
3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。

Spark生态系统主要包含Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX以及独立调度器
Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、HBase等多种外部数据源中的数据。
Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。
MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。 GraphX:Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大的方便了对分布式图处理的需求,能在海量数据上运行复杂的图算法。
独立调度器、Yarn、Mesos:Spark框架可以高效地在一个到数千个节点之间伸缩计算,集群管理器则主要负责各个节点的资源管理工作,为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,Hadoop Yarn、Apache Mesos以及Spark自带的独立调度器都被称为集群管理器。
2.请详细阐述Spark的几个主要概念及相互关系:
关系:
1,Application
一个SparkContext就是一个application,通过spark-submit脚本提交给集群。
2,DAG
RDD依赖组成的有向无环图,来表明一个Application中RDD的依赖关系。
3.Job
(1)没有检查点的正常情况下一个行动算子触发一个Job。
(2)如果行动算子的依赖链中有检查点(checkpoint),则至少有一个额外的Job来专门执行检查点功能。如果有多个checkpoint,需要根据下面参数来确定checkpoint Job的数量:spark.checkpoint.checkpointAllMarkedAncestors
如果值为true,则所有检查点都会执行,父RDD的checkpoint Job先执行。
否则只执行最靠后的RDD的checkpoint Job任务。
(3)主线程是串行阻塞式提交Job的,一个行动操作Job执行完毕后执行其依赖链中的checkpoint Job;然后执行下一个行动操作Job及其checkpoint Job。
4.Stage
(1)stage分为两类:ShuffleMapStage和ResultStage
(2)Spark根据ShuffleDependency来划分Stage,一个ShuffleDependency依赖关系的父RDD为前一个Stage的结束,子RDD(都是ShuffledRDD)下一个stage的开始。一个ShuffleDependency一个ShuffleMapStage,另外还会有一个ResultStage。
(3)一个Job stage的总数=零个或者多个ShuffleMapStage+一个ResultStage。
(4)stage之间有依赖关系,按照依赖关系的顺序串行执行。
5.Task
(1)Task分为两类:ShfflueMapTask和ResultTask。
(2)每个ShuffleMapStage都有一个或者多个ShfflueMapTask,数量为ShuffleMapStage中最后一个RDD的分区数量;
(3)每个ResultStage都有一个或者多个ResultStage,数量为ShuffleMapStage中最后一个RDD的分区数量。
(4)同一个stage的task之间并行执行,不同stage的task遵循stage的顺序。
(5)只有Task才会发送到spark Excutor中执行,涉及到数据计算。其它的概念都只存在于ApplicationMaster中。
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
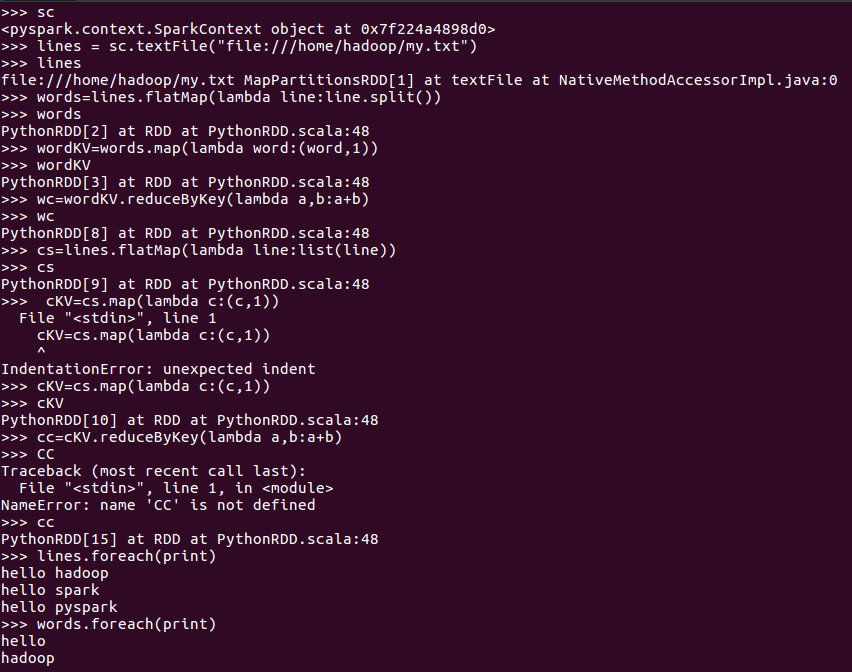



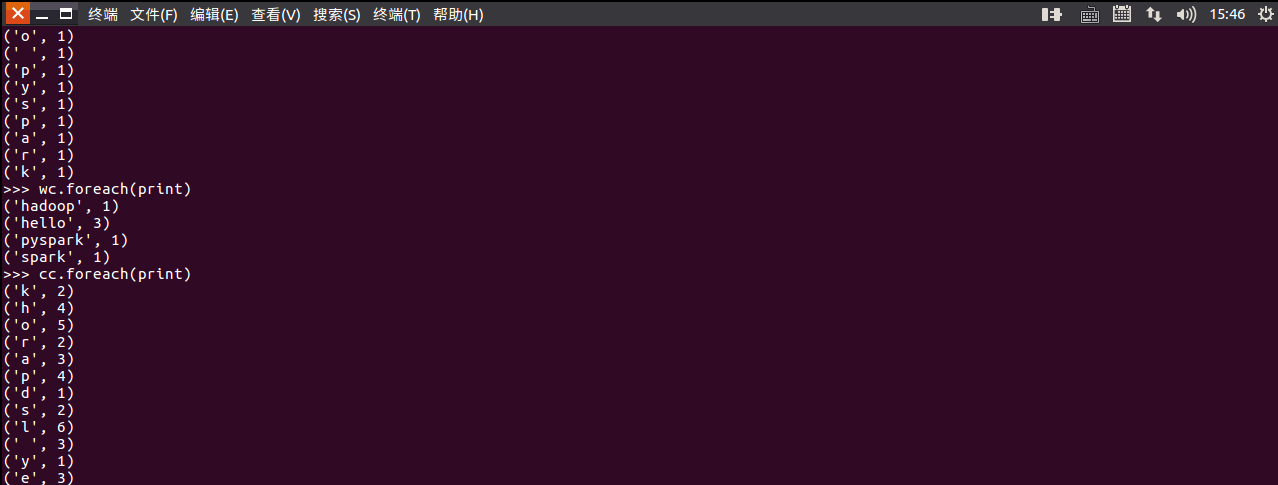
RDD转换关系图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号