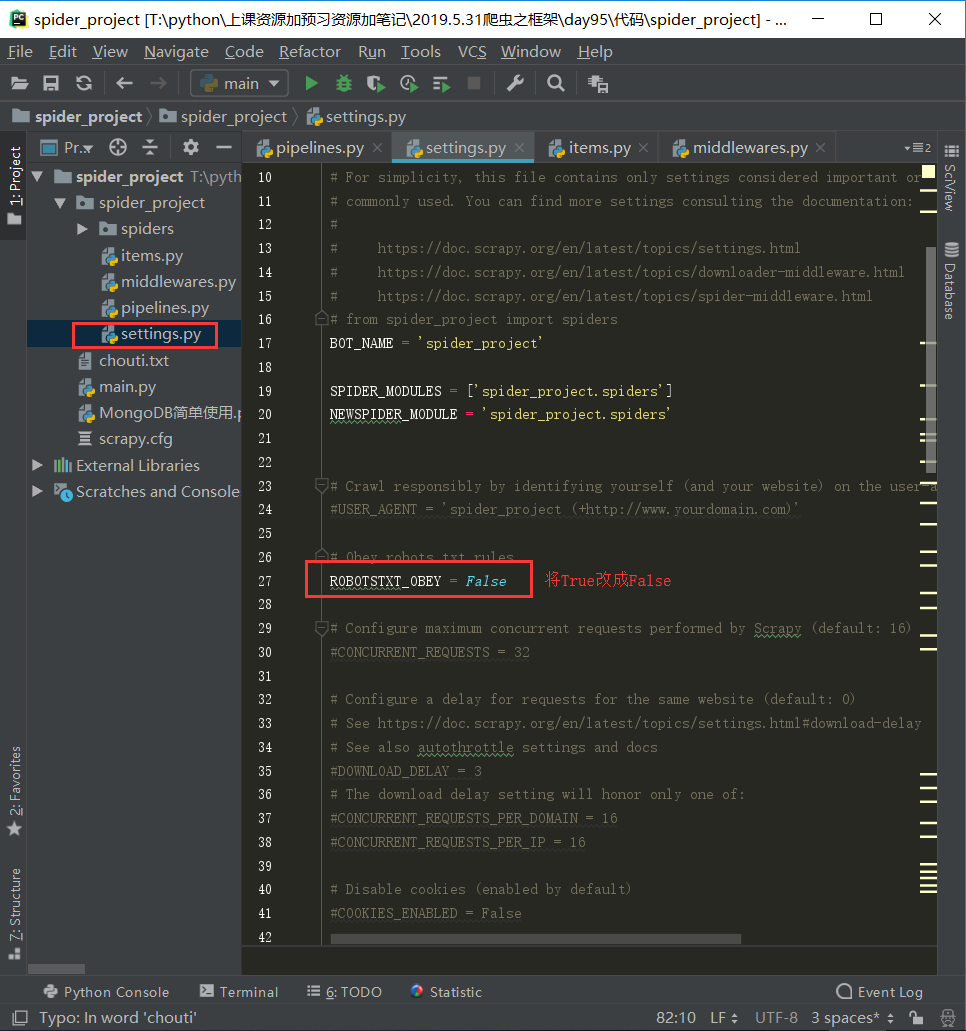
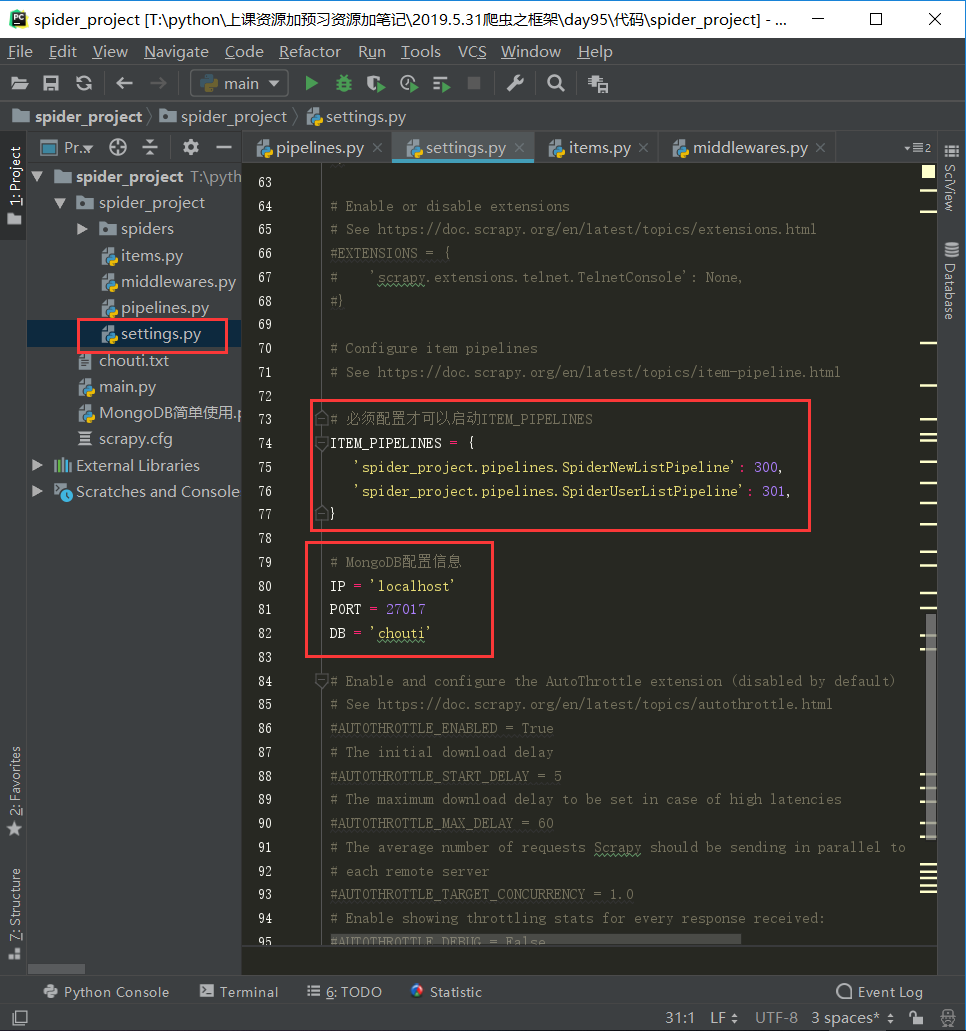
# -*- coding: utf-8 -*- ''' settings里面的参数必须全大写,小写无效 ''' # Scrapy settings for spider_project project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html # from spider_project import spiders BOT_NAME = 'spider_project' SPIDER_MODULES = ['spider_project.spiders'] NEWSPIDER_MODULE = 'spider_project.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'spider_project (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'spider_project.middlewares.SpiderProjectSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'spider_project.middlewares.SpiderProjectDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html # 必须配置才可以启动ITEM_PIPELINES ITEM_PIPELINES = { 'spider_project.pipelines.SpiderNewListPipeline': 300, 'spider_project.pipelines.SpiderUserListPipeline': 301, } # MongoDB配置信息 IP = 'localhost' PORT = 27017 DB = 'chouti' # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
主要就动了以下两张图所标识的地方
spiders下的chouti.py文件
# -*- coding: utf-8 -*- import scrapy from scrapy import Request from spider_project.items import SpiderNewListItem, SpiderUserListItem # from scrapy.http.response.html import HtmlResponse # 去重规则源码 # from scrapy.dupefilters import RFPDupeFilter class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] # 爬虫的第一次访问结果会返回给parse def parse(self, response): # print(response, type(response)) # print(response.text) ''' 解析新闻主页 :param response: :return: ''' # .extract()查找所有 # .extract_first() 查找一个 # 查找标签[] content_list = response.xpath('//div[@class="content-list"]/div[@class="item"]') # print(content_list) for content in content_list: # 查找属性@ # 新闻链接 new_url = content.xpath('.//a/@href').extract_first() # 新闻文本 new_text = content.xpath('.//a/text()').extract_first().strip() if new_text.startswith('/'): new_text = 'https://dig.chouti.com' + new_text # 点赞数 nice_num = content.xpath('.//a[@class="digg-a"]/b/text()').extract_first() # 新闻ID new_id = content.xpath('.//a[@class="digg-a"]/i/text()').extract_first() print(new_id) # 评论数 commit_num = content.xpath('.//a[@class="discus-a"]/b/text()').extract_first() # 新闻详情 new_content = content.xpath('.//span[@class="summary"]/text()').extract_first() # print(new_content) # 发表新闻用户的主页 user_link = 'https://dig.chouti.com' + content.xpath('.//a[@class="user-a"]/@href').extract_first() # 主页新闻items类 items =SpiderNewListItem( new_url=new_url, new_text=new_text, nice_num=nice_num, new_id=new_id, commit_num=commit_num, new_content=new_content, user_link=user_link ) yield items # print(user_link) yield Request(url=user_link, callback=self.parse_user_index) # with open('chouti.txt', 'a', encoding='utf-8') as f: # f.write('%s-%s-%s-%s-%s-%s' % (new_url, new_text, nice_num, new_id, commit_num, user_link) + '\n') # print(new_url) a_s = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract() print(a_s) for a in a_s: new_index_url = 'https://dig.chouti.com' + a print(new_index_url) # Request这个类帮我们提交请求 yield Request(url=new_index_url, callback=self.parse) # pass def parse_user_index(self, response): ''' 解析用户主页 :param response: :return: ''' # .extract()查找所有 # .extract_first() 查找一个 # 查找标签[] content_list = response.xpath('//div[@class="content-list"]/div[@class="item"]') # print(content_list) for content in content_list: # 查找属性@ # 新闻链接 new_url = content.xpath('.//a/@href').extract_first() # 新闻文本 new_text = content.xpath('.//a/text()').extract_first().strip() if new_text.startswith('/'): new_text = 'https://dig.chouti.com' + new_text # 点赞数 nice_num = content.xpath('.//a[@class="digg-a"]/b/text()').extract_first() # 新闻ID new_id = content.xpath('.//a[@class="digg-a"]/i/text()').extract_first() # 评论数 commit_num = content.xpath('.//a[@class="discus-a"]/b/text()').extract_first() # 新闻详情 new_content = content.xpath('.//span/[@class="summary"]/text()').extract_first() # 用户名 user_name = content.xpath('//div[@class="tu"]/a/text()').extract_first() print(user_name) # with open('chouti.txt', 'a', encoding='utf-8') as f: # f.write('%s-%s-%s-%s-%s-%s' % (new_url, new_text, nice_num, new_id, commit_num, user_link) + '\n') # print(new_url) items = SpiderUserListItem( new_url=new_url, new_text=new_text, nice_num=nice_num, new_id=new_id, commit_num=commit_num, new_content=new_content, user_name=user_name ) yield items a_s = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract() # print(a_s) for a in a_s: new_index_url = 'https://dig.chouti.com' + a # print(new_index_url) # Request这个类帮我们提交请求 yield Request(url=new_index_url, callback=self.parse_user_index)
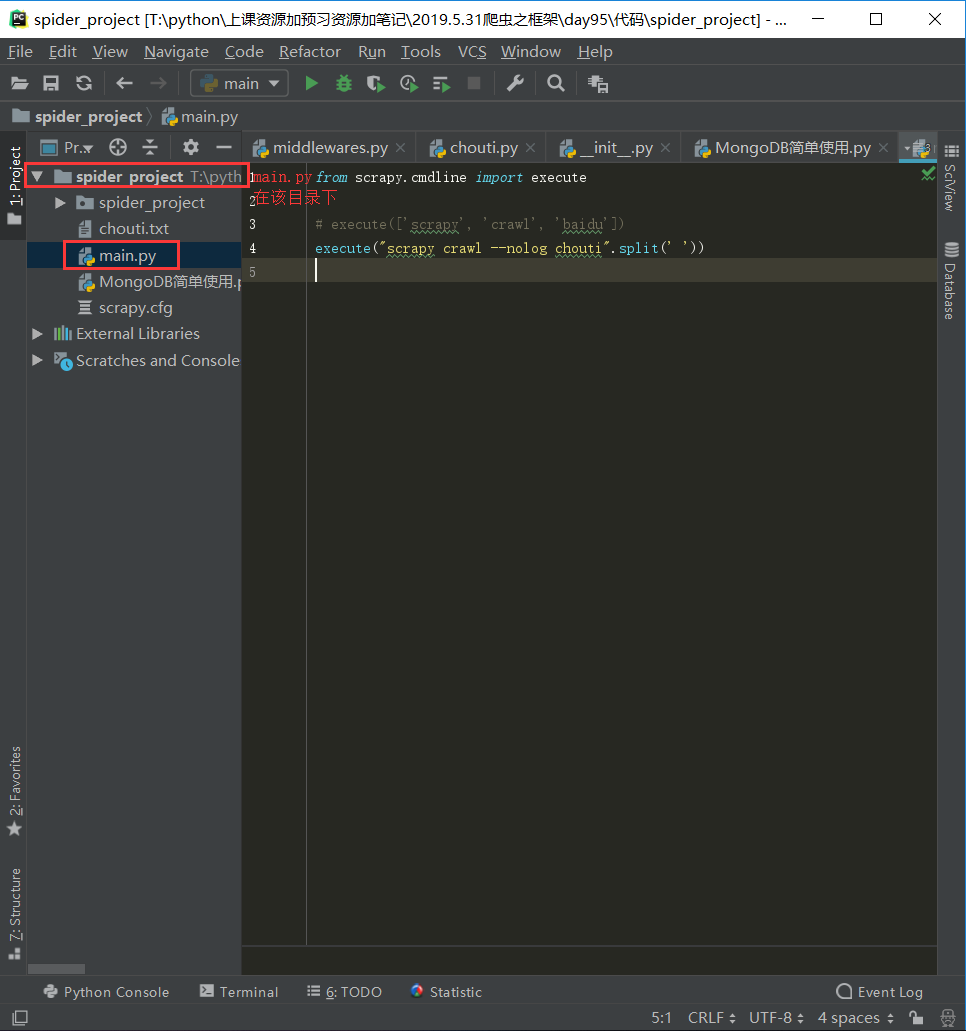
main.py文件
from scrapy.cmdline import execute # execute(['scrapy', 'crawl', 'baidu']) execute("scrapy crawl --nolog chouti".split(' '))
提醒:
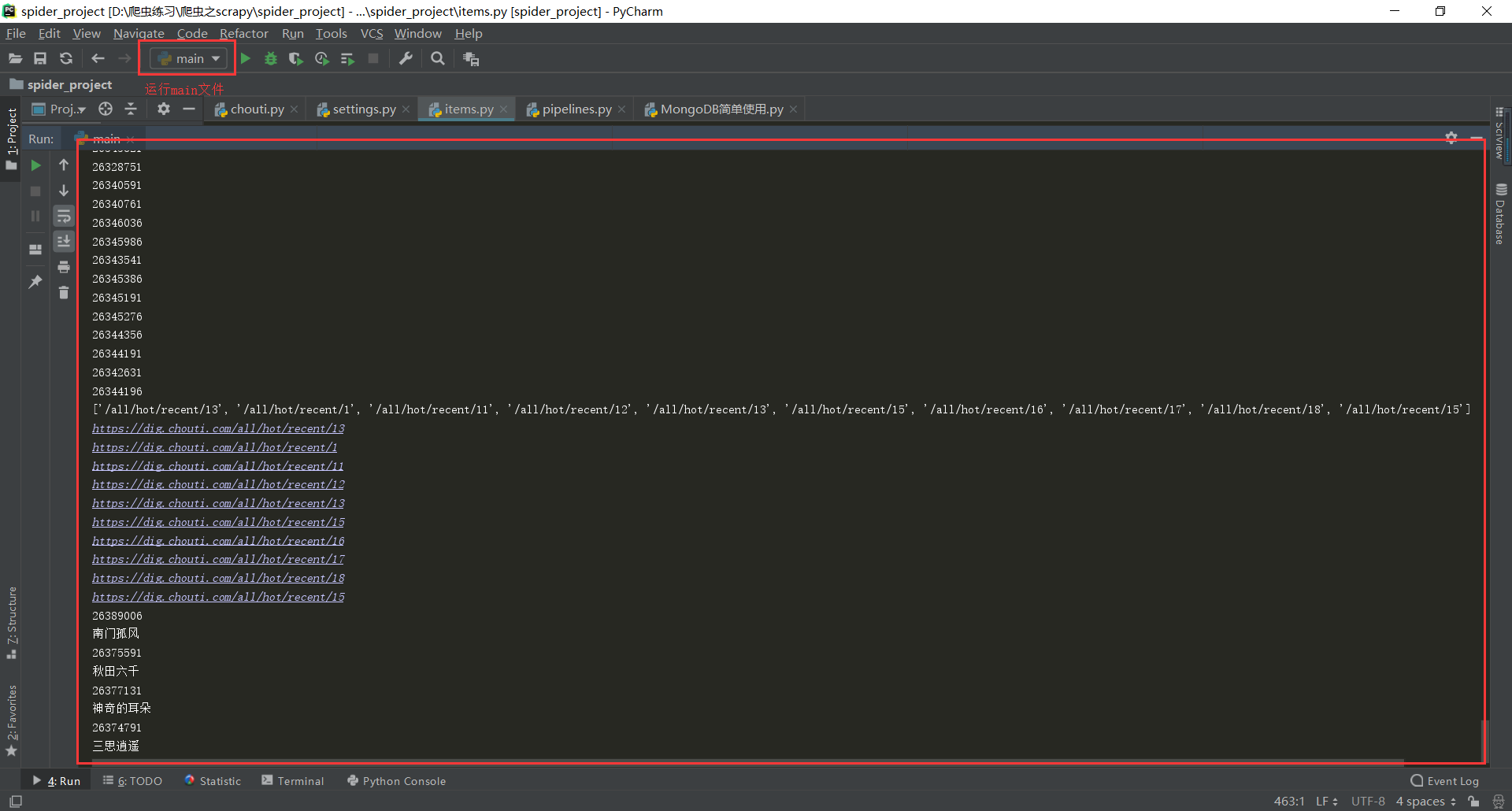
结果(运行的是main.py文件)
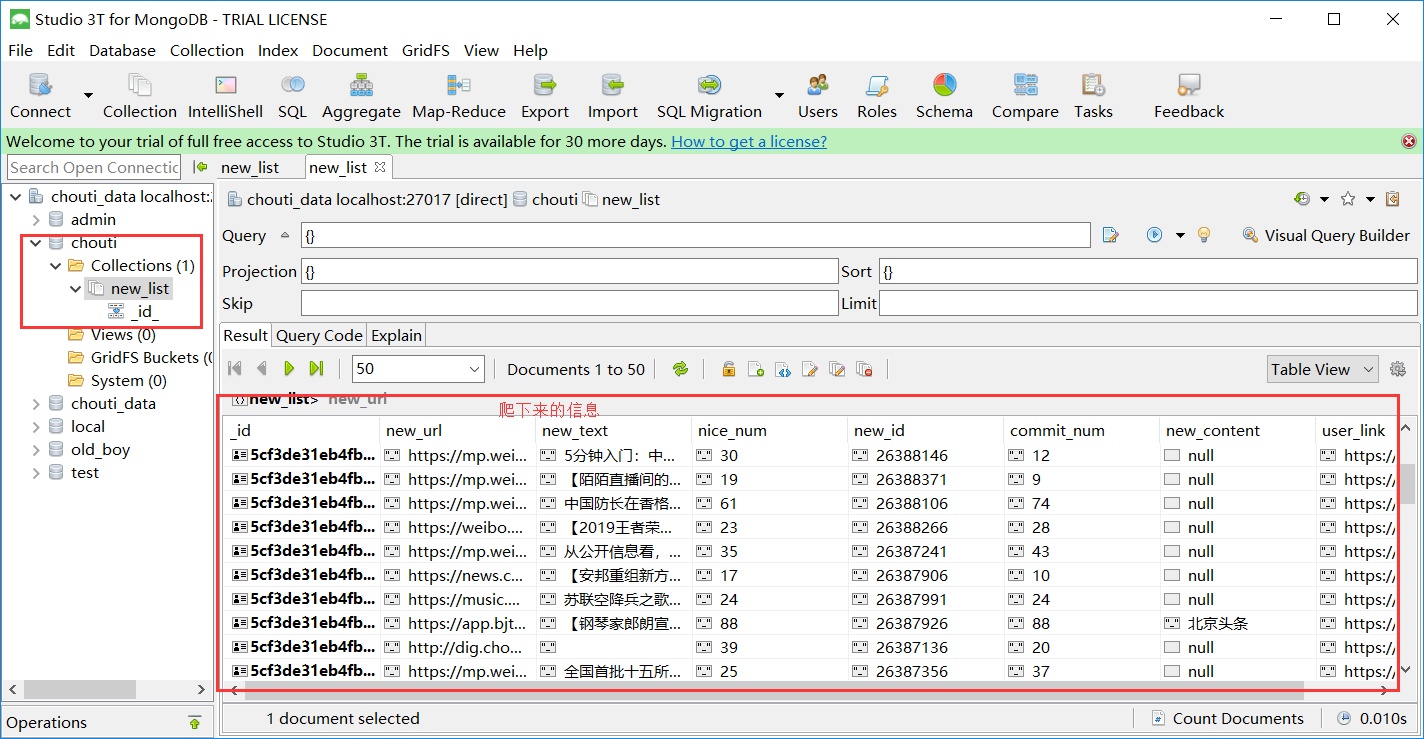

 浙公网安备 33010602011771号
浙公网安备 33010602011771号