
深入理解 JVM - 垃圾回收
本文由 简悦 SimpRead 转码, 原文地址 https://blog.csdn.net/weixin_38405354/article/details/105593015
深入理解 JVM - 垃圾回收
4、JVM 垃圾回收
- 垃圾判断算法
- GC 算法
- 垃圾回收器的实现
4.1 垃圾判断的算法
- 引用计数算法(Reference Counting)
- 根搜索算法(Root Tracing)
4.1.1 引用计数算法(Reference Counting)
- 给对象添加一个引用计算器,当有一个地方引用它,计算器就加 1,当引用失效,计数器减 1,任何时刻计数器为 0 的对象就是不可能再被使用的;
- 引用计数算法无法解决对象循环引用的问题。

当出现,A 对象引用 B 对象,B 对象引用 A 对象,当外界对 A 和 B 的引用消失时,A 和 B 的对象是无法通过引用计数算法实现回收的。
4.1.2 根搜索算法(Root Tracing)
-
在实际的生产语言中(Java、C++ 等),都是使用根搜索算法判定对象是否存活;
-
算法基本思路就是通过一系列的成为 “GC Roots” 的点作为起始进行向下搜索,当一个对象到 GC Roots 没有任何引用链(Reference Chain)相连,则证明此对象是不可用的。
-
在 Java 语言中,GC Roots 包括:
- 在 VM 栈(帧中的本地变量)中的引用;
- 方法区中的静态引用
- JNI(即一般说的 Native 方法)中的引用
- 方法区:
- Java 虚拟机规范表示不要求虚拟机在这区实现 GC,这区 GC 的 “性价比” 一般比较低;
- 在堆中,尤其是新生代,常规应用进行一次 GC 一般可以回收 70%-95% 的空间,而方法区的 GC 效率远小于此;
- 当前的商业 JVM 都有实现方法区的 GC,主要回收两部分内容:废弃常量与无用类。
- 类回收需要满足 3 个条件:(1)该类所有的实例都已经被 GC,也就是 JVM 中不存在该 Class 的任何实例;(2)加载该类的 ClassLoader 已经被 GC;(3)该类对应的 java.lang.Class 对象没有在任何地方被应用,如不能再任何地方通过反射访问该类的方法。
- 在大量使用反射、动态代理、CGLIB 等字节码框架、动态生成 JSP 以及 OSGI 这类频繁自定义 ClassLoader 的场景都需要 JVM 具备类卸载的支持以保证方法区不会溢出。
4.2 JVM 常见 GC 算法
- 标记 - 清除算法(Mark-Sweep)
- 标记 - 整理算法(Mark-Compact)
- 复制算法(Copying)
- 分代算法(Generational)
4.2.1 标记 - 清除算法(Mark-Sweep)
- 算法分为 “标记” 和“清除”两个阶段,首先标记出所有需要回收的对象,然后回收所有需要回收的对象。
- 缺点:
- 效率问题:标记和清理两个过程效率都不高,需要扫描所有对象
- 空间问题:标记清理之后会产生大量不连续的内存碎片,空间碎片太多可能会导致后续使用中无法找到足够的内存而提前出发另一次垃圾搜集动作。

4.2.2 复制算法(Copying)
- 将可用内存划分为两块,每次只使用其中的一块,当半区内存用完了,仅将还存活的对象复制到另外一块上面,然后就把原来整块内存空间一次性清理掉。
- 这样使得每次内存回收都是对整个半区的回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存就可以了,实现简单,运行高效。
- 只是这种算法的代价是将内存缩小为原来的一半,代价高昂。
- 现在的商业虚拟机中都是用了这一种收集算法来回收新生代。
- 将内存分为一块较大的 eden 空间和 2 块较少的 survivor 空间,每次使用 eden 和其中一块 survivor,当回收时将 eden 和 survivor 还存活的对象一次性拷贝到另外一块 survivor 空间上,然后清理掉 eden 和用过的 survivor。
- Oracle Hotspot 虚拟机默认 eden 和 survivor 的大小比例是 8:1,也就是每次只有 10% 的内存是浪费的。
- 复制收集算法在对象存活率高的时候,效率有所下降。
- 如果不想浪费 50% 的空间,就需要有额外的空间进行分配担保用于应付半区内存中所有对象都 100% 存活的极端情况,所以在老年代一般不能选用这种算法。

优点: - 只需要扫描存活的对象,效率更高;
- 不会产生碎片;
- 需要浪费额外的内存作为复制区;
- 复制算法非常适合生命周期比较短的对象,因为每次 GC 总能回收大部分的对象,复制的开销比较小;
- 根据 IBM 的专门研究,98% 的 Java 对象只会存活 1 个 GC 周期,对这些对象很适合用复制算法。而且不用 1:1 的划分工作区和复制区的空间。
4.2.3 标记 - 整理算法(Mark-Compact)
- 标记过程仍然一样,但后续步骤不是进行直接清理,而是令所有存活的对象向一端移动,然后直接清理掉边界以外的内存。

优点: - 没有内存碎片;
- 比 Mark-Sweep 标记清除算法耗费更多的时间进行 compact
4.2.4 分代收集算法(Generational Collecting)
- 当前商业虚拟机的垃圾收集都是采用 “分代收集” 算法,根据对象不同的存活周期将内存划分为几块;
- 一般是把 Java 堆分作新生代和老年代,这样就可以根据各个年代的特点采用最适合的收集算法,比如新生代每次 GC 都有大批对象死去,只有少量存活,那就选用复制算法只需要付出少量存活对象的复制成本就可以完成收集。
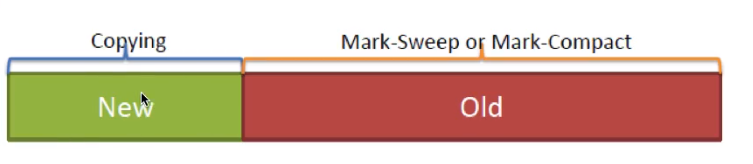
- Hotspot JVM6 中共划分为三个代:年轻代(Young Generation
)、老年代(Old Generation)和永久代(Permanent Generation)

4.2.4.1 年轻代(Young Generation)
- 新生成的对象都放在新生代。年轻代用复制算法进行 GC(理论上,年轻代对象的生命周期非常短,所以适合复制算法);
- 年轻代分三个区。一个 Eden 区,两个 Survivor 区(可以通过参数设置 Survivor 个数)。对象在 Eden 区中生成。当 Eden 区满时,还存活的对象将复制到一个 Survivor 区,当这个 Survivor 区满时,此区的存活对象将被复制到另外一个 Survivor 区,当第二个 Survivor 区也满的时候,从第一个 Survivor 区复制过来的并且此时还存活的对象,将被复制到老年代。2 个 Survivor 时完全对称,轮流替换。
- Eden 和 2 个 Survivor 的缺省比例是 8:1:1,也就是 10% 的空间会被浪费。可以根据 GC log 的信息调整大小的比例。
4.2.4.2 老年代 (Old Generation)
- 存放了经过一次或多次 GC 还存活的对象;
- 一般采用 Mark-Sweep 或 Mark-Compact 算法进行 GC
- 有多种垃圾收集器可以选择。每种垃圾收集器可以看作一个 GC 算法的具体实现。可以根据具体应用的需求选用合适的垃圾收集器(追求吞吐量?追求最短的响应时间)
4.2.4.3 永久代 (Permanent Generation)
- 并不属于堆,但是 GC 也会涉及到这个区域
- 存放了每个 Class 的结构信息,包括常量池、字段描述、方法描述。与垃圾收集要收集的 Java 对象关系不大。
4.3 内存结构

4.3.1 内存分配
1、堆上分配
- 大多数情况在 Eden 上分配,偶尔会直接在 old 上分配,细节决定于 GC 的实现
2、栈上分配
- 原子类型的局部变量
4.3.2 内存回收
1、 GC 要做的是将那些 dead 的对象所占用的内存回收掉
- Hotspot 认为没有引用的对象是 dead 的;
- Hotspot 将引用分为四种:Strong(强引用)、Soft(软引用)、Weak(弱引用)、Phantom(虚引用)
-Strong 即默认通过 Object o=new Object() 这种方法赋值的引用
-Soft、Weak、Phantom 这三种则都是继承 Reference - 在 Full GC 时会对 Reference 类型的引用进行特殊处理
-Soft:内存不够时一定会被 GC、长期不用也会被 GC
-Weak:一定会被 GC,当被 mark 为 dead,会在 ReferenceQueue 中通知
-Phantom:本来就没引用,当从 jvm heap 中释放时会通知
详情点击
4.4 GC 的时机
- 在分代模型的基础上,GC 从时机上分为两种:Scavenge GC 和 Full GC
4.4.1 Scavenge GC (Minor GC)
- 触发时机:新对象生成时,Eden 空间满了
- 理论上 Eden 区大多数对象会在 Scavenge GC 回收,复制算法的执行效率会很高,Scavenge GC 时间比较短。
4.4.2 Full GC
- 对整个 JVM 进行整理,包括 Young、Old 和 Perm
- 主要的出发时机:1) Old 满了;2)Perm 满了;3)system.gc()
- 效率很低,尽量减少 GC。
4.5 垃圾回收器(Garbage Collector)

- 分代模型:GC 的宏观愿景;
- 垃圾收集器:GC 的具体实现;
- Hotspot JVM 提供多种垃圾回收器,我们需要根据具体应用的需要采用不同的回收器;
- 没有万能的垃圾回收器,每种垃圾回收器都有自己的适用场景。
4.5.1 垃圾收集器的 “并行” 和“并发”
- 并行(Parallel):指多个收集器的线程同时工作,但是用户线程处于等待状态;
- 并发(Concurrent):指收集器在工作的同时,可以允许用户线程工作。
- 并发不代表解决了 GC 停顿的问题,在部分步骤还是要停顿。比如在收集器标记垃圾的时候。但在清除垃圾的时候,用户线程可以和 GC 线程并发执行。

- 并发不代表解决了 GC 停顿的问题,在部分步骤还是要停顿。比如在收集器标记垃圾的时候。但在清除垃圾的时候,用户线程可以和 GC 线程并发执行。
- JVM 有两种运行模式 Server 与 Client。两种模式的区别在于,Client 模式启动速度较快,Server 模式启动较慢;但是启动进入稳定期长期运行之后 Server 模式的程序运行速度比 Client 要快很多。这是因为 Server 模式启动的 JVM 采用的是重量级的虚拟机,对程序采用了更多的优化;而 Client 模式启动的 JVM 采用的是轻量级的虚拟机。所以 Server 启动慢,但稳定后速度比 Client 远远要快。
4.5.2 Serial 收集器
单线程收集器,收集时会暂停所有工作线程(Stop The World),使用复制收集算法,虚拟机运行在 Client 模式时的默认新生代收集器。
- 最早的收集器,单线程进行 GC;
- New 和 Old Generation 都可以使用;
- 在新生代,采用复制算法;在老年代,采用 Mark-Compact 算法;
- 因为是单线程 GC,没有多线程切换的额外开销,简单使用;
- Hotspot Client 模型缺省的收集器

4.5.3 ParNew 收集器
ParNew 收集器就是 Serial 的多线程版本,除了使用多个收集线程外,其余行为包括算法、STW、对象分配规则、回收策略等都与 Serial 收集器一模一样。对应的这种收集器是虚拟机运行在 Server 模型的默认新生代收集器,在单 CPU 的环境中,ParNew 收集器并不会比 Serial 收集器有更好的效果。
- Serial 收集器在新生代的多线程版本;
- 使用复制算法(因为针对新生代);
- 只有在多 CPU 的环境下,效率才会比 Serial 收集器高;
- 可以通过 - XX:ParallelGCThreads 来控制 GC 线程数的多少。需要结合具体的 CPU 个数;
- Server 模式下新生代的缺省收集器。
4.5.4 Parallel Scavenge 收集器
Parallel Scavenge 收集器也是一个多线程收集器,也是使用复制算法,但它的对象分配规则和回收策略都与 ParNew 收集器有所不同,它是以吞吐量最大化(即 GC 时间占总运行时间最小)为目标的收集器实现,它允许较长时间的 STW 换取总吞吐量最大化。
4.6.5 Serial Old 收集器
Serial Old 收集器是单线程收集器,使用标记 - 整理算法,是老年代的收集器。
4.5.6 Parallel Old 收集器
Serial Old 收集器是老年代版本的吞吐量优先收集器,使用多线程和标记 - 整理算法,JVM1.6 提供,再此之前,新生代使用 PS 收集器的话,老年代除 Serial Old 外别无选择,因为 PS 无法与 CMS 收集器配合工作。
- Parallel Scavenge 在老年代的实现;
- 在 JVM 1.6 才出现 Parallel Old;
- 采用多线程,Mark-Compact 算法;
- 更注重吞吐量;
- Parallel Scabenge + Parallel Old = 高吞吐量,但 GC 停顿可能不理想。

4.5.7 CMS(Concurrent Mark Sweep) 收集器
CMS 收集器是一种以最短停顿时间为目标的收集器,使用 CMS 并不能达到 GC 效率最高(总体 GC 时间最小),但它能尽可能降低 GC 时服务的停顿时间,CMS 收集器使用的是标记 - 清除算法。
- 追求最短停顿时间,非常适合 WEB 应用;
- 只针对老年区,一般结合 ParNew 使用;
- Concurrent,GC 线程和用户线程并发工作(尽量并发);
- Mark-Sweep
- 只有在多 CPU 环境下才有意义;
- 使用 - XX:+UseConcMarkSweepGC 打开。
缺点:
- CMS 以牺牲 CPU 资源的代价来减少用户线程的停顿。当 CPU 个数少于 4 的时候,有可能对吞吐量影响非常大;
- CMS 在并发清理的过程中,用户线程还在跑。这时候需要预留一部门空间给用户线程;
- CMS 用 Mark-Sweep,会带来碎片问题。碎片过多的时候回容易频繁出发 Full GC。
4.6 内存泄漏的经典原因
- 对象定义在错误的范围(Wrong Scope)
- 异常(Exception)处理不当
- 集合数据管理不当
4.6.1 对象定义在错误的范围(Wrong Scope)
- 如果 Foo 实例对象的声明较长,会导致临时性内存泄漏。(这里的 names 变量其实只有临时作用)
class Foo{
private String[] names;
public void doIt(int length){
if(names==null||names.length<length)
names=new Sting[length];
populate(names);
print(names);
}
}
- JVM 喜欢声明周期短的对象,这样做已经足够高效
class Fol{
public void doIt(int length){
private String[] names=new Sting[length];
populate(names);
print(names);
}
}
4.6.2 异常(Exception)处理不当
- 错误的做法
Connection conn=DriverManager.getConnection(url,name,password);
try{
String sql="do a query sql";
PreparedStatement stmt=conn.prepareStatement(sql);
ResultSet rs=stmt.executeQuery();
while(rs.next()){
doSomeStuff();
}
rs.close();
conn.close();
}catch(Exception e){
//如果doSomeStuff()抛出异常,rs.close();和conn.close();不会被调用,会导致内存泄漏和db连接泄漏。
//正确的做法应该是把关闭操作放到finally块中。
}
4.6.3 集合数据管理不当
- 当使用 Array-based 的数据结构时(ArrayList、HashMap 等)时,尽量减少 resize
比如 new ArrayList 时,尽量估算 size,在创建的时候把 size 确定;
减少 resize 可以避免没有必要的 array copying,gc 碎片等问题 - 如果一个 List 只需要顺序访问,不需要随机访问(Random Access),用 LinkedList 代替 ArrayList
LinkedList 本质是链表,不需要 resize,但只适用于顺序访问。
4.7 垃圾回收日志与算法深度解析
4.7.1 垃圾回收日志
- Test1
/*
* JVM参数:
* -verbose:gc 输出垃圾回收详情
* -Xms20M jvm启动时堆容量的大小,初始大小
* -Xmx20M jvm堆最大值
* -Xmn10m 堆空间中新生代的大小
*-XX:+PrintGCDetails 打印垃圾回收的日志
* -XX:SurvivorRatio=8 Eden空间和Survivor空间比例是81,即Eden:From:To=8:1:1
*
* PSYoungGen: Parallel Scavenge (新生代垃圾收集器)
* ParOldGen: Parallel Old (老年代垃圾收集器)
*/
public class Test1 {
public static void main(String[] args) {
int size=1024*1024;
byte[] myAllocl1=new byte[2*size];
byte[] myAllocl2=new byte[2*size];
byte[] myAllocl3=new byte[2*size];
byte[] myAllocl4=new byte[2*size];
System.out.println("hello world");
}
}
得到输出结果:(随着数组大小的改变GC和Full GC的结果不一致)
[GC (Allocation Failure) [PSYoungGen: 7127K->792K(9216K)] 7127K->6944K(19456K),
0.0033105 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 792K->0K(9216K)] [ParOldGen:
6152K->6679K(10240K)] 6944K->6679K(19456K), [Metaspace: 2738K->2738K(1056768K)],
0.0066545 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
hello world
Heap
PSYoungGen total 9216K, used 2290K [0x00000000ff600000,
0x0000000100000000, 0x0000000100000000)
eden space 8192K, 27% used
[0x00000000ff600000,0x00000000ff83c988,0x00000000ffe00000)
from space 1024K, 0% used
[0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
to space 1024K, 0% used
[0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
ParOldGen total 10240K, used 6679K [0x00000000fec00000,
0x00000000ff600000, 0x00000000ff600000)
object space 10240K, 65% used
[0x00000000fec00000,0x00000000ff285d58,0x00000000ff600000)
Metaspace used 2745K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 293K, capacity 386K, committed 512K, reserved 1048576K
给程序添加 - verbose:gc 和 XX:+PrintGCDetails 参数,当程序发生垃圾回收时,就会将垃圾回收的过程信息打印出来。
下面来对结果进行分析:
[GC (Allocation Failure) [PSYoungGen: 7127K->792K(9216K)] 7127K->6944K(19456K),
0.0033105 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
GC:代表垃圾回收,如果不是 Full GC,则代表是 Minior GC;
Allocation Failure :失败原因,分派失败;
PSYoungGen : Parallel Scavenge Young Generation:在新生代使用了 PS 收集器进行垃圾回收。
7127K : 在垃圾回收之前,存活的对象在新生代占据的内存空间;
792K : 在垃圾回收之后,存货的对象在新生代占据的内存空间;(7127-792 = 新生代释放容量)
(9216K) : 新生代总的空间容量;9216/1024=9M,新生代的容量是 9M;8+1=9M,没毛病,剩余 1M 是 to survivor,被浪费了。
7127K : 在垃圾回收之前,存活的对象占据堆空间大小;
6944K : 在垃圾回收之后,存活的对象占据堆空间大小;(7127-6944 = 释放的容量)
(19456K) : 总的堆的容量。19456/1024=19M;
0.0033105 secs :执行垃圾回收使用的时间;
Times: user=0.00 sys=0.00, real=0.00 secs : 用户空间时间,系统内核时间,真正执行的时间。
Heap 后面是垃圾回收的汇总信息。
[Full GC (Ergonomics) [PSYoungGen: 792K->0K(9216K)] [ParOldGen:
6152K->6679K(10240K)] 6944K->6679K(19456K), [Metaspace: 2738K->2738K(1056768K)],
0.0066545 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Full GC : 全面的垃圾回收
Ergonomics : 人类工程学?
ParOldGen : Parallel Old 老年代垃圾收集器
PSYoungGen: 792K->0K(9216K): 新生代没了
ParOldGen: 6152K->6679K(10240K) 6944K->6679K(19456K) 老年代
Metaspace: 2738K->2738K(1056768K) 元空间
当把 2 * 2 * 2 * 2 ,改成 2 * 2 * 3 * 3,Full GC 没了!
原因是:当新生代已经无法容纳下新创建的对象的话,新对象将直接在老年代创建。当创建第一个 3M 的时候,新生代无法容纳,直接在老年代创建,而第二个 3M 创建的时候,程序已经发生了 GC,容量又足够使用。(此处描述的有问题,暂且搁置。)
- jdk1.8 默认在新生代使用 Parallel Scavenge 收集器,在老年代默认使用 Parallel Old 收集器
4.7.2 阈值和垃圾回收器类型对对象分配的影响
打印 JVM 默认参数和版本号:

- Test2
/*
* JVM参数:
* -verbose:gc 输出垃圾回收详情
* -Xms20M <u>jvm</u>启时堆容量的大小,初始大小
* -Xmx20M <u>jvm</u>堆最大值
* -Xmn10m 堆空间中新生代的大小
* -XX:+PrintGCDetails 打印垃圾回收的日志
* -XX:SurvivorRatio=8 Eden空间和Survivor空间比例是8:1,即Eden:From:To=8:1:1
* -XX:PretenureSizeThreshold=4194304 设置对象超过多大时,则直接在老年代创建
* -XX:+UseSerialGC 使用串行收集器 (PretenureSizeThreshold必须结合这个参数一起使用)
*/
public class Test2 {
public static void main(String[] args) {
int size=1024*1024;
byte[] myAlloc=new byte[5*size];
}
}
运行结果:
Heap
def new generation total 9216K, used 1311K 。。。
eden space 8192K, 16% used [。。。
from space 1024K, 0% used [。。。
to space 1024K, 0% used [。。。
tenured generation total 10240K, used 5120K [。。。 //此处可以发现,5M的对象直接进入老年代
the space 10240K, 50% used [。。。
Metaspace used 2779K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 293K, capacity 386K, committed 512K, reserved 1048576K
使用 jvisualvm 查看此进程!

- Test2-1
public class Test2 {
public static void main(String[] args) {
int size=1024*1024;
byte[] myAlloc=new byte[10*size];
}
}
运行结果:
[GC (Allocation Failure) [Tenured: 0K->539K(10240K), 0.0859421 secs]
1147K->539K(19456K), [Metaspace: 2773K->2773K(1056768K)], 0.0860109 secs]
[Times: user=0.00 sys=0.00, real=0.09 secs]
[Full GC (Allocation Failure) [Tenured: 539K->526K(10240K), 0.0023771 secs]
539K->526K(19456K), [Metaspace: 2773K->2773K(1056768K)], 0.0024095 secs] [Times:
user=0.00 sys=0.00, real=0.00 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.hisense.jc.Test2.main(Test2.java:17)
Heap
def new generation total 9216K, used 246K [。。。
eden space 8192K, 3% used [。。。
from space 1024K, 0% used [。。。
to space 1024K, 0% used [。。。
tenured generation total 10240K, used 526K [。。。
the space 10240K, 5% used [。。。
Metaspace used 2806K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 296K, capacity 386K, committed 512K, reserved 1048576K
- Test2-2
/*
* PretenureSizeThreshold: 设置对象超过多大时,直接在老年代进行分配
*/
public class Test2 {
public static void main(String[] args) {
int size=1024*1024;
byte[] myAlloc=new byte[5*size];
}
}
经过多轮 Minor GC 无法进行回收的对象,就会晋升到老年代。
- Test3
/*
* * -verbose:gc -Xms20M -Xmx20M -Xmn10m -XX:+PrintGCDetails -XX:SurvivorRatio=8
* -XX:+PrintCommandLineFlags : 打印命令行的标志,打印JVM的启动参数
* -XX:MaxTenuringThreshold =5: 可以自动调节对象晋升(Promote)到老年代的阈值,设置该阈值的最大值。(理论上的最大值,默认值为15,CMS的默认值是6,G1默认值为15)
* -XX:+PrintTenuringDistribution : 打印出GC过程中对象信息。
经历过多次GC以后,存活的对象会在From Survivor和To Survivor之间来回存放,而这里面的前提是这两个空间有足够的大小来存放这些数据。在GC算法中,会计算每个对象年龄的大小,如果达到某个年龄后发现总大小已经大于了Survivor总空间的50%,那么这时候就需要调整阈值,让存活的对象尽快完成晋升。不能再继续等到默认的15此GC后才完成晋升,因为这样会导致Survivor空间不足。
*/
public class Test3 {
public static void main(String[] args) {
int size=1024*1024;
byte[] myAllocl1=new byte[2*size];
byte[] myAllocl2=new byte[2*size];
byte[] myAllocl3=new byte[2*size];
byte[] myAllocl4=new byte[2*size];
System.out.println("hello world");
}
}
运行结果:
-XX:InitialHeapSize=20971520 -XX:InitialTenuringThreshold=5
-XX:MaxHeapSize=20971520 -XX:MaxNewSize=10485760 -XX:MaxTenuringThreshold=5
-XX:NewSize=10485760 -XX:+PrintCommandLineFlags -XX:+PrintGC -XX:+PrintGCDetails
-XX:+PrintTenuringDistribution -XX:SurvivorRatio=8
-XX:+UseCompressedClassPointers -XX:+UseCompressedOops
-XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
[GC (Allocation Failure)
Desired survivor size 1048576 bytes, new threshold 5 (max 5)
[PSYoungGen: 7291K->776K(9216K)] 7291K->6928K(19456K), 0.0028395 secs] [Times:
[Full GC (Ergonomics) [PSYoungGen: 776K->0K(9216K)] [ParOldGen:
6152K->6682K(10240K)] 6928K->6682K(19456K), [Metaspace: 2773K->2773K(1056768K)],
hello world
Heap
PSYoungGen total 9216K, used 2288K 。。。
eden space 8192K, 27% used 。。。
from space 1024K, 0% used 。。。
to space 1024K, 0% used 。。。
ParOldGen total 10240K, used 6682K [
object space 10240K, 65% used 。。。
Metaspace used 2781K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 293K, capacity 386K, committed 512K, reserved 1048576K
- Test4
/*
* -verbose:gc
-Xmx200M
-Xmn50m
-XX:+PrintGCDetails
-XX:+PrintCommandLineFlags
-XX:MaxTenuringThreshold=3
-XX:+PrintTenuringDistribution
-XX:TargetSurvivorRatio=60 : 当某个Survivor的空间已经被占用60%,则重新计算对象晋升的阈值TenuringThreshold
-XX:+PrintGCDateStamps :以时间戳的格式打印GC信息
-XX:+UseConcMarkSweepGC :使用并发的标记清除CMS,进行老年代的垃圾回收
-XX:+UseParNewGC :使用ParNew进行新生代的垃圾回收
*/
public class Test4 {
public static void main(String[] args) throws InterruptedException {
byte[] byte1=new byte[512*1024];
byte[] byte2=new byte[512*1024];
myGC();
Thread.sleep(1000);
System.out.println("1111111111");
myGC();
Thread.sleep(1000);
System.out.println("2222222222");
myGC();
Thread.sleep(1000);
System.out.println("3333333333");
myGC();
Thread.sleep(1000);
System.out.println("4444444444");
byte[] <u>byte3</u>=new byte[1024*1024];
byte[] <u>byte4</u>=new byte[1024*1024];
byte[] <u>byte5</u>=new byte[1024*1024];
myGC();
Thread.sleep(1000);
System.out.println("5555555555");
myGC();
Thread.sleep(1000);
System.out.println("6666666666");
System.out.println("hello world!");
}
private static void myGC() {
for(int i=0;i<40;i++) {
byte[] <u>byteArray</u>=new byte[1024*1024];
}
}
}
输出结果:
-XX:InitialHeapSize=126494784 -XX:InitialTenuringThreshold=3
-XX:MaxHeapSize=209715200 -XX:MaxNewSize=52428800 -XX:MaxTenuringThreshold=3
-XX:NewSize=52428800 -XX:OldPLABSize=16 -XX:+PrintCommandLineFlags -XX:+PrintGC
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintTenuringDistribution
-XX:TargetSurvivorRatio=60 -XX:+UseCompressedClassPointers
-XX:+UseCompressedOops -XX:+UseConcMarkSweepGC
-XX:-UseLargePagesIndividualAllocation -XX:+UseParNewGC
2020-03-30T16:50:56.737+0800: [GC (Allocation Failure)
2020-03-30T16:50:56.737+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 3 (max 3)
- age 1: 1602352 bytes, 1602352 total
: 40346K->1597K(46080K), 0.0011137 secs] 40346K->1597K(119808K), 0.0011683 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
1111111111
2020-03-30T16:50:57.748+0800: [GC (Allocation Failure)
2020-03-30T16:50:57.748+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 3 (max 3)
- age 1: 696 bytes, 696 total
- age 2: 1601016 bytes, 1601712 total
: 42328K->1738K(46080K), 0.0028412 secs] 42328K->1738K(119808K), 0.0029356 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
2222222222
2020-03-30T16:50:58.758+0800: [GC (Allocation Failure)
2020-03-30T16:50:58.758+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 3 (max 3)
- age 1: 64 bytes, 64 total
- age 2: 696 bytes, 760 total
- age 3: 1601360 bytes, 1602120 total
: 42470K->1659K(46080K), 0.0009596 secs] 42470K->1659K(119808K), 0.0010307 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
3333333333
2020-03-30T16:50:59.768+0800: [GC (Allocation Failure)
2020-03-30T16:50:59.768+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 3 (max 3)
- age 1: 64 bytes, 64 total
- age 2: 64 bytes, 128 total
- age 3: 696 bytes, 824 total
: 42394K->231K(46080K), 0.0083973 secs] 42394K->1817K(119808K), 0.0085299 secs]
[Times: user=0.05 sys=0.00, real=0.01 secs]
4444444444
2020-03-30T16:51:00.784+0800: [GC (Allocation Failure)
2020-03-30T16:51:00.784+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 1 (max 3)
- age 1: 3145840 bytes, 3145840 total
- age 2: 64 bytes, 3145904 total
- age 3: 64 bytes, 3145968 total
: 40968K->3101K(46080K), 0.0026450 secs] 42554K->4687K(119808K), 0.0027542 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
5555555555
2020-03-30T16:51:01.795+0800: [GC (Allocation Failure)
2020-03-30T16:51:01.795+0800: [ParNew
Desired survivor size 3145728 bytes, new threshold 3 (max 3)
- age 1: 64 bytes, 64 total
: 43838K->3K(46080K), 0.0040829 secs] 45425K->4662K(119808K), 0.0042132 secs]
[Times: user=0.06 sys=0.00, real=0.00 secs]
6666666666
hello world!
Heap
par new generation total 46080K, used 13913K 。。。
eden space 40960K, 33% used 。。。
from space 5120K, 0% used 。。。
to space 5120K, 0% used 。。。
concurrent mark-sweep generation total 73728K, used 4658K 。。。
Metaspace used 2784K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 294K, capacity 386K, committed 512K, reserved 1048576K
4.8 CMS (Concurrent Mark Sweep)并发标记清除
4.8.1 枚举根节点
- 当执行系统停顿下来后,并不需要一个不漏地检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法直接得知哪些地方存放着对象引用。在 HotSpot 的实现中,是使用一组称为 OopMap 的数据结构来达到这个目的。
4.8.2 安全点
- 在 OopMap 的协助下,HotSpot 可以快速且准确地完成 GC Roots 枚举,但一个很现实的问题随之而来:可能导致引用关系变化,或者说 OopMap 内容变化的指令非常多,如果为每一条指令都生成对应的 OopMap,那将会需要大量的额外空间,这样 GC 的空间成本将会变得更高。
- 实际上,HotSpot 并没有为每条指令都生成 OopMap,而只是在 “特定的位置” 记录了这些信息,这些位置称为安全点(Safepoint),即程序执行时并非在所有地方都能停顿下来开始 GC,只有在达到安全点才能暂停。
- Safepoint 的选定既不能太少以至于让 GC 等待时间太长,也不能过于频繁以至于过分增大运行时的负载。所以,安全点的选定基本上是 “是否具有让程序长时间执行的特征” 为标准进行选定的 ---- 因为每条指令执行的时间非常短暂,程序不太可能因为指令流长度太长这个原因而过长时间运行,“长时间执行”的最明显的特征就是指令序列服用,例如方法调用、循环跳转、异常跳转等,所以具有这些功能的指令才会产生 Safepoint。
- 对于 Safepoint,另一个需要考虑的问题是如何在 GC 发生时让所有线程(这里不包括执行 JNI 调用的线程)都 “跑” 到最近的安全点上再停顿下来:抢占式中断(Preemptive Suspension)和主动式中断(Voluntary Suspension)
抢占式中断:它不需要线程的执行代码主动去配合,在 GC 发生时,首先把所有线程全部中断,如果有线程中断的地方不在安全点,就恢复线程,让它 “跑” 到安全点上。
主动式中断:当 GC 需要中断线程时,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发生中断标志位真时就自己中断挂起。轮询标志的地方和安全点时重合的,另外再加上创建对象需要分配内存的地方。 - 现在几乎没有虚拟机采用抢占式中断来暂停线程从而相应 GC 事件。
4.8.3 安全区域
- 使用 Safepoint 似乎已经完美地解决了如何进入 GC 的问题,但实际上情况却并不一定。Safepoint 机制保证了程序执行时,在不太长的时间内就会遇到可进入 GC 的 Safepoint。但如果程序在 “不执行” 的时候呢?所谓的程序不执行就是没有分配 CPU 时间,典型的例子就是出于 Sleep 状态或者 Blocked 状态,这时候线程无法响应 JVM 的中断请求,JVM 也显然不太可能等待线程重新分配 CPU 时间。对于这种情况,就需要安全区域(Safe Regin)来解决了。
- 在线程执行到 Safe Region 中的代码时,首先标识自己已经进入了 Safe Region。那样,在这段时间里 JVM 要发起 GC 时,就不用管标识自己为 Safe Region 状态的线程了。在线程要离开 Safe Region 时,它要检查系统是否完成了根节点枚举(或者是整个 GC 过程),如果完成了,那线程就继续执行,否则它就必须等待直到收到可以离开 Safe Region 的信号为止。
4.8.4 CMS 收集器
-
CMS(Concurrent Mark Sweep)收集器,以获取最短回收停顿时间为目标,多数应用于互联网站或者 B/S 系统的服务器端上。
-
CMS 是基于 “标记 - 清除” 算法实现的,整个过程大致分为 4 个步骤:
· 初始标记 (CMS initial mark)
· 并发标记 (CMS concurrent mark)
· 重新标记 (CMS remark)
· 并发清除 (CMS concurrent sweep)
并发指的是 GC 线程和用户线程可以同时运行。 -
其中,初始标记和重新标记这两个步骤仍然需要 “Stop The World”;
-
初始标记只是标记一下 GC Roots 能直接关联的对象,速度很快;
-
并发标记阶段就是进行 GC Roots Tracing 的过程;
-
重新标记阶段则是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
-
CMS 收集器的运作步骤如下图所示,在整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,因此,从总体上来看,CMS 收集器的内存回收过程是与用户线程一起并发执行的。

-
优点
· 并发收集、低停顿,Oracle 公司的一些官方文档中也称之为并发低停顿收集器(Concurrent Low Pause Collector) -
缺点
· CMS 收集器堆 CPU 的资源非常敏感;
· CMS 收集器无法处理浮动垃圾(Floating Garbage),可能出现 “Concurrent Mode Failure” 失败而导致另一次 Full GC 的产生。如果在应用中老年代增长不是太快,可以适当调高参数 - XX:CMSInitiatingOccupancyFraction 的值来提高触发百分比,以便降低内存回收次数从而获取更好的性能。要是 CMS 运行期间预留的内存无法满足程序需要时,虚拟机将启动后备预案:临时启用 Serial Old 收集器来重新进行老年代的垃圾收集,这样停顿时间就长了。所以说参数 - XX:CMSInitiatingOccupancyFraction 设置太高很容易导致大量 “Concurrent Mode Failure” 失败,性能反而降低。
· 收集结束时会有大量空间碎片产生,空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代还有很大的空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前进行一次 Full GC。CMS 收集器提供了一个 - XX:UseCMSCompactAtFullCollection 开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理过程是无法并发的,空间碎片问题没有了,但是停顿时间不得不变长。
浮动垃圾:由于垃圾回收和用户线程是同时进行的,在进行标记或者清除的同时,用户的线程还会去改变对象的引用,使得原来某些对象不是垃圾,但是当 CMS 进行清理的时候变成了垃圾,CMS 收集器无法收集,只能等到下一次 GC。
空间分配担保: -
在发生 Minitor GC 之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么 Minitor GC 可以确保是安全的。当大量对象在 Minitor GC 后仍然存活,就需要老年代进行空间分配担保,把 Survivor 无法容纳的对象直接进入老年代。如果老年代判断到剩余空间不足(根据以往每一次回收晋升到老年代对象容量的平均值为经验值),则进行一次 Full GC。
CMS 收集器收集完整详细步骤:
- Initial Mark
- Concurrent Mark
- Concurrent Preclean —并发预先清理
- Concurrent Abortable Preclean —并发可失败的预先清理
- Final Remark -- 最终重新标记
- Concurrent Sweep —并发清理
- Concurrent Reset —并发重置
1. Initial Mark
这个是 CMS 两次 stop-the-world 事件的其中一次,这个阶段的目标是:标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象。

2. Concurrent Mark
这个阶段 Garbage Collector 会遍历老年代,然后标记所有存活的对象,它会根据上个阶段找到的 GC Roots 遍历查找。并发标记阶段,它会与用户的应用程序并发运行。并不是所有的老年代存活对象都会被标记,因为在标记期间用户的程序可能会改变一些引用;

在上面的图中,与阶段 1 的图进行对比,就会发现有一个对象的引用已经发生了变化。
3. Concurrent Preclean
- 这也是一个并发阶段,与应用的线程并发运行,并不会 stop 应用的线程。在并发运行的过程中,一些对象的引用可能会发生变化,但是这种情况发生时,JVM 会将包含这个对象的区域(Card)标记为 Dirty,这也就是 Card Marking。
- 在 pre-clean 阶段,那些能够从 Dirty 对象到达的对象也会被标记,这个标记做完以后,dirty card 标记就会被清除了。

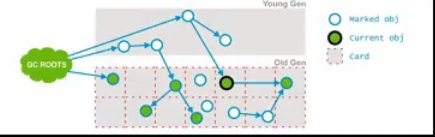
4. Concurrent Abortable Preclean
- 并发阶段,这个阶段是为了承担 STW(stop-the-world)中最终标记阶段的工作。这个阶段持续时间依赖于很多的因素,由于这个阶段在重复做很多相同的工作,直接满足一些条件(比如:重复迭代的次数、完成的工作量或者时钟时间等)
5. Final Remark
- 这是第二个 STW 阶段,也是 CMS 中的最后一个,这个阶段的目标是标记老年代所有的存活对象,由于之前的阶段是并发执行的,gc 线程可能跟不上应用程序的变化,为了完成标记老年代所有存活对象的目标,STW 就非常有必要的了。
- 通常 CMS 的 Final Remark 阶段会在年轻代干净的时候运行,目的就是为了减少连续 STW 发生的可能性(年轻代存活对象过多的话,也会导致老年代涉及的存活对象会很多)。这个阶段会比前面的几个阶段更复杂一些。
6. Concurrent Sweep
- 经历过前 5 个阶段之后,老年代所有存活对象都被标记过了,现在可以通过清除算法去清理那些老年代不再使用的对象。
- 这里不需要 STW,它是与用户的程序并发运行,清除那些不再使用的对象,回收它们的占用空间为将来使用。

7. Concurrent Reset
- 这个阶段也是并发的,它会重设 CMS 内部的数据结构,为下次的 GC 做准备。
总结:
-
MS 通过将大量的工作分散到并发处理阶段来减少 STW 时间,在这块做得非常优秀,但是 CMS 也有一些其他的问题。
-
Test4
/**
* * -verbose:gc -Xms20M -Xmx20M -Xmn10m -XX:+PrintGCDetails -XX:SurvivorRatio=8
* -XX:+UseConcMarkSweepGC 使用CMS进行老年代垃圾回收
*/
public class Test4{
public staitic void main(String[] args){
int size=1024*1024;
byte[] myAllocl1=new byte[4*size];
System.out.println("11111111");
byte[] myAllocl2=new byte[4*size];
System.out.println("22222222");
byte[] myAllocl3=new byte[4*size];
System.out.println("333333333");
byte[] myAllocl4=new byte[2*size];
System.out.println("4444444");
}
}

4.9 G1 垃圾收集器 (Garbage First Collector)
吞吐量
- 吞吐量关注的是,在一个指定的时间内,最大化一个应用的工作量。
- 如下方式来衡量一个系统吞吐量的好坏:
· 在一个小时内同一个事务(或者任务、请求)完成的次数(tps)
· 数据库一个小时可以完成多少次查询 - 对于关注吞吐量的系统,卡顿是可以接受的,因为这个系统关注长时间的大量任务的执行能力,单次快速的响应并不值得考虑。
响应能力
- 响应能力指一个程序或者系统对请求是否能够及时响应,比如:
· 一个桌面 UI 能多快地响应一个事件
· 一个网站能够多快返回一个页面请求
· 数据库能够多快返回查询的数据 - 对于这类对响应能力敏感的场景,长时间的停顿是无法接受的。
4.9.1 G1 思想
- G1 收集器是一个面向服务端的垃圾收集器,适用于多核处理器、大内存容量的服务端系统。
- 它满足短时间 gc 停顿的同时达到一个较高的吞吐量。(满足了吞吐量和响应能力的要求)
- JDK1.7 以上版本适用。
4.9.1.1 G1 收集器的设计目标
- 与应用线程同时工作,几乎不需要 stop the world(与 CMS 类似);
- 整理剩余空间,不产生内存碎片(CMS 只能在 Full GC 时,用 stop the world 整理内存碎片);
- GC 停顿更加可控;
- 不牺牲系统的吞吐量;
- GC 不要求额外的内存空间(CMS 需要预留空间存储浮动垃圾);
4.9.1.2 G1 的设计规划是要替换掉 CMS
- G1 在某些方面弥补了 CMS 的不足,比如:CMS 使用的是 mark-sweep 算法,自然会产生内存碎片;然而 G1 给予 copying 算法,高效的整理剩余内存,而不需要管理内存碎片。
- 另外,G1 提供了更多手段,以达到对 gc 停顿时间的可控。
4.9.1.3 HotSpot 虚拟机主要构成

4.9.1.4 传统垃圾收集器堆机构

4.9.1.5 G1 收集器堆结构

-
heap 被划分为一个个相等的不连续的内存区域(regions),每个 region 都有一个分代的角色:eden、survivor、old;
-
对每个角色的数量并没有强制的限定,也就是说对每种分代内存的大小,可以动态变化;
-
G1 最大的特点就是高效的执行回收,优先去执行那些大量对象可回收的区域(region);
-
G1 使用了 gc 停顿可预测的模型,来满足用户设定的 gc 停顿时间,根据用户设定的目标时间,G1 会自动地选择哪些 region 要清除,一次清除多少个 region;
-
G1 从多个 region 中复制存活的对象,然后集中放入一个 region 种,同时整理、清除内存(copying 收集算法)
4.9.1.6 G1 vs 其他收集器
- 对比使用 mark-sweep 的 CMS,G1 使用的 copying 算法不会造成内存碎片;
- 对比 Parallel Scavenge(基于 copying)、Parallel Old 收集器(给予 mark-compact-sweep),Parallel 会对整个区域做整理导致 gc 停顿时间会比较长,而 G1 只是特定地整理几个 region;
- G1 并非一个实时的收集器,与 Parallel Scavenge 一样,对 gc 停顿时间的设置并不会绝对生效,只是 G1 有较高的几率保证不超过设定的 gc 停顿时间。与之前的 gc 收集器对比,G1 会根据用户设定的 gc 停顿时间,智能评估哪几个 region 需要被回收可以满足用户的设定。
4.9.1.7 G1 相对于 CMS 的优势
- G1 在压缩空间方面有优势;
- G1 通过将内存空间分成区域(Region)的方式避免内存碎片问题;
- Eden、Survivor、Old 区不再固定,在内存使用效率上来说更加灵活;
- G1 可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间,避免应用出现雪崩现场。
- G1 在回收内存后马上同时做合并空闲内存的工作,而 CMS 默认是在 STW 的时候做;
- G1 会在 Young 中使用,而 CMS 只能在 Old 区使用。
4.9.1.8 G1 的适用场景
- 服务端多核 CPU、JVM 内存占用较大的应用;
- 应用在运行过程中会产生大量内存碎片、需要经常压缩空间;
- 想要更可控、可预期的 GC 停顿周期;防止高并发下应用的雪崩现象。
4.9.2 G1 重要概念
分区: G1 采取了不同的策略来解决并行、串行和 CMS 收集器的碎片、暂停时间不可控等问题 ----G1 将整个堆分成相同大小的分区(Region)
-
每个分区都可能是年轻代也可能是老年代,但是在同一时刻只能属于某个代。年轻代、幸存区、老年代这些概念还存在,成为逻辑上的概念,这样方便复用之前分代框架的逻辑;
-
在物理上不需要联系,则带来额外的好处—有的分区内垃圾对象特别多,有的分区内垃圾对象很少,G1 会优先回收垃圾对象特别多的分区,这样可以花费较少的时间来回收这些分区的垃圾,这也就是 G1 名字的由来,即首先收集垃圾最多的分区。
-
依然是在新生代满了的时候,对整个新生代进行回收—整个新生代中的对象,要么被回收、要么晋升,至于新生代也采取分区机制的原因,则是因为这样跟老年代的策略统一,方便调整代的大小;
-
G1 还是一种带压缩的收集器,在回收老年代的分区时,是将存活的对象从一个分区拷贝到另外一个可用分区,这个拷贝的过程就实现了局部的压缩。
收集集合(CSet): 一组可被回收的分区的集合。在 CSet 中存活的数据会在 GC 过程中被移动到另一个可用分区,CSet 中的分区可以来自 eden 空间、Survivor 空间、或者老年代。
已记忆集合(RSet): RSet 记录了其他 Region 中对象引用本 Region 中对象的关系,属于 points-into 结构(谁引用了我的对象)。RSet 的价值在于使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只扫描 RSet 即可。
Region1 和 Region3 中的对象都引用了 Region2 中的对象,因此在 Region2 的 RSet 中记录了两个引用。

- G1 GC 是在 points-out 的 card table 之上再加了一层结构来构成 points-into RSet:每个 region 会记录下到底哪些别的 region 有指向自己的指针,而这些指针分别在哪些 card 的范围内。
- 这个 RSet 其实是一个 hash table,key 是别的 region 的起始地址,value 是一个集合,里面的元素是 card table 的 index。举例来说,如果 region A 的 RSet 里有一项的 key 是 region B,value 里有 index 为 1234 的 card,它的意思就是 region B 的一个 card 里有引用指向 region A。所以对 region A 来说,该 RSet 记录的是 points-into 的关系;而 card table 仍然记录了 points-out 的关系。
Snapshot-At-Beginning(STAB): STAB 是 G1 GC 在并发标记阶段使用的增量式的标记算法。
- 并发标记是并发多线程的,但并发线程在同一时刻只扫描一个分区。
4.9.3 G1 官方文档
地址:https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html

JVM 中有三个重点组件进行性能调优:堆(垃圾收集器管理)、即时编译器、垃圾收集器。
When performing garbage collections, G1 operates in a manner similar to the CMS collector. G1 performs a concurrent global marking phase to determine the liveness of objects throughout the heap. After the mark phase completes, G1 knows which regions are mostly empty. It collects in these regions first, which usually yields a large amount of free space. This is why this method of garbage collection is called Garbage-First. As the name suggests, G1 concentrates its collection and compaction activity on the areas of the heap that are likely to be full of reclaimable objects, that is, garbage. G1 uses a pause prediction model to meet a user-defined pause time target and selects the number of regions to collect based on the specified pause time target.
在进行垃圾回收时,G1 的操作和 CMS 收集器非常类似。G1 会执行一个并发全局的操作来确定对象在堆中存活的状态。在标记阶段完成之后,G1 就知道了哪些 region 区域是最空的。收集和压缩这些区域,通常会产生大量的可用空间,这就是 G1 名字的由来。G1 使用了一个停顿可预测的模型来满足用户定义的停顿时间的目标。从特定的区域中选择部分区域进行垃圾回收。
The regions identified by G1 as ripe for reclamation are garbage collected using evacuation. G1 copies objects from one or more regions of the heap to a single region on the heap, and in the process both compacts and frees up memory. This evacuation is performed in parallel on multi-processors, to decrease pause times and increase throughput. Thus, with each garbage collection, G1 continuously works to reduce fragmentation, working within the user defined pause times. This is beyond the capability of both the previous methods. CMS (Concurrent Mark Sweep) garbage collector does not do compaction. ParallelOld garbage collection performs only whole-heap compaction, which results in considerable pause times.
对 G1 所标志的区域进行垃圾回收,G1 会将一个或多个区域内存活的对象复制到另外的单独区域中。在此过程中,还会进行压缩和释放内存。这种回收在多处理器中并行执行,可以节省时间和调高吞吐量。G1 会持续工作以减少碎片的产生,而且都是运行在用户指定的停顿时间之内。G1 完全超出了之前其他垃圾收集器的能力,CMS 不可以进行空间压缩,ParallelOld 收集器只会对整个堆进行压缩,耗时较长。
It is important to note that G1 is not a real-time collector. It meets the set pause time target with high probability but not absolute certainty. Based on data from previous collections, G1 does an estimate of how many regions can be collected within the user specified target time. Thus, the collector has a reasonably accurate model of the cost of collecting the regions, and it uses this model to determine which and how many regions to collect while staying within the pause time target.
G1 并不是一个实时的收集器,它会尽可能满足用户设定的停顿时间,但也不是完全绝对的。根据之前收集的数据,G1 会估算在用户指定的时间之内可以收集多少个区域。G1 就是使用这个模型来确定每次垃圾回收多少个区域。
Note: G1 has both concurrent (runs along with application threads, e.g., refinement, marking, cleanup) and parallel (multi-threaded, e.g., stop the world) phases. Full garbage collections are still single threaded, but if tuned properly your applications should avoid full GCs.
G1 既有并发阶段,也有并行阶段。Full GC 仍然是单线程的,它会出现 STW。
G1 垃圾回收的步骤 (The G1 Garbage Collector Step by Step):
新生代的回收:
- G1 内存结构(G1 Heap Structure)
堆将一整个内存划分为多个固定大小的 region(大小可指定) - 堆的分配(G1 Heap Allocation)
这些空间会被映射为 Eden、Survivor、和 Old generation。此外还有第四种类型:(Humongous regions)很大的区域(连续的)~。存放大小超出了 region 的 50% 以及上的空间的对象。

存活的对象会从一个区域移动到另外的区域上。 - G1 中的年轻代
堆大约会被分成 2000 个 region,大小在 1-32M 之间。蓝色区域代表老年代,绿色区域代表新生代。

region 不要求连续。 - 新生代中的垃圾收集
存活的对象会被移动至一个或多个 survivor 区域中,如果一些条件被满足,一些对象会被直接晋升到老年代。

新生代的 gc 会出现 STW 的暂停;
多线程并行完成;
可以根据需要动态的调整区域的大小。 - 新生代中剩余的对象
还存活的对象会被移动至 survivor 或者直接移动到老年代。

老年代的回收:
类似于 CMS 收集器,G1 的设计也是低停顿的。

- 初始标记
标记处由新生代所引用的对象。

- 并发标记
如果找到空的分区,直接会被移除。

- 重新标记

- 复制和清除阶段
G1 选择存活率最低的分区,优先进行回收,速度也最快。这些区域和新生代同时进行收集。

- 复制和清除阶段之后
选择的区域已经被清理和压缩。
4.9.4 G1 执行模式与 JVM 参数
4.9.4.1 G1 GC 模式
- G1 提供了两种 GC 模式,Young GC 和 Mixed GC,两种都是完全 Stop The World 的;
Young GC: 选定所有年轻代里的 Region。通过控制年轻代的 Region 个数,即年轻代内存大小,来控制 Young GC 的时间开销。
Mixed GC: 选定所有年轻代里的 Region,外加根据 global concurrent marking 统计得出收集效益高的若干老年代 Region。在用户指定的开销目标范围内尽可能选择收益高的老年代 Region。 - Mixed GC 不是 Full GC,它只能回收部分老年代的 Region,如果 Mixed GC 实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行 Mixed GC,就会使用 Serial Old GC(Full GC)来收集整个 GC Heap。所以,本质上 G1 是不提供 Full GC 的。当 Mied GC 赶不上对象产生的速度的时候就退化成 Gull GC,这一点需要重点调优。
4.9.4.2 global concurrent marking 全局并发标记
glbbal concurrent marking 的执行过程类似于 CMS,但是不同的是,在 G1 GC 中,它主要是为 Mixed GC 提供标记服务的,并不是一次 GC 过程的必须环节, global concurrent marking 的执行过程分为四个步骤:
1. 初始标记(initial mark,STW):它标记了从 GC Root 开始直接可达的对象。
2. 并发标记(Concurrent Marking): 这个阶段从 GC Root 开始对 heap 中的对象进行标记,标记线程与应用程序线程并发执行,并且收集各个 Region 的存活对象信息。
3. 重新标记(Remark, STW): 标记那些在并发标记阶段发生变化的对象,将被回收。
4. 清理(Cleanup): 清除空 Region(没有存活对象的),加入 free list。
- 第一阶段 initial mark 是共用了 Young GC 的暂停,这是因为他们可以复用 root scan 操作,所以可以说 global concurrent marking 是伴随 Young GC 而发生的。
- 第四阶段 Cleanup 只是回收了没有存活对象的 Region,所以它并不需要 STW。
- 出事标记是在 Young 上执行的,在进行全局并发标记的时候不会做 Mixed GC,在做 Mixed GC 的时候也不会启动初始标记阶段。
4.9.4.3 G1 在运行过程中的主要模式
Young GC (不同于 CMS)、 并发阶段、混合模式、Full GC(一般是 G1 出现问题时才发生)
- G1 Young GC 在 Eden 充满时触发,在回收之后所有之前属于 Eden 的区块全部变成空白,即不属于任何一个分区(Eden、Survivor、Old);
- 什么时候触发全局并发标记呢?
不知道。。。。。。。。。
什么时候触发 Mixed GC? - 由一些参数控制,另外也控制着哪些老年代 Region 会被选入 CSet(收集集合):
· G1HeapWastePercent :在 global concurrent marking 结束之后,我们可以知道 old gen regions 中有多少空间要被回收,在每次 Young GC 之后和再次发生 Mixed GC 之前,会检查垃圾占比是否达到此参数,只有达到了,下次才会发生 Mixed GC。
· G1MixedGCLiveThresholdPercent:old generation region 的存活对象的占比,只有在此参数之下,才会被选入 CSet。
· G1MixedGCCountTarget:一次 global concurrent marking 之后,最多执行 Mixed GC 的次数。
· G1OldCSetRegionThresholdPercent:一次 Mixed GC 中能被选入 CSet 的最多 old generation region 数量。
· 其他参数

4.9.4.4 G1 收集概览
- G1 算法将堆划分为若干个区域(Region),它仍然属于分代收集器。不过,这些区域的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者 Survivor 空间。老年代也分成很多区域,G1 收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1 完成了堆得压缩(至少是部分堆得压缩),这样也就不会有 CMS 内存碎片问题的存在了。
4.9.4.5 Humongous 区域
- 在 G1 中,还有一种特殊的区域,叫 Humongous 区域。如果一个对象占用的空间达到或是超过了分区容量 50% 以上,G1 收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1 划分了一个 Humongous 区,它用来专门存放巨型对象。如果一个 H 区装不下一个巨型对象,那么 G1 会寻找连续的 H 分区来存储。为了能找到连续的 H 区,有时候不得不启动 Full GC。
4.9.4.6 G1 Young GC
-
Young GC 主要是对 Eden 区进行 GC,它在 Eden 空间耗尽时会被触发。在这种情况下,Eden 空间的数据移动到 Survivor 空间中,如果 Survivor 空间不够,Eden 空间的部分数据会直接晋升到老年代空间。Survivor 区的数据移动到新的 Survivor 区中,也有部分数据晋升到老年代空间中。最终 Eden 空间的数据为空,GC 完成工作,应用线程继续执行。
-
如果仅仅 GC 新生代对象,我们如何找到所有的根对象呢?老年代的所有对象都是跟么?那这样扫描下来会耗费大量的时间。于是,G1 引进了 RSet 的概念。它的全称是 Remembered Set,作用是跟踪指向某个 heap 区内的对象引用。

(在 Region 的 RSet 中存放着引用了自己对象的 Region,RSet 是一个 Hash Table 数据结构,key 就是其他 Region 的起始地址,value 是卡表数据的集合。) -
在 CMS 中,也有 RSet 的概念,在老年代中有一块区域用来记录指向新生代的引用。这是一种 point-out,在进行 Young GC 时,扫描根时,仅仅需要扫描这一块区域,而不需要扫描整个老年代。但在 G1 中,并没有使用 point-out,这是由于一个分区太小,分区数量太多,如果是用 point-out 的话,会造成大量的扫描浪费,有些根本不需要 GC 的分区引用也扫描了。
-
于是,G1 采用了 point-in 来解决。point-in 的意思是哪些分区引用了当前分区中的对象。这样,仅仅将这些对象当做根来扫描就避免了无效的扫描。
-
由于新生代有多个,那么我们需要在新生代之间记录引用吗?这是不必要的,原因在于每次 GC 时,所有新生代都会被扫描,所以只需要记录老年代到新生代之间的引用即可。
-
需要注意的是,如果引用的对象很多,赋值器需要对每个引用做处理,赋值器开销就很大,为了解决赋值器开销的额问题,在 G1 中又引入了另外一个概念,卡表(Card Table)。一个 Card Table 将一个分区在逻辑上划分为固定大小的连续区域,每个区域称之为卡。卡通常较小,介于 128 刀 512 字节之间。Card Table 通常为字节数组,由 Card 的索引(即数组下标)来标志每个分区的空间地址。
-
默认情况下,每个卡都未被引用。当一个地址空间被引用时,这个地址空间对应的数组索引的值被标记为‘0’,即标记为被引用,此外 RSet 也将这个数据下表记录下来。一般情况下,这个 RSet 其实是一个 Hash Table,key 时别的 Region 的起始地址,value 是一个集合,里面的元素就是 Card Table 的 Index。
Young GC 的阶段:
- 阶段 1:根扫描 ------ 静态和本地对象被扫描
- 阶段 2:更新 RSet------ 处理 dirty card 队列更新 RS(dirty card 是什么?)
- 阶段 3:处理 RSet------ 检测从年轻代指向老年代的对象(?难道不应该是检测老年代指向年轻代的对象吗?)
- 阶段 4:对象拷贝 ----- 拷贝存活的对象到 survivor/old 区域
- 阶段 5:处理引用队列–软引用,弱引用,虚引用处理
4.9.4.7 再谈 Mixed GC
- Mixed GC 不仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的老年代分区。
总体上分为两大步骤:全局并发标记和拷贝存活对象(evacuation) - 在 G1 GC 中,global concurrent marking 主要是为 Mixed GC 提供标记服务的,并不是一次 GC 过程的一个必须环节。global concurrent marking 的执行过程分成四个步骤:初始标记、并发标记、重新标记、清理。
- G1 到现在可以知道哪些老的分区可回收垃圾最多。当全局并发标记完成后,在某个时刻就开始 Mixed GC。这些垃圾回收称为 “混合式”,是因为不仅仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的分区。
- 混合式 Mixed GC 采用的是复制清理策略,当 GC 完成后,会重新释放空间。
4.9.4.8 三色标记算法
提到并发标记,我们不得不了解并发标记的三色标记算法。它是描述追踪式回收器的一种有效的方法,利用它可以推演回收器的正确性。
-
我们将对象分成三种类型:
· 黑色:根对象,或者该对象与它的子对象都被扫描过(对象被标记了,且它的所有 field 也被标记了)。
· 灰色:对象本身被扫描,但还没扫描完该对象中的子对象(它的 field 还没有被标记或标记完)。
· 白色:未被扫描对象,扫描完成所有对象之后,最终为白色的不可达对象,即垃圾对象(对象没有被标记到)。 -
跟对象被置为黑色,子对象被置为灰色。

-
继续由灰色开始遍历,将已扫描了子对象的对象置为黑色。

-
遍历了所有可达的对象后,所有可达的对象都变成了黑色。不可达的对象即为白色,需要被清理。

可能产生的问题: 如果在标记过程中,应用程序也在运行,那么对象的指针就有可能改变。这样的话,我们就会遇到一个问题:对象丢失问题(漏标)。
· 当垃圾收集器扫描到下面情况时

· 这时候应用程序执行如下操作:
A.c=C;
b.C=null
· 这样,对象的状态图变成如下情形:

- 很显然,此时 C 是白色,被认为是垃圾需要清理掉,显然这是不合理的。(漏标 C)
- 还有,应用程序会不断地新建对象,那么新对象怎么处理?
4.9.4.9 STAB
在 G1 中,使用的是 STAB(Snapshot-At-The-Begining)的方式,删除的时候记录所有的对象
- 它有三个步骤:
- 在开始标记的时候生成一个快照图,标记存活对象;
- 在并发标记的时候所有被改变的对象入队(在 write barrier 里把所有旧的引用所指向的对象都变成非白的)
- 可能存在浮动垃圾,将在下次被收集。
- STAB 是维持并发 GC 的一种手段。G1 并发的基础就是 STAB。STAB 可以理解成在 GC 开始之前对堆内存里的对象做一次快照,此时活的对象就认为是活的,从而形成一个对象图。
- 在 GC 收集的时候,新生代的对象也认为是活的对象,除此之外其他不可达的对象都认为是垃圾对象。
- 如何找到在 GC 过程中分配的对象呢?每个 region 记录着两个 top-at-mark-start(TAMS)指针,分别为 prevTAMS 和 nextTAMS。在 TAMS 以上的对象就是新分配的,因而被视为隐式 marked。通过这种方式我们就找到了在 GC 过程中新分配的对象,并把这些对象认为是活的对象。
- 解决了对象在 GC 过程中分配的问题,那么在 GC 过程中引用发生变化的问题怎么解决呢?G1 给出的姐姐办法是通过 Write Barrier。Write Barrier 就是对引用字段进行赋值做了额外处理。通过 Write Barrier 就可以了解到哪些引用对象发生了什么样的变化。(附近老师讲的特别乱。。。)
- 对于三色算法在 concurrent 的时候可能产生的漏标记问题,STAB 在 marking 阶段中,对于从 gray 对象移除的目标引用对象标记为 gray,对于 black 引用的新产生的对象标记为 black;由于是在开始的时候进行 snapshot,因而可能存在 Floating Garbage。
漏标与误标
- 误标没什么关系,最多造成浮动垃圾,在下次 GC 还是可以回收的,但是漏标的后果是致命的,把本应该存活的对象给回收了,从而影响程序的正确性。
- 漏标的情况只会发生在白色对象中,且满足以下条件:1. 并发标记时,应用线程给一个黑色对象的引用类型字段复制了该白色对象;2. 并发标记时,应用线程删除所有灰色对象到该白色对象的引用。
4.9.4.10 G1 分代算法
- 为老年代设置分区的目的是老年代里有的分区垃圾多,有的分区垃圾少,这样在回收的时候可以专注于收集垃圾多的分区,这也是 G1 名称的由来。
- 不过这个算法并不适合新生代垃圾收集,因为新生代的垃圾手机算法是复制算法,但是新生代也使用了分区机制主要是因为便于代大小的调整。
4.9.4.11 停顿预测模型
- G1 收集器突出表现出来的一点是通过一个停顿预测模型根据用户配置的停顿时间来选择 CSet 的大小,从而达到用户期待的应用程序暂停时间。
- 通过 - XX:MaxGCPauseMillis 参数来设置。这一点有点类似 ParallelScavenge 收集器。关于停顿时间的设置并不是越短越好。设置的时间越短意味着每次收集的 CSet 越小,导致垃圾逐步积累变多,最终不得不退化成 Serial GC;停顿时间设置的过场,那么会导致每次都会产生长时间的停顿,影响了程序对外的响应时间。
4.9.4.12 G1 最佳实践
- 不断调优暂停时间指标
· 通过 - XX:MaxGCPauseMillis=x 可以设置启动应用程序暂停的时间,G1 在运行的时候会根据这个参数选择 CSet 来满足相应时间的设置。一般情况下这个值设置在 100ms 或者 200ms 都是可以的(不同情况下会不一样),但如果设置成 50ms 就不太合理。暂停时间设置的太短,就会导致 G1 跟不上垃圾产生的速度。最终退化成 Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。 - 不断设置新生代和老年代的大小
· G1 收集器在运行的时候会动态调整新生代和老年代的大小。通过改变代的大小来调整对象紧急的速度以及晋升年龄,从而达到我们为收集器设置的暂停时间目标。
· 设置了新生代的大小相当于放弃了 G1 为我们做的自动调优。我们需要做的只是设置整个堆内存的大小,剩下的交给 G1 自己去分配各个代的大小即可。 - 关注 Evacuation Failure
· Evacuation Failure 类似于 CMS 里面的晋级失败,堆空间的垃圾太多导致无法完成 Region 之间的拷贝,于是不得不退化成 Full GC 来做一次全局范围内的垃圾收集。
4.9.5 G1 回收器日志
- Test5
/**
使用JVM启动参数:
-verbose:gc
-Xms10m
-Xmx10m
-XX:+UseG1GC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:MaxGCPauseMillis=200m
*/
public class Test {
public static void main(String[] args) {
int size=1024*1024;
byte[] alloc1=new byte[size];
byte[] alloc2=new byte[size];
byte[] alloc3=new byte[size];
byte[] alloc4=new byte[size];
System.out.println("hello");
}
}
输出结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号