


数据库之索引
索引
什么是索引
索引是一种,单独的,物理层面的数据结构,其作用是用于加速查询
生活中的索引:
例如查字典:先查目录,可以根据笔画,偏旁,拼音等方式,来快速定位需要查询的字
为什么需要索引
mysql把数据存储到硬盘中,硬盘读写速度非常慢
一个应用程序,本质上就是再对数据进行增删改查
一旦数据量比较大时,硬盘的响应会变慢,给用户的感觉是应用横线非常慢
查询数据时是应用程序使用中频率最高的操作,如果有一百次数据操作,可能90次是查询
索引最终目的就是提升查询速度,因为对数据库的修改频率低
索引带来的问题
例如800页的数据,可能需要10页的索引
1.添加索引后,整体的数据更大了(占用额外的磁盘空间)
2.由于有了索引,多数数据的添加修改删除,都会引发索引的重建(效率降低)
误区:
索引不是越多越好
索引的实现
查询之所以慢的原因,数据量大是一个问题
最核心的问题就是硬盘的IO速度问题
mysql通过B+树结构来组织数据
由于硬盘设计原理导致每一次读取数据必须花费9ms时间来查找地址
9ms是固定的,没办法降低,只能想办法降低IO次数,来提高速度
操作系统有一个预读取的优化机制
比如你要读取地址为IO的数据,操作系统会把相邻的数据也读取到内容,来减少读取次数
mysql通过B+树这种结构来减少IO次数
B+树中每一个磁盘块,有两个数据项,一块三个地址,在查询时,会比较大小
如果小于左边,就访问p1地址,如果大于右边,就访问p3地址,否则就访问中间p2地址
与二分法原理相同,只不过每次把数据分成三段
图如下图:
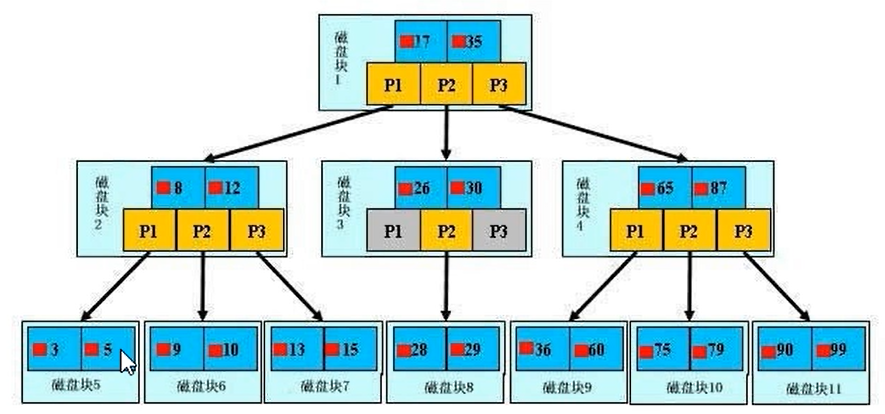
树的结构越低越好,所以建议把数据量小的作为索引,来降低高度
聚焦索引(主键)
主键索引,速度快,因为只要根据id就能找到叶子节点,那么改行的所有数据都拿到了
innoDB需要用主键索引来建立数据结构
所以每一个表都应该有主键
辅助索引
除了主键索引之外的所有的索引都是辅助索引
辅助索引会单独创建树结构,其中存储索引数据本身以及修改数据对应主键值
查找过程中可能出现的情况
覆盖索引:是在当前树结构中就拿到了所有需要的数据
回表:是在辅助索引中没有查询到需要的数据,就需要拿着id回到主键索引中查找
查询速度
主键 > 覆盖索引 > 回表
编写sql时,如果有主键值,优先使用主键来查询
如果没有主键值,需要用辅助索引,这时候尽量少查字段,最好保证需要的数据就在辅助索引中
避免 select *
索引的优化分为两方面
1.索引结构的优化
数据量小的
重复度低的
2.sql语句的优化
sql语句中条件应该是索引字段
避免在模糊匹配中,在最前面使用%,需要全表扫描
select count(*) from usr where name like "%Trish";
不要对主键进行运算就像:select count(*) from usr where id * 10 = 100;
需要写成:select count(*) from usr where id = 100/10;这样会好很多
3.and与or
在and语句中mysql中会优先查询带有索引的字段,无论书写位置在前还是在后
name有索引,但是重复度高,id没有索引,email有,会跳过id直接查email
select count(*) from usr where name = "Trish" and id = 1 and email = "xxx";
and语句没有优化的余地
or语句中不会自动选择有索引的,是依次执行,无论是否有条件成立,都查一遍
所以一定避免使用or语句
or语句优化
select *from usr where name = "Trish" or name = "Virgil";
select *from usr where name in ("Trish","Virgil");
select *from usr where name = "Trish"
union
select *from usr where name = "Virgil";
4.多字段联合索引
如果要查询的字段较多,而且如果为每一个字段都创建索引,会造成额外的容量的占用,
并且当你修改一条记录时,有可能所有索引都需要重建,会非常慢
顺序是重点,
创建索引时,把重复度低的字段放在最左边,依次排开
create index all_index on usr(email,name,gender);
缩写sql时,保证重复度低的字段出现在sql中即可
创建索引的语法
create index 索引的名字 on 表名(字段名)
删除索引
drop index 索引名字 on 表名;
例子:drop index n_index on usr;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号