集合
集合
1 概述
-
集合是JavaAPI中提供的一种容器工具,可以用来存储多个数据
-
集合和数组的区别
- 数组的长度是固定的,集合的长度是可变的
- 数组中存储的是同一类型的元素,集合中存储的数据可以是不同类型的
- 数组中可以存放基本类型数据或者对象,集合中只能存放对象
- 数组是由JVM中现有的 类型+[] 组合而成的,除了一个length属性,还有从Object中继承过来的方法
之外,数组对象就调用不到其他属性和方法了 - 集合是由JavaAPI中的java.util包里面所提供的接口和实现类组成的,这里面定义并实现了很多方
法,可以使用集合对象直接调用这些方法,从而操作集合存放的数据
-
集合框架三个要素
-
接口
整个集合框架的上层结构,都是用接口进行组织的。
接口中定义了集合中必须要有的基本方法。
通过接口还把集合划分成了几种不同的类型,每一种集合都有自己对应的接口。 -
实现类
对于上层使用接口划分好的集合种类,每种集合的接口都会有对应的实现类。
每一种接口的实现类很可能有多个,每个的实现方式也会各有不同。 -
数据结构
每个实现类都实现了接口中所定义的最基本的方法,例如对数据的存储、检索、操作等方法。
但是不同的实现类,它们存储数据的方式不同,也就是使用的数据结构不同。
-
-
集合按照其存储结构可以分为两大类
java.util.Collection 单列集合 [list set] java.util.Map 双列集合 [map]其他的集合接口都是由这两个接口派生出来的:
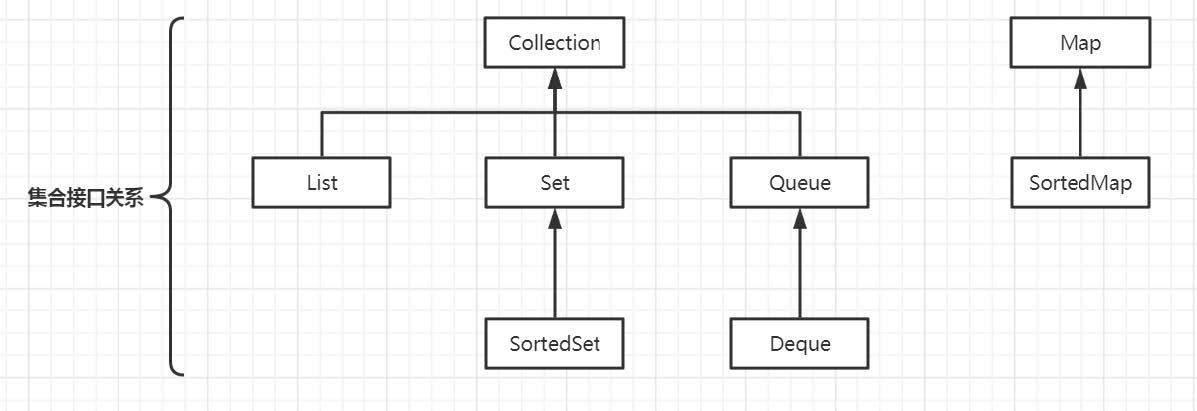
2 Collection接口
Collections接口是单列集合的接口,他有两个重要的子接口:
java.util.List
java.util.Set
Collections接口定义了单列集合(list和set)通用的方法
//向集合中添加元素
boolean add(E e)
//把一个指定集合中的所有数据,添加到当前集合中
boolean addAll(Collection<? extends E> c)
//清空集合中所有的元素。
void clear()
//判断当前集合中是否包含给定的对象。
boolean contains(Object o)
//判断当前集合中是否包含给定的集合的所有元素。
boolean containsAll(Collection<?> c)
//判断当前集合是否为空。
boolean isEmpty()
//返回遍历这个集合的迭代器对象
Iterator<E> iterator()
//把给定的对象,在当前集合中删除。
boolean remove(Object o)
//把给定的集合中的所有元素,在当前集合中删除。
boolean removeAll(Collection<?> c)
//判断俩个集合中是否有相同的元素,如果有当前集合只保留相同元素,如果没有当前集合元素清空
boolean retainAll(Collection<?> c)
//返回集合中元素的个数。
int size()
//把集合中的元素,存储到数组中。
Object[] toArray()
//把集合中的元素,存储到数组中,并指定数组的类型
<T> T[] toArray(T[] a)
12342
3 迭代器
-
java.util.Iterator 接口中,主要定义俩个方法:
public interface Iterator { boolean hasNext();//返回当前迭代器中是否还有下一个对象 Object next();//获取迭代器中的下一个对象 } -
例子
public static void main(String[] args) { Collection c = new ArrayList(); //放学生对象 用迭代器遍历 c.add(new Student("zs",22)); c.add(new Student("lucy",18)); c.add(new Student("tom",10)); c.add(new Student("jack",21)); c.add(new Student("lily",19)); java.util.Iterator it = c.iterator(); while(it.hasNext()) { //next() 获取下一个对象: 一次循环中,只能调用一次。 //System.out.println(((Student)it.next()).getName() + " ... " + ((Student)it.next()).getAge()); Student s = (Student)it.next(); System.out.println(s.getName() + "..." + s.getAge()); } /* c.add("a"); c.add("b"); c.add("c"); //获取集合的迭代器 java.util.Iterator it = c.iterator(); //如果有下一个元素,则取到 输出 //如果没有了,结束 while(it.hasNext()) { System.out.println(it.next()); } */ }
4 增强for循环
-
格式
for(变量类型 变量名 : 集合){ //操作变量 } -
例子
/*** * 遍历集合: 先把集合转成数组,再遍历数组输出 */ public class TraversalTest { public static void main(String[] args) { Collection c = new ArrayList(); c.add(new Student("zs", 21)); c.add(2); c.add(new Student("ls", 19)); c.add(new Student("ww", 20)); c.add(new Student("tom", 21)); c.add(new Student("jack", 23)); //将集合转换成数组 Object[] array = c.toArray(); //遍历数组 for (int i = 0; i < array.length; i++) { if (array[i] instanceof Student) { Student s = (Student) array[i]; System.out.println(s); }else System.out.println(array[i]); } } } 输出结果: Student{name='zs', age=21} 2 Student{name='ls', age=19} Student{name='ww', age=20} Student{name='tom', age=21} Student{name='jack', age=23}
增强for循环可以对集合,数组遍历其中的元素
5 单列集合
5.1 List
- list是一种有序的集合
- list是一种带索引的集合
- list是一种可以存放重复数据的集合
List实现类:
- ArrayList
- LinkedLIst
- Vector
常用方法
//返回集合中指定位置的元素。
E get(int index);
//用指定元素替换集合中指定位置的元素,并返回被替代的旧元素。
E set(int index, E element);
//将指定的元素,添加到该集合中的指定位置上。
void add(int index, E element);
//从指定位置开始,把另一个集合的所有元素添加进来
boolean addAll(int index, Collection<? extends E> c);
//移除列表中指定位置的元素, 并返回被移除的元素。
E remove(int index);
//查收指定元素在集合中的所有,从前往后查到的第一个元素(List集合可以重复存放数据)
int indexOf(Object o);
//查收指定元素在集合中的所有,从后往前查到的第一个元素(List集合可以重复存放数据)
int lastIndexOf(Object o);
//根据指定开始和结束位置,截取出集合中的一部分数据
List<E> subList(int fromIndex, 16 int toIndex);
注意,除了这些方法之外,还有从父接口Collection中继承过来的方法
List集合的方法使用:
基本方法的使用
/*
* * void add(int index,E element)
* E remove(int index)
* E get(int index)
* E hashSet(int index,E element)
*/
public class ListTest {
public static void main(String[] args) {
// 创建List集合对象
List list = new ArrayList();
// 往 尾部添加 指定元素
list.add("hello1");
list.add("hello2");
list.add("hello3");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1, "world");
System.out.println(list);
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// 修改指定位置元素
list.set(0, "123");
System.out.println(list);
//遍历集合
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("-----------------");
//使用foreach遍历
for(Object obj : list){
System.out.println(obj);
}
System.out.println("-----------------");
//使用迭代器进行遍历集合
Iterator it = list.iterator();
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
}
}
5.1.1 ArrayList
java.util.ArrayList 是最常用的一种List类型集合, ArrayList 类中使用数组来实现数据的存储
它的特点是:增删慢,查找快。
在日常的开发中,查询数据也是用的最多的功能,所以ArrayList是最常用的集合
例子
/**
* List集合的特有功能概述
* void add(int index,E element)
* E remove(int index)
* E get(int index)
* E set(int index,E element)
* 需求:我有一个集合,请问,我想判断里面有没有"world"这个元素
* 如果有,我就添加一个"javaee"元素,请写代码实现
*/
public class ListTest2 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("a");
list.add("b");
list.add("world");
list.add("d");
list.add("e");
// == 判断是否指向同一个内存空间
// .equals 判断所指向的内存空间的值是否相同
//使用iterator 一边通过迭代器遍历list, 一边修改list,会出现并发异常
//Iterator it = list.iterator();
ListIterator it = list.listIterator();
while (it.hasNext()) {
String str = (String) it.next();
if ("world".equals(str)) {
it.add("javaee");
//list.add("javaee");
}
}
System.out.println(list);
/*
for (int i = 0; i < list.size(); i++) {
//Object --> String
String str = (String) list.get(i);
if ("world".equals(str)) {
list.add("javaee");
}
}
System.out.println(list);*/
/*
boolean f = list.contains("world");
if ("true".equals(f)) {
list.add("javaee");
}
System.out.println(list);*/
}
}
输出结果:
[a, b, world, javaee, d, e]
5.1.2 LinkedLIst
java.util.LinkedList 存储数据采用的数据结构是链表,所以它的特点是:增删快,查找慢
LinkedList子类特有的方法:
//将指定元素插入此列表的开头
void addFirst(E e)
//将指定元素添加到此列表的结尾
void addLast(E e)
//返回此列表的第一个元素
E getFirst()
//返回此列表的最后一个元素
E getLast()
//从此列表所表示的堆栈处弹出一个元素
E pop()
//将元素推入此列表所表示的堆栈
void push(E e)
//移除并返回此列表的第一个元素
E removeFirst()
//移除并返回此列表的最后一个元素
E removeLast()
例子
/***
* 利用linkedLIst模拟栈数据结构
*/
public class Stack {
private LinkedList list;
public Stack() {
list = new LinkedList();
}
public Stack(LinkedList list) {
this.list = list;
}
public void in(Object obj) {
//往栈结构 添加元素的时候 每次都从尾部添加
list.addLast(obj);
}
public Object out() {
if (list.isEmpty()) {
return null;
}
//每次出栈 都取最后那个元素
Object obj = list.getLast();
//删除最后那个元素
list.removeLast();
return obj;
}
public void show() {
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "\t");
}
System.out.println();
}
}
public class StackTest {
public static void main(String[] args) {
Stack stack = new Stack();
stack.in("a");
stack.in("b");
stack.in("c");
stack.in("d");
stack.show();
Object o1 = stack.out();
stack.show();
Object o2 = stack.out();
stack.show();
}
}
5.1.3 Vector
Vector内部是采用数组存储数据,但是Vector中的方法大多数是线程安全的,所以效率低,速度慢,使用的次数少
Vector的迭代
Vector v = new Vector(); //创建集合对象,List的子类
v.addElement("a");
v.addElement("b");
v.addElement("c");
v.addElement("d");
//Vector迭代
Enumeration en = v.elements(); //获取枚举
while(en.hasMoreElements()) { //判断集合中是否有元素
System.out.println(en.nextElement());//获取集合中的元素
}
5.1.4 List各个子类之间的区别
ArrayList [数组]查询修改快 线程不安全
LinkedList [链表]增加删除快 线程不安全
Vector [数组](过时) 线程安全,效率低
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
LinkedList:
底层数据结构是链表,查询修改慢,增删快。
线程不安全,效率高。
ArrayList:
底层数据结构是数组,查询修改快,增删慢
线程不安全,效率高
Vector和ArrayList的区别
Vector是线程安全的,效率低
ArrayList是线程不安全的,效率高
共同点:都是数组实现的
ArrayList和LinkedList的区别
ArrayList底层是数组结果,查询和修改快
LinkedList底层是链表结构的,增和删比较快,查询和修改比较慢
共同点:都是线程不安全的
查询多用ArrayList
增删多用LinkedList
如果都多ArrayList
5.2 Set
- Set是一种无序的集合
- Set是一种不带下标索引的集合
- Set是一种不能存放重复数据的集合
Set实现类:
- hashSet
- TreeSet(TreeSet是Set接口的子接口SortedSet的实现类)
5.2.1 HashSet
HashSet的实现主要是依靠HashMap,hashMap的实现主要依靠的是哈希表
-
HashSet是靠对象的哈希值来确定元素在集合中的存储位置,所以HashSet是无序的
-
HashSet主要是靠对象的HashCode和equals方法来判断对象是否重复,所以HashSet是不可重复的
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
boolean b1 = hs.add(new Student("zs", 21));
boolean b2 = hs.add(new Student("zs", 21));
boolean b3 = hs.add(new Student("ls", 22));
boolean b4 = hs.add(new Student("ls", 22));
boolean b5 = hs.add(new Student("ww", 19));
System.out.println(b1);
System.out.println(b2);
System.out.println(b3);
System.out.println(b4);
System.out.println(b5);
for (Student h : hs) {
System.out.println(h + "\t");
}
}
输出结果:
true
true
true
true
true
Student{name='zs', age=21}
Student{name='ww', age=19}
Student{name='ls', age=22}
Student{name='zs', age=21}
Student{name='ls', age=22}
由于HashSet中判断对象是否重复是根据对象的HashCode值和equals方法比较结果,而不是根据对象的name和age是否相等判断。
没有重写过的HashCode对每一个对象所得到的HashCode值都不一样
如果俩个对象的hashCode值相等,那么再使用equals判断俩对象是否相同
如果俩个对象的hashCode值不同,就不需要用equals进行判断了,因为hashCode不同的俩个对象一定是不同的俩个对象!
/***
* 往HashSet里插入元素会优先比较HashCode
* 如果HashCode不一致,则说明两个对象不相同。如果一致,则进一步通过equals方法进行比较
* HashCode和equals方法在重写时是绑定的,如果要重写就要把HashCode和equals一起重写
* @return
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
对hashCode和equals方法重写后的结果:
true
false
true
false
true
Student{name='ww', age=19}
Student{name='zs', age=21}
Student{name='ls', age=22}
5.2.2 LinkedHashSet
LinkedHashSet可以保证集合有序且没有重复元素,底层通过链表实现
public static void main(String[] args) {
////保证有序 没有重复元素
LinkedHashSet<Integer> lhs = new LinkedHashSet<>();
lhs.add(5);
lhs.add(2);
lhs.add(3);
lhs.add(1);
lhs.add(3);
lhs.add(5);
System.out.println(lhs.size());
for (Integer l : lhs) {
System.out.print(l + "\t");
}
System.out.println();
}
5.2.3 TreeSet
TreeSet是Set接口的子接口SortedSet的实现类
TreeSet可以将我们存进去的数据进行排序,排序的方式有两种:
- 自然排序
- 比较器排序(也称客户化排序)
如果要实现TreeSet必须要实现以上两种方式的一种
自然排序
自然排序: 让类实现java.lang.Comparable 接口,通过comparaTo方法编写比较规则
public interface Comparable<T> {
public int compareTo(T o);
}
compareTo方法使用说明: int result = o1.compareTo(o2);
- result的值大于0,说明o1比o2大
- result的值小于0,说明o1比o2小
- result的值等于0,说明o1与o2相等
在判断result的值时,我们不关心resul的具体值,只关心result是正数负数还是零
/***
* 如果将 自定义类型对象 插入到TreeSet里面
* 必须保证 自定义类型实现Comparable接口,对象之间有比较算法
*/
public class Person implements Comparable<Person>{
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//@Override
//public int compareTo(Person o) {
//
// //按照姓名添加,如果姓名相同,按照年龄添加
// int num = name.compareTo(o.name);
// if (num == 0) {
// num = age-o.age;
// }
//
// return num;
//}
//按照姓名的长度排序,如果长度一样,则按照姓名字典顺序排序,
//如果姓名值也一样,则按照 年龄 排序
@Override
public int compareTo(Person o) {
int num = name.length() - o.name.length();
int temp = (num == 0) ? (name.compareTo(o.name)) : num;
if (temp == 0) {
temp = age - o.age;
}
return temp;
}
}
public class TreeSetTest2 {
public static void main(String[] args) {
TreeSet<Person> ts = new TreeSet<>();
ts.add(new Person("ls", 24));
ts.add(new Person("zs", 21));
ts.add(new Person("zs12", 21));
ts.add(new Person("ls", 20));
ts.add(new Person("ls123", 20));
ts.add(new Person("ww1", 19));
ts.add(new Person("ww", 19));
for (Person t : ts) {
System.out.println(t);
}
}
}
输出结果:
Person{name='ls', age=20}
Person{name='ls', age=24}
Person{name='ww', age=19}
Person{name='zs', age=21}
Person{name='ww1', age=19}
Person{name='zs12', age=21}
Person{name='ls123', age=20}
比较器排序
比较器排序:可以通过匿名内部类的方式让类实现java.util.Comparator 接口,通过compatator方法编写比较规则
public interface Comparator<T> {
int compare(T o1, T o2);
}
比较器的使用规则: int result = compare(o1, o2);
- result的值大于0,说明o1比o2大
- result的值小于0,说明o1比o2小
- result的值等于0,说明o1与o2相等
在判断result的值时,我们不关心resul的具体值,只关心result是正数负数还是零
//利用比较器按照姓名长度排序, 将对象插入TreeSet
public class TreeSetTest4 {
public static void main(String[] args) {
//通过匿名内部类的形式实例化一个比较器对象 TreeSet 默认中序排序
TreeSet<Person> ts = new TreeSet<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
int num = o1.getName().length() - o2.getName().length();
//System.out.println("长度=>" + num);
if (num == 0) {
num = o1.getName().compareTo(o2.getName());
if (num == 0) {
num = o1.getAge() - o2.getAge();
//System.out.println("年龄=>" + num);
}
}
return num;
}
});
//添加对象
ts.add(new Person("zs", 19));
ts.add(new Person("zs", 20));
ts.add(new Person("lucy",21));
ts.add(new Person("jack",20));
ts.add(new Person("wangwu",23));
ts.add(new Person("wangwu",19));
Iterator<Person> it = ts.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
输出结果:
Person{name='zs', age=19}
Person{name='zs', age=20}
Person{name='jack', age=20}
Person{name='lucy', age=21}
Person{name='wangwu', age=19}
Person{name='wangwu', age=23}
我们也可以通过比较器实现TreeSet不过滤重复元素:
/**
* 从键盘接收一个字符串, 程序对其中所有字符进行排序,
* 例如键盘输入: helloitcast程序打印:acehillostt
*/
public class TreeSetTest6 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
char[] arr = str.toCharArray();//将字符串转换成字符数组
TreeSet<Character> ts = new TreeSet<>(new Comparator<Character>() {
@Override
public int compare(Character o1, Character o2) {
int num = o1.compareTo(o2);
//不去除重复
return num == 0 ? 1 : num;
}
});
for (char c : arr) {
ts.add(c);
}
for (Character t : ts) {
System.out.print(t);
}
}
}
输出结果:
helloitcast
acehillostt
6 双列集合
6.1 Map
6.1.1 概述
java.util.Map<K, V> 接口是专门处理这种一一映射关系数据的集合类型
特点:
- 将键映射到值的对象
- 一个映射不能包含重复的键
- 每个键最多只能映射到一个值
Map类型集合与Collection类型集合,存储数据的形式不同:
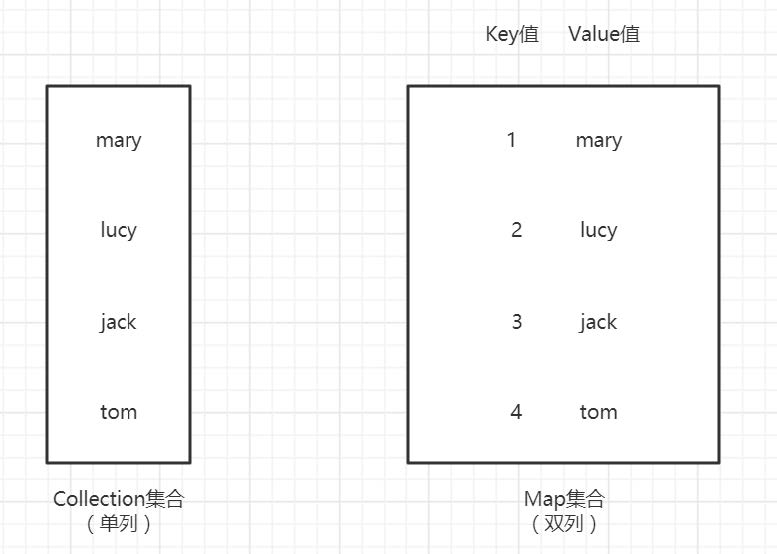
Collection集合每次存一个数据,Map集合一次存一对数据【key-value】键值对
Map接口和Collection接口的不同
-
Map是双列【key,value】,Collection是单列
-
Map的键唯一,Collection的子类set是唯一
-
Map集合的数据结构值针对键有效,跟值无关;
Collection集合的数据结构是针对元素有效
map接口方法
//把key-value存到当前Map集合中
V put(K key, V value)
//把指定map中的所有key-value,存到当前Map集合中
void putAll(Map<? extends K,? extends V> m)
//当前Map集合中是否包含指定的key值
boolean containsKey(Object key)
//当前Map集合中是否包含指定的value值
boolean containsValue(Object value)
//清空当前Map集合中的所有数据
void clear()
//在当前Map集合中,通过指定的key值,获取对应的value
V get(Object key)
//在当前Map集合中,移除指定key及其对应的value
V remove(Object key)
//返回当前Map集合中的元素个数(一对key-value,算一个元素数据)
int size()
//判断当前Map集合是否为空
boolean isEmpty()
//返回Map集合中所有的key值
Set<K> keySet()
//返回Map集合中所有的value值
Collection<V> values()
//把Map集合中的的key-value封装成Entry类型对象,再存放到set集合中,并返回
Set<Map.Entry<K,V>> entrySet()
Map集合的方法使用
public static void main(String[] args) {
Map map = new HashMap();
map.put(1,"tom");
map.put(2,"jack");
map.put(3,"lucy");
map.put(4,"mary");
System.out.println("map是否为空:"+map.isEmpty());
System.out.println("map中元素的个数:"+map.size());
System.out.println("map中是否包含指定key值1:"+map.containsKey(1));
System.out.println("map中是否包含指定value值mary:"+map.containsValue("mary"));
System.out.println("map中获取指定key值1对应的value值:"+map.get(1));
System.out.println("map中获取指定key值5对应的value值:"+map.get(5));\
/* Map集合的这三种遍历方式,在【Map的遍历】部分有详细的画图说明 */
System.out.println("---获取map中所有的kay值---");
Set keys = map.keySet();
for(Object key : keys){
System.out.println(key+" : "+map.get(key));
}
System.out.println("---获取map中所有的value值---");
Collection values = map.values();
for(Object value : values){
System.out.println(value);
}
System.out.println("---获取map中所有的key-value(键值对),封装成Entry类型对象---");
Set entrySet = map.entrySet();
for(Object obj : entrySet){
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
map集合遍历
/**
* map集合遍历
* keySet() 获取所有键的集合
* get(key) 根据键获取值
*/
public class MapTest2 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("001", "jack");
map.put("002", "rose");
map.put("003", "tom");
map.put("004", "lucy");
map.put("001", "kevin");
map.put("002", "larry");
Set<Map.Entry<String, String>> es = map.entrySet();
//entrySet 迭代器遍历
Iterator<Map.Entry<String, String>> it = es.iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " : " + value);
}
System.out.println("------------");
//entrySet 增强for循环遍历
for (Map.Entry<String, String> e : es) {
System.out.println(e.getKey() + " : " + e.getValue());
}
//通过keySet遍历
/*for (String s : map.keySet()) {
System.out.println(s + " : " + map.get(s));
}*/
//System.out.println(map.entrySet());
//show1(map);
}
//提取方法 Ctrl + Alt + M
private static void show1(Map<String, String> map) {
Set<String> ks = map.keySet();
//增强for循环遍历
//for (String k : ks) {
// System.out.println(k + " : " + map.get(k));
//}
//迭代器遍历
//Iterator<String> it = ks.iterator();
//while (it.hasNext()) {
// String key = it.next();
// System.out.println(key + " : " + map.get(key));
//}
}
}
6.1.2 Map实现类
- HashMap
- 存储结构采用的哈希表,元素存储顺序不能保证一致,要保证键的唯一和重复需要重写HashCode和equals方法【最常用的Map】
- HashTable
- 和之前List集合中的Vector 的功能类似,可以在多线程环境中,保证集合中数据的操作安全,类中的方法大多数使用了synchronized 修饰符进行加锁【线程安全】
- TreeMap
- 该类是Map接口的子接口SortedMap下面的实现类,和TreeSet 类似,它可以对key值进行排序,同时构造器也可以接收一个比较器对象作为参数。支持key值的自然排序和比较器排序俩种方式【支持key排序】
- LinkedHashMap
- 该类是HashMap 的子类,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致【存入顺序就是取出顺序】
HashMap和HashTable的区别:
- HashTable是线程安全的,效率低。HashMap是线程不安全的,效率高
- HashTable不可以存储null键和null值,HashMap可以存储null键和null值
6.1.3 HashMap
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//重写HashCode和equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
测试HashMap
/**
* HashMap内部,value值可以重复,与哈希算法无关
*
*/
public class HashMapTest {
public static void main(String[] args) {
//HashMap只关心key是否唯一,底层通过哈希算法实现去除重复,与value值无关
HashMap<String, Student> hs = new HashMap();
hs.put("001", new Student("zs", 19));
hs.put("002", new Student("zs", 19));
hs.put("003", new Student("zs", 19));
hs.put("004", new Student("zs", 19));
//在HashMap中,key或者value可以使用null值
hs.put("005", null);
hs.put(null, new Student("ls", 20));
hs.put(null, new Student("ww", 21));
for (Map.Entry<String, Student> entry : hs.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
/*for (String s : hs.keySet()) {
System.out.println(s + " : " + hs.get(s));
}*/
}
}
输出结果:
null : Student{name='ww', age=21}
001 : Student{name='zs', age=19}
002 : Student{name='zs', age=19}
003 : Student{name='zs', age=19}
004 : Student{name='zs', age=19}
005 : null
6.1.4 TreeMap
public class TreeMapTest {
public static void main(String[] args) {
//底层是二叉树,放入数据结构会自动排序
//优先比较器 推荐多使用比较器排序,通过实现接口类的局限性大
Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//int num = o1.getAge() - o2.getAge();
int num = o1.getName().compareTo(o2.getName());
return num;
}
});
map.put(new Student("zs", 19), "001");
map.put(new Student("ls", 21), "002");
map.put(new Student("ww", 25), "003");
map.put(new Student("zl", 18), "004");
for (Map.Entry<Student, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
输出结果:
Student{name='ls', age=21} : 002
Student{name='ww', age=25} : 003
Student{name='zl', age=18} : 004
Student{name='zs', age=19} : 001
6.1.5 LinkedHashMap
/**
* LinkedHashMap测试
* LinkedHashmap 底层是 链表 有序 不重复
*/
public class LinkedHashMapTest {
public static void main(String[] args) {
Map<Integer, String> map = new LinkedHashMap<>();
map.put(1, "zs");
map.put(3, "ls");
map.put(2, "ww");
map.put(2, "tom");
map.put(4, "zl");
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
输出结果:
1 : zs
3 : ls
2 : tom
4 : zl

 浙公网安备 33010602011771号
浙公网安备 33010602011771号