linux
计算机必须有的组成部分:cpu、硬盘、内存、电源
服务器硬件
- 显示屏
- 内置键盘
- usb接口
- 触摸板
- 网口
- 电源接口
- 散热口
- 摄像头
- 电源开关
服务器硬件厂商
- dell :戴尔
- hp :惠普
- 联想
- 浪潮
- ibm
cpu: 人的记忆,如同计算机的内存条,如果进程不重启,服务器不重启,内存中的数据也不丢
内存: 是CPU和磁盘之间的缓冲设备,也叫临时存储器(存放数据),断电时数据丢失
服务器分类:互联网公司,怎么选择服务器?一般有什么
1).物理服务器,有钱的大公司,买自己的服务器,建造自己的机房(零度,无尘,无静电)防止机器短路,数据丢失
有钱的公司,bat,建造自己的机房
中等的公司,普通的外企,也有自己的服务器,但是服务器,托管在别人的机房(世纪互联这家公司)
2).云服务器,阿里云,腾讯云(便宜,省钱,无烦恼),初创型的小公司
3).vmware虚拟化技术
linux
linux 系统的优势:
跨平台的硬件支持; 丰富的软件支持; 多用户多任务; 可靠的安全性 ; 良好的稳定性; 完善的网络功能
shell
我们输入linux命令发给 linux操作系统 ,shell将我们输入的命令,翻译给操作系统去执行
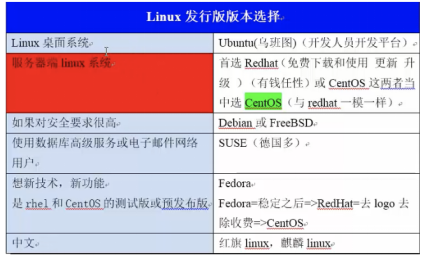
linux的发行版
各个厂家进行自己的定制开发,衍生出不同的发行版
不同的发行版,命令大同小异
centos 社区版的redhat,免费使用,功能和redhat一模一样
ubuntu 作为很多个人学习的linux平台,也常用在物联网嵌入式中
redhat 红帽子,企业版linux,收费使用,redhat资格认证才可以进行linux运维维护,rhcsa红帽管理员,rhce红帽工程师,rhca(红帽架构师)
开源软件特性
低风险 高品质 低成本 更透明
使用linux的好处 :
是自由传播,免费,不会犯法,任意切换图形/命令终端,安全稳定,不用杀毒软件,不卡
Python连接shell的工具是啥
os.system(cmd)
os.popen(cmd)
commands.getoutput(cmd) #python2使用
subprocess.run() #python3使用
例:
data_cmd = 'curl -s http://xxxxx'
result = commnads.getstatusoutput(data_cmd)
if retsult[0] == 0"
print xxx
linux xshell的快捷键
Tab 自动补全
Ctrl + c 取消当前操作
ctrl + l 是清屏
ctrl + d 是退出登录
ctrl + shift + r 是快速重新连接
什么是服务器
(在网络中对外提供服务器的一台性能超强的计算机),硬件
实体服务器
云服务器
centos7版本的linux操作系统
选择的vmware虚拟化软件,安装的linux,充当一个服务器的角色
服务器(可能是云服务器,也可能在全球各地某一个机器),开发人员一般是不会直接触碰的,通过远程连接的方式,去使用
xshell 就是封装了ssh(远程连接的命令),只在windows下有的工具
如果你用的就是linux或者macos,只需要打开终端,输入ssh命令即可
1.linux是个操作系统,服务器的操作系统,centos7系列的发行版
2.windows机器上,安装虚拟化软件vmware,在vmware软件里,安装linux操作系统
3.vmware如同服务器,我们选择远程登录,使用的工具是 xshell
远程登录linux的命令
ssh 用户名@服务器的ip地址(公网的ip)
ssh 用户名@教室内的局域网ip地址(私有的) 确保在同一个网段
windows查看ip的命令 :ipconfig
linux查看ip的方式: ifconfig
- linux登录之后的命令提示符
- 当前你所在的路径
# 超级用户的身份提示符
$ 普通用户的身份提示符
pip3 instal django #python装东西
yum install tree #linux安装软件
linux的特殊符号的含义
# 注释
~ 用户家目录
- 上一次的工作目录
.当前目录
..上一级目录
./ 当前工作目录
> 重定向覆盖输出符号
w
模式
>> 重定向追加输出符号
a
追加
< 重定向输入符,覆盖写入
<< 重定向追加写入符号
用在mysql数据导入时候
$PATH
环境变量
摘出来一些常用的基础命令
su 切换用户
mkdir 创建文件夹
cd 切换目录
touch 创建普通文件
cat 查看文本内容
vim 文本编辑器
ls 查看文件夹内容
ll 等于 ls -l
ps -ef 查看linux的进程
top linux的任务管理器
find 查找linux文件的
grep 过滤字符串信息的
pwd 打印当前工作目录的绝对路径
mv 移动文件 ,重命名
windows和linux传输文件的方法:xftp lrzsz scp
rm 删除文件 rm -rf -r 递归删除文件夹 -f 强制不提醒就删除
yum linux安装软件的命令,如同pip
head 从文本前*行开始看,默认前10行
tail 从文本后面10行看 tail -f filename 实时监控文件内容
more 翻页显示文件内容
less 翻页显示文件内容
echo 追加内容,相当于print打印
ifup ifdown 启停网卡的快捷命令
systemctl restart network 通过命令重启网卡
id kun #查看用户身份id
sudo 临时提权的命令
userdel -r 用户名 #删除用户信息,和家目录
netstat -tunlp | grep 8000 确认django的端口是否启动
ps -ef |grep python 确认django的进程是否存在
kill 进程id # 杀死进程的命令
Pkill -9 #杀死全部进程
Hostnamectl set-hostname #更改主机名
显示磁盘空间 df -h
显示系统主机名的命令: uname -n
查看命令 cat * | grep 卡維薩
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开机自启
iptables -F #清空防火墙规则
cat /etc/os-release #如何查看系统发行版信息
#cat /etc/redhat-release #查看系统版本信息
/etc/profile #系统全局环境变量配置文件
userdel -r 用户名 #删除用户信息,和家目录
#查看文件夹的进程
lsof 文件 #显示打开指定文件的所有进程
fuser 对应的文件
fuser -k 文件 #杀死占用对应文件的全部进程
yum clean all #清空缓存
yum makecache #生成yum缓存
pkill -9 进程号
其他信号说明

查看文件夹大小du -sh
centos6 命令管理服务 : service nginx start
centos7 命令管理服务: systemctl start/stop/restart nginx
查看内存大小信息
cat /proc/meminfo |grep MemTotal
free -m
查看cpu
cat /proc/cpuinfo
Lscpu top
查看板卡
Cat pro/pci lspci
查看网卡
cat pro/interrupts
如何手动启动网卡?
Ifup 网卡名
Ifup ens33
Ifup eth0
Systemctl start network
1.文件夹的操作慢命令
Pwd : 获取当前在哪个文件夹(目录) print work 目录(我在哪的命令)
**ls ** list的意思,查看当前文件夹下有哪些文件夹
man 手册 ,解释linux的命令如何使用
cd 更改工作目录的命令 cd /tmp
增
语法: mkdir 文件夹名字 (文件夹是蓝色的)
改
语法: mv命令,旧名字 新名字
mv 一脸懵逼 二脸懵逼
#新名字存在就是把一脸懵逼移动到二脸懵逼文件下,新名字不存在,就是改名字(后边的斜杠加不加都一样)
mv 二脸懵逼/呵呵/ ./ #这是把呵呵从二脸懵逼文件夹下移到当前文件夹下了
查:
语法: ls 查看文件夹内容
ls 呵呵
linux隐藏文件都是以 . 开头
ls -a 显示文件夹所有内容,以及隐藏文件
ls -la 以列表形式,详细输出文件信息
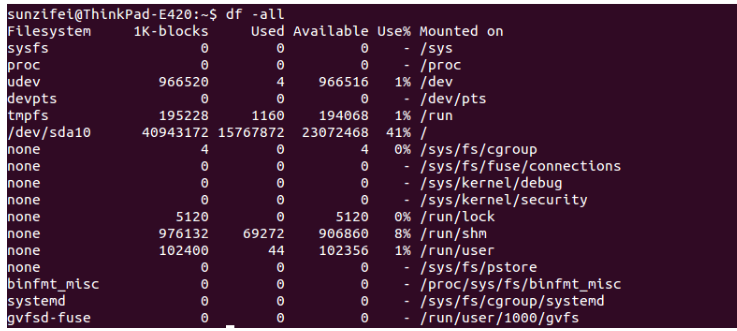
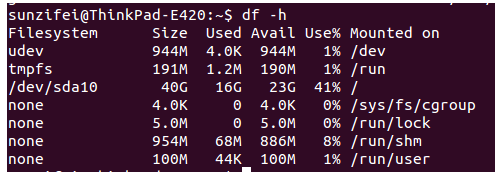
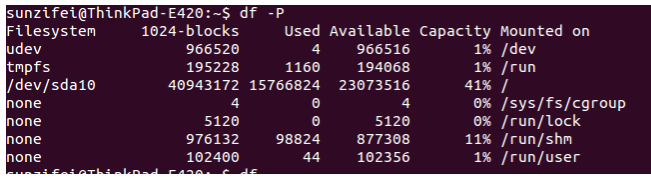
df 命令
命令选项
-
-a, --all 显示所有文件系统的磁盘使用情况,比如如下的使用情况
![]()
-
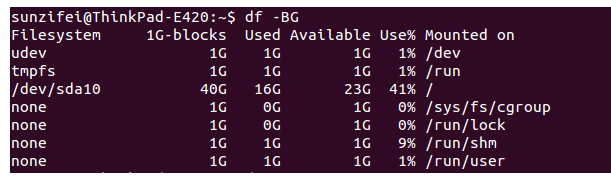
-B,--block-size=SIZE,以size为单位打印磁盘的使用情况,比如:
以GB为单位打印磁盘使用情况
![]()
以MB为单位打印磁盘使用情况:df -BM或 df -B 1048576
-
-h 以易读的方式打印磁盘的使用情况,与-BM的打印效果相当
![]()
-
-H是以1000为单位显示磁盘使用情况
-
-k与-BK的打印效果相当,都是指定打印单位为k
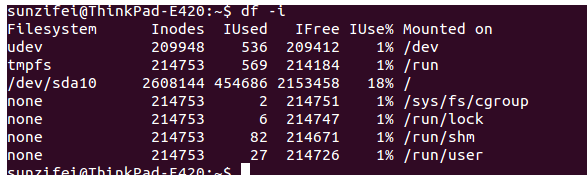
-
-i 显示i节点信息,而不磁盘块的使用信息
![]()
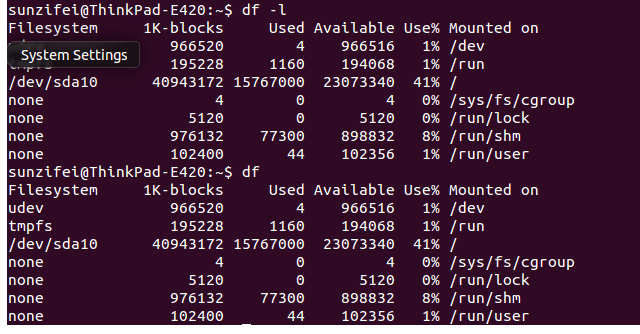
-
-l 只显示本地文件系统的磁盘使用情况,与df不带选项的命令打印效果相同
![]()
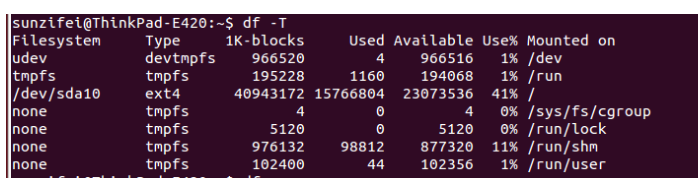
-
-T打印文件系统的类型
![]()
-
-t选项后面加一个文件系统类型,只显示特定文件系统的磁盘使用情况
![]()
-
-x选项后面加一个文件系统类型,不显示指定文件系统的磁盘使用情况
-
-p使用POSIX的输出模式
![]()

2.vim编辑器
即文本编辑器
字母 i ,代表插入,编辑
退出编辑模式,按下esc键
输入 : 冒号,进入底线命令模式 ,输入 :wq!
: w写入
q 退出 !强制的
:wq! 强制写入文本且退出vim
:q! 不写入直接强制退出
:w! 只保存写入,不退出
工作模式
命令模式 编辑模式 底线命令模式
vim快速替换
-
文件内全部替换:
:%s#abc#123#g --注:把abc替换成123
(如文件内有#,可用/替换,:%s/abc/123/g)
(或者: %s/str1/str2/g 用str2替换文件中所有的str1) -
文件内局部替换:
:20,30s#abc#123 (注:把20行到30行内abc替换成123)
(如文件内有#,可用/替换,:%s/abc/123/g)
vi/vim快捷键yy 复制当前行
p 粘贴
dd 删除 3dd 删除3行
dG 删除光标所在以下所有内容
u 撤销
ctrl + r 恢复
x 删除当前光标的内容
a 光标移动末尾
例:复制4-7行
光标放到第4行,3yy,把光标放到第7行,按k ,就把这三行 复制了
3.创建linux普通用户
useradd 用户名 #创建的用户信息会放在 / etc / passwd 这个文件下
useradd xiaofeng
passwd xiaofeng # 给肖峰更改密码
userdel - r 用户名 # 删除用户信息,和家目录
4.查看帮助信息
mkdir --help
man mkdir
5.递归创建文件夹信息
mkdir -p /tmp/s19/{男同学,女同学/小魏}
意思是:创建s19文件夹,底下有男同学,女同学目录,且女同学里面有个小魏
创建目录
os.makedirs() 和 Path.mkdir()(即你代码中的 self.images_dir.mkdir(...))都是 Python 中用于创建目录的方法,但它们来自不同的模块,用法和特性略有区别,具体对比如下
| 特性 | os.makedirs() | Path.mkdir()(pathlib 模块) |
|---|---|---|
| 所属模块 | os(传统文件操作模块) | pathlib(Python 3.4+ 新增的面向对象路径模块) |
| 路径参数类型 | 字符串路径(如 "/home/user/docs") | Path 对象(如 Path("/home/user/docs")) |
| 语法风格 | 函数式调用(os.makedirs(路径, 参数)) | 面向对象调用(路径对象.mkdir(参数)) |
| 默认行为 | 需显式指定 exist_ok=False(默认) | 需显式指定 exist_ok=False(默认) |
| os.makedirs(path, exist_ok=False, parents=True) | ||
| 参数: | ||
| path:字符串类型的目录路径(如 "./workspace/topics/images"); | ||
| parents=True(默认):如果父目录不存在,会自动创建(无需手动逐层创建); | ||
| exist_ok=False(默认):如果目录已存在,会抛出 FileExistsError;若设为 True,目录已存在时不报错。 |
示例:
import os
# 创建多层目录,父目录不存在则自动创建
os.makedirs("./workspace/topics/images", exist_ok=True)
- Path.mkdir(exist_ok=False, parents=False)
功能:通过 pathlib.Path 对象创建目录,同样支持多层目录。
参数:
parents=False(默认):父目录不存在时会报错;若设为 True,则自动创建父目录(类似 os.makedirs);
exist_ok=False(默认):目录已存在时抛出 FileExistsError;设为 True 则不报错。
示例:
from pathlib import Path
# 先创建 Path 对象
images_dir = Path("./workspace/topics/images")
# 创建目录(parents=True 确保父目录存在)
images_dir.mkdir(exist_ok=True, parents=True)
6.查看文本cat
more翻页显示文件内容
less 翻页显示文件内容 用于查看很大的文本 ,
cat读取文件,是一次性读取,非常占内存,用于读取小文本
Touch 创建普通文件
7.复制文件夹,文件
语法:cp 你要复制的内容 复制之后的文件名
cp filename filename.bak
8.查找命令
语法:find 从哪找 -name 你要找的文件名
-name 指定文件名字
-type 指定文件类型 f 文本类型 d文件夹类型
find / -name heeh.txt # 全局搜索
find /etc -name heeh.txt #局部搜索
找出/etc/下所有的txt文本 (*代表所有)
find /etc -name "*.txt"
找到/etc/下所有的python文件夹
find /etc -type d -name python*
9.grep 管道符的用法
语法:第一条命令 | 第二条命令
ps -ef | grep python #查看进程信息
语法: grep [-A] [-B] [--color=auto] '搜寻字符串' filename
特殊符号
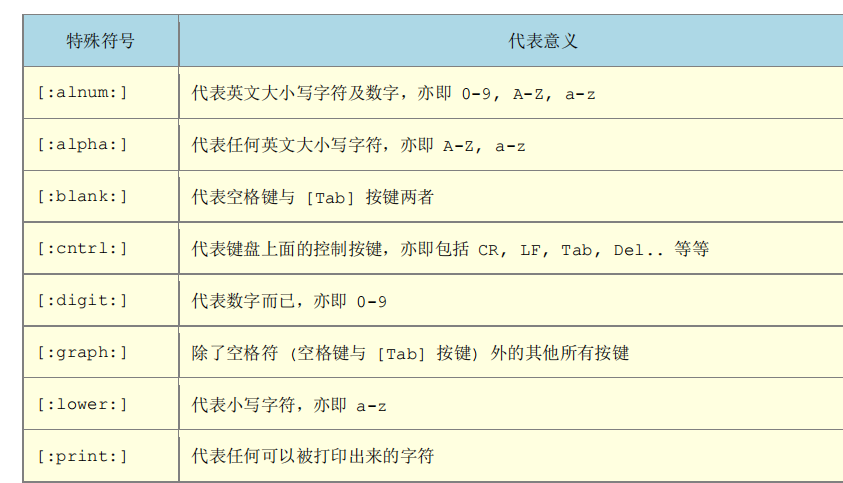

grep可以使用正则:
最典型的用法是,匹配指定字符串之间的字符。 比如,我们想在一句话(Hello,my name is aming.)中匹配中间的一段字符串(my name is) 可以这样写正则表达式。
echo "Hello, my name is aming."|grep -P '(?<=Hello, ).*(?= aming.)'
选项与参数:
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来;
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来;
--color=auto 可将正确的那个撷取数据列出颜色
(1)搜寻特定字符串
范例一:用 dmesg 列出核心讯息,再以 grep 找出内含 qxl 那行
[dmtsai@study ~]$ dmesg | grep 'qxl'
[ 0.522749] [drm] qxl: 16M of VRAM memory size
[ 0.522750] [drm] qxl: 63M of IO pages memory ready (VRAM domain)
[ 0.522750] [drm] qxl: 32M of Surface memory size
[ 0.650714] fbcon: qxldrmfb (fb0) is primary device
[ 0.668487] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
# dmesg 可列出核心产生的讯息!包括硬件侦测的流程也会显示出来。
# 鸟哥使用的显卡是 QXL 这个虚拟卡,透过 grep 来 qxl 的相关信息,可发现如上信息。
范例二:承上题,要将捉到的关键词显色,且加上行号来表示:
[dmtsai@study ~]$ dmesg | grep -n --color=auto 'qxl'
515:[ 0.522749] [drm] qxl: 16M of VRAM memory size
516:[ 0.522750] [drm] qxl: 63M of IO pages memory ready (VRAM domain)
517:[ 0.522750] [drm] qxl: 32M of Surface memory size
529:[ 0.650714] fbcon: qxldrmfb (fb0) is primary device
539:[ 0.668487] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
# 除了 qxl 会有特殊颜色来表示之外,最前面还有行号喔!其实颜色显示已经是默认在 alias 当中了!
范例三:承上题,在关键词所在行的前两行与后三行也一起捉出来显示
[dmtsai@study ~]$ dmesg | grep -n -A3 -B2 --color=auto 'qxl'
# 你会发现关键词之前与之后的数行也被显示出来!这样可以让你将关键词前后数据捉出来进行分析啦!
grep 在数据中查寻一个字符串时,是以 "整行" 为单位来进行数据的撷取的!』也就是说,假如一个文件内有 10 行,其中有两行具有你所搜寻的字符串,则将那两行显示在屏幕上,其他的就丢弃了!
在 CentOS 7 当中,预设已经将 --color=auto 加入在 alias 当中了!用户就可以直接使用有关键词显色的 grep 啰!非常方便!
例: 从刚刚的文件当中取得 the 这个特定字符串
[dmtsai@study ~]$ grep -n 'the' regular_express.txt
8:I can't finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword
那如果想要『反向选择』呢?也就是说,当该行没有 'the' 这个字符串时才显示在屏幕上,那就直接使用:
[dmtsai@study ~]$ grep -vn 'the' regular_express.txt
如果你想要取得不论大小写的 the 这个字符串,则:
[dmtsai@study ~]$ grep -in 'the' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
12:the symbol '*' is represented as start.
14:The gd software is a library for drafting programs.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword
(2)利用中括号 [] 来搜寻集合字符
搜寻 test 或 taste 这两个单字时,可以发现到,其实她们有共通的 't?st' 存在~这个时候,我可以这样来搜寻:
[dmtsai@study ~]$ grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
其实 [] 里面不论有几个字符,他都仅代表某『一个』字符, 所以,上面的例子说明了,我需要的字符串是『tast』或『test』两个字符串而已!
而如果想要搜寻到有 oo 的字符时,则使用:
[dmtsai@study ~]$ grep -n 'oo' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
但是,如果我不想要 oo 前面有 g 的话呢?此时,可以利用在集合字符的反向选择 [^] 来达成:
[dmtsai@study ~]$ grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
第 18 行明明有 google 的 goo 啊~别忘记了,因为该行后面出现了 tool 的 too 啊!所以该行也被列出来~ 也就是说, 18 行里面虽然出现了我们所不要的项目 (goo) 但是由于有需要的项目(too) , 因此,是符合字符串搜寻的喔!
至于第 19 行,同样的,因为 goooooogle 里面的 oo 前面可能是 o ,例如: go(ooo)oogle ,所以,这一行也是符合需求的
假设我 oo 前面不想要有小写字符,所以,我可以这样写 [^abcd....z]oo , 但是这样似乎不怎
么方便,由于小写字符的 ASCII 上编码的顺序是连续的, 因此,我们可以将之简化为底下这样:
[dmtsai@study ~]$ grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only
要取得有数字的那一行:
[dmtsai@study ~]$ grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
也可以用以下方式:
[dmtsai@study ~]$ grep -n '[^[:lower:]]oo' regular_express.txt
# 那个 [:lower:] 代表的就是 a-z 的意思!请参考前两小节的说明表格
[dmtsai@study ~]$ grep -n '[[:digit:]]' regular_express.txt
**(3)行首与行尾字符 ^ $ **
如果我想要开头是小写字符的那一行就列出呢?可以这样:
[dmtsai@study ~]$ grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
或者
[dmtsai@study ~]$ grep -n '^[[:lower:]]' regular_express.txt
那如果我不想要开头是英文字母,则可以是这样:
[dmtsai@study ~]$ grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:# I am VBird
# 指令也可以是: grep -n '^[^[:alpha:]]' regular_express.txt
注意到了吧?那个 ^ 符号,在字符集合符号(括号[])之内与之外是不同的!在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义!
那如果我想要找出来,行尾结束为小数点 (.) 的那一行,该如何处理:
[dmtsai@study ~]$ grep -n '\.$' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
11:This window is clear.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
20:go! go! Let's go
因为小数点具有其他意义(底下会介绍),所以必须要使用跳脱字符()来加以解除其特殊意义!
第 5~9 行最后面也是 . 啊~怎么无法打印出来? 这里就牵涉到 Windows 平台的软件对于断行字符的判断问题了!我们使用 cat -A 将第五行拿出来看, 你会发现
[dmtsai@study ~]$ cat -An regular_express.txt | head -n 10 | tail -n 6
5 However, this dress is about $ 3183 dollars.^M$
6 GNU is free air not free beer.^M$
7 Her hair is very beauty.^M$
8 I can't finish the test.^M$
9 Oh! The soup taste good.^M$
10 motorcycle is cheap than car.$
Linux 与 Windows 上的差异, 在上面的表格中我们可以发现5~9 行为 Windows 的断行字符 (^M\() ,而正常的 Linux 应该仅有第 10 行显示的那样 (\)) 。所以啰,那个 . 自然就不是紧接在 $ 之前喔!也就捉不到 5~9 行了!这样可以了解 ^ 与 $ 的意义吗?
那么如果我想要找出来,哪一行是『空白行』, 也就是说,该行并没有输入任何数据,该如何搜寻?
[dmtsai@study ~]$ grep -n '^$' regular_express.txt
22:

因为只有行首跟行尾 (^$),所以,这样就可以找出空白行啦!
找出非 空白行 和 # 注释行
[dmtsai@study ~]$ grep -v '^$' /etc/rsyslog.conf | grep -v '^#'
# 结果仅有 14 行,其中第一个『 -v '^$' 』代表『不要空白行』,
# 第二个『 -v '^#' 』代表『不要开头是 # 的那行』喔!
sed 用法
本身也是一个管线命令,可以分析 standard input 的啦! 而且 sed
还可以将数据进行取代、删除、新增、撷取特定行等等的功能呢!
[dmtsai@study ~]$ sed [-nefr] [动作]
1.选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在指令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(预设是基础正规表示法语法) -i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function 有底下这些咚咚:
a :新增, a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运作~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!
例如 1,20s/old/new/g 就是啦!
2.(1)删除功能
将 /etc/passwd 的内容列出并且打印行号,同时,请将第 2~5 行删除!
[dmtsai@study ~]$ nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
.....(后面省略).....
看到了吧?sed 的动作为 '2,5d' ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行啰~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 '' 两个单引号括住喔!如果题型变化一下,举例来说,如果只要删除第 2 行,可以使用『 nl /etc/passwd | sed '2d' 』来达成,至于若是要删除第 3 到最后一行,则是『 nl /etc/passwd | sed '3,$d' 』的啦,那个钱字号『 $ 』代表最后一行!
(2)新增功能
范例二:承上题,在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[dmtsai@study ~]$ nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
嘿嘿!在 a 后面加上的字符串就已将出现在第二行后面啰!那如果是要在第二行前呢?『 nl
/etc/passwd | sed '2i drink tea' 』就对啦!就是将『 a 』变成『 i 』即可。 增加一行很简单,那如果
是要增将两行以上呢?
范例三:在第二行后面加入两行字,例如『Drink tea or .....』与『drink beer?』
[dmtsai@study ~]$ nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
在多行新增的情况下, \ 是一定要的喔!
(3)取代功能
范例四:我想将第 2-5 行的内容取代成为『No 2-5 number』呢?
[dmtsai@study ~]$ nl /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
.....(后面省略).....
以前想要列出第 11~20 行, 得要透过『head -n 20 | tail -n 10』之类的方法来处理,很麻烦啦~ sed 则可以简单的直接取出你想要的那几行!是透过行号来捉的喔!看看底下的范例先.
范例五:仅列出 /etc/passwd 文件内的第 5-7 行
[dmtsai@study ~]$ nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
上述的指令中有个重要的选项『 -n 』,按照说明文件,这个 -n 代表的是『安静模式』! 那么为什么要使用安静模式呢?你可以自行下达 sed '5,7p' 就知道了 (5-7 行会重复输出)! 有没有加上 -n 的参数时,输出的数据可是差很多的喔!你可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号捉出来查阅!很棒的功能!不是吗?
(4) 部分数据的搜寻并取代的功能
sed 还可以用行为单位进行部分数据的搜寻并取代的功能喔! 基本上sed 的搜寻与取代的与 vi 相当的类似!他有点像这样:
sed 's/要被取代的字符串/新的字符串/g'
上表中特殊字体的部分为关键词,请记下来!至于三个斜线分成两栏就是新旧字符串的替换啦! 我们使用底下这个取得 IP 数据的范例,一段一段的来处理给您瞧瞧,让你了解一下什么是咱们所谓的搜寻并取代吧!
步骤一:先观察原始讯息,利用 /sbin/ifconfig 查询 IP 为何?
[dmtsai@study ~]$ /sbin/ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::5054:ff:fedf:e174 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:df:e1:74 txqueuelen 1000 (Ethernet)
.....(以下省略).....
# 因为我们还没有讲到 IP ,这里你先有个概念即可啊!我们的重点在第二行,
# 也就是 192.168.1.100 那一行而已!先利用关键词捉出那一行!
步骤二:利用关键词配合 grep 撷取出关键的一行数据
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet '
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 当场仅剩下一行!要注意, CentOS 7 与 CentOS 6 以前的 ifconfig 指令输出结果不太相同,
# 鸟哥这个范例主要是针对 CentOS 7 以后的喔!接下来,我们要将开始到 addr: 通通删除,
# 就是像底下这样:
# inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 上面的删除关键在于『 ^.*inet 』啦!正规表示法出现! ^_^
步骤三:将 IP 前面的部分予以删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g'
192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 仔细与上个步骤比较一下,前面的部分不见了!接下来则是删除后续的部分,亦即:
192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 此时所需的正规表示法为:『 ' *netmask.*$ 』就是啦!
步骤四:将 IP 后面的部分予以删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' \
> | sed 's/ *netmask.*$//g'
192.168.1.100
-
sed 与正规表示法的配合练习
假设我只要 MAN 存在的那几行数据, 但是含有 # 在内的批注我不想要,而且空白行我也不要!步骤一:先使用 grep 将关键词 MAN 所在行取出来 [dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN' # MANDATORY_MANPATH manpath_element # MANPATH_MAP path_element manpath_element # MANDB_MAP global_manpath [relative_catpath] # every automatically generated MANPATH includes these fields ....(后面省略).... 步骤二:删除掉批注之后的数据! [dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN'| sed 's/#.*$//g' MANDATORY_MANPATH /usr/man ....(后面省略).... # 从上面可以看出来,原本批注的数据都变成空白行啦!所以,接下来要删除掉空白行 [dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN'| sed 's/#.*$//g' | sed '/^$/d' MANDATORY_MANPATH /usr/man MANDATORY_MANPATH /usr/share/man MANDATORY_MANPATH /usr/local/share/man ....(后面省略).... -
直接修改文件内容(危险动作)
由于这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置文件来测试喔! 我们还是使用你下载的 regular_express.txt文件来测试看看吧!范例六:利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 ! [dmtsai@study ~]$ sed -i 's/\.$/\!/g' regular_express.txt # 上头的 -i 选项可以让你的 sed 直接去修改后面接的文件内容而不是由屏幕输出喔! # 这个范例是用在取代!请您自行 cat 该文件去查阅结果啰! 范例七:利用 sed 直接在 regular_express.txt 最后一行加入『# This is a test』 [dmtsai@study ~]$ sed -i '$a # This is a test' regular_express.txt # 由于 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增啰!
sed 的『 -i 』选项可以直接修改文件内容,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订!很棒吧!
- 延伸正规表示法
在上节的例题三的最后一个例子中,我们要去除空白行与行首为 # 的行列,使用的是
grep -v '^$' regular_express.txt | grep -v '^#'
需要使用到管线命令来搜寻两次!那么如果使用延伸型的正规表示法,我们可以简化为:
egrep -v '^$|^#' regular_express.txt
延伸型正规表示法可以透过群组功能『 | 』来进行一次搜寻!那个在单引号内的管线意义为『或 or』啦! 是否变的更简单呢?此外,grep 预设仅支持基础正规表示法,如果要使用延伸型正规表示法,你可以使用 grep -E , 不过更建议直接使用 egrep !直接区分指令比较好记忆!其实 egrep 与 grep -E 是类似命令别名的关系啦!
延伸型正规表示法有哪几个特殊符号?


以上这些就是延伸型的正规表示法的特殊字符。另外,要特别强调的是,那个 ! 在正规表示法当中
并不是特殊字符, 所以,如果你想要查出来文件中含有 ! 与 > 的字行时,可以这样:
grep -n '[!>]' regular_express.txt
格式化打印: printf
-
用法
[dmtsai@study ~]$ printf '打印格式' 实际内容
-
参数
选项与参数: 关于格式方面的几个特殊样式: \a 警告声音输出 \b 退格键(backspace) \f 清除屏幕 (form feed) \n 输出新的一行 \r 亦即 Enter 按键 \t 水平的 [tab] 按键 \v 垂直的 [tab] 按键 \xNN NN 为两位数的数字,可以转换数字成为字符。 关于 C 程序语言内,常见的变数格式 %ns 那个 n 是数字, s 代表 string ,亦即多少个字符; %ni 那个 n 是数字, i 代表 integer ,亦即多少整数字数; %N.nf 那个 n 与 N 都是数字, f 代表 floating (浮点),如果有小数字数, 假设我共要十个位数,但小数点有两位,即为 %10.2f 啰! 范例一:将刚刚上头数据的文件 (printf.txt) 内容仅列出姓名与成绩:(用 [tab] 分隔) [dmtsai@study ~]$ printf '%s\t %s\t %s\t %s\t %s\t \n' $(cat printf.txt) Name Chinese English Math Average DmTsai 80 60 92 77.33 VBird 75 55 80 70.00 Ken 60 90 70 73.33
由于 printf 并不是管线命令,因此我们得要透过类似上面的功能,将文件内容先提出来给 printf 作为后续的资料才行。 如上所示,我们将每个数据都以 [tab] 作为分隔,但是由于 Chinese 长度太长,导致 English 中间多了一个 [tab] 来将资料排列整齐!啊~结果就看到资料对齐结果的差异了!
另外,在 printf 后续的那一段格式中,%s 代表一个不固定长度的字符串,而字符串与字符串中间就以 \t 这个 [tab] 分隔符来处理!你要记得的是,由于 \t 与 %s 中间还有空格,因此每个字符串间会有一个 [tab] 与一个空格键的分隔喔!
既然每个字段的长度不固定会造成上述的困扰,那我将每个字段固定就好啦!没错没错!这样想非常
好! 所以我们就将数据给他进行固定字段长度的设计吧!
范例二:将上述资料关于第二行以后,分别以字符串、整数、小数点来显示:
[dmtsai@study ~]$ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt | grep -v Name)
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
上面的格式共分为五个字段, %10s 代表的是一个长度为 10 个字符的字符串字段,%5i 代表的是长度为 5 个字符的数字字段,至于那个 %8.2f 则代表长度为 8 个字符的具有小数点的字段,其中小数点有两个字符宽度。我们可以使用底下的说明来介绍 %8.2f 的意义:
字符宽度: 12345678
%8.2f 意义:00000.00
如上所述,全部的宽度仅有 8 个字符,整数部分占有 5 个字符,小数点本身 (.) 占一位,小数点下的位数则有两位。
printf 除了可以格式化处理之外,他还可以依据 ASCII 的数字与图形对应来显示数据喔(注 3)! 举
例来说 16 进位的 45 可以得到什么 ASCII 的显示图 (其实是字符啦)?
范例三:列出 16 进位数值 45 代表的字符为何?
[dmtsai@study ~]$ printf '\x45\n'
E
# 这东西也很好玩~他可以将数值转换成为字符,如果你会写 script 的话,
# 可以自行测试一下,由 20~80 之间的数值代表的字符是啥喔! ^_^
awk:好用的数据处理工具
[dmtsai@study ~]$ awk '条件类型 1{动作 1} 条件类型 2{动作 2} ...' filename
awk 后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作。awk 主要是处理『每一行
的字段内的数据』,而默认的『字段的分隔符为 "空格键" 或 "[tab]键" 』!
[dmtsai@study ~]$ last -n 5 <==仅取出前五行
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 (03:22)
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 (06:12)
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 (00:14)
dmtsai tty1 Fri May 29 11:55 - 12:11 (00:15)
若我想要取出账号与登入者的 IP ,且账号与 IP 之间以 [tab] 隔开,则会变成这样:
[dmtsai@study ~]$ last -n 5 | awk '{print $1 "\t" $3}'
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai Fri
字段的分隔则以空格键或 [tab] 按键来隔开。 因为不论哪一行我都要处理,因此,就不需要有 "条件类型" 的限制!我所想要的是第一栏以及第三栏, 但是,第五行的内容怪怪的~这是因为数据格式的问题啊!所以啰~使用 awk 的时候,请先确认一下你的数据当中,如果是连续性的数据,请不要有空格或[tab] 在内,否则,就会像这个例子这样,会发生误判喔!
另外,由上面这个例子你也会知道,在 awk 的括号内,每一行的每个字段都是有变量名称的,那就
是 $1, $2... 等变量名称。以上面的例子来说,dmtsai 是 $1 ,因为他是第一栏嘛!至于 192.168.1.100
是第三栏, 所以他就是 $3 啦!后面以此类推~呵呵!还有个变数喔!那就是 $0 ,$0 代表『一整
列资料』的意思~以上面的例子来说,第一行的 $0 代表的就是『dmtsai .... 』那一行啊! 由此可知,
刚刚上面五行当中,整个 awk 的处理流程是:
1. 读入第一行,并将第一行的资料填入 $0, $1, $2.... 等变数当中;
2. 依据 "条件类型" 的限制,判断是否需要进行后面的 "动作";
3. 做完所有的动作与条件类型;
4. 若还有后续的『行』的数据,则重复上面 1~3 的步骤,直到所有的数据都读完为止。
经过这样的步骤,你会晓得, awk 是『以行为一次处理的单位』, 而『以字段为最小的处理单位』。好了,那么 awk 怎么知道我到底这个数据有几行?有几栏呢?这就需要 awk 的内建变量的帮忙啦~
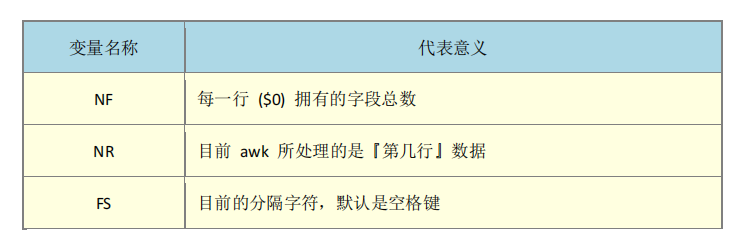
我们继续以上面 last -n 5 的例子来做说明,如果我想要:
列出每一行的账号(就是 $1); 列出目前处理的行数(就是 awk 内的 NR 变量) 并且说明,该行有多少字段(就是 awk 内的 NF 变量)
则可以这样:
要注意喔,awk 后续的所有动作是以单引号『 ' 』括住的,由于单引号与双引号都必须是成对的, 所以, awk 的格式内容如果想要以 print 打印时,记得非变量的文字部分,包含上一小节 printf 提到的格式中,都需要使用双引号来定义出来喔!因为单引号已经是 awk 的指令固定用法了!
[dmtsai@study ~]$ last -n 5| awk '{print $1 "\t lines: " NR "\t columns: " NF}'
dmtsai lines: 1 columns: 10
dmtsai lines: 2 columns: 10
dmtsai lines: 3 columns: 10
dmtsai lines: 4 columns: 10
dmtsai lines: 5 columns: 9
# 注意喔,在 awk 内的 NR, NF 等变量要用大写,且不需要有钱字号 $ 啦!
(2)awk 的逻辑运算字符
既然有需要用到 "条件" 的类别,自然就需要一些逻辑运算啰~例如底下这些:
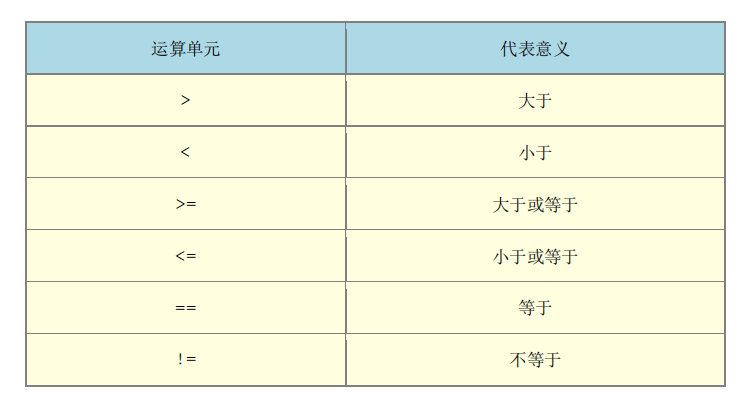
值得注意的是那个『 == 』的符号,因为:
逻辑运算上面亦即所谓的大于、小于、等于等判断式上面,习惯上是以『 == 』来表示;
如果是直接给予一个值,例如变量设定时,就直接使用 = 而已。
举例说,在 /etc/passwd 当中是以冒号 ":" 来作为字段的分隔, 该文件中第一字段为账号,第三字段则是 UID。那假设我要查阅,第三栏小于 10 以下的数据,并且仅列出账号与第三栏, 那么可以这样做:
[dmtsai@study ~]$ cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t " $3}'
root:x:0:0:root:/root:/bin/bash
bin 1
daemon 2
....(以下省略)....
不过,怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变数 $1,
$2... 默认还是以空格键为分隔的,所以虽然我们定义了 FS=":" 了, 但是却仅能在第二行后才开始
生效。那么怎么办呢?我们可以预先设定 awk 的变量啊! 利用 BEGIN 这个关键词喔!这样做:
[dmtsai@study ~]$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
daemon 2
......(以下省略)......
而除了 BEGIN 之外,我们还有 END 呢!另外,如果要用 awk 来进行『计算功能』呢?
以底下的例子来看, 假设我有一个薪资数据表档名为 pay.txt ,内容是这样的
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
如何帮我计算每个人的总额呢?而且我还想要格式化输出喔!我们可以这样考虑:
第一行只是说明,所以第一行不要进行加总 (NR==1 时处理);
第二行以后就会有加总的情况出现 (NR>=2 以后处理)
[dmtsai@study ~]$ cat pay.txt | \
> awk 'NR==1{printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total" }
> NR>=2{total = $2 + $3 + $4
> printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
Name 1st 2nd 3th Total
VBird 23000 24000 25000 72000.00
DMTsai 21000 20000 23000 64000.00
Bird2 43000 42000 41000 126000.00
上面的例子有几个重要事项应该要先说明的:
awk 的指令间隔:所有 awk 的动作,亦即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号『;』
间隔, 或者直接以 [Enter] 按键来隔开每个指令,例如上面的范例中,鸟哥共按了三次 [enter] 喔!
逻辑运算当中,如果是『等于』的情况,则务必使用两个等号『==』!
格式化输出时,在 printf 的格式设定当中,务必加上 \n ,才能进行分行!
与 bash shell 的变量不同,在 awk 当中,变量可以直接使用,不需加上 $ 符号。
awk 的输出格式当中,常常会以 printf 来辅助,所以, 最好你对 printf 也稍微熟悉一下比较好啦!另外, awk 的动作内 {} 也是支持 if (条件) 的喔! 举例来说,上面的指令可以修订成为这样:
[dmtsai@study ~]$ cat pay.txt | \
> awk '{if(NR==1) printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"}
> NR>=2{total = $2 + $3 + $4
> printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
我个人是比较倾向于使用第一种语法, 因为会比较有统一性啊!
diff 文件对比
diff 通常是用在同一的文件(或软件)的新旧版本差异上! 举例来说,假如我们要将 /etc/passwd 处理成为一个新的版本,处理方式为: 将第四行删除,
第六行则取代成为『no six line』,新的文件放置到 /tmp/test 里面,那那么应该怎么做?
[dmtsai@study ~]$ mkdir -p /tmp/testpw <==先建立测试用的目录
[dmtsai@study ~]$ cd /tmp/testpw
[dmtsai@study testpw]$ cp /etc/passwd passwd.old
[dmtsai@study testpw]$ cat /etc/passwd | sed -e '4d' -e '6c no six line' > passwd.new
# 注意一下, sed 后面如果要接超过两个以上的动作时,每个动作前面得加 -e 才行!
# 透过这个动作,在 /tmp/testpw 里面便有新旧的 passwd 文件存在了!
关于diff的用法
[dmtsai@study ~]$ diff [-bBi] from-file to-file
选项与参数:
from-file :一个档名,作为原始比对文件的档名;
to-file :一个档名,作为目的比对文件的档名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表『Standard input』之意。
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。
范例一:比对 passwd.old 与 passwd.new 的差异:
[dmtsai@study testpw]$ diff passwd.old passwd.new
4d3 <==左边第四行被删除 (d) 掉了,基准是右边的第三行
< adm:x:3:4:adm:/var/adm:/sbin/nologin <==这边列出左边(<)文件被删除的那一行内容
6c5 <==左边文件的第六行被取代 (c) 成右边文件的第五行
< sync:x:5:0:sync:/sbin:/bin/sync <==左边(<)文件第六行内容
---
> no six line <==右边(>)文件第五行内容
# 很聪明吧!用 diff 就把我们刚刚的处理给比对完毕了!
你不要用 diff 去比对两个完全不相干的文件,因为比不出个啥咚咚! 另外, diff 也可以比对整个目录下的差异喔!举例来说,我们想要了解一下不同的开机执行等级 (runlevel) 内容有啥不同?假设你已经知道执行等级 0 与 5 的启动脚本分别放置到/etc/rc0.d 及 /etc/rc5.d , 则我们可以将两个目录比对一下:
[dmtsai@study ~]$ diff /etc/rc0.d/ /etc/rc5.d/
Only in /etc/rc0.d/: K90network
Only in /etc/rc5.d/: S10network
sar命令
在使用UNIX操作系统的过程中,我们常常会用到各种各样的问题,比如系统运行速度突然变慢,系统容易死机或者主机所带的终端常出现死机,这时我们常常猜测,是硬盘空间太小,还是内存不足?I/O出现瓶颈,或者是系统的核心参数出了问题?这时,我们应该考虑使用系统给我们提供的sar命令来对系统作一个了解,该命令是系统维护的重要工具,主要帮助我们掌握系统资源的使用情况,特别是内存和CPU 的使用情况,是UNIX系统使用者应该掌握的工具之一。
- sar命令常用格式
![]()
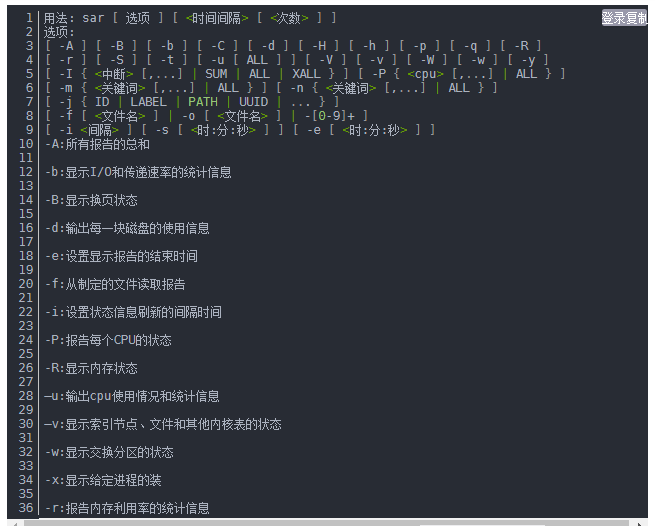
https://blog.csdn.net/weixin_44232712/article/details/121084965
10.端口信息
Redis 6379
mysql 3306
mongodb 27017
80 http web服务器端口
443 https 加密的http协议
8000 django
22 ssh协议用的端口
8080 自定义的端口
netstat -tunlp |grep 3306 #确认mysql是否启动了3306端口
netstat -tunlp |grep 8000 #验证django是否正常启动
11.过滤字符串命令,过滤文本信息
语法 : grep 参数 你要过滤字符串 你要操作的文件
grep -i "all" settings.py
-i 是忽略大小写 -v 是翻转搜索结果
1)过滤掉settings.py中无用的信息(空白行,注释行)
grep -v "^#" settings.py | grep -v "^$"
2)过滤出file1中以abc结尾的行
grep 'abc$' file1
12.查看,检测文件
head -5 filename #看文件的前5行
tail -5 filename #看文件的后5行
tail -f fielname #实时监测文件信息
13.alias 别名
alias rm="echo 你这个大傻x,求你别用rm了"
unalias rm #取消别名 ,重新赋值别名变量也可以
14.远程传输命令scp
语法: scp 你想传输的内容 你想传输到的地方
1)把自己的文件 发送给别人
scp 小姐姐电话.txt root@192.168.16.41:/tmp/
2)把别人的文件夹拿过来
scp -r root@192.168.16.41:/tmp/s19/ ./
3)把自己的文件夹,发送给别人
scp -r 你的文件夹 用户名@其他人的服务器ip:路径
15.如何查看文件夹大小du -sh
ls -lh . #详细的显示当前文件信息,和大小单位
ll 等于 ls -l
du -sh /var/log/ # -h 显示 kb mb gb 单位 -s 显示合计大小
16.linux的任务管理器
top命令
17.给文件加锁,解锁
chattr +a filename #给文件加锁 让文件不得删除
chattr -a filename #减锁
lsattr filname #显示文件是否有锁
18.时间同步
date 查看当前系统时间
和阿里云的时间服务器同步
ntpdate -u ntp.aliyun.com #和阿里的时间服务器同步 -u 更新
call :查看日历
19.切换用户 su
Whoami #先看下当前用户(我是谁)
su - oldboy #切换用户
logout ctrl + d #退出用户登录
20.解压缩源代码
语法: tar -xf Python-3.6.2.tgz
tar 是压缩解压的命令 -x 是解压参数 -f 指定一个压缩文件的名字
1)解压缩命令
-c 打包
-x 解包
-z 调用gzip命令去压缩文件,节省磁盘空间
-v 显示打包过程
语法: tar -cvf 打包文件的名字 你要打包的内容
压缩<打包>当前的所有内容到alltmp.tar这个文件中,这里不节省磁盘
tar -cvf 压缩文件的名字.tar ./*
解压的方式
tar -xvf 压缩文件的名字.tar
打包文件,并且压缩文件大小的用法,节省磁盘
tar -zcvf 压缩文件的名字.tar.gz ./*
解压缩
tar -zxvf 压缩文件的名字.tar.gz
21.linux下载软件包的方法有?
wget curl
22.linux如何安装软件?有几种方式?
yum rpm 源码包
rpm命令的使用方式:
安装软件的命令格式 rpm -ivh filename.rpm # i表示安装 v显示详细过程 h以进度条显示
升级软件的命令格式 rpm -Uvh filename.rpm
卸载软件的命令格式 rpm -e filename.rpm
查询软件描述信息的命令格式 rpm -qpi filename.rpm
列出软件文件信息的命令格式 rpm -qpl filename.rpm
查询文件属于哪个 RPM 的命令格式 rpm -qf filename
23.linux和windows互传文件的软件 lrzsz
yum install lrzsz -y
rz 接受文件(从windows接受文件)
sz 发送文件(发送linux文件给windows)
24.临时提权的命令sudo
1.修改sudoers配置文件,把你想提权的用户写进去
编辑配置文件
vim /etc/sudoers
2.写入如下信息,定位到那一行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
kun ALL=(ALL) ALL #允许kun在任何地方,执行任何命令
3.使用sudo命令
sudo 你想执行的命令
25.文件拥有者分三类
属主 users u
属组 group g
其他人others o
- 普通文本
d 文件夹
l 软连接
R 可读 w 可写 x 可执行
修改权限
chmod 权限 文件/文件夹权限
chmod 777 你好.txt #赋予文本最高的权限
权限分为: r 4 w 2 x 1
更改文件的属主,属组
chown 用户名 要操作的文件 #更改文件属主
chgrp 组名 要操作的文件 #更改文件属组
26.软连接
语法: ln -s 目标文件 快捷方式绝对路径
27.linux的命令提示符
PS1变量
echo $PS1 #显示命令提示符
修改命令提示符
PS1="[\u@\h \w \t]\$"
27.什么是dns(域名解析系统)
其实就是一个超大的网络电话簿 ,dns就是域名解析到ip的一个过程,
linux的dns配置文件如下 :
vim /etc/resolv.conf
linux解析dns的命令:
nslookup 域名
解析流程:
自上而下的顺序
1.优先查找本地dns缓存
2.查找本地/etc/hosts文件,是否有强制解析
3.如果没有去/etc/resolv.conf指定的dns服务器中查找记录(需联网
4.在dns服务器中找到解析记录后,在本地dns中添加缓存
5.完成一次dns解析
如何给linux添加一个dns服务器记录
echo "nameserver 114.114.114.114" >> /etc/resolv.conf
28.定时任务
分 时 日 月 周
-
-
-
-
- 命令的绝对路径
-
-
-
例:每周一到周五的凌晨1点,清空/tmp目录的所有文件
00 1 * * 1-5 /usr/bin/rm -rf /tmp/*
在晚上8-11点的第3和第15分钟执行
3,15 20-23 * * * 命令的绝对路径
29.yum源的工作目录是?
/etc/yum.repos.d/ 在这个目录下
所有名字是 *.repo的文件,就会被识别为仓库文件
Yum makecache生成yum缓存
30.tree是什么作用?
以树状图显示文件夹内容
31.系统用户的环境变量配置文件是?
.修改/.bash_profile(首选),将影响当前用户。在/.bash_profile文件中添加
系统全局环境变量配置文件是?
/etc/profile
31.防火墙
防火墙作用:保护服务器的流量网络安全,允许/禁止 ip地址段和端口的出入流量
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开机自启
iptables -F #清空防火墙规则
Virtualenv 虚拟环境
含义:virtualenv就是用来为一个应用创建一套“隔离”的Python运行环境。
1.python的虚拟环境,用于解决python环境依赖冲突的问题,仅仅是多个解释器的分身,多个解释器的复制,和操作系统无关
2.python虚拟环境的工具有很多 ,有virtualenv,pipenv ,pyenv
3.virtualenv 可以在系统中建立多个不同并且相互不干扰的虚拟环境。
创建虚拟环境
这个命令,在哪敲,就会在哪生成venv文件夹
virtualenv --no-site-packages --python=python3 venv #得到独立第三方包的环境,并且指定解释器是python3
#参数解释
--no-site-packages #这个参数用于构建,干净的环境,没有任何的第三方包
--python=python3 #指定虚拟环境的本体,是python的哪一个版本
venv 就是一个虚拟环境的文件夹,是虚拟python解释器
source activate #source是读取指令,读取这个activate脚本中的内容,激活虚拟环境
virtualenvwrapper
Virtaulenvwrapper是virtualenv的扩展包,用于更方便管理虚拟环境
命令:
mkvirtualenv 虚拟环境的名字 #创建虚拟环境,存放目录是统一管理的
workon 虚拟环境的名字 #可以在任意目录直接激活虚拟环境
rmvirtualenv 虚拟环境的名字 #删除虚拟环境
lsvirtualenv #列出所有的虚拟环境
cdvirtualenv #进入虚拟环境的目录
cdsitepackages #进入虚拟环境的第三方包
virtualenv和virtualenvwrapper区别:
virtualenv每次开启虚拟环境之前要去虚拟环境所在目录下的 bin 目录下 source 一下 activate,
Virtualenvwrapper
1.安装虚拟环境 pip3 install virtualenvwrapper
2.创建并进入虚拟环境 mkvirtualenv env1
3.切换虚拟环境 workon 虚拟环境名
nginx
web服务器(nginx): 接收HTTP请求(例如www.pythonav.cn/xiaocang.jpg)并返回数据
web框架(django,flask): 开发web应用程序,处理接收到的数据
1.静态网站
就是不变化的网页,静态的html,css js等页面,以及jpg gif mp4等静态资源
2.动态网站
指的是,可以与数据库打交道,数据交互的网页,网页内容根据数据库的数据变化
3..常见web服务器有哪些
windows下 IIS服务器
linux下的web服务器 nginx apache lighthttp
4.web服务器
nginx 这样的软件
web服务器它自己 不支持 编程,仅仅是页面返回,nginx + lua
django flask tornado这样的 web逻辑框架 支持 程序员自己写代码,进行逻辑处理
nginx是什么
nginx是web服务器、反向代理服务器、邮件代理服务器,负载均衡等等,支持高并发的一款web服务器
为什么Nginx性能这么高
因为他的事件处理机制:异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
为什么要用Nginx
1.跨平台、配置简单、方向代理、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发,内存消耗小:开启10个nginx才占150M内存 ,nginx处理静态文件好,耗费内存少,
2.而且Nginx内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
3.使用Nginx的话还能:
节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
稳定性高:宕机的概率非常小
接收用户请求是异步的
启动nginx
直接输入nginx 指令,默认代表启动,不得再执行第二次
nginx
nginx -s reload #平滑重启nginx,不重启nginx,仅仅是重新读取nginx配置文件
nginx -s stop #停止nginx进程
nginx -t #检测nginx.conf的语法
Nginx怎么处理请求的
nginx接收一个请求后,首先由listen和server_name指令匹配server模块,再匹配server模块里的location,location就是实际地址
server{ # 一个虚拟主机
listen 80; # 监听的端口,访问的端口80
server_name 192.168.11.11; # 访问的域名192.168.11.11
location / { # 访问的路径 /
root html; # 指定页面的目录,访问/会找到html目录
index index.html # 指定网页,访问/就是访问index.html
}
}
server{ #虚拟主机
listen 8080; #nginx监听端口
server_name 192.168.11.11; #nginx访问域名
location / { #location匹配url
include uwsgi_params; #将uwsgi参数添加进nginx
uwsgi_pass 0.0.0.0:8000; #反向代理转发请求给uwsgi
}
}
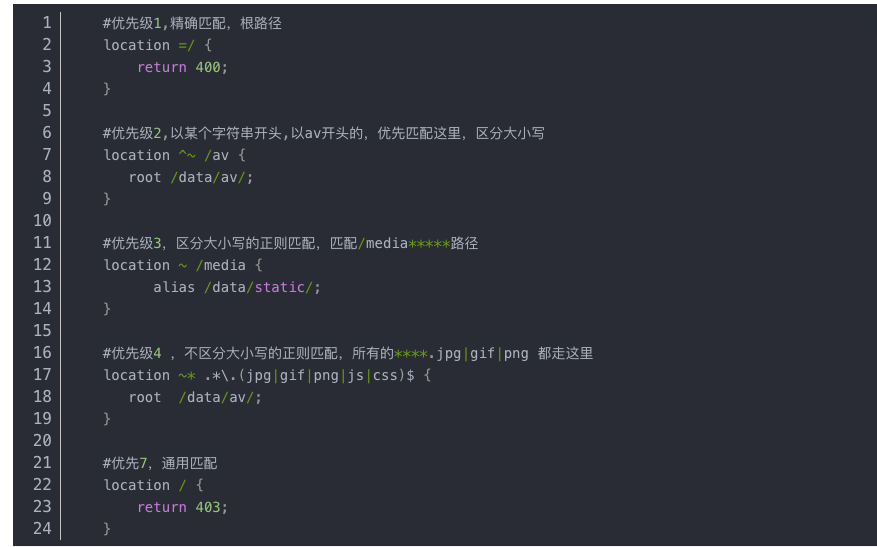
location的语法能说出来吗
解释目录
conf 存放nginx配置文件的
html 存放前端文件目录 ,首页文件就在这里
logs 存放nginx运行日志,错误日志的
sbin 存放nginx执行脚本的
nginx的反向代理功能
1.见过生活中的代理
客户端(请求资源) -> 代理(转发资源) -> 服务端(提供资源)
功能参数: proxy_pass
使用“反向代理服务器的优点是什么
反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。
如何永久添加/opt/python36/的环境变量?
vim /etc/profile
添加PATH = /opt/python36/bin:
source /etc/profile
负载均衡
参数:upstream 地址池
Nginx负载均衡与Nginx代理不同地方在于
Nginx代理仅代理一台服务器,而Nginx负载均衡则是将客户端请求代理转发至一组upstream虚拟服务池
分摊到多个操作单元上进行执行
负载均衡的规则
轮询 ((不做配置,默认轮询)) 按时间顺序逐一分配到不同的后端服务器(默认)
Weight(权重(优先级)) 加权轮询,weight值越大,分配到的访问几率越高,最常用的方式,
ip_hash(配置,根据客户端ip哈希分配,不能和weight一起用) 每个请求按访问IP的hash结果分配,这样来自同一IP的固定访问一个后端服务器
url_hash 按照访问URL的hash结果来分配请求,是每个URL定向到同一个后端服务器
least_conn 最少链接数,那个机器链接数少就分发
为什么要用nginx结合uwsgi
1.nginx支持静态文件处理性能更好,django uwsgi,默认不支持静态文件解析
2.nginx的负载均衡特性,让网站并发性更高
3.并且反向代理特性,用户访问 80,即可访问到8000的应用
4.uwsgi支持多进程的方式,启动django,性能更高
5.nginx转发请求给uwsgi ,应该用 uwsgI_pass ,实现了uwsgi协议的请求转发
Nginx的优缺点
优点:
占内存小,可实现高并发连接,处理响应快
可实现http服务器、虚拟主机、反向代理、负载均衡
Nginx配置简单
可以不暴露正式的服务器IP地址
缺点:
动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力,
如何用Nginx解决前端跨域问题
使用Nginx转发请求。把跨域的接口写成调本域的接口,然后将这些接口转发到真正的请求地址
Nginx虚拟主机怎么配置?
1、基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站
2、基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台
3、基于ip的虚拟主机。
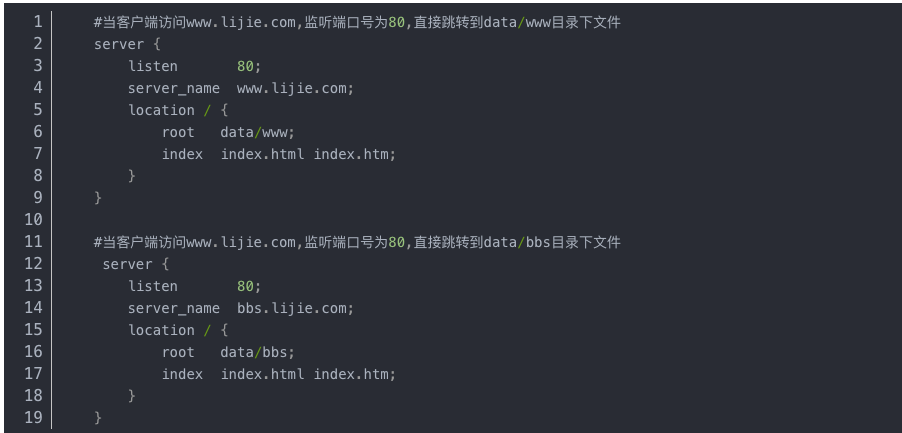
基于虚拟主机配置域名
需要建立/data/www /data/bbs目录,windows本地hosts添加虚拟机ip地址对应的域名解析;对应域名网站目录下新增index.html文件;
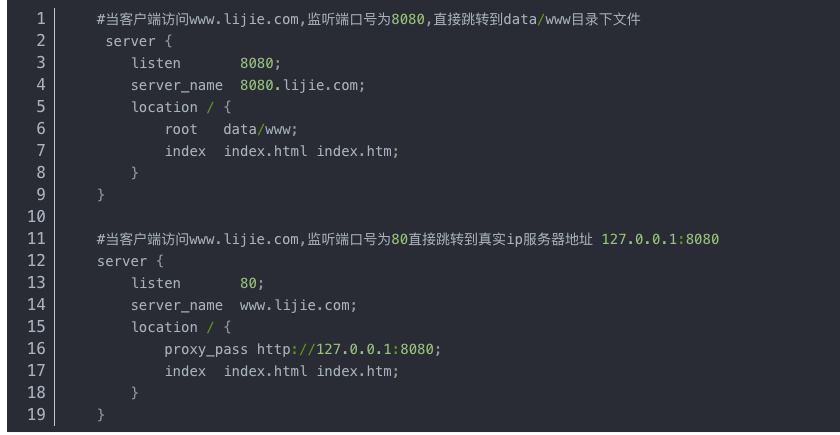
基于端口的虚拟主机
使用端口来区分,浏览器使用域名或ip地址:端口号 访问
进程管理工具supervisor
其实就是在帮咱们去执行命令
退出虚拟环境,在物理环境下安装
supervisorctl 这是管理命令
supervisord 这个是服务端命令
启动supervisor服务
supervisord -c /etc/supervisor.conf
启动所有项目
supervisorctl -c /etc/supervisor.conf
停止任务
supervisor> stop s19_ob_crm
s19_ob_crm: stopped
查看任务状态
supervisor> status
s19_ob_crm STOPPED May 08 12:23 PM
停止所有的任务
supervisor> stop all
s19_ob_crm STOPPED May 08 12:23 PM
启动所有任务
supervisor> start all
s19_ob_crm RUNNING May 08 12:23 PM
Redis 缓存数据库
https://www.cnblogs.com/pyyu/p/9467279.html
./redis-cli //redis的客户端
./redis-server //redis的服务端
redis面试题 https://blog.csdn.net/weixin_40205234/article/details/124614720
Redis是一个开源的基于内存的,key-value数据结构的缓存数据库,支持数据持久化,m-s复制,读写速度快。
主要用来做什么
redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
特点
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
redis为什么快
- 基于内存存储实现的(内存读写比磁盘快)
2.高效的数据结构(字典 Redis 作为 K-V 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如HashMap,通过key就可以直接获取到对应的value。而哈希表的特性,在O(1)时间复杂度就可以获得对应的值。)
redis应用场景
缓存
排行榜
计数器应用
共享Session
分布式锁
社交网络
消息队列
位操作
怎么实现Redis高可用
将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务。Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
redis事务
Redis事务就是顺序性、一次性、排他性的执行一个队列中的一系列命令。
Redis执行事务的流程如下:
开始事务(MULTI)
命令入队
执行事务(EXEC)、撤销事务(DISCARD )
1.数据类型 string set hash list
1)字符串(strings)
语法:set key value
set name dsb #设置name为key,值是dsb
get name #获取name的值
append 追加string
mset 设置多个键值对
mget 获取多个键值对
del 删除key
incr 递增+1
decr 递减-1
2)散列(hashes) 字典key-value
语法 hset key field value
hset 设置散列值
hget 获取散列值
hmset 设置多对散列值
hmget 获取多对散列值
hsetnx 如果散列已经存在,则不设置(防止覆盖key)
hkeys 返回所有keys
hvals 返回所有values
hlen 返回散列包含域(field)的数量
hdel 删除散列指定的域(field)
hexists 判断是否存在
例:
hset news1 content "news content" #添加一个conntent内容
hget news1 content #获取news的内容
3)列表(lists)
lpush 从列表左边插
rpush 从列表右边插
lrange 获取一定长度的元素 lrange key start stop
ltrim 截取一定长度列表
lpop 删除最左边一个元素
rpop 删除最右边一个元素
lpushx/rpushx key存在则添加值,不存在不处理
4)集合(set)无序,去重的数据类型
sadd/srem 添加/删除 元素
sismember 判断是否为set的一个元素
smembers 返回集合所有的成员
sdiff 返回一个集合和其他集合的差异
sinter 返回几个集合的交集
sunion 返回几个集合的并集
5)有序集合(zset)
keys * 查看机器所有的key
type key #显示key的类型
expire key #给key加上过期时间
ttl key #查看key的剩余 过期时间 -1 是永不过期 -2 是没有这个key
persist # 取消key的过期时间 -1表示key存在,没有过期时间
exists key #判断key存在 存在返回1 否则0
dbsize #计算key的数量
2.发布订阅
发布 PUBLISH 订阅 SUBSCRIBE
3.redis 数据持久化
背景:进程被杀死,服务器断电,内存中的数据都会被释放,数据丢失,如果redis没有持久化,数据丢失
RDB
基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
通过save指令可以手动触发 持久化
也可以配置时间触发持久化
save 900 1 #900秒 1个修改类的操作
aof:
AOF文件内容是字符串
以追加的方式记录redis操作日志的文件。
可以最大程度的保证redis数据安全,类似于mysql的binlog
AOF
优点:数据安全,不怕数据损坏
缺点:,占磁盘,性能损耗高,数据恢复慢
Rdb:
定期保存数据快照 数据可能会丢失,但是持久化速度最快
使用RDB恢复数据:自动的持久化数据存储到dump.rdb后。实际只要重启redis服务即可完成(启动redis的server时会从dump.rdb中先同步数据)
使用save进行本地存储
save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save 900 1
save 300 10
save 60 10000
客户端使用命令进行持久化save存储:
./redis-cli -h ip -p port save
./redis-cli -h ip -p port bgsave
怎么在不重启的情况下将rdb切换成aof
此选项为aof功能的开关,默认为“no”,可以通过“yes”来开启aof功能 ,只有在“yes”下,aof重写/文件同步等特性才会生效
CONFIG set appendonly yes
CONFIG SET save ""
4.高可用之哨兵功能 redis-sentinel
redis哨兵是监控redis主从服务,不存储数据的,
作用是用于自动切换reidis服务主从关系,即当主库服务停止后,会将其中一个从库变为主库
5.redis-cluster集群搭建
redis的集群还未分配 槽位 slots ,我们得下载ruby的脚本,创建这个16384个槽位分配
集群,也就是分布式存储,至少有三个主库才可以运行
使用集群,只需要将每个数据库节点的车路士特热-嗯啊变了配置打开即可
redis 和memcache的区别
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例 如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
总结
有持久化需求或者对数据结构和处理有高级要求的应用,选择redis,其他简单的key/value存储,选择memcache。
docker和k8s的区别
k8s的全称 kubernetes。它是一个完整的分布式系统支撑平台,集群管理功能齐全。Kubernetes同时提供完善的管理工具,涵盖了开发、部署、测试、运行监控等各个环节。k8s是一种开放源码的容器集群管理系统,能够实现自动化部署、扩展容器集群、维护等功能。
Docker是一种开放源码的应用容器引擎,允许开发人员将其应用和依赖包打包成可移植的镜像,然后发布到任何流行的 Linux或 Windows机器上,也能实现虚拟化。该容器完全使用沙箱机制,彼此之间没有任何接口。
Docker是一种开放源码的应用容器引擎,开发者可以将他们的应用和依赖打包在一个可移植的容器中,发布到流行的 Linux机器上,也可以实现虚拟化。
在k8s中kuberctl 的使用
vim ~/.bashrc #查看环境变量配置
kuberctl get po | grep m32 #查看m32tpod名称
kuberctl exec -it 44-m32t-xunfei-mid-mi-online-m32t-bagmeger-tom3u8-normal-5m46cr -c user bash #进入容器,(必须指定user容器),-c 是指定容器,不写是进入默认容器
docker 和 virtualenv 的区别
virtualenv虚拟python运行环境,保证系统python环境的整洁,docker也是一样,只是它虚拟的是系统运行环境。
Docker
docker是容器软件,应用于快速构建应用
1.docker的三大生命周期
容器 镜像 .仓库
仓库有dockerhub 共有仓库,docker registory私有仓库,存放镜像的地方
2.镜像:
增删查
docker search 镜像名字 # 搜索镜像名
docker search hello-world #搜索docker镜像
docker pull 镜像名 #下载docker镜像
docker image ls #查看当前机器的docker镜像
docker images #同上,查看本机的所有docker镜像
docker rmi 镜像名/镜像id #删除docker镜像
docker run -d后台运行 镜像名
-p指定端口映射
-P 随机端口映射
-it (交互式的命令操作)
-v 数据库挂载(宿主机和容器空间的映射 )
docker save #导出镜像
docker load #导入镜像
docker start #启停容器
docker stop
docker login #登录dockerhub
docker commit #提交本地容器记录,保存为一个新的镜像
docker build . #打包构建docker镜像
docker run --name 容器的名字 运行的镜像名
语法是: docker tag 仓库名 yuchao163/仓库名
docker tag 5e0 yuchao163/s19-centos-flask #.修改镜像的名字
#推送docker image到dockerhub
docker push yuchao163/centps-cmd-exec:latest
#删除本地镜像,测试下载pull 镜像文件
docker pull yuchao163/centos-entrypoint-exec
容器:
增删改查
docker run 镜像名字/镜像id #运行docker镜像,生成容器记录
docker run 不存在的镜像名 #会先docker pull下载这个镜像,然后在自动运行
docker container ls #列出当前机器的所有容器(正在运行的容器,正在 运行的docker进程 )
docker ps #查看docker进程,docker容器记录的(正在运行的)
docker ps -a #查看docker所有的进程,以及挂掉的进程
Docker ps -aq #列出所有id
运行一次镜像,就会生成一个容器记录
docker容器必须有正在运行的进程,否则容器就会挂掉
docker rm 容器id/容器名 #删除容器记录(只能删除挂掉的容器记录)
docker rm `docker ps -aq` #一次性删除所有docker容器记录,只能删除挂掉的记录
docker logs 容器id #查看容器内的日志信息
docker logs -f 容器id #实时查看容器的日志
docker exec -it 容器id /bin/bash #用exec指令,进入到容器系统内
-i 交互式的shell命令方式
-t 开启一个终端,去运行
docker exec -it 容器id /bin/bash # 进入一个已经在运行的docker容器中
docker run -it ubuntu /bin/bash #交互式的运行ubuntu容器,且进入容器空间内
cat /etc/os-release #查看版本信息
退出docker容器空间,然后提交这个容器,生成一个新的镜像文件
语法:docker commit 你想要提交的容器id 你想创建的镜像名
提交自定义的docker镜像 如何自己打包镜像,让其他人使用
1.准备一个centos的docker容器,默认是没有vim的
docker run -it centos /bin/bash #创建启动一个docker容器,且是centos系统的
yum install vim -y #下载 vim
2.退出docker容器空间,然后提交这个容器,生成一个新的镜像文件
docker commit 你想要提交的容器id 你想创建的镜像名
3.查看你创建的镜像
docker images
4.导出你提交的镜像,成为一个压缩文件
docker save yuchao163/s19-centos-vim > /opt/myimage.tar.gz
5.把这个压缩文件,传递给其他人,其他人导入这个镜像文件,然后运行,默认就携带了vim编辑器
docker load < /opt/myimage.tar.gz
6、 检查你导入的镜像
docker images
7. 交互式运行切进入
docker run -it 镜像id /bin/bash 就创建了一个新的容器
运行一个web内容的docker容器
docker run -d -P training/webapp python app.py
-d 后台运行
-P 大写的字母p参数,意思是随机映射一个端口
在后台运行docker容器
docker run -d centos /bin/sh -c "while true;do echo hello centos; sleep 1;done"
#每秒打印一次hello centos
-d daemonize 后台运行的意思
centos 指定一个镜像去运行
/bin/sh 指定centos的解释器
-c 指定一段shell语法
指定端口映射关系
docker run -d -p 8888:5000 training/webapp python app.py
-p 宿主机端口:容器内的端口
由于重启了docker,所有的容器都挂掉了,还得重新再运行一下docker私有仓库
Docker run --privileged=true -d -p 5000:5000 -v /opt/data/registry:/var/lib/registry registry
-d 后台运行
-p 端口映射
-v 数据卷挂载
--privileged=true #设置特权运行的容器
dockerfile的学习
dockerfile作用是自定义一个docker镜像
每一个应用程序运行,必须得有一个系统作为载体
定义以哪一个基础镜像去运行docker容器
FROM scratch #制作base image 基础镜像,尽量使用官方的image作为base image
FROM centos #使用base image
FROM ubuntu:14.04 #带有tag的base image
LABEL version=“1.0” #容器元信息,帮助信息,Metadata,类似于代码注释
LABEL maintainer=“yc_uuu@163.com" #告诉别人,这个dockerfile是谁写的
#RUN 万能的指令,去执行你输入的命令
#对于复杂的RUN命令,避免无用的分层,多条命令用反斜线换行,合成一条命令!
RUN yum update && yum install -y vim \
Python-dev #反斜线换行
RUN /bin/bash -c "source $HOME/.bashrc;echo $HOME”
WORKDIR /root #相当于linux的cd命令,改变目录,尽量使用绝对路径!!!不要用RUN cd
WORKDIR /test #如果没有就自动创建
WORKDIR demo #再进入demo文件夹
RUN pwd #打印结果应该是/test/demo
ADD 和 COPY
ADD指令用于把物理机上的文件,添加到容器空间内,并且还有解压缩的作用
COPY指令的作用,是吧物理机的文件,拷贝到容器空间内,仅仅一个作用
ADD与COPY
- 优先使用COPY命令
- ADD除了COPY功能还有解压功能
将本地文件拷贝到 root@106.12.16.169服务器,在在拷贝到容器(k8s)
- 先将本地代码拷贝到106.12.16.169下,(首先先进入到106.12.16.169这个服务器里去执行以下命令)
[root@instance-6wr0hckq qxm]# scp -P 8022 /本地文件路径 root@106.12.16.169:/服务器目标路径
传输整个目录(加 -r 递归传输)
scp -r -P 8022 /本地目录路径 root@106.12.16.169:/服务器目标路径
scp -r -P 8022 /Users/qixiaomin/Desktop/bdcc-dev/baidu/idg-xcloud-service/workflow-ppl-framework/operators/bdcc_legal_etl_dalu/out.tar.gz root@106.12.16.169:/home/qxm/
- 在将106.12.16.169下的包传到k8s容器:
-
正确语法:ktcpun cp [Pod名]:[Pod内源路径] [本地目标路径] -c [容器名]
[root@instance-6wr0hckq qxm]# ktcpun cp ./ 81-conti-poc-test-online-flow-mid-preprocess-normal-5b7948cfz26:/home/caros/workspace/bdcc_legal_etl_dalu/q -c user
- 将容器的tar.gz压缩包传到root@106.12.16.169服务器:
明确指定本地目标路径为 “目录 + 文件名”(避免工具误判):
/home/qxm/out 是目录,必须加上要压缩的文件名
[root@instance-6wr0hckq qxm]#ktcpun cp 80-conti-poc-test-online-flow-data-push-high-59899d44d7-q68vw:/data/tool/output.tar.gz /home/qxm/out/output.tar.gz -c user
ENV
环境变量,尽可能使用ENV增加可维护性
rabbitmq
含义:rabbitmq是一个消息代理,他接收,存储和转发消息(邮局)
1.对消息队列进行授权,可以读写
rabbitmqctl set_permissions -p "/" heiheihei ".*" ".*" ".*"
2..设置用户为管理员权限
rabbitmqctl set_user_tags heiheihei administrator
3..创建rabbitmq的登录账号密码
rabbitmqctl add_user heiheihei 123
(可以 netstat -tunlp 看一下端口 15672,在地址栏输入地址:15672,可以访问了)
1)程序解耦
2)数据冗余,例如rabbitmq的ack机制,消息确认机制
3)削峰能力
4)可恢复性,就算系统中部分组件挂掉,消息在队列也不丢失,待组件恢复后继续处理消息。
5)异步通信,如发红包,短信等流程丢入队列,可以优先级很低的去处理
no_ack=True
不确认机制,不需要给服务端一个确认回复,服务端直接标记消息清除,从队列中删除
no_ack=Flase
确认机制,你消费走了数据,还得给服务端一个确认回复,让服务端可以正确的标记消息清除,保证消息不丢失
队列的持久化
背景:默认队列不支持持久化,rabbitmq重启之后,所有队列丢失
实现rabbitmq持久化条件
delivery_mode=2 #实现消息的持久化,重启后,队列和消息都不丢失
使用durable=True声明queue是持久化
salt 命令
salt-key -L #列出所有主机的秘钥信息
salt-key -a 秘钥id #接受一个秘钥id
#常用参数
-L #查看KEY状态
-A #允许所有
-D #删除所有
-a #认证指定的key
-d #删除指定的key
-r #注销掉指定key(该状态为未被认证)
RPC远程过程调用
将一个函数运行在远程计算机上并且等待获取那里的结果,这个称作远程过程调用(Remote Procedure Call)或者 RPC。 RPC是一个计算机通信协议。
定时任务
crontab是用来定期执行程序的命令
crontab -e
crontab -l
参数
-e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI
-l : 列出目前的时程表
在以上各个字段中,还可以使用以下特殊字符:
"*"代表所有的取值范围内的数字,如月份字段为*,则表示1到12个月;
"/"代表每一定时间间隔的意思,如分钟字段为*/10,表示每10分钟执行1次。
"-"代表从某个区间范围,是闭区间。如“2-5”表示“2,3,4,5”,小时字段中0-23/2表示在0~23点范围内每2个小时执行一次。
","分散的数字(不一定连续),如1,2,3,4,7,9。
注:由于各个地方每周第一天不一样,因此Sunday=0(第一天)或Sunday=7(最后1天)
每天上午8-11点的第3和15分钟执行command:
3,15 8-11 * * * command
每隔2天的上午8-11点的第3和15分钟执行command:
3,15 8-11 */2 * * command
每周六、周日的1 : 10重启smb
10 1 * * 6,0 /etc/init.d/smb restart
2>&1 代表什么
代表 错误重定向到标准输出
例 :*/1 * * * * /usr/local/php/bin/php posts.php >> /data/logs/audit_bbsposts.log 2>&1
0表示键盘输入
1表示屏幕输出
2表示错误输出
">"就是输出(标准输出和标准错误输出)重定向的代表符号
重定向> 若有文件则清除原来数据,重新写入;没有则创建并写入;
重定向>>若有文件,则在文件末尾继续写入;没有则创建并写入
command >out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中。2>&1 是将标准出错重定向到标准输出,
这里的标准输出已经重定向到了out.file文件,即将标准出错也输出到out.file文件中。最后一个& , 是让该命令在后台执行。
试想2>1代表什么,2与>结合代表错误重定向,而1则代表错误重定向到一个文件1,而不代表标准输出;
换成2>&1,&与1结合就代表标准输出了,就变成错误重定向到标准输出.
awk用法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号