BERT解析及文本分类应用
前言
在18年末时,NLP各大公众号、新闻媒体都被BERT(《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)刷屏了,刷新了自然语言处理11项纪录,也被称为了2018年最强自然语言处理模型。
笔者很早便完整看了这篇论文,迟迟没有动手,一方面是因为自己懒,各种事情耽搁了,另一方面还是想通过在具体的任务中进行了确切的实践后再与大家分享交流。废话不多说,下面我们进入正题,2018最强自然语言处理模型BERT(注意修饰语2018,因为最近冒出来的OpenAI的研究人员训练的超大规模15亿参数模型已经进一步打破了记录,并开源了一个117M的小模型和代码: https://github.com/openai/gpt-2 ,感兴趣的读者可以看看)
BERT模型概览
了解BERT模型我们需要先回顾谷歌在早前发表的一些观点和paper,我们首先来简单回顾下seq2seq,之后说说attention引出的transformer模型,最后看看BERT模型的细节以及创新点。
Seq2Seq
关于Seq2Seq的模型抽象,笔者之前在浅谈分词算法系列博文中也有反复提及(浅谈分词算法(5)基于字的分词方法(bi-LSTM)),在分词或者词性标注的NLP任务中,我们将文本序列映射到另一个结果序列,如词性tag,分词的BEMS标记tag等。
而在另一类NLP任务,即机器翻译(MT)中,也可以抽象成一种序列到序列的模型,在谷歌2014年的论文Sequence to Sequence Learning with Neural Networks中,提出了端到端的序列到序列的映射模型,利用了LSTM分别做编码和解码(encoder-decoder)操作,并在英文与法文的互相翻译上取得了很棒的效果。比较经典的模型了,网上资料一大把,我们来简单说说这个模型,详细的读者可以翻论文和各种资料。
Seq2Seq即序列到序列的模型,将输入序列\((x_1,x_2,...,x_T)\)映射到输出序列\((y_1,y_2,...,y_{T'})\),其中每个\(y_t\)依赖于之前的输出值\(y_1,y_2,...,y_{t-1}\),另外值得注意的是,在大多数应用场景中输入序列和输出序列的长度是不相等的\((T\neq T')\)。
NMT是典型的Seq2Seq应用场景,将输入序列的一种语言翻译为输出序列的另一种语言,基于条件概率:
其中\(c_t\)表示通过注意力机制(Attention)计算的上下文信息:
条件概率可以通过以下公式进行计算:
其中
\(f(\cdot)\)是一个全连接层,对于机器翻译任务而言,softmax函数用于计算词典中每个词的概率。
encoder-decoder的这种框架在深度模型中是非常常用的,很多实际的NLP问题可以抽象到这个框架上来进行建模,比如NMT(机器翻译)、TTS(语音合成)、ASR(语音识别)等。
Attention
我们了解了Seq2Seq模型后,再来一起看看对其增加Attention后的模型。在Neural Machine Translation by Jointly Learning to Align and Translate这篇论文中,Bahdanau等人在原有Seq2Seq框架的基础上新增了attention(注意力机制),其基于的主要先验感知是:基本的encoder-decoder框架在达到瓶颈后,作者希望通过将源句中与目标句对应部分的关联程度,由模型来自动查找(soft search),而不是硬性的切分。换句好理解的,源句中的每个词在翻译到目标词汇时起到的作用是不一样的,作者希望模型能够学出这种关联强度。举个例子:
我/想/买/苹果/手机。
I want to buy iPhone.
比如在翻译苹果这个词的step时,这时候会有一个明显的歧义,是吃的苹果呢,还是商标品牌呢,那么源句中苹果的上下文对翻译时产生的影响是不一样的,我/想/买,仅凭这三个词我们并不能解决这个苹果的歧义问题,但是看到苹果后面跟着手机这个词,歧义马上消除,苹果指品牌。那么在这个过程中,很明显手机这个词所起到的作用是远远大于我/想/买三个词的。
这只是一个非常直观上的感知,为什么Attention会起作用,当然模型内部的逻辑不会这么具化。下面我们一起看下具体的模型定义:
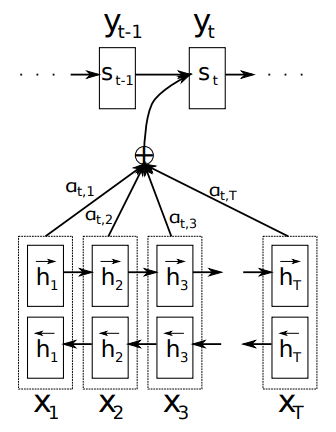
图中我们可以看到大的还是一个encoder-decoder的框架,但是在decoder的过程中,不是将final-state直接作为输入给到,而是在每个step解码时,都考虑encoder过程中对每个词的编码,并以一个权重的形式加权后作为当前step预测的输入,我们来具体看下模型定义:
- 模型输入为:\(X=(x_0,x_1,x_2,...,x_T)\)
- 模型输出为:\(Y=(y_0,y_1,y_2,....,y_T)\)
- encoder层隐层状态:\(H=(h_0,h_1,h_2,...,h_T)\)
- decoder层上一时刻隐层状态:\(s_{t-1}\)
- decoder层上一时刻的输出:\(y_{t-1}\)
- 当前decoder step的上下文:\(c_t\)
图中整个attention的流程是:
- 根据输入X,利用双向LSTM得到两组隐向量,直接concat后得到最终的H;
- 根据encoder层得到的H,对于第t时刻的步骤,当前时刻的上下文\(c_t\)由以下方法计算:
其中\(\alpha_{ij}\)是权重,又称为alignment;h是当前时刻step的encoder所有隐变量,又叫做value或者memory; i代表decoder层的时刻step, j代表encoder层的时刻step。
而\(\alpha_{ij}\)的计算方式如下:
其中\(e_{ij}=a(s_{i-1},h_j)\),我们来解释下这波公式:本质上\(\alpha\)就是一个softmax,其作用就是用一个概率和为1的分布,来刻画encoder不同时刻得到的隐变量的权重,从而衡量其对decoder的重要性;而\(e_{ij}\)其实是通过a,一种线性表达式来度量\(s_{i-1},h_j\)之间的相关程度。细化下a(在论文中称为 alignment mode)的计算方式:
- 对\(s_{i-1}\)做线性映射,得到的向量起名为query,记为\(q_i\);
- 同样对\(h_j\)做线性映射,得到的向量起名为key,记为\(k_j\);
- 最终\(e_{ij}=a(s_{i-1},h_j)=v^Ttanh(q_i+k_j)\),其中\(q_i k_j\)维度一致记为d,v的维度为d*1。
上面在做alignment时采用了query和key相加的方式,也即Bahdanau attention(以作者名字命名);还有另一种常见的Luong attention,核心就是\(e_{ij}\)的计算方式不同,换成相乘即乘性attention,具体计算公式如下:
乘性attention常用的即general一项,dot两者直接相乘相当于是general的特例情况,即以进行过维度统一。还有一些其他变种,大家可以找找相关论文根据具体任务和x、y的向量空间具体分析。
总结下,attention在原有的encoder-decoder框架的基础上,通过query和key的相关程度,之后通过类似softmax的归一化操作得到权重,利用权重、隐状态进行加权和得到上下文context向量,作为decoder层的输入。直观上attention使得与decoder层的状态s相关度越大的h,权重会越高,从而在context中占比更多,对y的输出影响更大,这也是直观的先验解释,为什么attention会这么有效。
注意:这里记住query、key和value的由来,没啥为什么,就起了个别名,在transfomer中它们还将发挥更多的作用。
Transformer
在聊完Attention机制后,我们来聊一聊更加激进的一个模型,Transformer,该框架是谷歌于2017年发表的一篇paper:Attention is all you need[3]。为什么说其激进呢,因为传统意义上的attention框架是构建在RNN或者CNN的基础上,而在该篇论文中,整个框架完全是基于attention的思路建立的,所以也就起名为Attetion is all you need(名字有点嚣张...),下面我们一起来看看transformer模型,先上图:
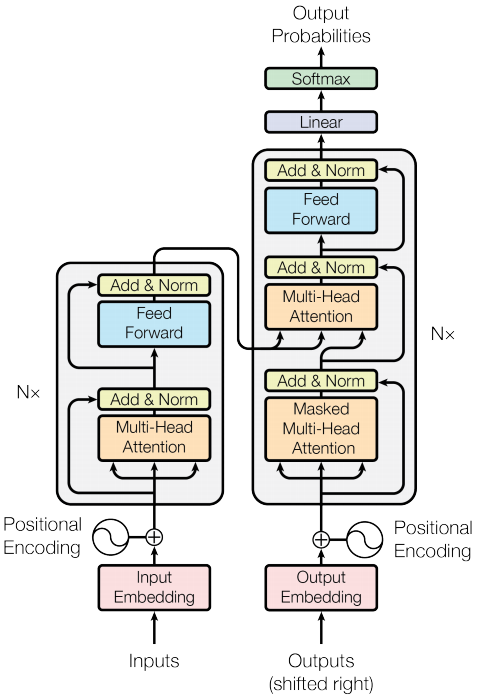
这张图是论文中模型架构图,从主体上看,模型还是遵照了encoder-decoder的框架,左半部分为编码部分,右半部分为解码部分,我们一步步拆解开说下。
图中在Encoder和Decoder两边有Nx的标志,原文中也解释了Encoder部分叠加了6个完全一样的层,同样Decoder层也包含6个相同的层,不过值得注意的是模型中每一层之间都用到了残差连接。
对于每层Encoder的内部,首先会通过一个self-attention层,之后跟一层全连接前馈神经网络;而对于每层Decoder的内部,首先通过一个self-attention,之后会多跟一个attention层用于单词聚焦(类似之前RNN中加入的attention作用),之后同样会跟一层全连接前馈神经网络。
encoder部分
(1)self-attention
上文中Transformer的整体结构我们明白了,我们首先来阐述下self-attention。关于Attention我们在前文中已有详细阐述,只不过之前的attention层依托于RNN之上,而在transformer中使用的self-attention其核心思想来源于attention,不过是独立的一层模型,我们首先直观的理解下self-attention的原理:
例句:因为小狗太累了,所以它没有穿过街区。
我们在理解这句话中的“它”时,很容易关联到“小狗”,那计算机在用向量表征“它”这个词时,如何做到兼顾上下文呢?并且更多的关注到“小狗”这个词,而不是“因为”或者“街区”这些词呢?
我们先回顾一下RNN中计算步骤t的词\(w_t\)的hidden-state时是怎么做的?输入当前词的embedding,并且接收来自t-1的状态向量,根据遗忘门控制接收程度,这样在计算当前词的hidden-state向量时,就考虑了之前的序列(上文),那么如果也想考虑当前词之后的序列(下文)怎么办呢?那就正反各来一遍RNN,即bi-RNN。
现在回到self-attention模型,如果要计算当前词的向量表征,那么我们需要关注上下文其它词,并且每个词对当前词的影响不同,即注意力不同,下面我们进一步细剖析原理。
简单回顾下上文attention时提到的query、key和value的概念(笔者专门让大家注意),通过对s做映射得到query,对h做映射得到key,而h也即是value,之后通过query和key计算关联度之后,利用加权和的方式获得最终的编码向量。
那么在self-attention中,所谓self就都是它自己,没有所谓encoder和decoder的区分,对于经过embedding后的文本向量,通过三个不同的权重向量,分别映射成为query、key以及value,之后通过下图的步骤得到最终的编码向量:
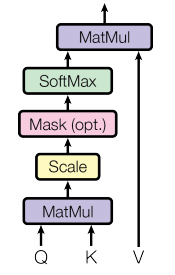
我们可以看到除了映射成为query、key、value时的过程与attention不同外,后续的计算流程self-attention与attention是基本一致的,计算过程如下:
在阅读原论文时,我们会发现论文中在self-attention的基础上,有一个Multi-Head Attention,即多头注意力机制,就是字面意思,将文本embedding通过多个self-attention得到不同的编码结果,然后拼接起来进入下一层,如下图:
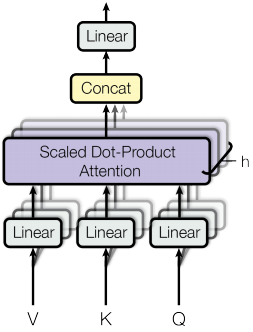
这样做的主要目的是从不同的语义空间投射原文本,能够从更多的角度表征,并且能够拓展模型对不同位置的关注能力。
(2)输入编码
包括CNN、LSTM,我们在进入模型前,需要先将自然语言通过embedding的方式进行编码,从而将高维语义空间的自然语言转化到低维的向量空间,这基本上成了目前NLP的通用模式。那么在Transformer中为什么我们要单独再来说说embedding的问题呢?
熟悉LSTM的可以回忆下,我们将每个词或者字符编码成embedding后,会按照正序或者逆序进入LSTM,在这个过程中,序列中词的位置信息是得到保存的;其实Text-CNN也可以通过不同大小的filter,捕捉到句子中词序的信息。
但是在Transformer中,我们发现序列编码好的矩阵,进入模型,分别通过三个不同的权重矩阵变成了Q、K、V,这个过程当中词序的信息是丢失了的,为了解决这个问题,Transformer在Embedding的基础上,加上了位置编码(Position Encoding),没错就是两者直接相加。原文中在对位置进行编码时,用了一种神奇的规则,利用sine和cosine,正余弦函数来编码,论文中解释了也使用了可学习的位置编码方式,但发现效果差不多,最后选择了正余弦编码方式,因为这种编码方式能够将位置编码扩展到看不见长度的序列优点(比如推断过程中出现的序列比训练样本中任何文本都长)。也比较玄学,感觉作者也是做了很多实验对比选择了一个较优方案吧,编码方式如下:
其中pos是位置,i是维度。也就是说,位置编码的每个维度波长形成从2π到10000·2π的几何级数。而作者提到选择此功能是因为其假设它可以让模型轻松学会理解相对位置,因为对于任何固定偏移k,PEpos + k可以表示为一个线性的PEpos。
(3)残差和FFN
还有两个细节我们没有提到,就是Transformer中的残差和FFN部分。在FFN的部分,模型使用了ReLU作为激活函数,公式如下:
每一层会使用不同的参数,可以将其理解为两个Kernel size为1的卷积。
另外一点是在模型结构中,每层都会间隔一层Add & Norm即layer-normalization,这里深度残差网络的特性,将前一层和前前一层的输出进行求和正则后,作为下一层的输入,该思想成名于图像领域的ResNet,当时在imageNet的结果超过了之前的VGG等模型,感兴趣的读者可以瞅瞅。正则化时,文中提到了dropout设置为0.1。
Decoder部分
(1)结构
逐层理清模型中Encoder的部分,我们来看看Decoder部分。Decoder部分整体与Encoder是一致的,不过从模型图的右边我们可以看出其多了一个子层Multi-Head Attention,在Decoder时,会先进入第一个子层self-attention,得到Q,之后中间层的atention并不是self-attention,其K、V来自Encoder层,结合前一个Q,进入该子层,有这么几点需要注意下:
- 第i个位置的Encoder输出简单变化作为K、V与i-1位置的Decoder第一个子层的输出作为Q;
- Encoder在编码时可以将输入序列作为一个整体,以矩阵的形式一次性编码,但Decoder时当前位置的输出需要依赖上一个位置的输出,所以是按顺序解码的;
- 在Decoder的第一个子层self attention做了mask,保证当前位置i的预测只依赖小于i位置的输出,避免利用未来的信息;
- Decoder层在预测到类似
的结束符时便会停止预测。
(2)Linear和Softmax
Decoder经过两个attention子层和一个FFN子层后的输出,其解码向量经过一个线性映射WX+b,将其映射到整个字典空间,然后经过softmax规整成字典词汇的概率分布,即每个词的分数,之后选取分数最高的词作为输出即可。
BERT
BERT全称是Bidirectional Encoder Representations from Transformers,取了核心单词的首字母而得名,从名字我们能看出该模型两个核心特质:依赖于Transformer以及双向,下面来看论文中的一结构对比图:

论文在最一开始就与另外两个pretrain模型:ELMo和OpenAI GPT做了对比,从结构上我们可以看出ELMo的基础是使用了LSTM,而OpenAI GPT和BERT使用了Transformer作为基本模型。注意BERT一些核心的创新点:
- 相较于OpenAI GPT模型而言,其为双向Transformer;
- 而同是双向,ELMo由于是基于LSTM,BERT基于Transformer,并且核心的是两者的目标函数是不一致的:
OpenAI GPT:$$P(w_i|w_1,...,w_{i-1})$$
ELMo:$$P(w_i|w_1,...,w_{i-1})和P(w_i|w_{i+1},...,w_n)$$
BERT:$$P(w_i|w_1,...,w_{i-1},w_{i+1},...,w_n)$$
即传统意义双向类似ELMo模型,根据上下文,每个词会得到left-to-right和right-to-left两种表示,我们可以将两者concat在一起作为该词的表示,再进行下游的任务操作。而直觉上,如果我们能有一个更加深入的双向模型,直接能够给出词的上下文表示。遗憾的是,不可能训练像普通LM一样的深度双向模型,因为这会产生一些循环,在这些循环中,单词可以间接地“看到自己”,并且预测变得微不足道(其实这点有待进一步商榷)。
所以BERT采用了一些非常简单的trick来实现,
利用自编码器,从输入中掩盖了一部分的单词并且必须从上下文重构这些单词。即所谓Masked LM,其实就是通常意义上的“完形填空”。
关于双向的设计思路,BERT作者在https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/进行过详细论述,感兴趣读者可以移步看看。
Embedding
在前文Transformer我们已经详细阐述过了一句话进入模型的Embedding过程,BERT除了token embedding和position embedding,由于还需要以两个句子作为输入,还添加了segment embedding,如下图:
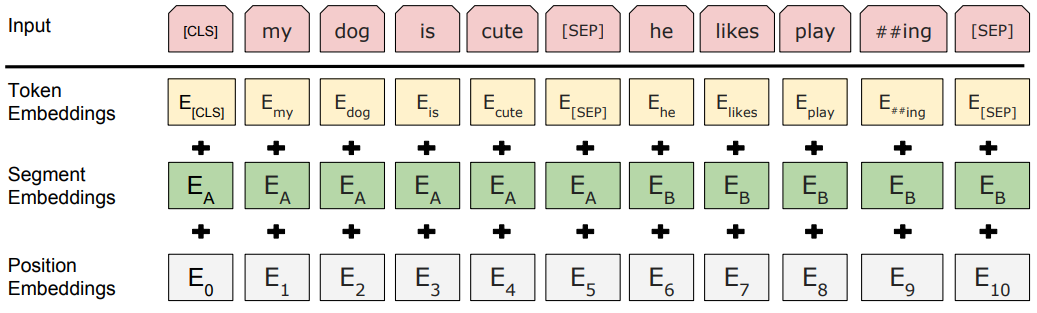
- Token Embeddings是词向量(中文进入就是字符向量),第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
预训练
BERT为了能够在大规模语料上进行无监督学习,非常巧妙的设计了两个预训练任务:一个是随机遮蔽(mask)掉一个句子中的词,利用上下文进行预测;另一个是预测下一个句子(类似QA场景)。
(1) Task #1: Masked LM
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = store
该任务就是BERT为了做到双向深度上下文表示设计的预训练trick任务,而在mask单词的时候,作者也采用了一些技巧,随机mask掉15%的token,最终的损失函数只计算mask掉的token。而对于被mask掉的词也并非简单粗暴的将全部替换成[MASK]标签完事,会遵循如下步骤:
- 80%即大部分情况下,被mask掉的词会被[MASK]标签代替;
- 10%的情况下,将该词用一个随机的词替换掉;
- 10%的情况下,保留该词在原位置。
这样做的目的是偏向代表实际观察到的词。另外模型在预训练时,Transformer编码器并不知道哪些词被mask掉了,所以模型对每个词都会关注。同时,因为随机替换仅发生在所有词的1.5%(即15%*10%),对模型的语言理解能力影响很小。
(2) Task #2: Next Sentence Prediction
Input:
the man went to the store [SEP] he bought a gallon of milk
Label:
IsNext
Input:
the man went to the store [SEP] penguins are flightless birds
Label:
NotNext
由于在LM的下游任务还会涉及到问答(Question Answering (QA) )和推理( Natural Language Inference (NLI))的任务,这需要LM有理解句子间关系的能力,所以作者新增了一个预训练任务,输入句子A和B,预测B是否为A的下一个句子,以50%的概率配对A和B,即50%B是真的,50%B是随机选取的一个句子。
所以作者提示在选取预训练语料时,要尽可能选取document-level的语料而非segment-level混合在一起的语料。
文本分类试验
利用BERT我在文本分类任务上进行了尝试,语料集是用户评论内容,目标是预测用户评论内容的情感极性,分为正中负三类。
BERT源码拉下来后需要进行一些简单调整,比如将TPUEstimator换成普通的estimator,改变一些模型指标计算方式等。
笔者首先利用1000W左右的评论语料对BERT的中文预训练模型进行了迁移学习,之后通过500W语料分别在text-cnn、lstm concat cnn以及lstm concat cnn with bert上进行了训练对比。(注:这里lstm concat cnn是笔者在该任务上试验后选取的效果较好的模型结构)
指标情况如下:
Text_cnn
Avg acc: 0.8802
sentence num:13530, tags all num:13530, neg num:5539, neu num:1398, pos num:6593
precision recall f1-score support
0 0.88 0.96 0.92 5539
1 0.54 0.22 0.31 1398
2 0.91 0.95 0.93 6593
avg / total 0.86 0.88 0.86 13530
LSTM concat CNN
precision recall f1-score support
0 0.92 0.96 0.94 5539
1 0.60 0.43 0.50 1398
2 0.93 0.95 0.94 6593
avg / total 0.89 0.90 0.89 13530
0.8997782705099778
3.9ms/条
LSTM concat CNN with BERT
precision recall f1-score support
0 0.92 0.96 0.94 5539
1 0.67 0.35 0.46 1398
2 0.90 0.97 0.94 6593
avg / total 0.89 0.90 0.89 13530
0.9000739098300073
29.365628ms/条
笔者在实验过程中发现的几点需要注意:
- 直接用BERT进行fine-tune的效果,在中文语料上效果一般,因为中文是以字作为embedding来考虑的,丢失了太多的词语信息;
- 将BERT作为辅助上下文,添加在别的模型中,效果会有所提升,但效果有限;
- 添加BERT后,CPU做inference速度较慢,需要考虑计算成本
鉴于第3点,笔者尝试了将BERT中的字向量完全抽出来,作为辅助输入到模型中,但是这种方式的效果不是很好,直觉上BERT需要依赖上下文来求得当前token的embedding,单独抽出来失去了其双向深度编码的优势。
后续笔者准备尝试下百度的 https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE ,其考虑了中文的词语信息,更适合中文场景,BERT只能进行纯字的embedding在中文场景效果提升有限。
另外还有更好的想法欢迎大家留言一起讨论~
参考文献
- Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017: 5998-6008.
- Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- https://github.com/google-research/bert

 浙公网安备 33010602011771号
浙公网安备 33010602011771号