
爬取搜狗动漫热搜榜数据
一.主题式网络爬虫设计方案
1.爬虫名称:爬取搜狗动漫热搜榜数据
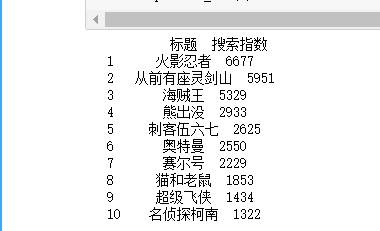
2.网络爬虫爬取内容:动漫名称,搜索指数
3.概述:打开网址源文件分析并精确找到我们所需要的数据所在节点(标签),然后抓取数据保存后利用各种库进行数据可视化处理与数据分析
技术难点:各种库的使用和数据的分析
二.主题页面的结构特征分析
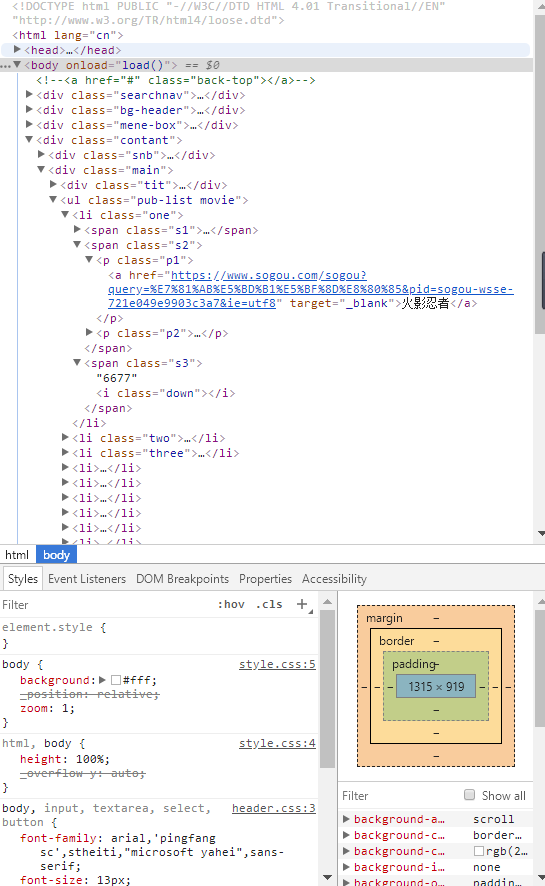
打开网址http://top.sogou.com/animation/all_1.html 查看源文件为html结构
根据所需爬取的内容可以找到对应的节点(标签) 为<p class="p1">和<span class="s3">
三、网络爬虫程序设计
1.数据采集
import csv import requests from bs4 import BeautifulSoup import bs4 import pandas as pd import scipy as sp from numpy import genfromtxt import matplotlib from pandas import DataFrame import matplotlib.pyplot as plt from scipy.optimize import leastsq import urllib.request as urlrequest url = 'http://top.sogou.com/animation/all_1.html' headers = {'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫 r=requests.get(url)#发送get请求 r.encoding=r.apparent_encoding#统一编码 t=r.text soup=BeautifulSoup(t,'lxml')#提取html并解析内容 a=[] b=[] for i in soup.find_all(class_="p1"): a.append(i.get_text().strip()) for j in soup.find_all('span', class_="s3"): b.append(j.get_text().strip()) data=[a,b] df=pd.DataFrame(data,index=["标题","搜索指数"],columns=range(1,11)) print(df.T) rebo="E:/1.xlsx" df.T.to_excel(rebo) df.to_csv('搜狗动漫排行.csv')#保存文件 f = open(r"C:\Users\Hasee\搜狗动漫排行.csv",encoding="utf-8") train1 = pd.read_csv(f)
2.数据清洗
df = pd.DataFrame(pd.read_csv('搜狗动漫排行.csv')) df.head() df.duplicated()#查找重复值

df.isnull().sum()#查找有无空值

df[df.isnull().values==True]#缺失值查找

3数据分析及可视化
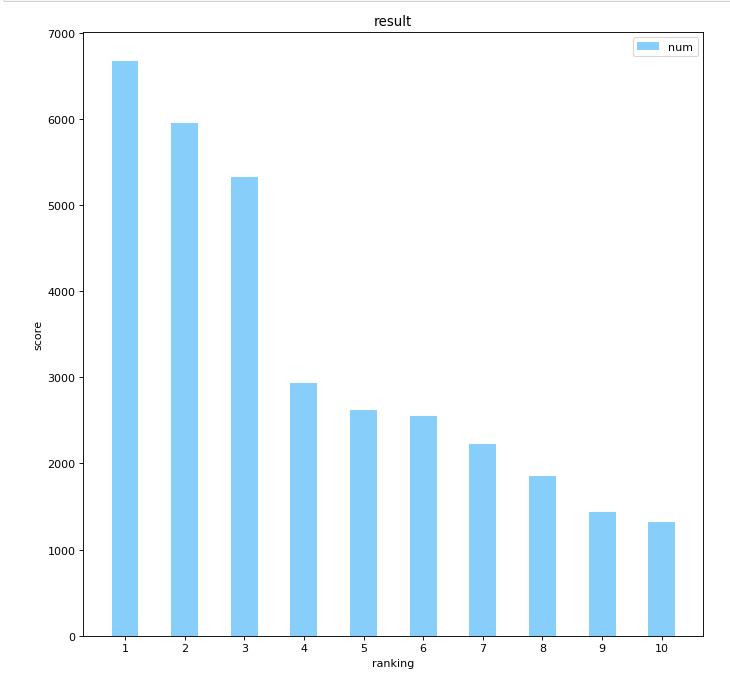
#前10数据数据可视化 # 创建一个点数为 8 x 6 的窗口, 并设置分辨率为 80像素/每英寸 plt.figure(figsize=(10, 10), dpi=80) # plt.subplot(1, 1, 1) # 柱子总数 N = 10 # 包含每个柱子对应值的序列 values = (6677,5951,5329,2933,2625,2550,2229,1853,1434,1322) # 包含每个柱子下标的序列 index = np.arange(N) # 柱子的宽度 width = 0.45 p2 = plt.bar(index, values, width, label="num", color="#87CEFA") # 设置横轴标签 plt.xlabel('ranking') # 设置纵轴标签 plt.ylabel('score') # 添加标题 plt.title('result') # 添加纵横轴的刻度 plt.xticks(index, ('1','2','3','4','5','6','7','8','9','10')) # plt.yticks(np.arange(0, 10000, 10)) # 添加图例 plt.legend(loc="upper right") plt.show()
4建立回归方程
chinese=matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc') plt.rcParams['font.sans-serif']=['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False filename="E:/1.xlsx" colnames=["rank","name","hot"] df=pd.read_excel(filename,skiprows=1,names=colnames) X=df.rank Y=df.hot #确定x,y轴 def func(params,x): a,b,c=params return a*x*x+b*x+c def error(params,x,y): #设置误差函数 return func(params,x)-y p0=[78,0] def main(): #主函数 plt.figure(figsize=(10,6)) #画布尺寸 p0=[178,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(0,9,10) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) #画拟合曲线 plt.legend() plt.title("动漫排名与热度回归方程") plt.grid() plt.show() main() plt.savefig(fname="E:/动漫排名与热度回归方程.jpg",figsize=[1,1])#保存图像

5.整体代码
import csv import requests from bs4 import BeautifulSoup import bs4 import pandas as pd import scipy as sp from numpy import genfromtxt import matplotlib from pandas import DataFrame import matplotlib.pyplot as plt from scipy.optimize import leastsq import urllib.request as urlrequest url = 'http://top.sogou.com/animation/all_1.html' headers = {'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫 r=requests.get(url)#发送get请求 r.encoding=r.apparent_encoding#统一编码 t=r.text soup=BeautifulSoup(t,'lxml')#提取html并解析内容 a=[] b=[] for i in soup.find_all(class_="p1"): a.append(i.get_text().strip()) for j in soup.find_all('span', class_="s3"): b.append(j.get_text().strip()) data=[a,b] df=pd.DataFrame(data,index=["标题","搜索指数"],columns=range(1,11)) print(df.T) rebo="E:/1.xlsx" df.T.to_excel(rebo) df.to_csv('搜狗动漫排行.csv')#保存文件 f = open(r"C:\Users\Hasee\搜狗动漫排行.csv",encoding="utf-8") train1 = pd.read_csv(f) df = pd.DataFrame(pd.read_csv('搜狗动漫排行.csv')) df.head() df.duplicated()#查找重复值 df.isnull().sum()#查找有无空值 df[df.isnull().values==True]#缺失值查找 #前10数据数据可视化 # 创建一个点数为 8 x 6 的窗口, 并设置分辨率为 80像素/每英寸 plt.figure(figsize=(10, 10), dpi=80) # plt.subplot(1, 1, 1) # 柱子总数 N = 10 # 包含每个柱子对应值的序列 values = (6677,5951,5329,2933,2625,2550,2229,1853,1434,1322) # 包含每个柱子下标的序列 index = np.arange(N) # 柱子的宽度 width = 0.45 p2 = plt.bar(index, values, width, label="num", color="#87CEFA") # 设置横轴标签 plt.xlabel('ranking') # 设置纵轴标签 plt.ylabel('score') # 添加标题 plt.title('result') # 添加纵横轴的刻度 plt.xticks(index, ('1','2','3','4','5','6','7','8','9','10')) # plt.yticks(np.arange(0, 10000, 10)) # 添加图例 plt.legend(loc="upper right") plt.show() chinese=matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc') plt.rcParams['font.sans-serif']=['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False filename="E:/1.xlsx" colnames=["rank","name","hot"] df=pd.read_excel(filename,skiprows=1,names=colnames) X=df.rank Y=df.hot #确定x,y轴 def func(params,x): a,b,c=params return a*x*x+b*x+c def error(params,x,y): #设置误差函数 return func(params,x)-y p0=[78,0] def main(): #主函数 plt.figure(figsize=(10,6)) #画布尺寸 p0=[178,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(0,9,10) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) #画拟合曲线 plt.legend() plt.title("动漫排名与热度回归方程") plt.grid() plt.show() main() plt.savefig(fname="E:/动漫排名与热度回归方程.jpg",figsize=[1,1])#保存图像
四.结论
1.对数据的分析与可视化处理可以展现各数据之间的差距大小,简洁明了。
2小结:python的使用要联系到非常多的库,代码的准确性也决定了能否实现所需,现在的自己运用还不熟练,理解也没有完全到位,很多地方有错误,还需改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号