1 CPU版本
1.1 代码
void matrix_multiply_block(const float *M, const float *N, float *P, int M_rows, int M_cols, int N_rows, int N_cols)
{
int siz = BLOCK_SIZE;
for (int b_row = 0; b_row < M_rows; b_row += siz)
for (int b_col = 0; b_col < N_cols; b_col += siz)
for (int b_k = 0; b_k < M_cols; b_k += siz) {
for (int i = 0; i < siz; i++) {
int row = b_row + i;
if (row >= M_rows) break;
for (int j = 0; j < siz; j++) {
int col = b_col + j;
if (col >= N_cols) break;
float sum = P[row * N_cols + col];
for (int k = 0; k < siz; k++) {
if (b_k + k >= M_cols) break;
sum += M[row * M_cols + b_k + k] * N[(b_k + k) * N_cols + col];
}
P[row * N_cols + col] = sum;
}
}
}
}
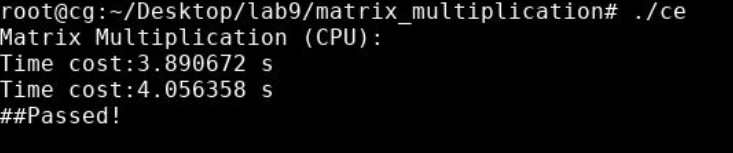
1.2 实验结果
![image-20230518133805449]()
2 GPU版本
2.1 代码
__global__ void kernel_matrix_multiply_block(float *M, float *N, float *P, int M_rows, int M_cols, int N_rows, int N_cols)
{
int tx = threadIdx.x;
int ty = threadIdx.y;
int siz = BLOCK_SIZE;
int row_in_P = blockIdx.y * siz + ty;
int col_in_P = blockIdx.x * siz + tx;
__shared__ float M_sub[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float N_sub[BLOCK_SIZE][BLOCK_SIZE];
float sum = 0;
for (int j = 0; j < (M_cols - 1) / siz + 1; j++) {
int M_row = row_in_P;
int M_col = j * siz + tx;
int N_row = j * siz + ty;
int N_col = col_in_P;
if (M_row < M_rows && M_col < M_cols) M_sub[ty][tx] = M[M_row * M_cols + M_col];
else M_sub[ty][tx] = 0;
if (N_row < N_rows && N_col < N_cols) N_sub[ty][tx] = N[N_row * N_cols + N_col];
else N_sub[ty][tx] = 0;
__syncthreads();
for (int k = 0; k < siz; k++) sum += M_sub[ty][k] * N_sub[k][tx];
__syncthreads();
}
if (row_in_P < M_rows && col_in_P < N_cols) P[row_in_P * N_cols + col_in_P] = sum;
}
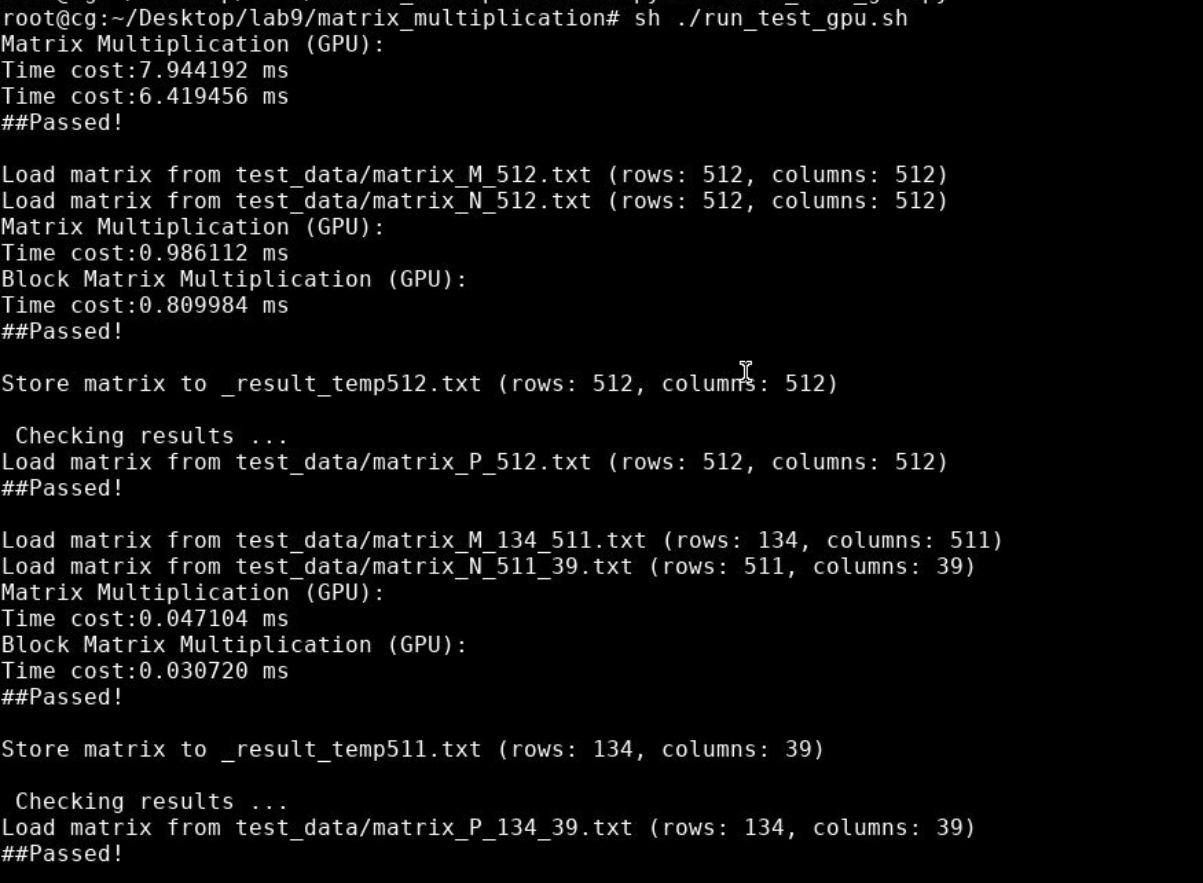
2.1 实验结果
![image-20230518133220845]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号