
爬取今日体育热点排行
import requests from bs4 import BeautifulSoup import pandas as pd url = 'http://top.baidu.com/buzz?b=11&c=513&fr=topbuzz_b342_c513' headers = {'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫 r=requests.get(url)#发送get请求 r.encoding=r.apparent_encoding#统一编码 t=r.text soup=BeautifulSoup(t,'lxml')#提取html并解析内容 title=[]#创建两个列表 index=[] for y in soup.find_all(class_="keyword"):#使用find all方法 title.append(y.get_text().strip()) for x in soup.find_all('td', class_="last"):#查找以td标签的内容 index.append(x.get_text().strip()) data=[title,index] print(data) s=pd.DataFrame(data,index=["标题","搜索指数"])#使用工具使其可视化 print(s.T)
打开我们所需要爬取的百度今日热点排行网站,点击查看源文件分析网页结构发现我们所需的class标签在<tbody>下面
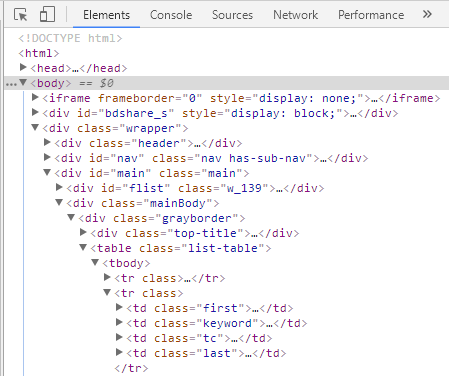
利用requests和beautifulsoup工具解析并得出结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号